스파크를 이용하여 스트리밍 데이터를 델타레이크로 저장할 때 체크포인트가 성능에 어떠한 영향을 미치는지 살펴보고, 이를 개선할 수 있는 멀티파트 체크포인트 기능에 대해 알아보도록 하자.
(아래의 실험 환경은 모두 마이크로 배치 간격이 1 분으로 설정되어 있다.)
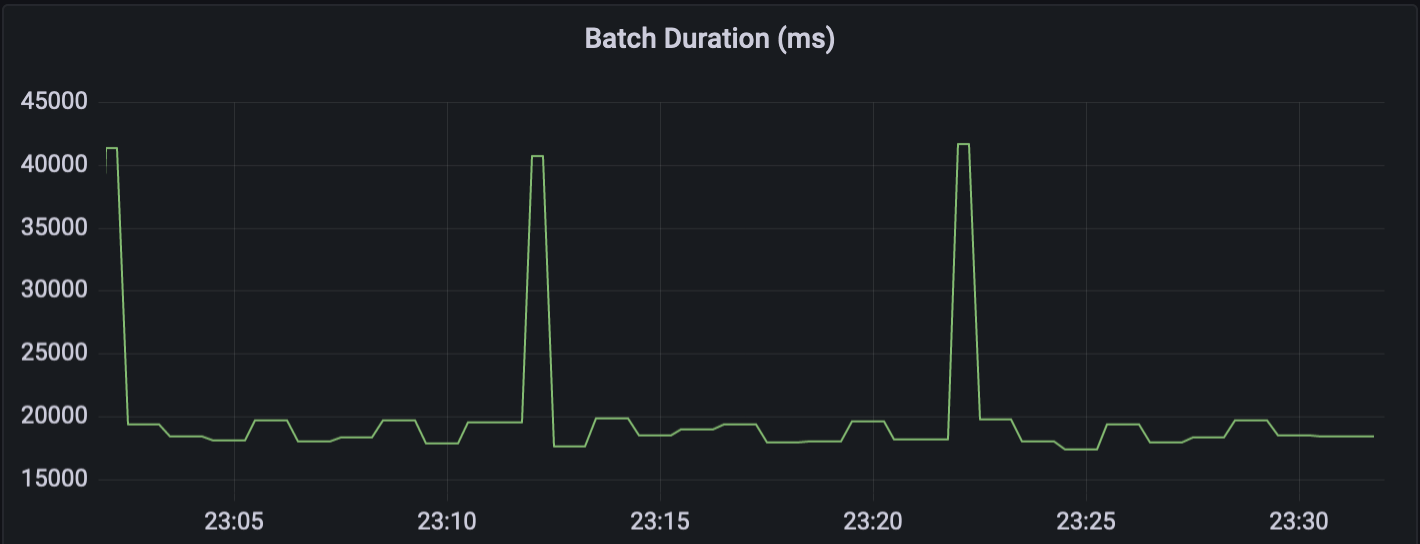
위의 그래프는 실험 환경에서 스파크 스트리밍의 마이크로 배치 처리시간을 시간순으로 보여주고 있다. 마이크로 배치에서는 특별한 작업없이 바로 (델타) 테이블에 저장하기 때문에 대부분의 처리시간은 저장하는데 소요된다. 그리고 중간에 반복적으로 한번씩 튀는 것은 델타레이크에서 10 번의 쓰기 작업마다 새로운 체크포인트 파일을 만들기 때문이다. (배치 간격이 1 분이기 때문에 대략 10 분에 한번씩 그래프가 튀는 것을 볼 수 있다.) 그럼 이제 스트리밍 데이터를 처리한 후, 테이블에 저장하는 과정을 자세히 분석해보도록 하자.
델타레이크에서는 테이블을 최신 상태로 유지하기 위해 쓰기 작업이 끝날 때마다 (델타로그) 스냅샷을 갱신한다. 이를 위해 마지막 체크포인트 파일과 이후의 로그 파일들을 이용하여 스냅샷에서 사용하는 (스파크) 데이터프레임을 만든다. 델타레이크는 체크포인트 파일을 위한 FileScanRDD 와 로그 파일들을 위한 FileScanRDD 를 각각 만들어서 파일들을 읽어들인 다음, 하나의 RDD 로 합친 후 설정된 값(기본값 50)으로 리파티셔닝(repartition)한다.
(델타로그도 빅데이터이기 때문에 병렬 처리가 중요하다.)
아래는 체크포인트 파일과 로그 파일들을 읽어서 리파티셔닝을 위한 셔플 쓰기(Shuffle Write)를 하는 스테이지를 보여주고 있다. 17 개의 태스크가 생성되었지만, 제대로 파일을 읽는 태스크는 6 번 (125MB), 13 번 (34MB), 그리고 16 번 (753KB) 밖에 없다. 왜 이런 상황이 벌어졌는지 자세히 살펴보자.
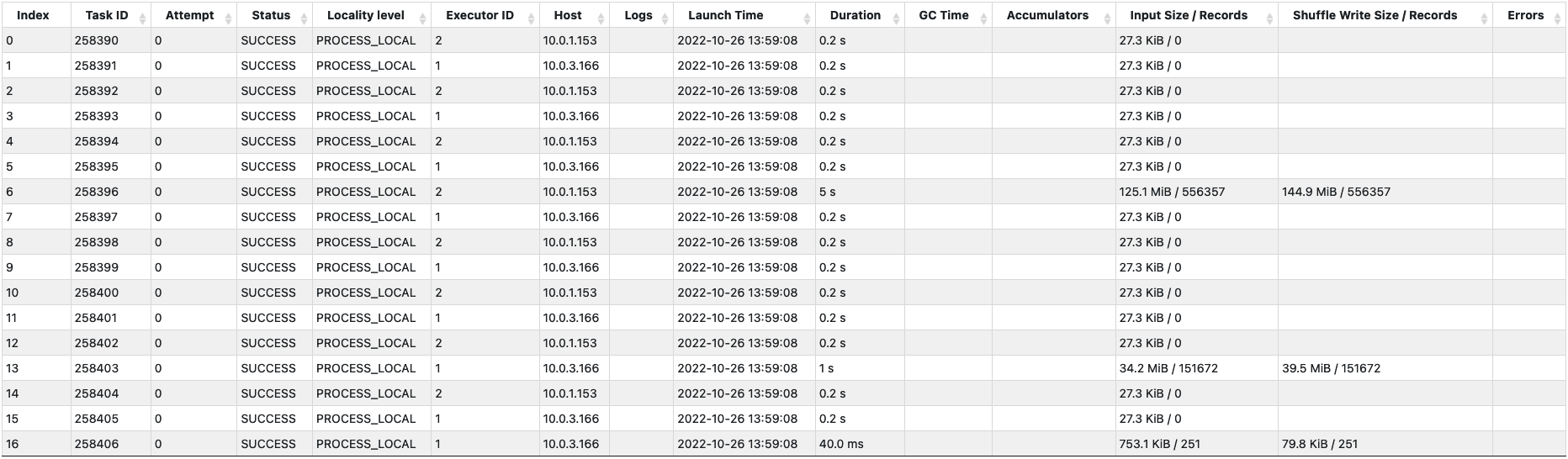
우선 왜 17 개의 태스크가 생성되었을까? 스파크에서는 FileScanRDD 가 사용할 파티션을 만들 때, 하나의 파티션에서 읽을 수 있는 파일의 최대 크기를 정하는데 이 때 몇 가지 변수들(maxPartitionBytes, openCostInBytes, ...)과 전체 코어 개수를 사용한다. 해당 실험 환경에서는 이렇게 계산된 최대 파일 크기가 대략 10MB 였고, 그래서 160MB 정도 크기인 체크포인트 파일을 분할하여 읽기 위한 16 개의 파티션과 1 개의 로그 파일을 읽기 위한 1 개의 파티션이 만들어져서 총 17 개의 태스크가 생성되었다.
(마지막 체크포인트 이후 하나의 로그만 생성되었기 때문에 1 개의 로그 파일만 추가로 읽으면 되었다.)
그런데 왜 하나의 로그 파일을 읽는 태스크를 제외하고, 두 개의 태스크만 체크포인트 파일을 읽었을까? 이유는 파케이(Parquet) 포맷을 사용하는 체크포인트 파일의 블럭 크기가 128MB 이기 때문에 2 개의 블럭(125MB, 34MB)만을 가지고 있었고, 그래서 각 블럭의 중간 위치를 포함하는 태스크인 6 번과 13 번 태스크만이 해당 블럭을 읽었기 때문이다.
이러한 이유로 해당 스테이지에서는 17 개의 태스크를 사용했지만 하나의 태스크가 125MB 를 읽으면서 5 초의 시간이 소요되었다.
아래는 50 개의 태스크에서 셔플 읽기(Shuffle Read)를 하는 스테이지를 보여주고 있고, 이후 델타로그와 관련된 연산은 해당 RDD 에서 50 개의 파티션으로 나누어져서 처리된다.

이러한 과정을 통해 일반적인 쓰기 작업은 위의 그래프에서 보면 대략 20 초 정도 걸리는 것을 알 수 있다. 그리고 지금부터는 10 번의 쓰기 작업마다 처리시간이 40 초 이상 걸리는 이유인, 주기적으로 새로운 체크포인트 파일을 만드는 부분에 대해 자세히 살펴보도록 하자.
새로운 체크포인트 파일을 만드는 부분에서 성능적으로 가장 문제가 되는 것은 체크포인트가 하나의 파일로 만들어진다는 점이다. 위에서 설명한 것처럼 하나의 파케이 파일을 읽는 작업은 여러 태스크에서 서로 다른 블럭을 동시에 읽어서 처리시간을 줄일 수 있지만, 하나의 파케이 파일에 쓰는 작업은 하나의 태스크에서만 처리할 수 있기 때문이다.
아래는 50 개의 파티션으로 나뉘어 처리되던 RDD 를 하나의 파티션을 가지는 RDD 로 합치기 위해 셔플 쓰기를 하는 스테이지를 보여주고 있다.
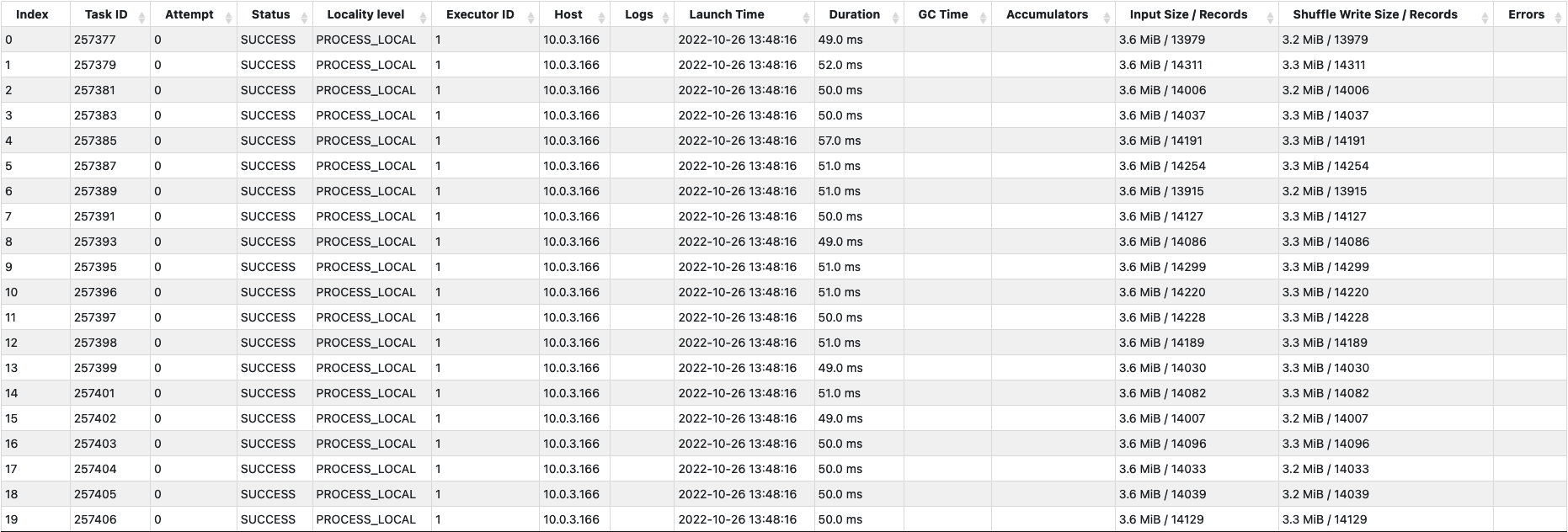
그리고 하나의 태스크에서 셔플 읽기를 하고, 하나의 체크포인트 파일을 만드는 스테이지는 아래와 같다. 아직 체크포인트 파일의 크기가 163MB 밖에 되지 않지만 20 초나 걸리는 것을 볼 수 있다. 이 처리시간은 로그가 쌓이면 쌓일수록 체크포인트 파일의 크기가 커져서 점점 더 길어질 수 밖에 없기 때문에 실시간으로 스트리밍 데이터를 저장하기 위해서는 무언가 해결책이 필요해 보인다.

이를 해결하기 위해 나온 것이 바로 멀티파트 체크포인트 기능이다. 기능 자체는 단순하다. 기존에 하나의 파일로 관리되던 체크포인트를 여러 파일로 분할해서 관리하자는 것이다. 사용법도 매우 간단한데, 관련 옵션(spark.delta.checkpoint.partSize)을 이용해서 하나의 체크포인트 파일에 담을 수 있는 최대 로그 개수를 지정하면 된다.
그럼 이제 멀티파트 체크포인트 기능을 사용했을 때 어느 정도의 성능이 개선되는지 살펴보자. 실험 환경에서는 최대 로그 개수를 10 만개로 지정하였고, 체크포인트 파일 1 개의 크기는 대략 20MB 정도까지다. 체크포인트 파일을 읽는 부분과 쓰는 부분만 간단히 살펴보자.
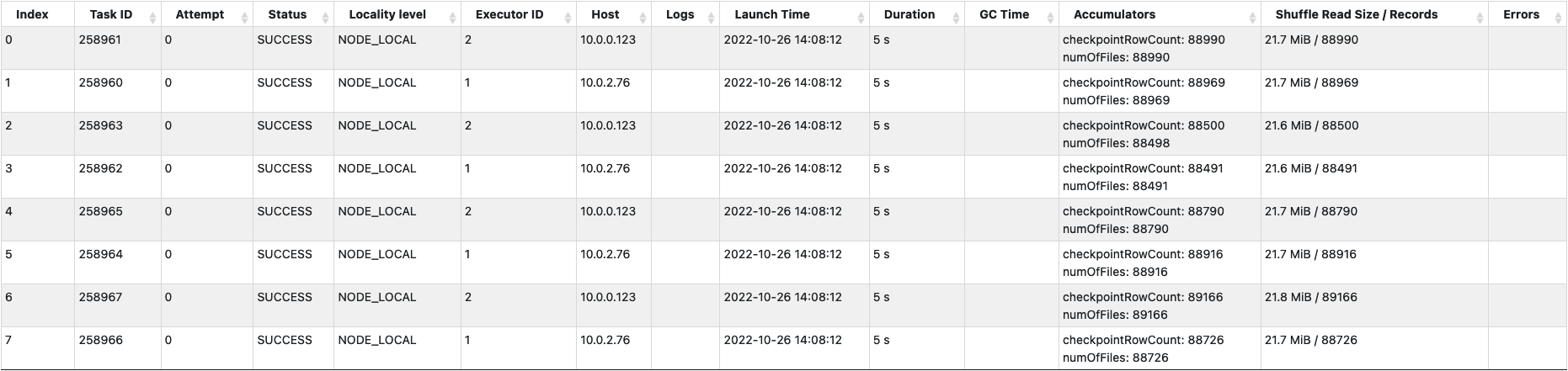
아래의 체크포인트 파일을 읽는 스테이지를 보면, 체크포인트 파일의 크기가 모두 합쳐서 160MB 정도이고 마지막 체크포인트 이후 4 개의 로그가 생성되었기 때문에 20 개의 태스크가 할당되었고, 160MB 정도의 체크포인트 파일이 8 개로 분할되어 있기 때문에 8 개의 태스크가 동시에 체크포인트 파일을 읽어들이는 것을 알 수 있다. 그래서 해당 스테이지는 대략 1 초 정도 밖에 걸리지 않는다.
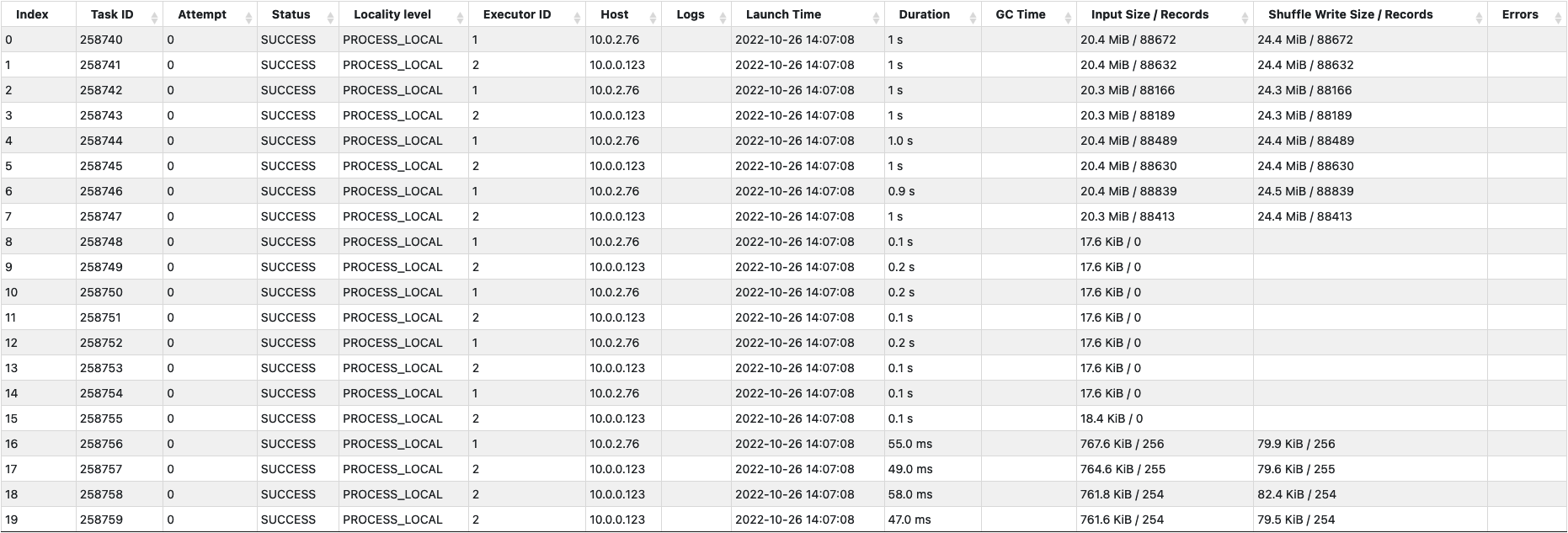
다음으로 체크포인트 파일을 쓰는 스테이지를 보면, 대략 70 만개 정도의 로그를 최대 10 만개씩 8 개의 파일로 분할해서 저장하기 위해 8 개의 태스크가 할당된 것을 볼 수 있다.
마지막으로 멀티파트 체크포인트 기능을 사용하는 경우 마이크로 배치 처리시간이 얼마나 개선되는지도 간단히 살펴보자.
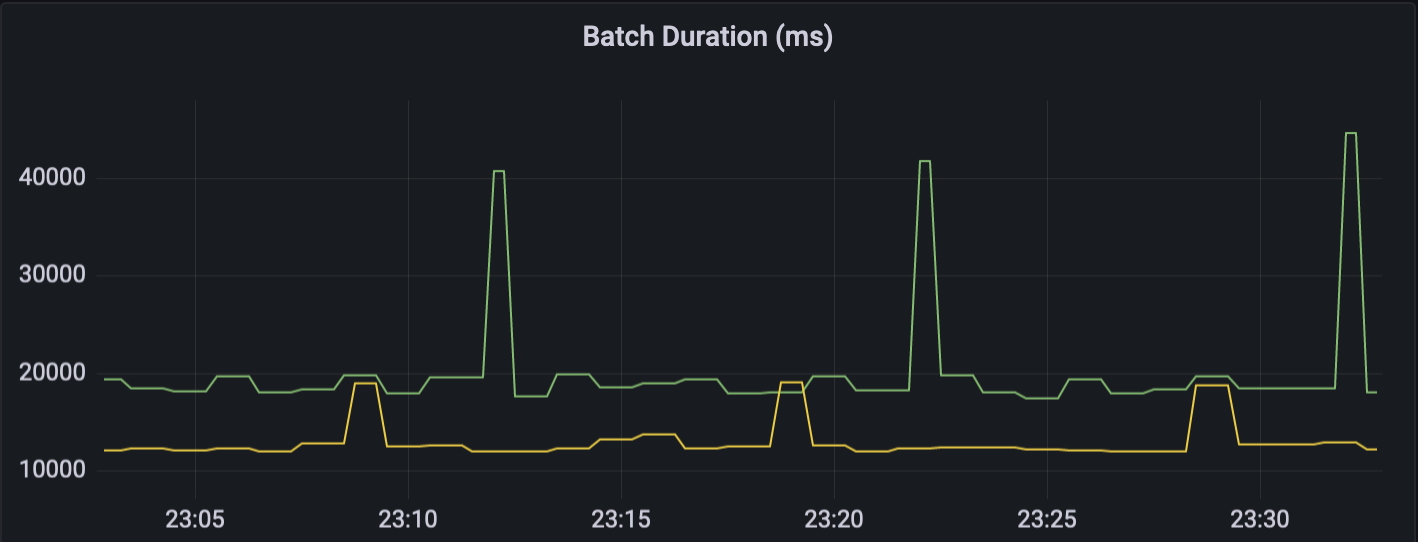
초록색은 하나의 체크포인트 파일을 사용한 경우이고, 노란색은 멀티파트 체크포인트 파일을 사용한 경우이다. 보시는 바와 같이 일반적인 쓰기 작업 시에도 체크포인트 파일을 읽는 속도가 빨라져서 7~8 초 정도 성능이 개선되었고, 새로운 체크포인트 파일을 만드는 부분에서는 20 초 이상 성능이 개선된 것을 볼 수 있다.
지금까지 멀티파트 체크포인트 기능을 사용하면 성능적으로 어떤 부분이 어느 정도 개선될 수 있는지 살펴보았다. 실시간 스트리밍처럼 잦은 쓰기 작업이 필요한 서비스에서는 적절한 로그 보관(retention) 정책과 함께 잘 활용하면 좋은 성능을 기대할 수 있을 것이다.