
MongoDB Migration
배경
Docker Swarm에서 서비스 애플리케이션과 MongoDB Replica Set을 함께 운영 중이었다.
최근 여러 서비스를 Kubernetes(K8s)로 이전하면서, 현재 운영 중인 서비스도 K8s로 이전해 관리하는 것이 좋겠다고 판단했다.
간단히 이전할 수 있는 서비스들은 모두 K8s에 배포했으나, DB 데이터 이전은 이전해야 했다.
DB 동기화 후 트래픽을 돌리면 되지만 가장 중요한 것은 데이터 정합성이었다.
RDB는 RDS를 사용 중이라 문제가 없었지만, 온프레미스로 운영 중인 MongoDB는 실시간 동기화가 필요했다.
이 문제를 해결하기 위해 여러 방법을 시도한 경험을 정리해본다.
어떻게 데이터를 완전 동기화 할 것인가?
CDC(Change Data Capture) & KafkaConnect
첫 번째로 CDC 와 KafkaConnect 를 활용한 데이터 동기화 방법이 떠올랐다.
KafkaConnect 와 Debezium(Source Connector), MongoSinkConnector 를 사용해본 경험이 있어서 이 방법을 시도해봤다.
이전에는 KafkaCluster 를 docker-compose 로 직접 정의해 사용했는데, kafka, zookeeper, schema registry, connect 등 서비스 구성이 복잡하고, 이를 모두 관리하기 어려웠다.
K8s 생태계에는 이런 복잡한 서비스들을 쉽게 배포하고 관리할 수 있는 Operator 가 존재한다.
Strimzi Kafka Operator 를 사용해 KafkaCluster 를 배포하고, KafkaConnect 를 사용해 데이터를 동기화해보기로 했다.
우선 Strimzi Kafka Operator 를 사용해 Kafka 환경을 구성해본다.
Strimzi Kafka Operator 는 Kubernetes 환경에서 Apache Kafka 클러스터를 관리하고 운영할 수 있도록 도와주는 오픈 소스 프로젝트입니다.
이 Operator는 Kubernetes 네이티브 방법론을 사용하여 Kafka 클러스터의 배포, 관리, 모니터링을 자동화합니다.
Strimzi는 특히 Kafka 클러스터의 설정 및 유지보수를 간소화하고, 높은 가용성과 확장성을 제공하며, 운영자의 수작업을 최소화합니다.
Install Strimzi Kafka Operator
helm repo add strimzi https://strimzi.io/charts/
helm repo update
helm install strimzi-kafka-operator strimzi/strimzi-kafka-operator --namespace kafka --create-namespaceDeploy Kafka Cluster
# kafka-cluster.yaml
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: kafka-cluster
namespace: kafka
spec:
kafka:
replicas: 3
listeners:
- name: plain
port: 9092
type: internal
tls: false
- name: tls
port: 9093
type: internal
tls: false
- name: external
port: 9094
type: nodeport
tls: false
storage:
type: jbod
volumes:
- id: 0
type: persistent-claim
size: 10Gi
deleteClaim: true
config:
offsets.topic.replication.factor: 3
transaction.state.log.replication.factor: 3
transaction.state.log.min.isr: 2
default.replication.factor: 3
min.insync.replicas: 2
template:
pod:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app.kubernetes.io/name
operator: In
values:
- kafka
topologyKey: 'kubernetes.io/hostname'
zookeeper:
replicas: 3
storage:
type: persistent-claim
size: 10Gi
deleteClaim: true
template:
pod:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app.kubernetes.io/name
operator: In
values:
- zookeeper
topologyKey: 'kubernetes.io/hostname'
entityOperator:
topicOperator: {}
userOperator: {}kubectl apply -f kafka-cluster.yamlDeploy Schema Registry
Schema Registry는 Kafka 메시지의 데이터 구조를 정의하고 관리하는 중앙 저장소입니다.
이를 통해 데이터의 형식과 스키마를 중앙에서 관리하고, 데이터의 호환성을 보장할 수 있습니다.
주로 Apache Kafka와 함께 사용되며, JSON, Avro, Protobuf 등 다양한 데이터 형식을 지원합니다.
Schema Registry는 데이터 프로듀서와 컨슈머 간의 데이터 형식 계약을 정의하고 관리하여 데이터 일관성을 유지합니다.
# schema-registry.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: schema-registry
namespace: kafka
labels:
app: schema-registry
spec:
replicas: 1
selector:
matchLabels:
app: schema-registry
template:
metadata:
labels:
app: schema-registry
spec:
containers:
- name: schema-registry
image: confluentinc/cp-schema-registry:7.3.0
ports:
- containerPort: 8081
env:
- name: SCHEMA_REGISTRY_KAFKASTORE_BOOTSTRAP_SERVERS
value: PLAINTEXT://kafka-cluster-kafka-bootstrap:9092
- name: SCHEMA_REGISTRY_HOST_NAME
value: schema-registry
- name: SCHEMA_REGISTRY_LISTENERS
value: http://0.0.0.0:8081
---
apiVersion: v1
kind: Service
metadata:
name: schema-registry-service
namespace: kafka
spec:
selector:
app: schema-registry
ports:
- protocol: TCP
port: 8081
targetPort: 8081kubectl apply -f schema-registry.yamlKafkaConnector
Strimzi KafkaConnector 는 빌드 단계와 커넥트 단계로 나뉜다.
빌드 단계는 필요한 플러그인을 설치하고 커스텀 이미지를 생성해 배포한다.
커넥트 단계는 빌드된 이미지를 사용하여 Kafka Connect 클러스터를 배포한다.
커스텀 이미지를 저장하기 위한 이미지 저장소가 필요하다. dockerhub 등을 사용해도 되고 harbor 같은 프라이빗 레지스트리를 사용해도 된다.
나의 경우 harbor 를 사용했다. 적절한 secret 을 생성한다.
kubectl create secret docker-registry harbor-secret \
--docker-server=<harbor-domain> \
--docker-username=robot\$<robot-name> \
--docker-password=<robot-secret> \
--namespace=kafkaStrimzi KafkaConnector 에서 사용할 Source, Sink Connector 의 (Plugin)[Strimzi Connector] 을 설정해야한다.
문서에서 확인할 수 있듯이, Plugin 의 유형별로 정의하는 방법이 다르다.
maven, tgz, jar 등 다양한 유형의 Plugin 을 설정할 수 있다.
- maven: 저장소, 그룹, 아티팩트, 버전을 지정해야한다.
- tgz: url, sha512sum 을 지정해야한다.
- jar: url, sha512sum 을 지정해야한다.
debezium 등 관련 의존성이 모두 패키징 되어있는 경우 tgz, jar 로 설치해도 되는데 그 외의경우 maven 으로 설치하길 권장한다.
예를들어, converter 를 사용하기 위해 kafka-connect-avro-converter 를 설치하려고 했는데, jar 를 사용하니 관련의존성을 모두 수동으로 추가해야 하는 복잡함이 있었다.
maven 을 사용하는경우 관련 의존성이 자동으로 설치된다.
처음에는 maven 사용 시 매우 느린 설치(빌드) 시간 때문에 jar 를 사용했는데, 위 문제로 인해 maven 을 사용했다.
wget https://repo1.maven.org/maven2/io/debezium/debezium-connector-mongodb/1.9.5.Final/debezium-connector-mongodb-1.9.5.Final-plugin.tar.gz
sha512sum debezium-connector-mongodb-1.9.5.Final-plugin.tar.gz
> 89134e22bc0cdd37452a9c348a361c299d1c96ece4ec546970f00daf2f482ee8f91c81c13ee4948fb42fc2430b73790d44567f4bad480bbb7d9a1ae85532bc3e debezium-connector-mongodb-1.9.5.Final-plugin.tar.gz
# 위 sha512sum key 를 plugin artifacts 에 함께 정의한다.Deploy Kafka Connector
# kafka-connector.yaml
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnect
metadata:
name: kafka-connect-cluster
namespace: kafka
spec:
replicas: 1
bootstrapServers: kafka-cluster-kafka-bootstrap:9092
config:
group.id: connect-cluster
offset.storage.topic: connect-offsets
config.storage.topic: connect-configs
status.storage.topic: connect-status
build:
output:
type: docker
image: <YOUR_IMAGE_REPOSITORY_HOST>/util/mongodb-kafka-connect:latest
pushSecret: harbor-secret
plugins:
######################################################################################################
# 아래 다양한 plugin 을 설치하고 있는데, 필요한것만 사용하면된다. 테스트 중 오래걸리는 빌드를 여러번 하고싶지 않아 모두 설치했다. #
######################################################################################################
- name: confluent-protobuf-converter
artifacts:
- type:
maven
# 레파지토리 잘 확인해야함 central 아니라 confluent 이다.
repository: https://packages.confluent.io/maven/
group: io.confluent
artifact: kafka-connect-protobuf-converter
version: 7.3.0
- name: confluent-json-converter
artifacts:
- type:
maven
# 레파지토리 잘 확인해야함 central 아니라 confluent 이다.
repository: https://packages.confluent.io/maven/
group: io.confluent
artifact: kafka-connect-json-schema-converter
version: 7.3.0
- name: confluent-avro-converter
artifacts:
- type:
maven
# 레파지토리 잘 확인해야함 central 아니라 confluent 이다.
repository: https://packages.confluent.io/maven/
group: io.confluent
artifact: kafka-connect-avro-converter
version: 7.3.0
- name: debezium-mongodb
artifacts:
- type: tgz
url: https://repo1.maven.org/maven2/io/debezium/debezium-connector-mongodb/2.6.1.Final/debezium-connector-mongodb-2.6.1.Final-plugin.tar.gz
sha512sum: f1b99f20eda66659cd18d63abdd95b88cf7c0a46e707375821c4bf8d53d3c934e755f37cd3471474d57baf499bddc705493a51c81439b1e7f12c60cb9fe2de70
- name: mongo-kafka-connect
artifacts:
- type: maven
group: org.mongodb.kafka
artifact: mongo-kafka-connect
version: 1.12.0
template:
pod:
imagePullSecrets:
- name: harbor-secret
readinessProbe:
initialDelaySeconds: 60
periodSeconds: 5
livenessProbe:
initialDelaySeconds: 60
periodSeconds: 5
jvmOptions:
-Xms: 512M
-Xmx: 1G
resources:
requests:
memory: 2Gi
cpu: 1000m
limits:
memory: 2Gi
cpu: 1000mkubectl apply -f kafka-connector.yamlDebezium Source Connector & MongoDB Kafka Sink Connector
Register Debezium MongoDB Connector
source, sink connector 설정을 위한 configmap 을 생성해야한다.
그리고, connector 를 등록하는 job 을 생성한다. (직접 curl 로 등록해도 된다)
# connectors-config.json
apiVersion: v1
kind: ConfigMap
metadata:
name: mongodb-connectors-config
namespace: kafka
data:
mongodb-source-connector.json: |
{
"name": "mongodb-source-connector",
"config": {
"connector.class": ~,
"connection.uri": ~,
...
}
}
mongodb-sink-connector.json: |
{
"name": "mongodb-sink-connector",
"config": {
"connector.class": ~,
"connection.uri": ~,
...
}
}
---
# register-mongodb-connectors-job.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: register-mongodb-connectors
namespace: kafka
spec:
template:
spec:
containers:
- name: curl
image: curlimages/curl
command: ['sh', '-c']
args:
- |
cat /config/mongodb-source-connector.json &&
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" -d @/config/mongodb-source-connector.json http://kafka-connect-cluster-connect-api.kafka.svc.cluster.local:8083/connectors/ &&
echo "\n\n------------------------------------------------------------------------\n\n" &&
cat /config/mongodb-sink-connector.json &&
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" -d @/config/mongodb-sink-connector.json http://kafka-connect-cluster-connect-api.kafka.svc.cluster.local:8083/connectors/
volumeMounts:
- name: config
mountPath: /config
readOnly: true
restartPolicy: OnFailure
volumes:
- name: config
configMap:
name: mongodb-connectors-configkubectl apply -f connectors-config.yaml
kubectl apply -f register-mongodb-connectors-job.yaml하지만 위와같이 connector 를 등록해도 정상적으로 동작하지 않는다.
이 내용은 아래 계속한다.
Kafka Cli (Optional)
Strimzi Kafka Operator 에는 기본적으로 cli 가 제공되지 않는다.
connector config 을 테스트하다가 offset 이 꼬여서 reset 하기 위해 kafka cli 를 사용했다.
# kafka-cli.yaml
apiVersion: v1
kind: Pod
metadata:
name: kafka-cli
namespace: kafka
spec:
containers:
- name: kafka-cli
image: confluentinc/cp-kafka:latest
command: ['sleep']
args: ['infinity']kubectl apply -f kafka-cli.yamlShow Kafka Consumer Group
# in kafka-cli pod
[appuser@kafka-cli ~]$ kafka-consumer-groups --bootstrap-server kafka-cluster-kafka-bootstrap:9092 --list
connect-mongodb-sink-connectorDescribe Group
# in kafka-cli pod
[appuser@kafka-cli ~]$ kafka-consumer-groups --bootstrap-server kafka-cluster-kafka-bootstrap:9092 --describe --group connect-mongodb-sink-connector
Consumer group 'connect-mongodb-sink-connector' has no active members.
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
connect-mongodb-sink-connector dbserver1.<db>.<collection> 0 190 190 0 - - -
connect-mongodb-sink-connector dbserver1.<db>.<collection> 0 285100 285100 0 - - -
connect-mongodb-sink-connector dbserver1.<db>.<collection> 0 0 0 0 - - -
connect-mongodb-sink-connector dbserver1.<db>.<collection> 0 16 16 0 - - -Reset Offset
# in kafka-cli pod
[appuser@kafka-cli ~]$ GROUP_ID="connect-mongodb-sink-connector"
[appuser@kafka-cli ~]$ kafka-consumer-groups --bootstrap-server kafka-cluster-kafka-bootstrap:9092 --group $GROUP_ID --reset-offsets --to-earliest --all-topics --execute
GROUP TOPIC PARTITION NEW-OFFSET
connect-mongodb-sink-connector dbserver1.<db>.<collection> 0 0
connect-mongodb-sink-connector dbserver1.<db>.<collection> 0 0
connect-mongodb-sink-connector dbserver1.<db>.<collection> 0 0
connect-mongodb-sink-connector dbserver1.<db>.<collection> 0 0KafkaConnect Troubleshooting
마이그레이션 할 source, sink mongodb 를 지정해야한다.
나의 경우 모든 데이터베이스가 내부망에 위치해있고 replicaset 으로 배포되어있었다.
k8s cluster 의 서비스로 배포된 KafkaConnect 에서 docker swarm 클러스터의 mongodb 에 바로 접근할 수 없는 환경이다.
이 문제를 해결하기 위해 여러 방법을 시도했다.
Source MongoDB 외부망으로 공개
처음에는 cloudflare tunnel 을 사용해 public hostname 을 부여하고 커넥터에서 연결하려 했으나 실패했다.
docker swarm 의 api 서버 등 내부망에 배포되어있지만 공개적으로 노출되어야 하는 서비스를 위해 사용하고 있었다.
tunnel connector 는 docker swarm 을 구성하고있는 vm 노드에 배포되어있고 mongodb 서비스는 host.docker.internal:host-gateway 로 물려있어서 접근이 가능할거라고 생각했다.
tcp 프록시를 설정했고 연결을 시도했으나 실패했다. cloud flare tunnel 이 http 유형에 특화되어 있어서 그런지 결국 해결하지 못했다.
이후 ngrok 을 사용해 tcp 터널을 생성했고 테스트해본 결과 외부에서 접근이 가능해졌다.
하지만 이 방법에도 문제가 있었는데, ngrok 은 1개의 터널까지만 무료로 제공한다. 동시에 여러개의 터널(노드개수 3개)을 사용하기 위해선 유료로 전환해야한다.
primary node 의 데이터만 복제해도 정합성을 유지할 수 있어서 primary mongodb 컨테이너 내부에 터널(ngrok)을 사용하여 외부망에 노출시켰다.
위 방법은 개발서버에서 테스트하기에 편한 방법이지만, 운영서버에서 사용하기에는 적합하지 않다.
데이터베이스에 접근할 수 있는 엔드포인트가 외부망에 노출되어있기 때문에 보안상 위험하다.
Invalid user permissions authentication failed. Exception authenticating MongoCredential
sink mongodb replicaset 에서 인증이 실패하는 문제가 발생했다.
모든 노드정보를 connection.uri 에 사용했는데, Invalid user permissions authentication failed. Exception authenticating MongoCredential 인증 에러가 발생했다.
이유는 모르겠지만, primary 노드를 특정해서 사용하니 인증이 성공했다.
Debezium Connector Transform
Document 가 그대로 옮겨지길 원했는데, Sink 에 실제로 옮겨진 데이터에 잡다한 메타데이터가 붙어있었다.
기본적으로 kafka connect 로 전송되는 데이터에는 여러 메타데이터가 포함되어있는걸로 보인다.
example
{
"_id": {
"$oid": "6645e81b44e1f02c42fd650d"
},
"patch": null,
"filter": null,
"op": "r",
"updateDescription": null,
"after": "{\"_id\": {\"$oid\": \"649288be3f7df20bb41c1d29\"}, ...}",
"source": {
"ord": {
"$numberLong": "1"
},
"rs": "dbrs",
"h": null,
"txnNumber": null,
"stxnid": null,
"collection": "<collection>",
"version": "1.9.5.Final",
"lsid": null,
"sequence": null,
"connector": "mongodb",
"name": "dbserver1",
"tord": null,
"ts_ms": {
"$numberLong": "1715845839000"
},
"snapshot": "true",
"db": "<db>"
},
"ts_ms": {
"$numberLong": "1715845848559"
},
"transaction": null
}이 경우 원하는 데이터만 다루기 위해 SMT(Single Message Transform) 를 구성하라고 문서에 나와있다.
transforms=unwrap,...
transforms.unwrap.type=io.debezium.transforms.ExtractNewRecordState
...하지만 SMT 설정을 해도 여전히 메타데이터가 포함된 데이터가 전송되었다.
공식 문서 를 잘 살펴보니 위 설정은 SQL 기반 데이터베이스 커텍터에 대한 SMT 설정이었다.
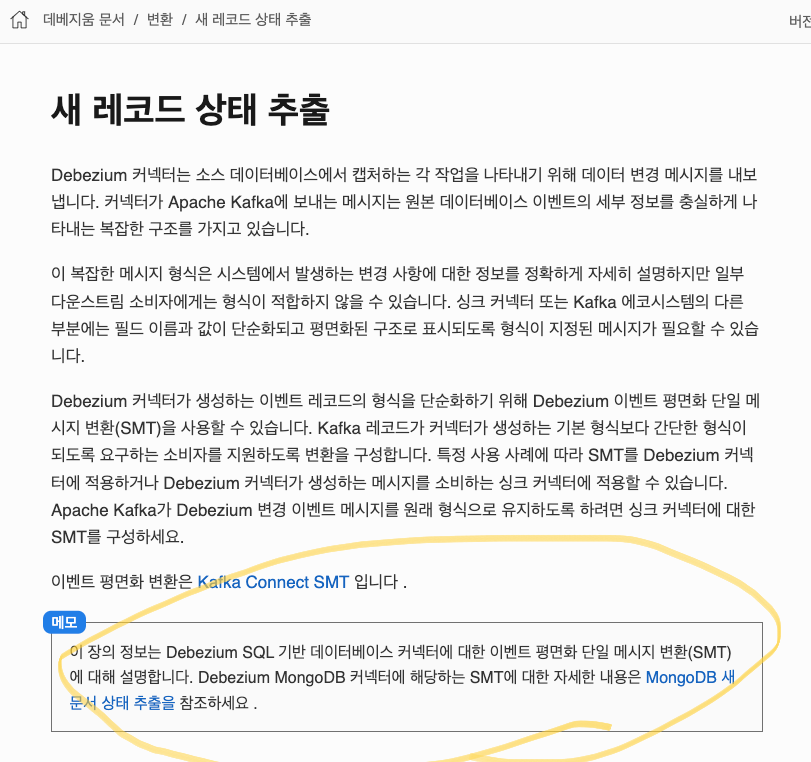
안내에 따라 확인한 MongoDB 문서 에서는 아래 설정을 추가하라고 한다.
transforms=unwrap,...
transforms.unwrap.type=io.debezium.connector.mongodb.transforms.ExtractNewDocumentState,
snapshot.mode=initial위 설정 외에도 몇몇 문제가 발생했다.
debezium source config 에서topic.prefix를mongo.으로 했는데 생성된 토픽들이mongo..~~~가 되는 문제가 있었다.
debezium 버전에 따라 달라진 설정들이 있으니 공식 문서 에서 확인 후 사용하길 바란다.
Schema Registry & Avro Converter
데이터 마이그레이션이 동작하는것을 확인했으나, Source 의 테이터 타입이 지켜지지 않고 이전되는 상황이 발생했다.
JsonConverter 를 사용하고 있었는데, 데이터의 타입까지는 보장해주지 않았다.
Schema Registry 와 Avro Converter 를 사용하면 데이터의 타입까지 보장해준다고 해서 적용시켜봤다.
Avro Converter 를 적용시켰지만 여전히 안된다. writer(publish) 스키마와 reader(consume) 스키마가 다르다는 에러가 발생했다.
writer 스키마에는 문제가 없는데 reader 스키마에서 nested field(Array -> Object -> ...) 에서 해당 필드를 String 으로 인식한다.
reader 스키마
{
...,
"name": "labels",
"type": ["null", { "type": "array", "items": ["null", "string"] }],
"default": null,
...
}writer 스키마
{
...,
"name": "labels",
"type": [
"null",
{
"type": "array",
"items": [
"null",
"string",
{
"type": "record",
"name": "labels",
"fields": [
{ "name": "field1", "type": ["null", "int"], "default": null },
{ "name": "field2", "type": ["null", "double"], "default": null },
{ "name": "field3", "type": ["null", "int"], "default": null },
...,
{ "name": "_class", "type": ["null", "string"], "default": null }
]
}
],
"default": []
}
],
"default": null,
...
}등록된 Schema 를 수정하고 여러 정책을 적용시켜봐도 해결되지 않았고, 결국 Avro Converter 사용을 포기했다.
source 와 sink 커넥터의 provider 가 달라서 이런 호환문제가 발생하는게 아닐까 하는 마음에 MongoDB Kafka Connector 문서를 찾아보는데 아래와 같은 내용이 있었다.

서비스중에 스키마가 변경되어 비정형 구조를 가지고 있었다.
위에서 테스트한 source connector 는 debezium 이었지만, avro converter 의 고질적인 문제일 수 있다고 생각했다.
MongoDB Kafka Source & Sink Connector
Debezium 도 포기하고, 같은 Provider 에서 제공하는 커넥터들은 사용해보기로 했다.
여러 시도를 해봤으나 커넥터를 등록한 이후의 데이터만 복제되고, 초기 데이터를 모두 복제하지 못했다.
완전 동기화를 위해서 source 의 모든 데이터를 복제하고 스트림을 유지해야한다.
문서를 보면 레플리카 셋이나 샤드 클러스터일 경우 "startup.mode": "copy_existing" 이 가능하다고 하는데, 노드 하나만 사용해서 그런건 아닐까 싶다.
확인을 위해선 source mongodb replica 전체를 외부로 노출시킬 만큼의 터널링 해야하는데, 불가능하다.
MongoMirror Troubleshooting
KafkaConnect 를 사용한 방법을 포기했다. mongodb 에서 공식적으로 제공하는 마이그레이션 툴이 있을까 싶어 찾아봤는데 있었다.
이걸 먼처 찾아봤어야 하는데, 삽질 다 하고 나서야 찾았다.
mongomirror 는 source, destination 클러스터로 접근이 가능한 환경에서 사용할 수 있었다.
내부망에서 docker swarm, k8s 를 구성하고 있는 모든 노드들은 192.168.c.d 대역을 사용하고있다.
c 레코드로 구분하고있고 서로 통신이 가능하다. (docker swarm 1번, k8s 5번 대역)
따라서, k8s 노드(5번 대역)에서 docker swarm 클러스터의 mongodb 로 접근할 수 있고 mongomirror 를 사용할 수 있을 것이다.
- 192.168.1.85:11027
- 192.168.1.85:11028
- 192.168.1.85:11029
strimzi kafka connector pod 에 hostNetwork 설정하고 1번 대역의 swarm mongodb 로 접근하면 되지 안되나?
-> 안된다. Strimzi KafkaConnect CRD 에서는 지원하지 않는 기능이다.
$ ./mongomirror \
--host "dbrs/192.168.1.85:11027,192.168.1.85:11028,192.168.1.85:11029" \
--destination "rs0/192.168.142.179:27017,192.168.96.239:27017,192.168.18.4:27017" \
--destinationUsername "test" \
--destinationPassword "test" \
--destinationAuthenticationDatabase "<db>" \
-vvvvv
mongomirror version: 0.12.8
git version: 9ada646c5a33fa5a06b77000579e21e932879f6a
Go version: go1.16.15
os: linux
arch: amd64
compiler: gc
2024-05-17T17:30:09.569+0000 will listen for SIGTERM, SIGINT, and SIGKILL
2024-05-17T17:30:09.580+0000 Source isMaster output: {IsMaster:true MinWireVersion:0 MaxWireVersion:21 Hosts:[192.168.1.85:11027 192.168.1.85:11028 192.168.1.85:11029] SetName:dbrs SetVersion:3 Me:192.168.1.85:11028}
2024-05-17T17:30:09.580+0000 Source buildInfo output: {Version:7.0.9 VersionArray:[7 0 9 0] GitVersion:3ff3a3925c36ed277cf5eafca5495f2e3728dd67 OpenSSLVersion: SysInfo: Bits:64 Debug:false MaxObjectSize:16777216}
2024-05-17T17:30:09.583+0000 Mirroring from source: dbrs/192.168.1.85:11027,192.168.1.85:11028,192.168.1.85:11029; to destination: rs0/192.168.142.179:27017,192.168.96.239:27017,192.168.18.4:27017위 상태에서 멈춰있다가 timeout 에러가 발생했다.
직접 mongodb container 에 접속해보니 인증 에러가 발생했다.
$ mongosh --host "192.168.142.179:27017,192.168.96.239:27017,192.168.18.4:27017" -u "test" -p "test" --authenticationDatabase "<db>"
Current Mongosh Log ID: 66479c6e0810e04b608a758b
Connecting to: mongodb://<credentials>@192.168.142.179:27017,192.168.96.239:27017,192.168.18.4:27017/?authSource=<db>&appName=mongosh+1.10.5
MongoServerSelectionError: getaddrinfo EAI_AGAIN staging-mongodb-0.staging-mongodb-headless.<service-namespace>.svc.cluster.local호스트 이름을 직접 매핑한다.
sudo vi /etc/hosts
192.168.142.179 staging-mongodb-0.staging-mongodb-headless.<service-namespace>.svc.cluster.local
192.168.96.239 staging-mongodb-1.staging-mongodb-headless.<service-namespace>.svc.cluster.local
192.168.18.4 staging-mongodb-2.staging-mongodb-headless.<service-namespace>.svc.cluster.local
---
$ mongosh --host "192.168.142.179:27017,192.168.96.239:27017,192.168.18.4:27017" -u "test" -p "test" --authenticationDatabase "<db>"
Current Mongosh Log ID: 66479d498fed4f8e39ebfb78
Connecting to: mongodb://<credentials>@192.168.142.179:27017,192.168.96.239:27017,192.168.18.4:27017/?authSource=<db>&appName=mongosh+1.10.5
Using MongoDB: 7.0.7
Using Mongosh: 1.10.5
For mongosh info see: https://docs.mongodb.com/mongodb-shell/
rs0 [primary] test> rs.status()
MongoServerError: not authorized on admin to execute command { replSetGetStatus: 1, lsid: { id: UUID("b0380869-a273-4f63-a5e3-fd5a14861430") }, $clusterTime: { clusterTime: Timestamp(1715969348, 1), signature: { hash: BinData(0, 4F0B9C292832F7E1903F4DAA04C8691C27F1806D), keyId: 7369193195852267525 } }, $db: "admin" }
rs0 [primary] test>접속은 되었으나 권한이 없다는 에러가 발생했다.
mongomirror 가 MongoDB Atlas 로 이전하기 위한 툴이라는 설명이 있는데 혹시 이것때문인가 싶어 다른 방법을 찾아봤다.
이때 정확한 원인을 찾지 못하고 포기했는데, 돌아보니 추가적인 권한설정을 하지 않아서 그랬던 것 같다.
아래에 mongosync 를 적용시켜봤는데, 마찬가지로 권한문제가 많이 발생했다.
결국 적절한 권한을 부여해 mongosync 의 권한문제를 해결했다.
MongoSync Troubleshooting
mongodb 공식문서에서 mongosync 제공하는것을 확인할 수 있었고 사용해봤다.
mongosync 를 사용하기 위해 source, destination mongodb 에서 사용자를 생성하고 권한을 부여해야했다.
예를들어 test 계정을 사용해 동기화 하려면 아래와 같이 권한을 부여한다.
권한을 부여하지 않으려면 root 계정으로 동기화를 진행해야한다.
아래 권한은 정확하지 않을 수 있습니다. 권한을 여러개 부여하다 보니 맞지않는 부분이 있을 수 있습니다.
권한이 부족할 경우 에러로그를 보고 적절한 권한을 추가해주시기 바랍니다.
# primary node mongosh
use admin
db.grantRolesToUser("test", [
{ role: "readWrite", db: "admin" },
{ role: "readWrite", db: "admin" },
{ role: "dbAdmin", db: "admin" },
{ role: "readWrite", db: "mongosync_reserved_for_internal_use" },
{ role: "clusterAdmin", db: "admin" },
{ role: "clusterMonitor", db: "admin" }
])권한이 준비됐으면 mongosync 를 실행한다.
$ mongosync --cluster0 "mongodb://test:test@192.168.1.85:11021,192.168.1.85:11022,192.168.1.85:11023/<db>?replicaSet=dbrs&authMechanism=SCRAM-SHA-256&authSource=<db>" --cluster1 "mongodb://<username>:<password>@192.168.142.179:27017,192.168.96.239:27017,192.168.18.4:27017/?replicaSet=rs0&authMechanism=SCRAM-SHA-256"
{"time":"2024-05-20T06:18:51.439291Z","level":"info","serverID":"68554aa1","mongosyncID":"coordinator","version":"1.7.2","commit":"a06d79c5513abdb5dc52b12b478b449011973917","go_version":"go1.20.14","os":"linux","arch":"amd64","compiler":"gc","message":"Version info"}
{"time":"2024-05-20T06:18:51.439357Z","level":"info","serverID":"68554aa1","mongosyncID":"coordinator","cluster0":"mongodb://test:<REDACTED>@192.168.1.85:11021,192.168.1.85:11022,192.168.1.85:11023/<db>?replicaSet=dbrs&authMechanism=SCRAM-SHA-256&authSource=<db>","cluster1":"mongodb://root:<REDACTED>@192.168.142.179:27017,192.168.96.239:27017,192.168.18.4:27017/?replicaSet=rs0&authMechanism=SCRAM-SHA-256","verbosity":"DEBUG","logPath":"","port":27182,"pprofPort":0,"id":"coordinator","isMultipleReplicatorConfiguration":false,"retryDurationLimit":"10m0s","retryRandomly":false,"disableTelemetry":false,"featureFlags":{},"hiddenFlags":{"numParallelPartitions":4,"numInsertersPerPartition":4,"numEventApplierThreads":128,"sampleRate":0.04,"maxNumDocsToSamplePerPartition":10,"partitionSizeInBytes":419430400,"slowOperationWarningThreshold":"1m0s","transactionLifetimeLimit":"1m0s","crudEventBatchFlushInterval":"100ms","docBufferMaxNumDocs":10000,"docBufferFlushBytes":15728640,"numDocBuffersPerInserter":2,"partitionCursorBatchSize":10000,"mongosyncSleepBeforeInitDuration":"0s","ceaMaxMemoryGB":4,"sampleBatchSize":25000,"enableRestrictedSync":false,"orchestrator":"noOrchestrator","enableExtraCollectionCopyProgressFields":false,"loadLevelProvided":false},"message":"Mongosync Options"}
{"time":"2024-05-20T06:18:51.439713Z","level":"info","serverID":"68554aa1","mongosyncID":"coordinator","message":"Telemetry will be tracked."}
{"time":"2024-05-20T06:18:51.439750Z","level":"warn","serverID":"68554aa1","mongosyncID":"coordinator","totalRAMGB":8,"message":"At least 10 GB of RAM should be available to run mongosync."}
{"time":"2024-05-20T06:18:51.441791Z","level":"info","serverID":"68554aa1","mongosyncID":"coordinator","clusterType":"dst","operationDescription":"Pinging deployment at mongodb://test:<REDACTED>@192.168.1.85:11021,192.168.1.85:11022,192.168.1.85:11023/<db>?replicaSet=dbrs&authMechanism=SCRAM-SHA-256&authSource=<db> to establish initial connection.","attemptNumber":0,"durationSoFarSecs":0,"durationLimitSecs":600,"message":"Trying operation."}
{"time":"2024-05-20T06:19:11.442715Z","level":"debug","serverID":"68554aa1","mongosyncID":"coordinator","clusterType":"dst","operationDescription":"Pinging deployment at mongodb://test:<REDACTED>@192.168.1.85:11021,192.168.1.85:11022,192.168.1.85:11023/<db>?replicaSet=dbrs&authMechanism=SCRAM-SHA-256&authSource=<db> to establish initial connection.","attemptNumber":0,"durationSoFarSecs":0,"durationLimitSecs":600,"timeElapsed":"20.000969124s","description":"Pinging deployment at mongodb://test:<REDACTED>@192.168.1.85:11021,192.168.1.85:11022,192.168.1.85:11023/<db>?replicaSet=dbrs&authMechanism=SCRAM-SHA-256&authSource=<db> to establish initial connection.","message":"Long-running operation."}
{"time":"2024-05-20T06:19:21.442729Z","level":"warn","serverID":"68554aa1","mongosyncID":"coordinator","clusterType":"dst","operationDescription":"Pinging deployment at mongodb://test:<REDACTED>@192.168.1.85:11021,192.168.1.85:11022,192.168.1.85:11023/<db>?replicaSet=dbrs&authMechanism=SCRAM-SHA-256&authSource=<db> to establish initial connection.","attemptNumber":0,"durationSoFarSecs":0,"durationLimitSecs":600,"errorCode":0,"error":"server selection error: server selection timeout, current topology: { Type: ReplicaSetNoPrimary, Servers: [{ Addr: <db>_mongo1:27017, Type: Unknown, Last error: dial tcp 192.168.1.85:27017: i/o timeout }, { Addr: <db>_mongo2:27017, Type: Unknown, Last error: dial tcp 192.168.1.85:27017: i/o timeout }, { Addr: <db>_mongo3:27017, Type: Unknown, Last error: dial tcp 192.168.1.85:27017: i/o timeout }, ] }","transientReason":"error is a server selection error","message":"Waiting 1s to retry operation after transient error."}source 와 destination 모두 replicaset 으로 구성되어 있다.
그런데, source cluster 로 rs 의 모든 노드를 선언하면 timeout 에러가 발생하며 동기화가 수행되지 않았다.
구체적인 원인은 알 수 없어 primary 노드를 직접 연결(directConnection=true)해 동기화를 수행했다.
mongosync --cluster0 "mongodb://test:test@192.168.1.85:11021/<db>?replicaSet=dbrs&directConnection=true&authMechanism=SCRAM-SHA-256&authSource=<db>" --cluster1 "mongodb://<username>:<password>@192.168.142.179:27017,192.168.96.239:27017,192.168.18.4:27017/?replicaSet=rs0&authMechanism=SCRAM-SHA-256"mongosync 를 실행 후 동기화 준비가 되었으면 API 호출로 시작할 수 있다. API 명세는 mongosync API 엔드포인트 문서를 참고한다.
$ curl localhost:27182/api/v1/start -X POST --data '{ "source": "cluster0", "destination": "cluster1" }'
{"success":true}동기화를 완료하고 클러스터 간의 지속적인 동기화를 중지하려면 commit 엔드포인트를 호출해야한다.
그 전에 동기화를 커밋 할 준비가 되었는지 확인할 수 있다.
$ curl localhost:27182/api/v1/progress -XGET
{
"progress":{
"state":"RUNNING",
"canCommit":true,
"canWrite":false,
"info":"change event application",
"lagTimeSeconds":905,
"collectionCopy":{
"estimatedTotalBytes":94253596,
"estimatedCopiedBytes":94411731
},
"directionMapping":{
"Source":"cluster0: 192.168.1.85:11021",
"Destination":"cluster1: 192.168.142.179:27017,192.168.96.239:27017,192.168.18.4:27017"
},
"mongosyncID":"coordinator",
"coordinatorID":"coordinator"
}
}progress 엔드포인트가 "canCommit":true 을(를) 반환했는데, 이는 commit 요청을 성공적으로 실행할 수 있음을 의미한다.
$ curl localhost:27182/api/v1/commit -XPOST --data '{ }'
{"success":true}만약 다시 동기화를 시작하려는 경우 mongosync_reserved_for_internal_use 데이터베이스의 컬렉션을 삭제하여 동기화 상태를 초기화할 수 있다.
# source
use mongosync_reserved_for_internal_use
db.dropDatabase()
---
# destination
use mongosync_reserved_for_internal_use
db.dropDatabase()
use <db>
db.dropDatabase()마치며
인프라 이전 작업을 진행하면서 여러 문제가 발생했고, 너무 많은 삽질을 했다.
본 포스팅에서는 mongodb 마이그레이션에 대해서만 다루고 있지만, 그 외 여러 아쉬운점들도 많이 보였다.
추후 다른 문제들도 개선하고 그 내용을 다뤄볼 예정이다.
