본 포스팅은 woohoo님의 블로그를 참조하여 만들었습니다.
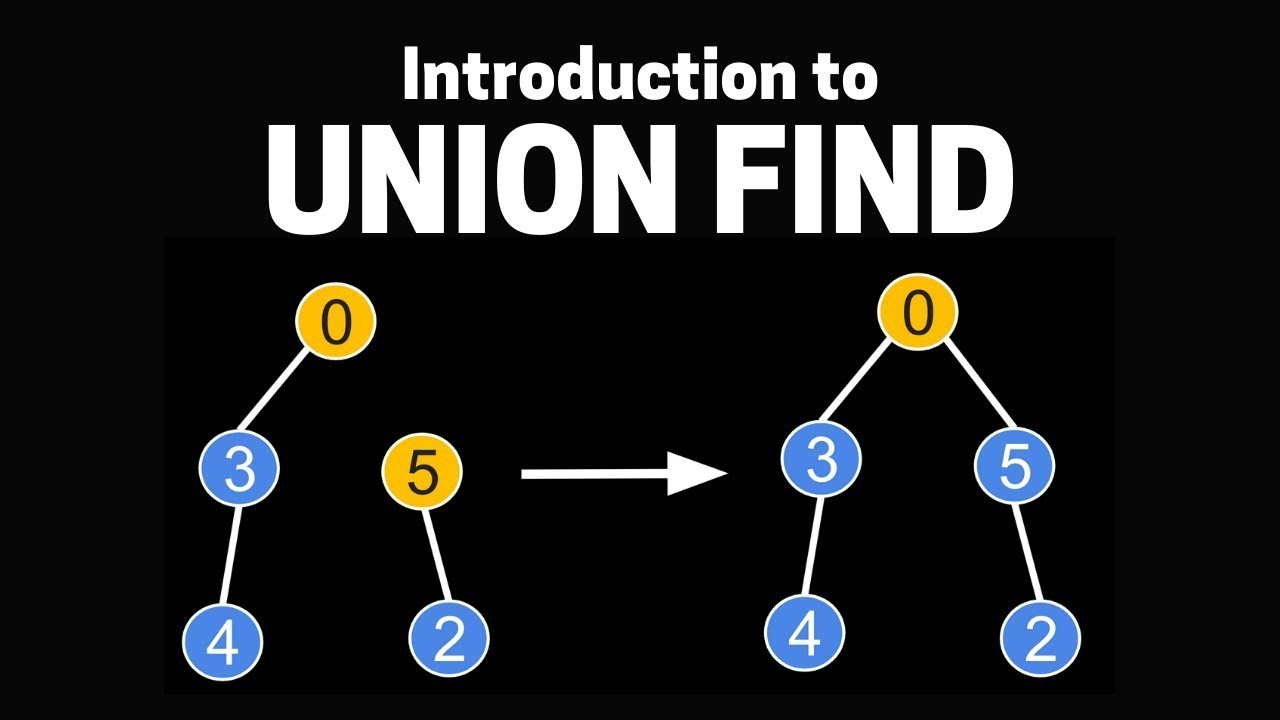
유니온 파인드란?
유니온 파인드 자료구조는 서로 다른 집합을 합치는 과정을 효율적으로 수행하기 위해서 존재한다.
백준의 집합의 표현을 무지성으로 풀면 아래와 같다.
import sys
input = sys.stdin.readline
def union(a,b,lst):
lst[a] = (lst[a]|lst[b])
lst[b] = (lst[a]|lst[b])
return lst
def find(a,b,lst):
if lst[a] == lst[b]:
return 'YES'
return 'NO'
if __name__ == '__main__':
n,m = map(int,input().split())
tmp = []
for i in range(n+1):
tmp.append(set({i}))
for _ in range(m):
cmd,a,b = map(int,input().split())
print(tmp)
if cmd:
print(find(a,b,tmp))
else:
tmp = union(a,b,tmp)여기서 메모리 초과가 발생하는데 그 이유는
for i in range(n+1):
tmp.append(set({i}))n의 최대값은 백만이다.
그러면 집합을 백만개 생성해야 하는데 이 때문에 메모리 부하가 걸리는 것이다.
동작 과정
[1,2,3,4,5,6]의 집합 리스트에서
union(1,4)
union(2,3)
union(2,4)
union(5,6)
위와 같은 4가지 연산을 수행한다고 하자.
우리는 집합의 헤드를 기준으로 병합을 진행한다.
union(a,b)
- a의 루트 노드를 찾는다.
- b의 루트 노드를 찾는다.
- 1과 2중 더 작은 루트 노드를 큰 루트 노드의 루트 노드로 설정한다.
def union(a,b,parent):
a = find(a,parent)
b = find(b,parent)
if a < b:
parent[b] = a
else:
parent[a] = bfind(node)
def find(node, parent):
if node != parent[node]:
parent[node] = find(parent[node], parent)
return parent[node]경로 압축
find 함수의 return 값을 node와 parent[node] 둘중 무엇으로 해도 상관없지만 parent[node]로 하는 것이 훨씬 더 시간이 빠르다.
다음과 같은 예시를 보자.
from solution import union,find # solution.py
parent = [i for i in range(6)]
tmp = [(4,5), (3,4), (2,3), (1,2)]
for a,b in tmp:
union(a,b,parent)
print(parent)
print(find(3,parent))
print(parent)
find(4,parent)
print(parent)
find(5,parent)
print(parent)return node
{1,2,3,4,5}의 집합에서 union 연산이 (4,5), (3,4), (2,3), (1,2)와 같다고 할때, 부모테이블은 다음과 같아진다.
| 노드번호 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| 부모 | 1 | 1 | 2 | 3 | 4 |
return parent[node]
| 노드번호 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| 부모 | 1 | 1 | 1 | 1 | 1 |
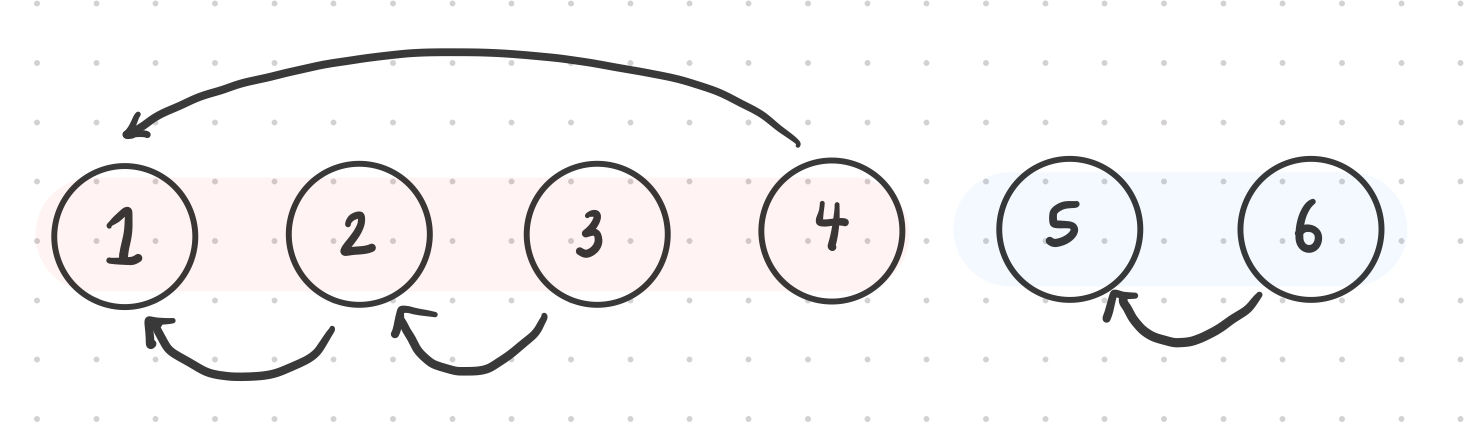
동일하게 5의 루트를 찾아간다고 가정했을 때,
return node는 5➡️4➡️3➡️2➡️1
return parent[node]는 5➡️1 이다.
따라서 후자가 시간복잡도가 더 작고 이를 "경로 압축"이라고 한다.

0x68656C6C6F21