스택
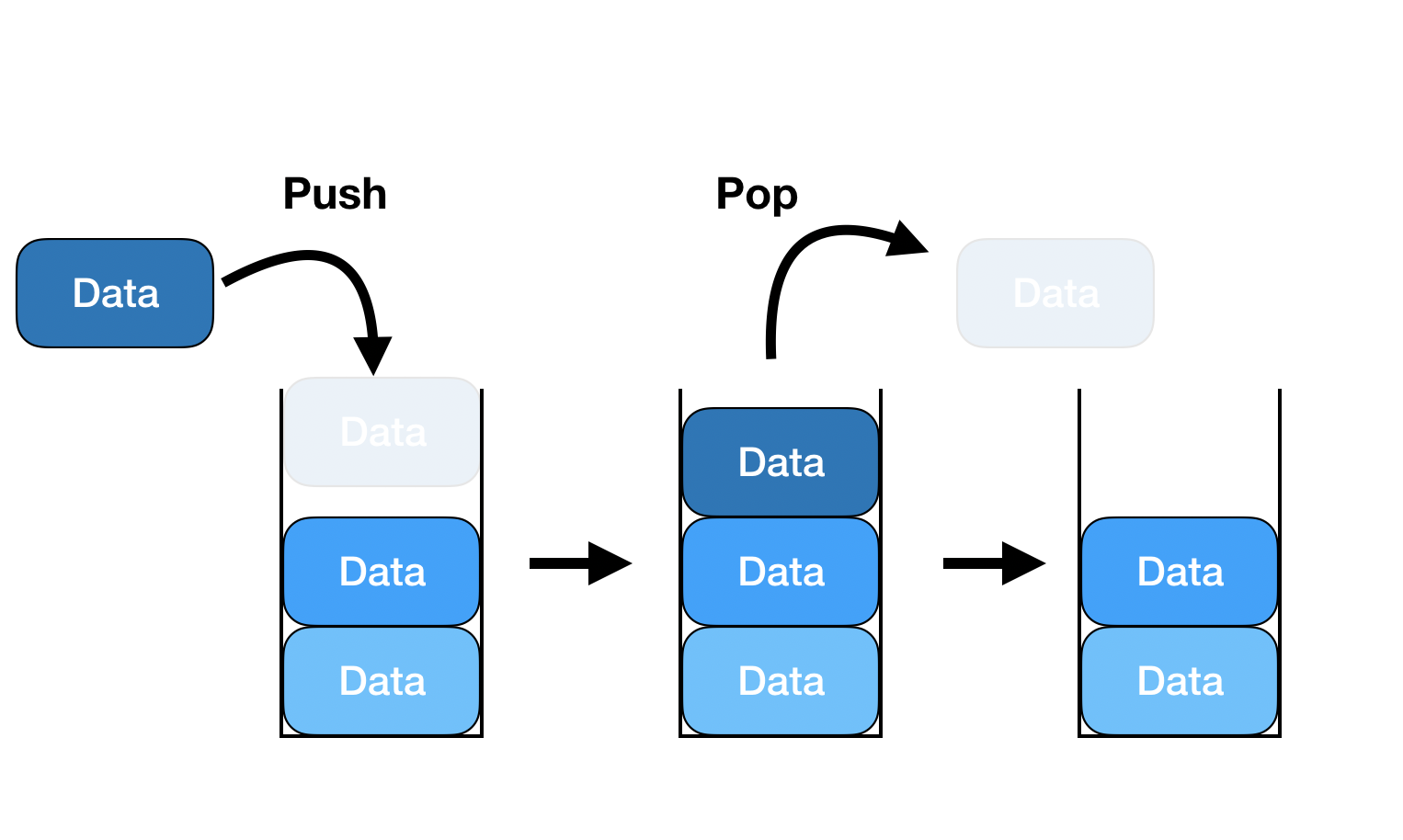
스택은 선입후출(LIFO) 자료구조다.
파이썬에서는 이를 리스트로 구현한다.
stack = [] # stack create
stack.append(1) # stack push
stack.append(2)
stack.append(3)
stack.pop() # stack.pop큐
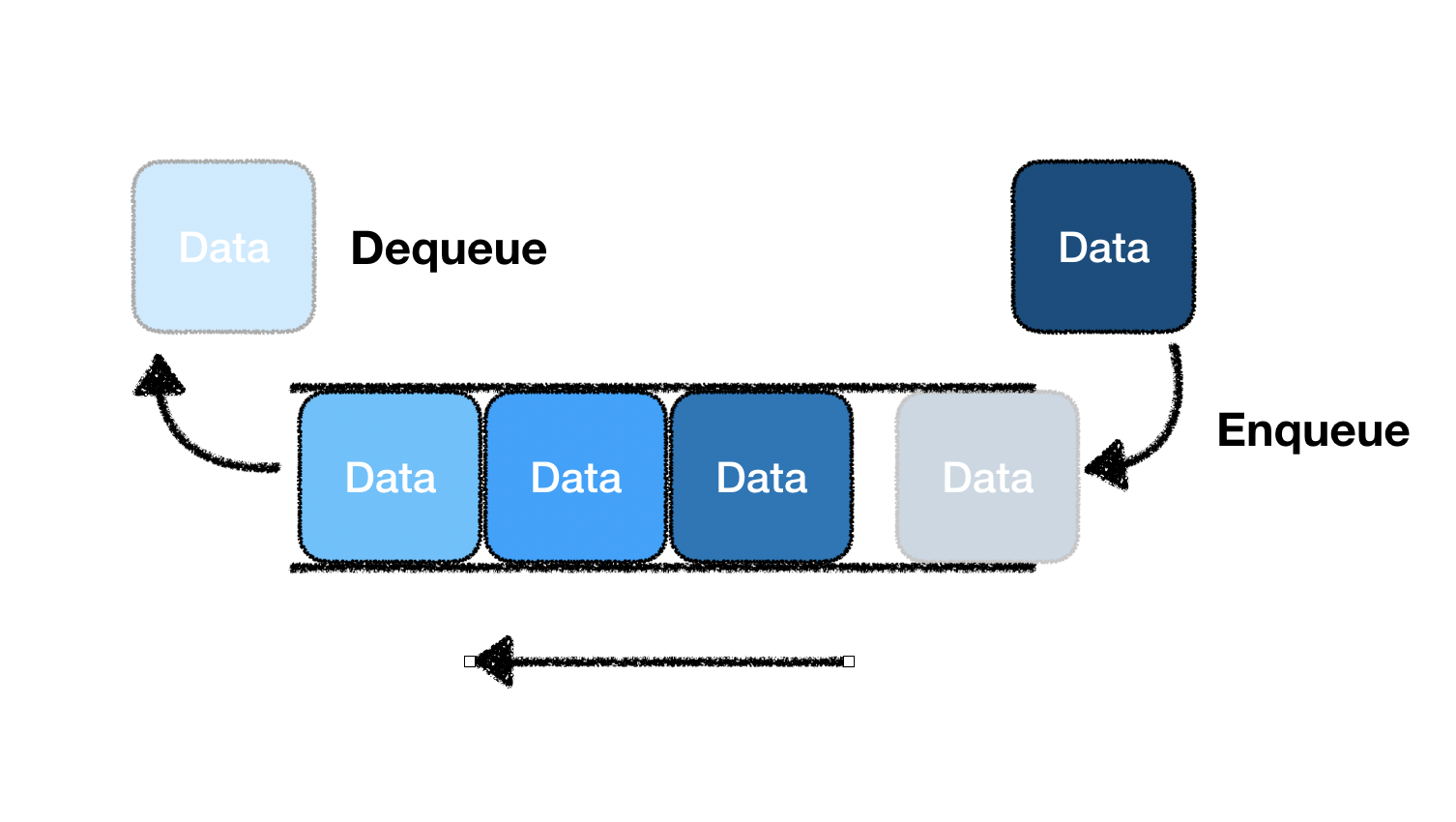
큐는 선입선출(FIFO) 자료구조다.
파이썬에서는 deque 패키지를 사용해 구현한다.
from collections import deque
queue = deque([]) # queue create
queue.append(1) # queue push
queue.append(2)
queue.append(3)
queue.popleft() # queue poppop(인덱스)를 쓰면 안되나 ...?
여기까지 읽었다면 이러한 의문점이 생길 것이다.
리스트의 pop 메서드를 이용하면 큐의 기능을 구현할 수 있는데?
뭐하러 deque을 쓰는거지...
무슨 말이냐 하면
queue = [1,2,3,4,5]
queue.pop(0)위와 같이 pop 메서드의 파라미터로 0을 넘겨줌으로써 큐의 기능을 동일하게 구현할 수 있다.
근데 왜 굳이 굳이 굳이 deque을 쓰냐?
그 이유는 바로 시간복잡도 때문이다.
시간복잡도
시간복잡도... 혹시라도 이해가 잘 안된다면 연산량 이라고 생각해도 된다.
n = 100
for _ in range(n):
print("hello world!")위 코드의 연산량은 얼마일까? 100!
그렇다면 아래 코드는?
n = 100
for _ in range(n):
for _ in range(n):
print("hello world!")10000이다.
이를 일반화 시킨 것이 빅오 표기법(Big-O Notation)이다.
위 코드는 O(n), 아래 코드는 O(n^2)이라고 부른다.
다시 본론으로 돌아와서 큐를 리스트로 안 쓰고 덱으로 쓰는 이유는 시간복잡도 때문이라고 했다.
왜 그럴까?
lst = [0,1,2,3,4]
lst2 = [i for i in range(100)]pop() 메서드의 시간복잡도는 O(1)이다.
다시 말해, 리스트 내의 원소가 몇 개 있든 lst나 lst2나 pop()의 연산량은 1번이라는 뜻이다.
반면에 pop(idx)의 시간복잡도는 O(리스트 길이)다.
lst.pop(3)은 0,1,2,3,4 전부 탐색을 해보고 3번 인덱스의 원소를 뱉어낸다.
lst2.pop(0)도 마찬가지로 0,1,2,3,...,100까지 전부 순회를 한 후 0번 인덱스를 반환한다.
따라서, 리스트로 큐를 구현하려면 시간복잡도가 O(n)이다.
반면에 덱의 popleft()는 시간복잡도가 O(1)이다.
q = deque([0,1,2,3,4])
q2 = deque([i for i in range(100)])큐 안에 원소가 몇개 있든 popleft()는 1번의 연산을 수행한다.
따라서 q.popleft()와 q2.popleft()는 동일한 시간복잡도를 가진다.
이러한 이유 때문에 큐를 구현할 때 덱을 임포트하여 사용한다.
그래서 어디에 쓰지?
나는 개인적으로 알고리즘이나 자료구조를 공부할 때 제일 중요하게 여기는 부분이 그래서 이 개념은 어떤 상황에서 사용하는가? 이다.
우리는 학문적인 공부가 목적이 아니라 취업이 목표이기 때문에 개념의 지식적인 측면보다는 코딩테스트에 주안점을 두어 공부를 해야 한다.
스택과 큐는 다음과 같은 상황에서 떠올릴 수 있다.
- 앞/뒤 원소를 순차적으로 처리해야할 때
https://www.acmicpc.net/problem/10773 - 문자열 관련 문제일 때
https://school.programmers.co.kr/learn/courses/30/lessons/12909
1번은 스택과 큐의 특성(후입선출, 선입선출)을 그대로 반영한 것이기 때문에 난이도가 쉬운 편이다.
2번은 스택과 큐를 이용해야 한다는 것을 떠올릴 수 있으면 쉽지만 그걸 몰랐을 때는 꽤 애를 먹었던 유형이다.
한 번씩 풀어보며 감을 익혀보도록 하자. ^^
