모니터링 메트릭 소개
1. 모니터링 메트릭 이란
시스템이이나 서비스의 상태와 성능을 실시간으로 파악하고 성능을 측정하기 위해 수집되는 지표이다. 이를 통해 시스템이 잘 작동하는지, 문제가 발생하지는 않았는지 관리/검토할 수 있다.
2. 모니터링 메트릭의 종류
성능 메트릭(Performance Metrics)
성능 메트릭은 시스템이나 서비스가 사용자의 요구에 얼마나 빠르고 효과적으로 응답하는지를 말한다.
- 응답 시간(Response Time)
- 요청을 보내고 응답을 받기까지 걸리는 시간
- 빠를 수록 좋다. 지연되면 서비스 품질이 저하되면서 사용자가 불편함을 느낀다.
- 지연 시간(Latency)
- 네트워크에서 데이터가 출발지부터 도착지까지 전달되는데 걸리는 시간
- 음성 통화, 게임, 영상 스트리밍 같은 실시간 서비스에서 특히 주의해야 한다.
- 처리량(Throughput)
- 일정 시간 내에 서비스가 처리할 있는 데이터의 총량
- 처리량이 높을 수록 많은 요청을 처리할 수 있다는 의미로, 초당 비트 수(bps, 등)나 초당 처리 건수(TPS)로 표현한다.
- 패킷 손실률(Packet Loss Rate)
- 데이터가 전송 중 소실되는 비율
- 손실률이 높을 수록 서비스 질이 떨어진다. 즉, 0%에 가까울 수록 네트워크 상태가 좋다고 판단한다.
자원 사용률 메트릭 (Resource Utilization Metrics)
자원 사용률 메트릭은 시스템의 하드웨어 자원(CPU, 메모리, 디스크 등)이 얼마나 효율적으로 사용되고 있는지를 나타내며, 시스템의 안정성 관리에 필수적이다.
클라우드 환경에서는 자원 사용률에 따라 Auto-Scaling 정책을 적용하여 비용 효율적인 운영을 한다.
- CPU 사용률
- 전체 CPU 처리능력 중 현재 사용 중인 비율
- 사용률이 지속적으로 높으면 성능 저하, 서비스 장애를 일으킬 수 있으므로 70~80%를 초과하면 주의해야 한다.
- 메모리 사용률
- RAM의 총량 대비 현재 사용 중인 비율
- 메모리 부족 시 응답 속도가 급격히 느려지거나 응답하지 않을 수 있으므로 적정 수준을 유지하도록 주의해야 한다.
- 디스크 사용률
- 디스크 전체 용량 중 현재 사용된 용량의 비율
- 저장 공간이 가득 차면 서비스 장애가 발생할 수 있다.
- 네트워크 대역폭 사용률
- 대역폭 대비 현재 사용 중인 데이터 비율
- 대역폭 사용률이 높으면 네트워크 병목현상이 발생할 수 있으며, 추가적인 네트워크 용량 증설 여부를 고려해야 한다.
오류 및 장애 메트릭 (Error and Fault Metrics)
오류 및 장애 메트릭은 시스템이나 서비스의 문제점을 사전에 인지하고 신속하게 대응하기 위해 사용됩니다.
- 에러율(Error Rate)
- 전체 요청 중 실패하거나 에러가 발생할 비율
- 시스템의 전반적인 품질을 판단하는 지표로, 에러율이 급격히 증가하면 시스템에 심각한 문제가 발생하고 있다는 뜻이다.
- 장애 발생 빈도(Failure Frequency)
- 특정 기간 내 장애가 발생한 횟수
- 장애 빈도가 높으면 사용자 만족도가 급격히 떨어질 수 있으므로 원인 분석과 예방책 마련이 중요하다.
- 장애 지속 시간(Failure Duration)
- 장애가 발생한 후 정상 상태로 복구될 때까지 걸린 시간
- 장애 지속 기간이 길어질 수록 서비스 신뢰도가 떨어지므로 최대한 빨리 복구할 수 있도록 절차를 효율화해야 한다.
- 장애 복구 시간(MTTR: Mean Time to Repair)
- 장애 발생 시 평균 복구까지 걸리는 시간
- MTTR이 짧을 수록 장애 대응력이 좋다는 것을 의미하며 이를 낮추기 위해 자원을 효율적으로 관리해야 한다.
- 장애 간격 시간(MTBF: Mean Time BetweenFailures)
- 장애가 발생한 후 다음 장애가 발생하기까지 평균 시간
- MTBF가 길수록 시스템 신뢰도가 높은 것으로 판단하며 이를 높이기 위해 시스템 안정성 개선 작업을 수행한다.
2. 모니터링 구조
1. 메트릭 수집
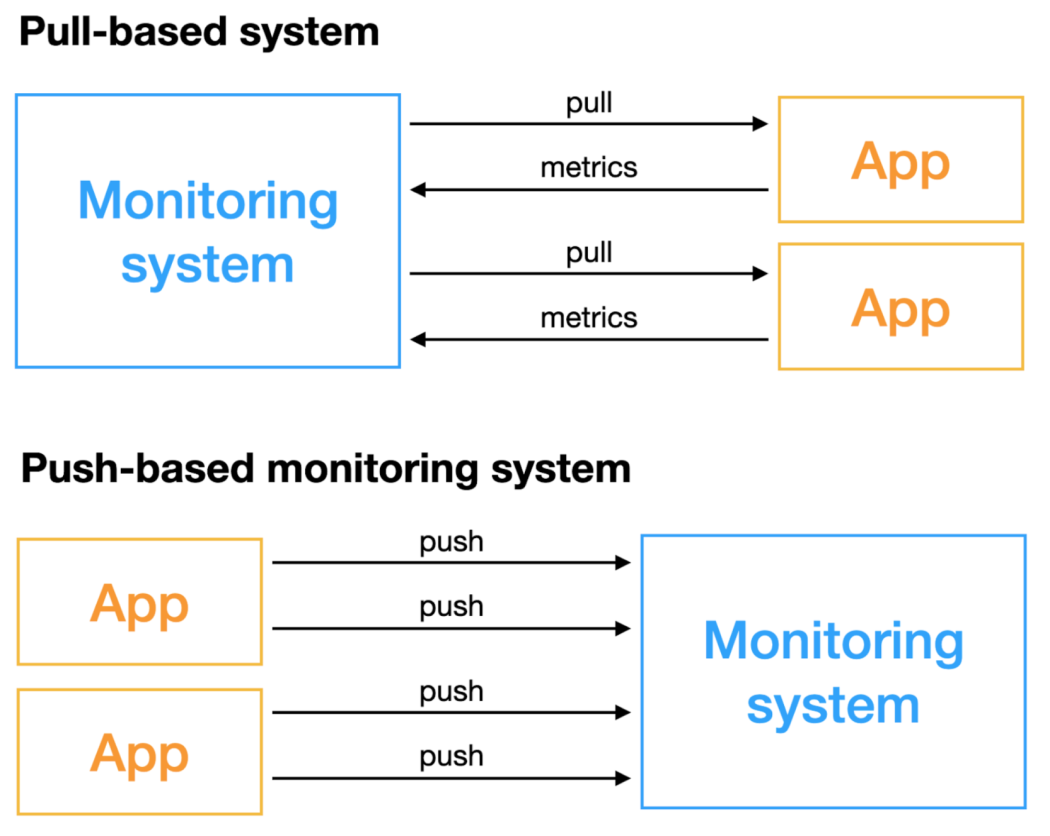
Pull Method
- 모니터링 서버
- 모니터링 대상에 요청을 하여 데이터 수집을 시작하면 수집 빈도를 결정하고 정기적으로 데이터를 가져온다.
- 모니터링 대상
- 모니터링 시스템이 스크랩할 메트릭을 노출하는 HTTP 끝점 또는 내보내기 도구를 제공한다.데이터를 주기적으로 pull하면 실시간 모니터링 기능을 제공하지 못할 수도 있지만 과거 분석 및 추세 탐지 기능을 사용할 수 있다.
- 대규모 인프라 및 클라우드 네이티브 환경에 적합하다.
Push Method
- 모니터링 대상
- 요청을 기다리지 않고 모니터링 시스템에 메트릭을 능동적으로 push한다. 메트릭을 생성하고 모니터링 시스템의 지정된
end-point또는gateway로 직접 전송한다. - 이를 위해선 모니터링 서버의 정보를 알아야 하고 각 대상자마다 agent와 같은 client 시스템이 있어야 한다.
- 요청을 기다리지 않고 모니터링 시스템에 메트릭을 능동적으로 push한다. 메트릭을 생성하고 모니터링 시스템의 지정된
- 실시간 모니터링을 수행하고 변경 사항 또는 이상 징후를 즉시 파악할 수 있다. 따라서 실시간 응답성이 중요한 애플리케이션 수준 또는 모니터링에 사용된다.
2. 메트릭 통합 도구
Prometheus

프로메테우스는 간단한 텍스트 형식으로 메트릭을 쉽게 수집한다. 데이터 모델은 key-value 형식의 label을 사용해 시계열 데이터를 구별하며, PromQL로 유연하게 분석 및 집계할 수 있다. 이를 통해 프로세스, 데이터센터, 서비스 등 다양한 단위로 분석할 수 있고 시각화 도구와 쉽게 연동할 수 있다.
알림도 동일한 PromQL을 이용하여 정의할 수 있어 관리가 편하다.
InfluxDB

프로메테우스가 주로 데이터를 서버에서 직접 pull 방식으로 가져오는 반면, 인플럭스는 데이터를 client에서 서버로 push 방식으로 보내는 구조를 기본으로 지원한다. 또한 인플럭스는 자체적으로 강력한 SQL 유사 언어인 InfluxQL 또는 Flux를 이용해 시계열 데이터를 편리하게 쿼리 및 분석할 수 있다.
3. 시각화 도구
Grafana

그라파나는 주로 시스템 모니터링과 같은 시계열(time-series) 데이터 시각화에 많이 쓰이며 관계형 데이터베이스의 데이터를 표나 차트 형태로도 시각화할 수 있다.
또한 사용자가 직접 기능을 추가하거나 확장할 수 있는 플러그인이 제공되며, 사용자들이 제작한 다양한 대시보드 템플릿을 쉽게 공유할 수 있다.
오픈소스로이기 때문에 소스 코드를 직접 수정할 수 있고 사용 환경이나 상황에 따라 자체 서버 설치형(On-premise)과 클라우드 기반 서비스형(SaaS) 중 선택할 수 있다.
Kibana

키바나는 ElasticSearch에 적재된 데이터만을 시각화할 수 있다는 특징이 있습니다. 이로 인해 Prometheus와 같은 다른 데이터 소스의 시계열 데이터를 시각화하려면 메트릭비트(Metricbeat) 와 같은 추가적인 도구를 이용해 데이터를 엘라스틱서치로 전달해야 하는 불편함이 있다.
그러나 직관적이고 인터랙티브한 대시보드와 상세한 데이터 검색, 다차원적 분석 기능을 제공하기 때문에 ElasticSearch의 데이터를 중심으로 시각화와 데이터 탐색을 중점적으로 고려하는 경우 매우 강력하다.
4. 클라우드 모니터링 도구
클라우드 환경에서는 시스템 자원 중심에서 벗어나 서비스 수준의 목표(SLO)와 계약(SLA)을 중심으로 모니터링해야 한다.
예를 들어, 서비스 가용성(Availability), 응답 시간, 처리량 등을 명확히 정의하고 이를 기준으로 경고(Alert)를 설정하고 관리한다.
CloudWatch

CPU 사용률, 메모리, 디스크 용량 등 기본적인 시스템 메트릭뿐 아니라, AWS 서비스별 상세 메트릭(EC2 인스턴스 상태, RDS DB 지연 시간, Lambda 호출 성공률 등)을 모니터링할 수 있다.
또한 EC2 서버 로그, 애플리케이션 로그 등을 CloudWatch Logs에 통합하여 로그 기반 문제 분석 및 대응을 통합하여 처리할 수 있다.
Azure Monitor

Azure 플랫폼 내 모든 리소스의 성능 및 가용성을 모니터링할 수 있는 통합 서비스이다. Application Insights로 애플리케이션의 응답 시간, 트랜잭션 처리 속도, 에러 발생 빈도 등의 상세한 메트릭을 수집하여 애플리케이션의 성능 병목 현상을 쉽게 파악할 수 있는 애플리케이션 성능 모니터링(APM)를 제공한다.
Stackdriver Monitoring

멀티 클라우드 환경 모니터링 서비스로, GCP는 물론 AWS의 EC2나 RDS 같은 서비스를 통합적으로 모니터링하여 단일 플랫폼에서 멀티 클라우드 환경을 쉽게 관리할 수 있다.
머신러닝을 통해 기존과 다른 이상 징후를 감지하고 빠르게 관리자에게 경고하여 장애가 발생하기 전 문제를 사전 대응할 수 있다.
