DOM은 뭘까?
Document Object Model의 약자로 문서 객체 모델을 뜻한다.
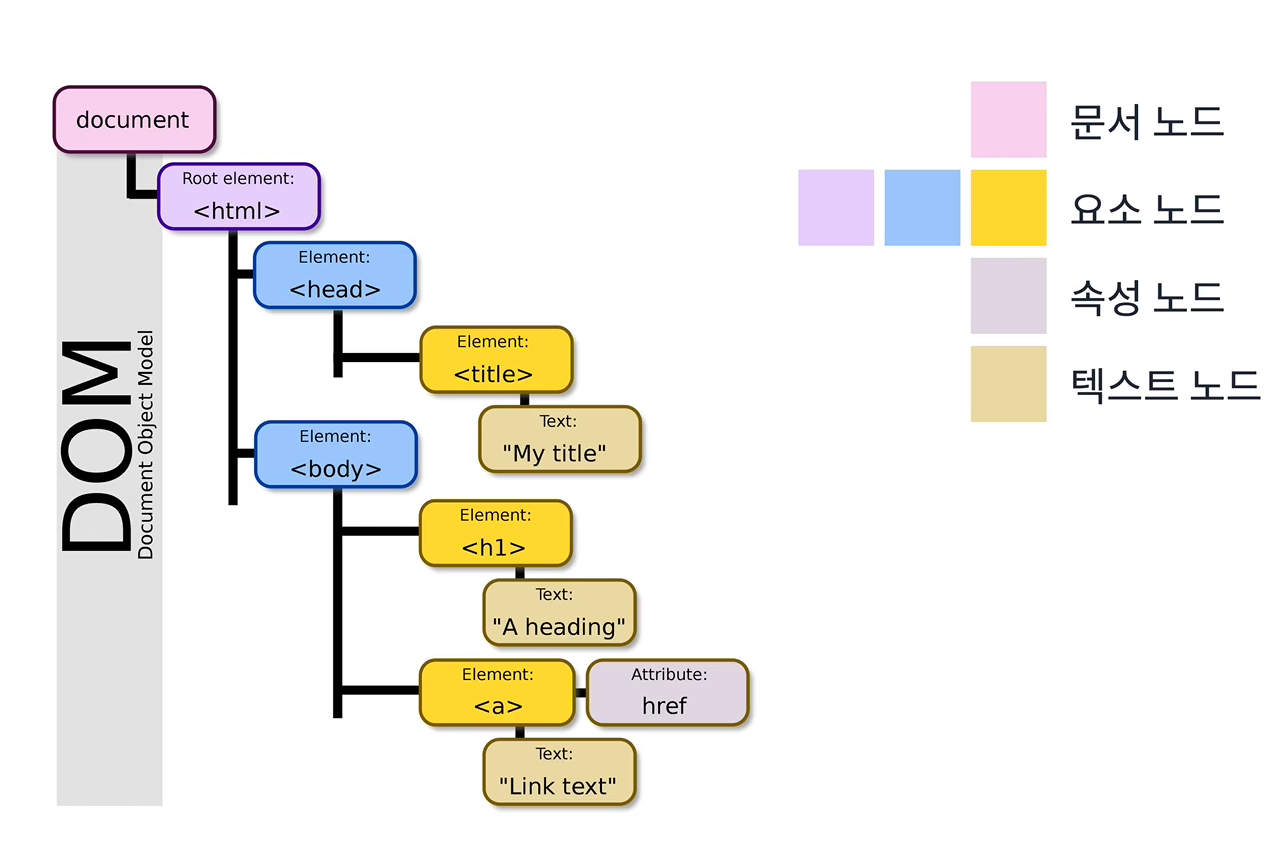
그럼 이 모델이란게 도대체 뭘까?
=> 모델이란 현실에 있는 것을 추상화한 것을 지칭한다.
따라서 DOM은 HTML 문서에 있는 내용을 추상화(모델링)하여 객체로 만든 것이다.
DOM의 각 요소는 key와 value로 이루어져 있다. 웹 브라우저 UI의 상태, 기능, 속성들을 객체로 만든 것이라 할 수 있다.
DOM은 왜 만들어졌나
-
JavaScript가 탄생하면서 동시에 만들어졌다.
- HTML 문서와 상호작용하여 form 태그의 유효성 검사 등에 처음에 사용되었다.
- 초창기에는 접근 가능한 태그가 많지 않았다.
-
표준안은 1998년에 만들어졌고 지금까지 범용화되기까지 오랜 시간이 걸렸다.
-
현재는 HTML 문서를 직접 수정이 가능할 정도로 발전했다.
DOM에서 원하는 태그를 찾는 법
DOM Tree 순회는 PreOrder(전위 순회)로 이루어진다.
document 노드에서부터 단계적으로 찾아나간다.
DOM 트리 렌더링
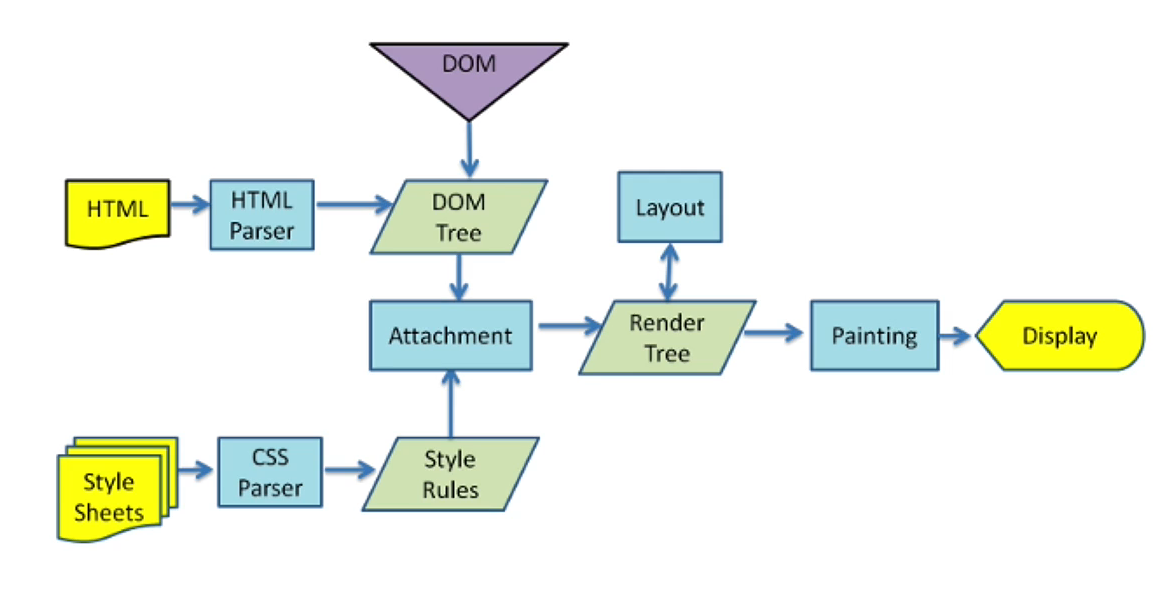
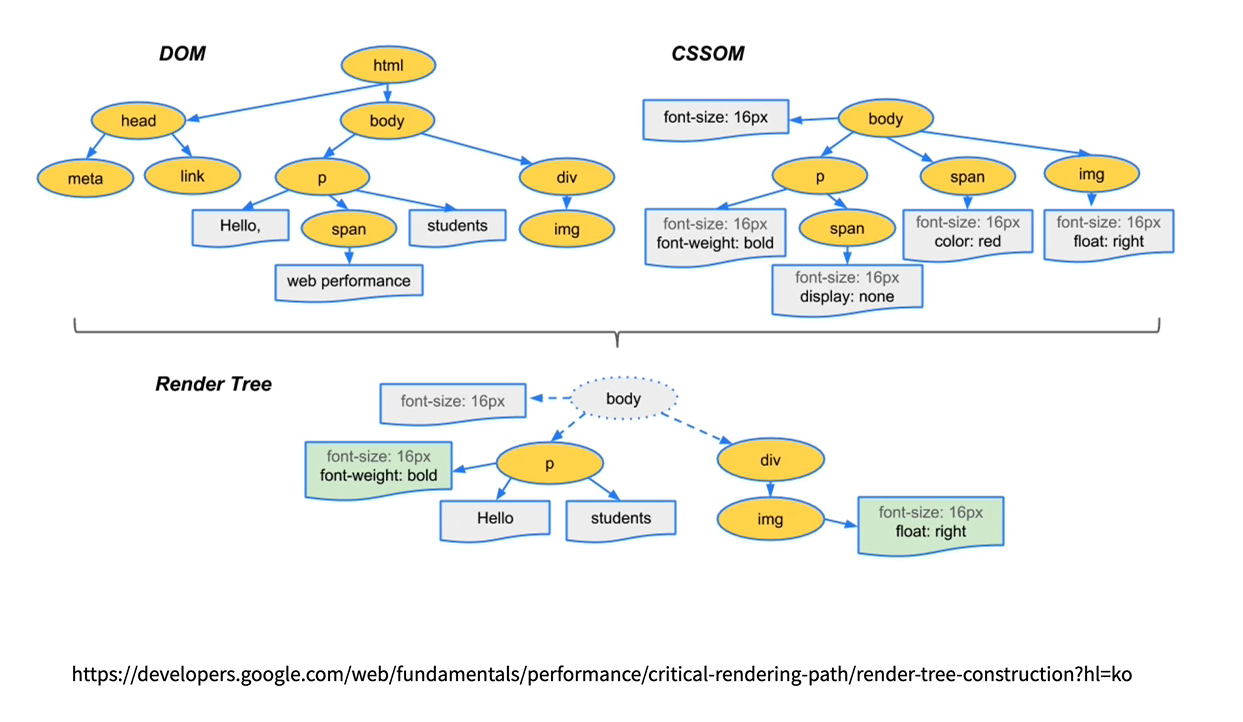
-
브라우저는 HTML을 읽고 파싱(Parsing)하여 DOM 트리를 구성한다.
-
이어 Style Sheet를 읽고 파싱하여 Style Rule(CSSOM 트리)을 만들어 DOM 트리에 입힌다. (Attachment)
-
Layout 또는 Reflow 과정을 통해 DOM 노드의 위치를 정해 Render Tree를 생성한다.
-
Render Tree를 바탕으로 실제 브라우저에 요소들을 그린다. (Painting)
DOM에서 요소를 선택하는 법
-
getElementById
DOM Tree에서 요소 노드를 id로 찾는다. 제일 먼저 찾은 요소 하나만 반환한다.
-
getElementsByClassName
DOM Tree에서 요소 노드를 class로 찾는다. 일치하는 모든 요소를 반환한다.
-
getElementsByTagName
DOM Tree에서 요소 노드를 tag로 찾는다. 일치하는 모든 요소를 반환한다.
-
querySelector
DOM Tree에서 요소 노드를 CSS 선택자(selector) 문법으로 찾는다. 제일 먼저 찾은 요소 하나만 반환한다.
-
querySelectorAll
DOM Tree에서 요소 노드를 CSS 선택자(selector) 문법으로 찾는다. 일치하는 모든 요소를 반환한다.
-
window.[id]
id가 있는 요소는 window 객체를 통해 찾을 수 있다. 여러 개라면 리스트로 반환된다. (
처음 알았다)
DOM 요소를 선택했으니 이제 해당 요소를 탐색하는 법을 알아보자.
DOM 요소 내 노드를 탐색하는 법
-
parentNode
선택한 요소 노드의 부모 노드를 불러온다. document의 부모 노드는 null이다.
-
firstElementNode
선택한 요소 노드의 자식 요소 노드 중 첫 번째 것을 불러온다. 없을 경우 null을 반환한다. 마지막 자식 요소 노드를 불러오는 lastElementNode도 있다.
-
children
선택한 요소 노드의 모든 자식 요소 노드를 불러온다. 없을 경우 빈 배열을 반환한다.
-
nextElementSibling
선택한 요소 노드의 다음 형제 요소 노드를 불러온다. 없을 경우 null을 반환한다.
-
previousElementSibling
선택한 요소 노드의 이전 형제 요소 노드를 불러온다. 없을 경우 null을 반환한다.
DOM 요소을 선택하여 탐색해서 찾았으니 이제 조작해보자.
DOM 요소 조작하는 법
-
class 접근 : .className / .classList
선택한 요소 노드에서 className과 classList로 요소의 class 속성을 불러오고 변경 가능하다.
-
hasAttribute
선택한 요소 노드에서 해당 속성을 가지고 있는지 여부를 확인한다.
-
getAttribute
선택한 요소 노드에서 속성의 값을 반환한다. 없다면 null을 반환한다.
-
setAttribute
선택한 요소 노드에서 속성을 정의한다.
-
removeAttribute
선택한 요소 노드에서 속성을 제거한다.
-
textContent
선택한 요소 노드에서 텍스트 노드에 접근, 변경할 수 있다.
-
innerHTML
선택한 요소 노드에서 내부 HTML을 수정한다. XSS 위험이 있으므로 가급적 사용을 피해야 한다.
-
createElement
요소 노드를 생성할 수 있다. 생성한 요소는 appendChild로 요소 마지막에 추가가 가능하다.
-
removeChild
선택한 요소 노드 자식 노드 중 해당하는 요소를 제거한다.
😅 해당 내용은 공부하면서 정리한 글입니다. 틀린 부분이나 오해하고 있는 부분이 있다면 피드백 부탁드립니다.
