에 이어 설명을 시작하려고 한다.
1-1. 프로세스란?
컴퓨터에서 실행되는 프로그램의 인스턴스,
프로세스는 실행 중인 프로그램의 코드, 현재 상태, 메모리, CPU 사용량 등을 포함하는 시스템 리소스의 집합이다!
1-2. 프로세스란 무엇으로 구성되어 있나?
(1) 텍스트 섹션 (Text Segment)
- 프로세스의 실행 코드들로 구성됨
(2) 데이터 섹션 (Data Segment)
- 전역 및 정적 변수와 같은 초기화된 데이터를 저장
(3) 힙 (Heap)
- 동적 메모리 할당을 위한 영역으로, 프로그램이 실행되는 동안 크기가 변할 수 있다.
주로 동적배열(파이썬의 list 같은 것), 동적 할당된 객체(class)처럼 가변적인 데이터 구조를 가진 것들이 힙에 저장된다.동적 메모리 할당??????
우리가 어떤 프로그램를 돌릴때, 프로그램이 계산해야 할 리소스들을 메모리에 저장한다.
그때, 필요 이상의 메모리를 사용(memory leak)하는 것을 방지하지 위해!
"동적"으로 프로세스에게 메모리를 할당하는 것을 말한다.
할당 (Allocation): 필요한 메모리 요청하기. (운영체제 -> 프로그램)
해제 (Deallocation) : 필요없는 메모리 돌려주기.(프로그램 -> 운영체제)
그럼 누가 그런걸 해주냐?
C언어의 경우 malloc(할당), free(해체)를 통해서 할 수 있음!
python 같은 고수준의 언어에서는 가비지 콜렉터가 알아서 할당하고 해제한다.
더 자세한 내용은 메모리편에서 서술하겠다!
(4) 스택 (Stack): 함수 호출과 지역 변수에 사용되는 메모리 영역으로, LIFO (Last-In, First-Out) 구조를 가집니다.
LIFO?
LIFO(Last in First out) : 가장 최근에 들어온 요소가 가장 먼저 나가는 구조!
그림 한방으로 바로 이해할 수 있다.
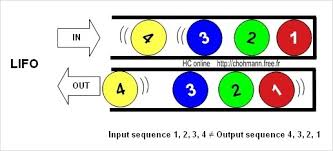
그럼 왜 LIFO를 쓰느냐????
프로세스의 메모리 공간안에 있는 "스택"은 일반적으로 함수 호출과 관련되어 있다.
def main():
member_A = 1
def fun1():
member_B =1
def fun2():
def fun3():예를 들어 위의 함수를 실행한다고 해보자.
그렇다면
D의 결과의 반환 주소를 C에,
C의 결과의 반환 주소를 B에,
B의 결과의 반환 주소를 A에
가져다 줘야한다.
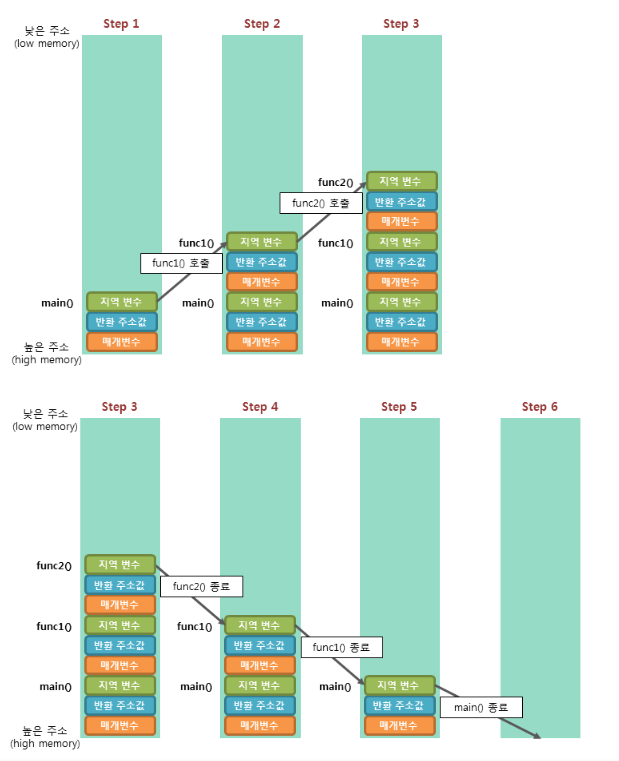 출처 : TCP School(http://www.tcpschool.com/c/c_memory_stackframe)
출처 : TCP School(http://www.tcpschool.com/c/c_memory_stackframe)
그렇기에 위의 구슬처럼 4 다음 3, 3 다음 2, 2 다음 1의 구조를 가장 빠르게 가질 수 있는 스택 구조를 사용한다! 라고 개인적으로 생각한다 ..
(메모리에서 낮은 주소와 높은 주소, 스택 포인터 등 다양한 것들이 있지만 그건 메모리 정리편에서 다루도록 하자!)
(4) 프로세스 제어 블록 (Process Control Block, PCB):
-
프로세스 식별자 (Process ID, PID): 프로세스를 고유하게 식별하기 위한 번호입니다.
-
프로세스 상태: 프로세스의 현재 상태를 나타냅니다 (예: 준비, 대기, 실행 중 등).
-
프로그램 카운터: 프로세스가 다음에 실행할 명령어의 주소를 저장합니다.
-
CPU 레지스터 정보: 프로세스가 실행되는 도중에 CPU 레지스터에 저장된 값을 보관합니다. 컨텍스트 스위칭 시 이 정보를 활용하여 프로세스의 실행 상태를 저장하고 복원합니다.
-
CPU 스케줄링 정보: 프로세스의 우선순위, 스케줄링 큐에 대한 포인터 등 스케줄링에 필요한 정보를 포함합니다.
-
메모리 관리 정보: 프로세스가 사용하는 메모리 공간에 대한 정보, 페이지 테이블 또는 세그먼트 테이블의 위치 등을 저장합니다.
-
입출력 상태 정보: 프로세스에 의해 열린 파일 목록, 사용 중인 입출력 장치 등의 정보를 포함합니다.
-
어카운팅 정보: 프로세스의 CPU 사용 시간, 실행된 명령어 수, 생성 시간 등과 같은 통계 정보를 포함할 수 있습니다.
등의 정보를 저장한다! cpu 스케줄링 과 레지스터 입출력 등은 cpu편에서 자세히 다루도록하자.
정리하면!
프로세스는 실행 중인 프로그램의 코드, 현재 상태, 메모리, CPU 사용량 등을 포함하는 시스템 리소스의 집합으로
- 텍스트 세그먼트 : 실행 코드 저장
- 데이터 세그먼트 : 정적, 전역 변수 저장
- 힙 : 가변적인 데이터 구조 저장
- 스택 : 지역 변수, 함수 호출 관련 저장
으로 구성 됨!
2-1. 스레드
스레드(thread)는 프로세스 내에서 실행되는 독립적인 제어 흐름이다.
하나의 프로세스 안에 여러개의 스레드가 있을 수 있으며, 프로세스는 항상 하나 이상의 스레드를 포함한다.
2-2. 스레드의 구성요소
(1) 프로그램 카운터 (Program Counter):
프로그램 카운터는 다음에 실행될 명령어의 주소를 저장한다.
각 스레드는 자신만의 프로그램 카운터(자신만의 text segment를 가르킨다!)를 가지고 있으므로, 독립적인 실행 경로를 가질 수 있다!
(2) 레지스터 집합 (Register Set):
CPU 레지스터의 현재 상태를 저장하고 있다.
이를 통해 스레드가 중단되었다가 다시 시작될 때 이전의 실행 상태를 복원할 수 있는 .. 데 .. CPU 레지스터에 관해서는 나중에 다시 포스팅하겠다!
(3) 스택 (Stack):
스레드의 스택은 지역 변수, 반환 주소, 매개변수 등을 저장하는 데 사용된다.
위에서 프로세스는 코드, 데이터, 힙, 스택을 가지고 있다고 말했다.
스레드는 프로세스 안에서 다른 프로세스들과 코드, 데이터, 힙을 공유한다.
하지만 스택만큼은 자신만의 스택을 가지고 있어서 함수 호출과 반환 과정을 독립적으로 관리할 수 있다!
(4) 상태 (State):
스레드의 상태는 실행 중, 실행 대기, 중지 등의 상태를 나타낸다.
스레드 스케줄러(운영체제에서 여러 스레드가 공평하게 실행되게 하는 구성요소!)는 이 상태 정보를 바탕으로 스레드의 실행을 관리한다.
일부 시스템에서는 스레드에 우선 순위를 할당하여 중요한 작업을 먼저 수행하게 할 수 있음!
(5) 스레드 로컬 스토리지 (Thread-Local Storage, TLS):
스레드 로컬 스토리지는 각 스레드가 자신만의 전용 데이터를 저장할 수 있는 메모리 영역이다. 이를 통해 스레드 간에 데이터를 격리할 수 있으며, 동기화 문제를 줄일 수 있다!
동기화 문제란?
한 프로세스 내에서 여러 스레드가 같은 자원을 공유하다보니, 자꾸만 문제가 생긴다
그래서
뮤택스(mutex) : 한번에 한 쓰레드만 접근 가능!
세마포어(semaphore) : 한번에 N개의 쓰레드만 접근 가능!
바리어(barrior) : N개의 스레드가 동시에 접근할 수 있도록 스레드에게 "기다렷!"이라고 하는것
읽기 쓰기 락(Read Write Lock) : 동시 읽기는 허용하되, 쓰기 작업은 동시에 하나의 스레드만 수행할 수 있음!
등 다양한 기법이 있다.
그래서 이걸 왜 설명하냐 ..
위 동기화 문제를 해결하기 위해서(한 프로세스 내에서 힙을 공유하기 때문에) 싸우지 말라고 그냥 스레드 별로 하나씩 주소를 주는 것이다.
3-1. 프로세스와 스레드의 차이
간단하게 생각하면 같은 집에 사냐, 옆집에 사냐 차이로 구분할 수 있다.
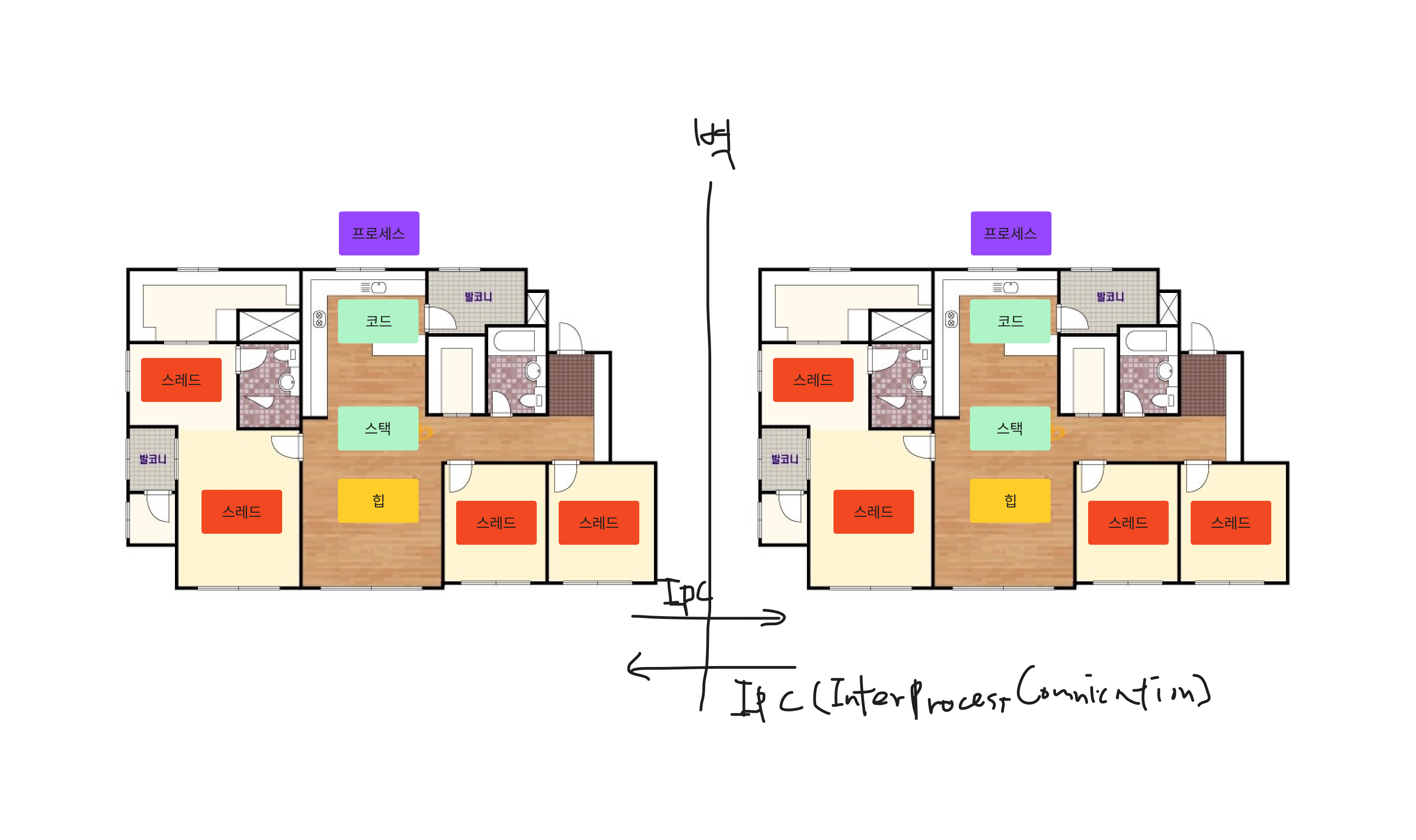
(1)메모리
- 프로세스 : 하나의 프로세스는 마당, 거실, 주방 (코드, 데이터, 힙, 스택)을 가짐!
- 스레드 : 하나의 스레드는 스택과 레지스터(프로그램 카운터 포함)를 가지고, 나머지 스레드와 코드, 데이터, 힙을 공유한다!
(2) 다른 프로세스, 스레드와의 메모리 공유
-
프로세스 : 얘들은 서로 남남이다. 벽을 치고 살기 때문에(프로세스마다 독립적인 메모리 공간 보유) 옆집과 이야기 하려면 Inter Process Communication(IPC,(파이프, 메시지 큐, 공유 메모리,소켓 등))를 통해야 할 수 있다.
-
스레드 : 같은 프로세스 내의 스레드는 코드, 데이터, 힙 영역을 공유한다. 이로 인해 메모리 효율이 좋으며 스레드 간의 통신이 빠르다!.
(3) 생성 및 관리
- 프로세스 : 벽 짓고 집 짓고 하려면 할 게 많다. (생성과 관리에 많은 리소스가 필요하다.)
하지만 옆집 무너져도 내 집은 상관없다.(다른 프로세스가 오류가 있어도 독립적으로 작동함) - 스레드 : 옆방이 무너지면 같은 집에 사는 사람들은 멘붕이 온다 (하나의 스레드가 오류가 나면 다른 스레드도 영향을 받음)
(4) 선택
- 프로세스: 집에 술 먹고 진상피우는 놈이 있을 경우(안정성 문제), 좀 혼자 살고 싶은 경우(독립성) 멀티 프로세스로 처리한다.
- 스레드: 집에서 다같이 모여서 프로젝트 진행해야 할 경우 (타이트하게 연결된 작업, 빠른 응답 시간이 필요한 경우, 리소스를 효율적으로 사용해야 할 때 사용)
멀티 프로세스와 멀티 스레드는 다음 시간에 이어서 진행해보자!!
