1바이트는 뭘까..
나는 파이썬으로 주로 개발을 하다보니, 사실 메모리나 기본적인 CS 밑단까지 생각이 미치지 않았다.
그냥 1기가 정도면 '음 데이터 양이 생각보다 너무 적은데 .. 더 늘려야하나?' 이정도?
그런데 BASE 64에 대해서 공부를 하다가 하다가 보니
- 1바이트는 뭔지,
- 왜 8비트인지,
- 왜 굳이 8비트여야하는지,
- 더 작거나 커질수 없는지
- 한글은?
궁금해졌다. 렛츠 고.
1. 1 바이트가 뭘까?
컴퓨터의 저장 단위로, 컴퓨터가 처리할 수 있는 최소 처리 단위이다.
이는 8비트 즉, 8개의 비트(11010100)로 구성되어 있다.
컴퓨터에서 연산을 할때, 주로 0 혹은 1로 이라는 신호를 받아서 처리를 하게 되는데, 이 0 혹은 1를 8개를 모아서 1바이트를 구성하게 된다.
2. 근데 왜 1바이트는 8비트인가요??
사실 1바이트가 8비트로 표준화 되기 전까지는 6비트, 7비트, 8비트, 9비트 등 사용 목적이나 제조사, 컴퓨터마다 각기 다른 바이트 크기를 가지고 있었다고 한다.
1바이트가 8비트로 표준화된 이유는 다음과 같다. 내 생각이 포함되어 있다.
(1) 이진 연산에 최적화된 2의 3제곱이다. 따라서 메모리 누수가 생길 부분을 최대한으로 줄일 수 있다.(현재 AI의 모델에서 batch size가 2의 제곱 중 하나를 선택하는 것 처럼)
(2) ASCII 코드를 사용하기 좋다.
ASCII 코드란?
영어의 대문자, 소문자, 특수 문자등 다양한 입력을 7비트로 표현할 수 있는 코드!
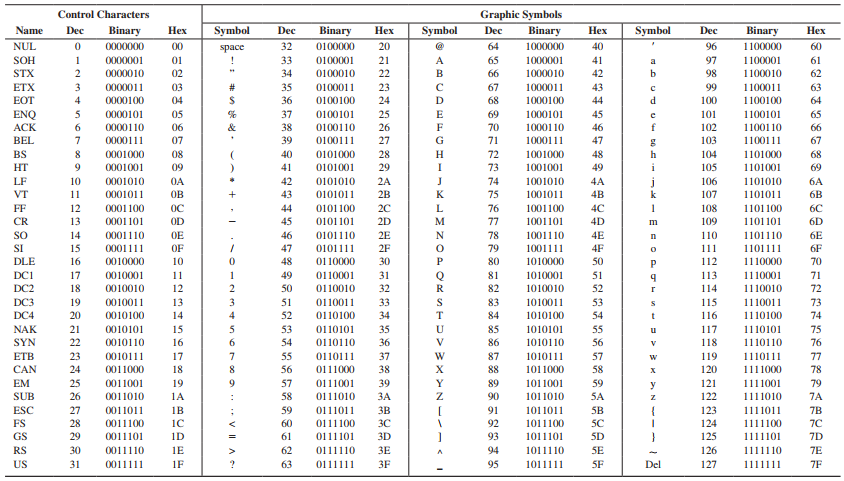
그런데, 잠시만.
아니 7비트이면 항상 1개의 비트가 남는게 아닌가요? 라고 생각할 수 있다.
8개의 비트 중 앞의 7개의 비트를 ASCII 코드로 채우고, 1개의 비트를 패리티비트(Parity Bit)로 채운다.
2가지의 패리티 비트가 있는데,
짝수 패리티 : 1의 갯수가 짝수라면 패리티 비트가 1, 홀수라면 0
짝수 패리티 : 1의 갯수가 짝수라면 패리티 비트가 0, 홀수라면 1
이걸 왜, 어떻게 쓰냐면,
데이터 전송시 처음에 짝수 패리티를 사용할지, 홀수 패리티를 사용할 지 미리 규약을 정해 놓고(보통 짝수 패리티로 고정, 동적으로 바꾸어야 할 경우 Header에 포함시켜서 표기할 수 있음) 통신을 하여, 데이터를 받는 입장에서 패리티비트를 통해 검증을 한다.
검증 결과가 잘못되었을 경우, 데이터가 잘못되었다는 신호를 내뱉는다.
아무튼!
이야기가 조금 새어나갔지만, 8비트는 ASCII를 사용하기 좋다!
위의 두가지 이유로 8비트를 쓰는 것 같다.
3. 더 작거나 커질 수 있나요?
물론이다.
#define MAKEBYTE(hi, lo) ((unsigned char)0xF0 & (hi << 4)) | ((unsigned char)0x0F & (lo))
#define HIBYTE(w) ((unsigned char)0xF0 & w) >> 4
#define LOBYTE(w) ((unsigned char)0x0F & w);
unsigned char cSum = 0;
//cSum = sTemp[0] | sTemp[1] << 4;
cSum = MAKEBYTE(sTemp[0], sTemp[1]);
sTemp[2] = HIBYTE(cSum);
sTemp[3] = LOBYTE(cSum);해당 코드를 보면,
4비트로 잘라서 사용하는 것을 볼 수 있다.
4. 아니 그럼 한글은요? 중국어는요? 일본어는요?
그럴줄알고, 유니코드(unicode) 등장!
이번에는 2바이트를 써서 2**16 이니, 65536개의 문자를 표현할 수 있게 되었다.
현재는 4바이트까지 써서, 아랍어니, 케냐어니, 이모티콘이니 다 표현 할 수 있다.
저는 영어만 쓸껀데요.. 그럼 굳이 하나에 4바이트까지 쓸 이유가 있으까여?
그럴 줄 알고! UTF-8 등장!
UTF-8 가변길이 인코딩을 사용한다.
영어의 경우 1바이트만, 라인 문자, 기타문자의 경우 2바이트만 ..
이렇게 여러가지의 문자를 인식하고, 그에 맞게 인코딩을 해서 메모리를 효율적으로 사용한다.
예를 들면,
- ASCII 문자 (U+0000 ~ U+007F): 1바이트
예: 'A' → 0x41- 라틴 문자와 기타 문자 (U+0080 ~ U+07FF): 2바이트
예: '©' (저작권 기호, U+00A9) → 0xC2 0xA9- 기본 다국어 평면의 문자 (U+0800 ~ U+FFFF): 3바이트
예: '한' (U+D55C) → 0xED 0x95 0x9C- 다른 평면의 문자 (U+010000 ~ U+10FFFF): 4바이트
예: '😀' (웃는 얼굴, U+1F600) → 0xF0 0x9F 0x98 0x80
이런식으로 변환해서 사용하게 된다.
그래서 우리가 excel이나 csv를 사용할때 제대로 인코딩을 안해주면, 맨날 "궳벍혻힏" 같은 단어가 나오는 것이다!
다음 글은 main 주제인 base 64를 알아보도록 하잣!
