네트워크에 대해서 이것 저것 만지다 보면, UUID라는 단어를 듣게 된다.
구글링을 해보면, 대충 겹치지 않는 고유의 값라고 한다.
그당시에는 아하! 고유값이군! 끄덕끄덕 하고 바로 pass! 해버렸지만
실제로 구현하는 과정에 있어서 UUID를 쓰려니, 아무래도 막 쓰기에는 찜찜하다.
사용하는데에 있어 적어도 사용방법, 원리 정도는 알아야 하지 않을까?
라고 생각하여 구글링을 하다가 이 블로그에 온 당신을 위해서 나도 적어본다.
UUID
정의 (UUID란 무엇인가?)
범용 고유 식별자(汎用固有識別子, 영어: universally unique identifier, UUID)는 소프트웨어 구축에 쓰이는 식별자 표준으로, 개방 소프트웨어 재단(OSF)이 분산 컴퓨팅 환경(DCE)의 일부로 표준화하였다.
굳이 다 외울필요는 없이 UUID = 식별자 표준이군. 정도만 알면 될 것 같다.
이유 (왜 UUID가 필요한가?)
네트워크를 사용하다 보면 정말 정말 정말 많은 id, 고유 값이 쓰인다.
그런데 막상 id를 내가 지정하자니, 다른 사람이랑 겹칠수도 있을 것 같다.
게다가 적어도 직업으로서 컴퓨터를 만지는 사람들은 뭔가 겹치거나, 논리에 있어 오류가 생길것만 같은 상황을 극도로 싫어한다.
그래서 누구나 쓸 수 있는 규칙을 만들자!
(1) 어디서인가 값을 참조하지 않아도,
(2) 적어도 한참동안은 값이 겹칠일이 없으며,
(3) 어디서나 쉽게 고유값을 만들 수 있는 그런 규칙!
이 바로 UUID라고 할 수 있다.
물론 값이 정말 매우 극도로 우연이 한 10번 겹치면 같은 값이 만들어 질 수 있으나, 일반적으로는 UUID를 사용한 고유값이 서로 일치하는 일은 없다고 상정한다.
구조 (UUID는 어떤 구조로 이루어져 있나?)
550e8400-e29b-41d4-a716-446655440000
뭐 이런 구조로 이루어져 있다. 하나 하나 설명하자면,
우선 공간5개와 하이픈 4개로 이루어져 있으며, 8-4-4-4-12 의 구조를 가지고 있다.
그리고 공간 5개에 32개의 문자로 구성 되어 있다.(+ 하이픈 4개 = 총 36개)
또한 16 옥텟으로 이루어져 있는데(하나의 문자에 16진수를 사용),
16 옥텟(=1바이트=8비트) 은 16x8 = 128비트를 가진다!
그럼 1비트가 0 or 1 이니, 2의 128승인,
최대 340,282,366,920,938,463,463,374,607,431,768,211,456의 경우의 수를 가진다.
그렇다. 겹치려해도 겹칠수가 없다.
하지만 모든 128비트가 난수처럼 들어가는 것이 아니고, 어떠한 규칙이 있다.
생성(UUID는 어떻게 생성하나?)
v 1
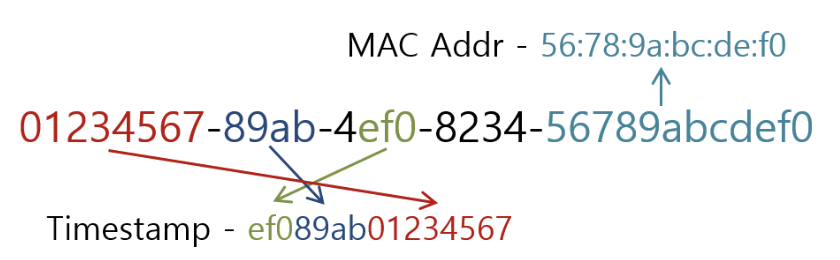
버전 1 은 위에 보는 것 처럼 Timestamp를 찢어서 넣고,
뒤에 MAC 주소를 넣는다.
사실 위의 그림은 uuid v1을 설명하기에는 틀린부분이 있습니다.
그러나 설명이 너무 잘되어 있어서 가져왔습니다.
개념만 이해하고 넘어가시죠!

임의로 생성한 uuid v1이다.
보면 기본적으로 uuid가 비슷하다.
67 ~~ d5 ~~ 11ed ~~ 466(이부분은 내 mac주소이니 당연히 모든 실행에서 같다)
아니 uuid는 고유하다면서 이렇게 비슷하면 어떠케요???
위의 실행은 같은 시간에, 같은 애플리케이션에서 실행한 결과여서 비슷하게 나올 수 밖에 없다.
또한 뒤의 MAC주소도 다른 사람에게 드러나게 된다.(위험해요)
v4
v4 UUID는 완전 Random을 기반으로 UUID를 생성한다.
UUID의 Version(중간에 4가 반복된 자리가 version이다), Variant Field를 제외하고 모두 모두 랜덤이다.
v5
v5 UUID는 SHA-1 Hashing을 기반으로 UUID를 생성한다. v5 UUID를 생성하기 위해서는 Namespace와 Name값이 필요하다. Namespace와 Name값이 동일하다면 동일한 UUID가 생성된다. Namespace 값은 아래와 같이 정의되어 있으며, 정의된 값 말고 다른 값도 이용할 수 있다.
NAMESPACE_DNS : Name이 Domain 이름이다.
NAMESPACE_URL : Name이 URL이다.
NAMESPACE_OID : Name이 OID (Object Identitfier)이다.
NAMESPACE_X500 : Name이 LDAP Protocol의 Directory Name이다.
v2
v2 UUID는 v1 UUID와 동일하게 Timestamp 기반이지만 Timestamp Filed가 줄어들고 Domain/Identifier Field가 추가되었다. v2 UUID의 Timestamp 값은 약 7분 정도 지나야 1씩 증가한다. v2 UUID는 일반적인 UUID가 아닌 DCE (Distributed Computing Environment) 환경을 위한 UUID이기 때문에 잘 이용되지 않는다.
v3
v5 UUID는 v3 UUID와 동일하지만 MD5 Hahsing Algorithm을 이용하여 Hashing을 수행한다는 점이 다르다. MD5 Hashing Algorithm은 현재 보안적 취약점을 이용해서 Reverse Hashing이 쉽게 가능한 상태이다. 따라서 현재 v3 UUID 보다는 v5 UUID를 이용하는 것을 권장하고 있다.
사용처(그래서 UUID를 어디에 쓰는데?)
주로 DB에서 PK 값으로 쓰이고는 한다.
일반적으로 모든 uuid 값은 서로 다르다고 상정하기 때문에 PK 값으로 쓰기 아주 매우 적절하다.
다만 장점이 있으면, 단점도 존재한다.
- 일단 만들어야함.
그냥 sequential 하게 id 떄려버리면 ez하다.
그런데 uuid는 또 규칙을 거쳐 만들어야 하니, 또 리소스가 사용이 된다. - uuid는 같은 record의 내용과 상관이 없음.
당연히 상관이 없게 만들었으니, 상관이 없다.
장점이자, 단점인 경우이다.
상관이 없으므로 보안적인 부분에 대해서 안전하지만, 상관이 없으므로 내용을 추측하거나, 정렬 시 에 다른 값을 참조해야한다. - 공간을 많이 먹음
보통 int 계열의 id들은 4Byte를 사용하지만, uuid는 어떤 버전을 사용하든 16Byte를 잡아먹어서 하나당 4배나 더 공간을 잡아먹는다. 매우 끔찍함.
char(32) 를 binary(16)으로 바꾸어 저장하면 2배 줄일 수 있지만, 사람이 인식하려면 또 변환해줘야한다. 이것도 다 일이다 일. - DB indexing 떄 자원 소모
uuid가 랜덤으로 생성되는 값이라, sequential 한 값에서 빠른 DB들은 성능저하를 겪게된다.
다음에 누가 uuid를 물어보면 위 내용을 잘 기억해두었다가 사용하도록 하자!
참조:
https://ko.wikipedia.org/wiki/%EB%B2%94%EC%9A%A9_%EA%B3%A0%EC%9C%A0_%EC%8B%9D%EB%B3%84%EC%9E%90
https://ssup2.github.io/theory_analysis/UUID/
https://ssup2.github.io/theory_analysis/UUID/
