
4. 트리 + 힙 + 그래프 + DFS / BFS + DP(DynamicProgramming)
- 트리
-> 트리란 뿌리와 가지로 구성되어 거꾸로 세워놓은 나무처럼 보이는 계층형 비선형 자료 구조.
-> 3편에서 살펴보았던 큐(Queue), 스택(Stack) 은 자료구조에서 선형 구조라고 한다.
선형 구조란 자료를 구성하고 있는 데이터들이 순차적으로 나열시킨 형태를 의미한다.
이번편에서는 비선형 구조에 대해서 살펴보자.
비선형 구조는 선형구조와는 다르게 데이터가 계층적 혹은 망으로 구성되어있다.
선형구조와 비선형구조의 차이점은 형태뿐만 아니라 용도에서도 차이점이 많다!
선형구조는 자료를 저장하고 꺼내는 것에 초점이 맞춰져 있고, 비선형구조는 표현에 초점이 맞춰져 있다.
- 아래 폴더 구조가 대표적인 트리의 형태이다!
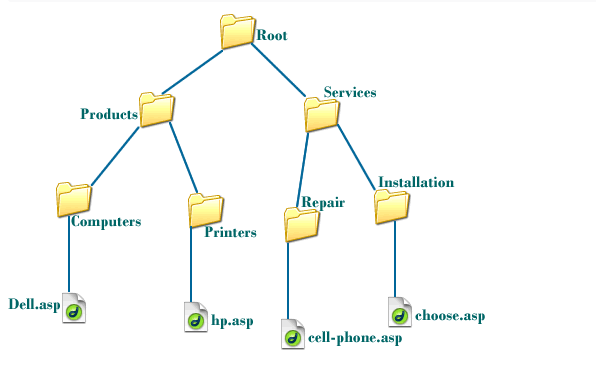
트리는 이름에서부터 느껴지듯이 계층형 구조이고, 위 아래가 구분되어 있다.
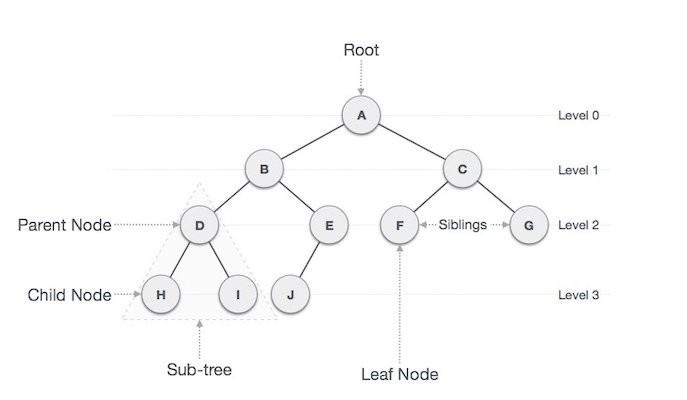
트리에서 나오는 용어들:
Node: 트리에서 데이터를 저장하는 기본 요소
Root Node: 트리 맨 위에 있는 노드
Level: 최상위 노드를 Level 0으로 하였을 때, 하위 Branch로 연결된 노드의 깊이를 나타냄
Parent Node: 어떤 노드의 상위 레벨에 연결된 노드
Child Node: 어떤 노드의 하위 레벨에 연결된 노드
Leaf Node(Terminal Node): Child Node가 하나도 없는 노드
Sibling: 동일한 Parent Node를 가진 노드
Depth: 트리에서 Node가 가질 수 있는 최대 Level
-> 트리는 이진 트리, 이진 탐색 트리, 균형 트리(AVL 트리, red-black 트리), 이진 힙(최대힙, 최소힙) 등 되게 다양한 트리가 있다. (4편에선 이진 트리와 완전 이진 트리만 보자)
이진 트리(Binary Tree)의 특징은 바로 각 노드가 최대 두 개의 자식을 가진다는 것이다. (즉, 하위의 노드가 4~5개 일 수 없습니다. 무조건 0, 1, 2 개만 있어야 한다)

완전 이진 트리(Complete Binary Tree)의 특징은 바로
노드를 삽입할 때 최하단 왼쪽 노드부터 차례대로 삽입해야 한다는 것 이다.

트리 구조를 표현하는 방법은 직접 클래스를 구현해서 사용하는 방법이 있고,
배열로 표현하는 방법이 있다.
트리 구조를 배열에 저장할 수 있는 방법은 완전 이진 트리를 쓰는 경우에 사용할 수 있다.
완전 이진 트리는 왼쪽부터 데이터가 쌓이게 되는데, 이를 순서대로 배열에 쌓으면서 표현할 수 있다.
ex) - 완전 이진 트리를 배열에 표현한다면..

트리의 높이(Height)는, 루트 노드부터 가장 아래 리프 노드까지의 길이인데,
예를 들어 아래와 같은 트리의 높이는 2라고 할 수 있다.

그렇다면, 각 레벨에 노드가 가득 차 있으면 몇 개가 있을까?
아래 예시를 보면, 레벨을 k라고 한다면, 각 레벨에 최대로 들어갈 수 있는 노드의 개수는
2^k 개수 임을 알 수 있다.

-> 그렇다면 높이가 h 인데 모든 노드가 꽉 차 있는 완전 이진 트리라면 모든 노드의 개수는 몇개일까?
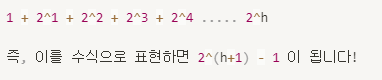
즉, 높이가 h 일 때 최대 노드의 개수는 2^(h+1) -1개 이다.
-> 그럼, 최대 노드의 개수가 N이라면, h 는 뭘까?
2^(h+1) -1 = N
→
h = log_2(N+1)-1
라고 할 수 있다!
즉, 완전 이진 트리 노드의 개수가 N일 때 최대 높이가 log_2(N+1) - 1 이므로...
-> 이진 트리의 높이는 최대로 해봤자.. O(log(N)) 라고 생각하면 된다.
- 힙
-> 힙은 데이터에서 최대값과 최소값을 빠르게 찾기 위해 고안된 완전 이진 트리(Complete Binary Tree)이다.
항상 최대의 값들이 필요한 연산이 있다면? -> 힙을 사용하면 된다.
Then, how to use heap?
-> 힙은 항상 큰 값이 상위 레벨에 있고 작은 값이 하위 레벨에 있도록 하는 자료구조이다.
다시 말하면, 부모 노드의 값이 자식 노드의 값보다 항상 커야 한다. -> 가장 큰 값은 모든 자식보다 커야 하기 때문에 가장 위로 간다. -> 따라서 최대의 값들을 빠르게 구할 수 있게 되는 것이다.
ex)

참고로, 힙은 다음과 같이 최대값을 맨 위로 올릴수도 있고, 최솟값을 맨 위로 올릴 수도 있다.
최댓값이 맨 위인 힙을 Max 힙,
최솟값이 맨 위인 힙을 Min 힙이라고 한다.
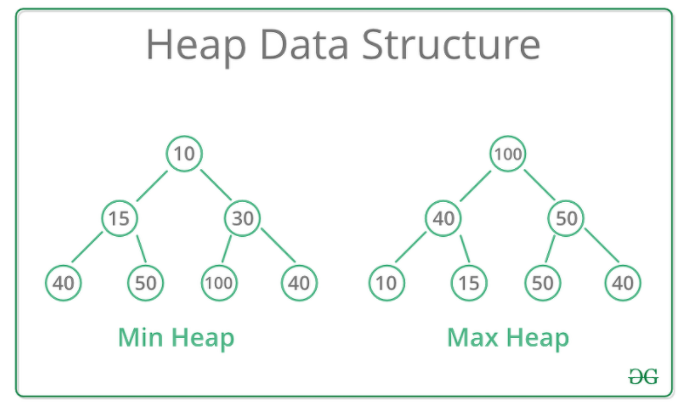
- 힙의 규칙
힙은 항상 큰 값이 상위 레벨에 있고 작은 값이 하위 레벨에 있어야 한다.
- 그래프
- 그래프란? -> 연결되어 있는 정점와 정점간의 관계를 표현할 수 있는 자료구조.
선형구조는 자료를 저장하고 꺼내는 것에 초점이 맞춰져 있고,
비선형구조는 표현에 초점이 맞춰져 있다.
이번 자료구조인 그래프는 바로 연결 관계에 초점이 맞춰져 있다.
그래프에서 사용되는 용어들:
노드(Node): 연결 관계를 가진 각 데이터를 의미한다. 정점(Vertex)이라고도 한다.
간선(Edge): 노드 간의 관계를 표시한 선.
인접 노드(Adjacent Node): 간선으로 직접 연결된 노드(또는 정점).
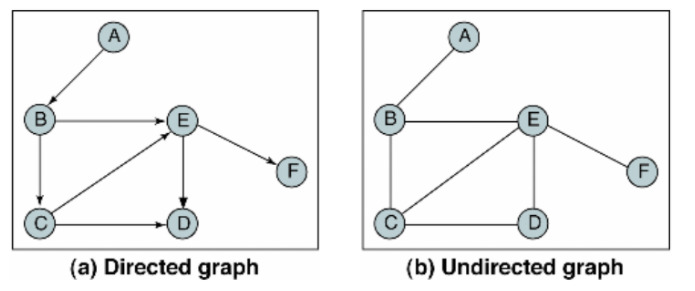
ex)

++
유방향 그래프(Directed Graph): 방향이 있는 간선을 갖는다. 간선은 단방향 관계를 나타내며, 각 간선은 한 방향으로만 진행할 수 있다.
무방향 그래프(Undirected Graph)는 방향이 없는 간선을 갖는다.
- DFS & BFS
-> 자료의 검색, 트리나 그래프를 탐색하는 방법. 한 노드를 시작으로 인접한 다른 노드를 재귀적으로 탐색해가고 끝까지 탐색하면 다시 위로 와서 다음을 탐색하여 검색한다.
-> 한 노드를 시작으로 인접한 모든 정점들을 우선 방문하는 방법. 더 이상 방문하지 않은 정점이 없을 때까지 방문하지 않은 모든 정점들에 대해서도 넓이 우선 검색을 적용한다.
- Then why have to know about DFS & BFS?
정렬된 데이터를 이분 탐색하는 것처럼 아주 효율적인 방법이 있는 반면에,
모든 경우의 수를 전부 탐색해야 하는 경우도 있다.
대표적인 예시가 알파고인데, 대국에서 발생하는 모든 수를 계산하고 예측해서 최적의 수를 계산해내기 위해 모든 수를 전부 탐색해야 한다.
DFS 와 BFS는 그 탐색하는 순서에서 차이가 있다.
DFS 는 끝까지 파고드는 것이고,
BFS 는 갈라진 모든 경우의 수를 탐색해보고 오는 것이 차이점입니다.
++
DFS 는 끝까지 파고드는 것이라, 그래프의 최대 깊이 만큼의 공간을 요구한다. -> 따라서 공간을 적게 쓰는데, 그만큼 최단 경로를 탐색하기 쉽지 않다.
BFS 는 최단 경로를 쉽게 찾을 수 있다. 모든 분기되는 수를 다 보고 올 수 있기 때문인데, 모든 분기되는 수를 다 저장하다보니 그만큼 공간을 많이 써야하고, 모든 걸 다 보고 오다보니 시간이 더 오래걸릴 수 있다.
