
NanoGrid - Self-Hosted FaaS Platform
🎯 THEME: "Run Your Functions Instantly over HTTP"
Lambda에 의존하지 않고, EC2 위에 직접 구축한 셀프 호스트형 FaaS 플랫폼
EC2/Compute Engine 위에서 구현하는 차세대 Serverless 플랫폼. 기존 서버리스 환경에서는 API Gateway의 29초 타임아웃 제한으로 인해 AI 추론, 대용량 데이터 처리 같은 장기 실행 작업이 불가능했습니다. NanoGrid는 이 한계를 극복하고, VPC 내부에서 완전히 격리된 Private AI 추론 환경까지 제공하는 Self-Hosted FaaS 플랫폼입니다.
역할:
- 프로젝트 아이디어 제공 및 설계
- 인프라 설계 및 구축 담당 (AWS Multi-AZ 아키텍처, Terraform IaC)
- 멀티클라우드 연동 (AWS + GCP)
핵심 기여:
- 아키텍처 전환: API Gateway + Lambda 기반에서 ALB + EC2 Controller 기반으로 전환하여 타임아웃 제한 극복
- Multi-AZ 고가용성 설계: Controller 2대를 서로 다른 AZ에 배치, Worker ASG Multi-AZ 구성
- Private AI Node 구축: VPC 내부 격리된 Ollama 기반 AI 추론 서버 구현
- SQS 기반 Auto Scaling: CloudWatch 메트릭 연동으로 동적 Worker 스케일링 구현
- AWS WAF 보안 강화: SQLi, XSS, Log4j, Rate Limit, Zip Bomb 방어 규칙 적용
- 멀티클라우드 데이터 영속성: AWS S3 + GCP Cloud Storage 연동으로 데이터 이중화
- Terraform IaC: 전체 인프라 코드화 및 모듈화
심사위원 피드백 (인프라 관련 발췌):
Adachi_SoftBank
"Lambda에 의존하지 않는 설계는 참신하고 도전적이며 훌륭합니다. 또한 안정성과 관측성을 관리하고 있는 것도 매우 좋습니다."
PARK_SOFTBANK Corp.
"트래픽의 분산, 네트워크 분리·보안 강화(안정성)가 고려된 설계가 이루어지고 있는 것을 알 수 있었습니다."
후루카와_소프트뱅크
"Lambda의 약점에 착안하여, 특정 서버에 집중하지 않기 위한 연구라는 관점은 재미있습니다. 제어를 그리드 상에 나누어 부하 분산이라는 아이디어. 안정성과 보안에의 주목도 ◎. Slack 연계도 중요하며, observability에 대한 배려도 Good."
Makoto Shimazu_Progate
"WAF, ALB, Controller나 Multi-AZ 구성 등 상당히 제대로 인프라가 구성되어 있어 훌륭하다고 생각했습니다!"
🔄 개발 배경과 진화 과정 (V1 → V6)
과제: 기존 FaaS의 제약과 VMware 의존에서의 탈피
| 버전 | 해결책 (NanoGrid Solution) | 기술적 특징 |
|---|---|---|
| V1 | 탈VMware · 독자 엔진 설계 | 경량 컨테이너 기반의 독자 클라우드 엔진 구축. 확장성과 비동기 처리 확보. |
| V2 | 29초의 벽 (Lambda 제한) 돌파 | Lambda를 폐지하고 EC2 Controller 도입. API GW → ALB로 변경하여 장시간 실행 실현. |
| V3 | 고가용성 (High Availability) | Controller와 Worker를 Multi-AZ에 배치. 단일 장애점(SPOF) 제거. |
| V4 | 멀티클라우드 영속성 | 실행 성공 코드를 GCP Cloud Storage에 영구 보존. Vendor Lock-in 리스크 저감. |
| V5 | 엔터프라이즈 보안 | AWS WAF 도입 (SQLi, XSS, DoS 방어). 모든 데이터를 VPC 내부에서만 처리하는 폐쇄망 설계. |
| V6 | Private AI 내재화 | 내부 AI EC2 노드 구축. 데이터 유출을 방지하는 보안 추론 환경. |
기술적 의사결정: 왜 EC2 Controller인가?
대안 비교:
| 구분 | API Gateway + Lambda | ALB + EC2 Controller |
|---|---|---|
| 타임아웃 | 29초 (API GW 한계) | 무제한 |
| 실시간 통신 | 불가 (동기 응답만) | Redis Pub/Sub 가능 |
| 비용 | 요청당 과금 | 상시 가동 비용 |
| 확장성 | 자동 | ASG 설정 필요 |
| AI 추론 | 외부 API 의존 | VPC 내부 Private AI |
선택 이유:
1. AI 추론, 대용량 데이터 처리 등 장기 실행 작업 지원 필수
2. Redis Pub/Sub을 통한 실시간 결과 반환 구현 가능
3. VPC 내부 Private AI Node로 데이터 보안 확보
4. Vendor Lock-in 없이 자체 AI 모델 운영 가능
🏗️ 아키텍처 및 기술 스택
전체 아키텍처
User → WAF → ALB → Controller EC2 (Public Subnet, Multi-AZ)
↓
DynamoDB (메타데이터)
↓
SQS (작업 큐)
↓
Worker EC2 (Private Subnet, ASG 2~5대)
↓ ↓ ↓
AI Node Redis S3/GCP
(Private AI) (상태 관리) (영속 저장)상세 아키텍처 다이어그램
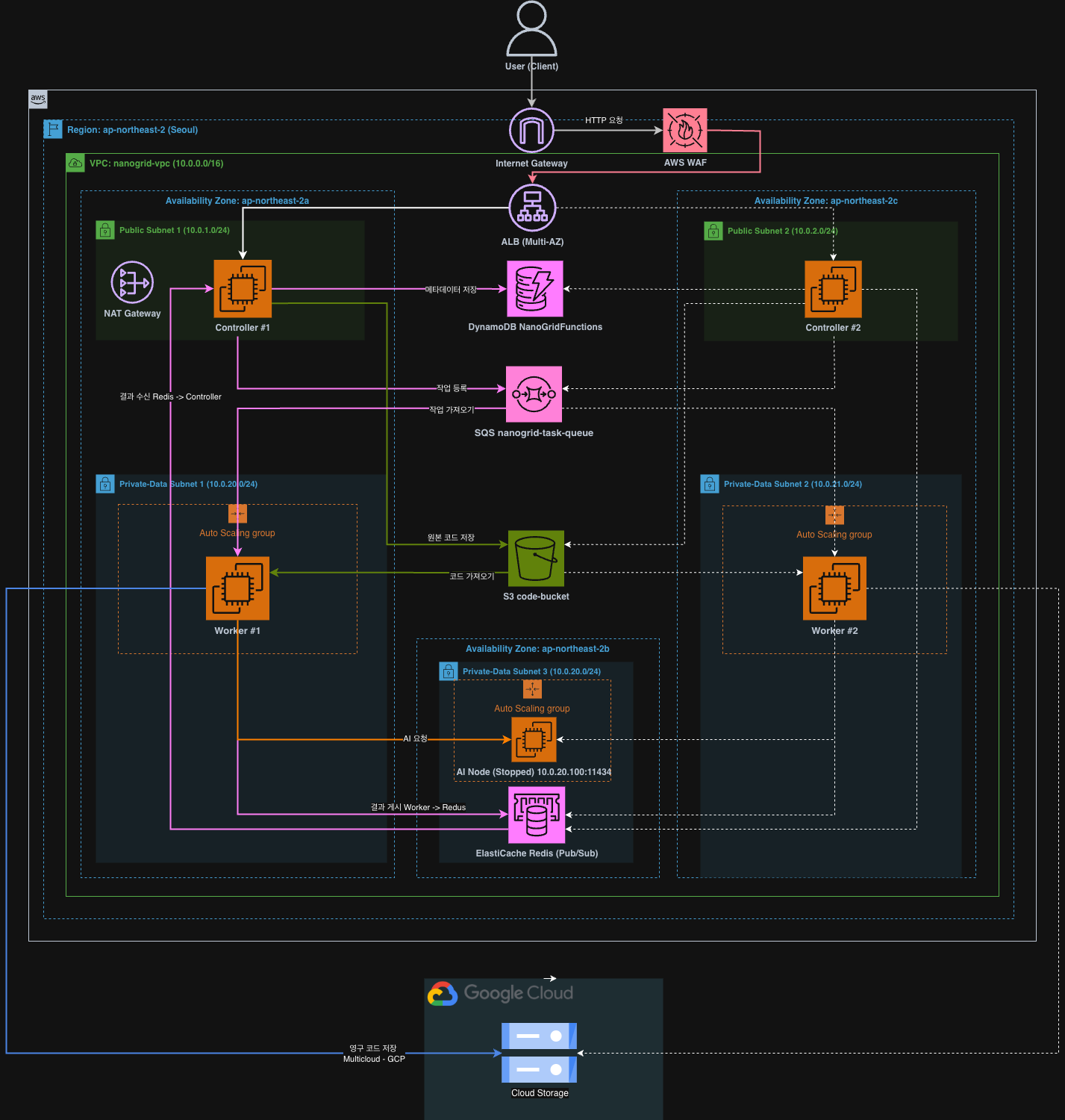
데이터 흐름
함수 등록 (Upload):
User → ALB → Controller → S3 (코드 업로드) → DynamoDB (메타데이터 저장) → Response함수 실행 (Run):
User → ALB → Controller → DynamoDB (조회) → SQS (작업 등록)
→ Worker (SQS 폴링) → S3 (코드 다운로드) → Docker (실행)
→ AI Node (추론, 필요시) → Redis (결과 저장)
→ GCP Storage (영속 저장, SUCCESS 시)
→ Controller (Redis 구독) → Response기술 스택
| 분류 | 기술 | 선정 이유 및 용도 |
|---|---|---|
| Language | Node.js/Express (Controller), Python (Worker) | Controller REST API, Worker 비동기 처리 |
| AWS 인프라 | EC2, VPC, ALB, SQS, S3, ElastiCache Redis, Secrets Manager | 핵심 컴퓨팅 및 상태 관리 |
| 멀티클라우드 | GCP Cloud Storage | Backup & Persistence, Vendor Lock-in 방지 |
| IaC | Terraform | AWS 리소스 코드화, 버전 관리 및 재현 가능한 인프라 |
| 컨테이너 | Docker | 사용자 코드 격리 실행 (Isolation & Runtime) |
| 보안 | AWS WAF, Private Subnet, NAT GW | SQLi, XSS, Log4j, Rate Limit 방어 |
| 모니터링 | CloudWatch Alarms | Auto Scaling Trigger |
주요 지표 (Key Metrics)
| 항목 | 수치/사양 |
|---|---|
| Controller | 2대 (Multi-AZ 고가용성 구성) |
| Worker | 2~5대 (SQS 기반 Auto Scaling) |
| Scale Out 임계값 | SQS 메시지 10개 이상 |
| Scale In 조건 | SQS 메시지 0개 (3분간 유지) |
| Cooldown | 300초 (5분) |
| AI Node | Private Subnet 완전 격리 (Internet Access Blocked) |
| 데이터 저장 | AWS S3 + GCP Cloud Storage (멀티클라우드) |
🛠️ 핵심 기능 상세 (Core Features)
1. Lambda-less 독자 컨트롤 플레인 (Control Plane)
- 구성: EC2 Controller 2대에 의한 Multi-AZ 구성 (ap-northeast-2a, 2c)
- 보안: ALB + WAF로 트래픽 분산과 공격 방어 (SQLi, XSS, Rate Limit)
- 기능: 라우터로서 기능하며, 타임아웃 없는 장기 실행 태스크 관리
# Controller #1 (AZ-a)
resource "aws_instance" "controller" {
subnet_id = aws_subnet.public.id # ap-northeast-2a
}
# Controller #2 (AZ-c) - Multi-AZ HA
resource "aws_instance" "controller_2" {
subnet_id = aws_subnet.public_2.id # ap-northeast-2c
}2. VPC 내부 Private AI Node
- 완전 격리: Private Subnet에 배치된 AI 추론 서버 (IP: 10.0.20.100)
- 데이터 주권: 외부 인터넷 노출 없음. 데이터 유출 원천 차단
- 접근 제어: Security Group으로 Worker에서의 접근만 허용
resource "aws_security_group" "ai_sg" {
ingress {
from_port = 11434 # Ollama 포트
to_port = 11434
protocol = "tcp"
security_groups = [aws_security_group.worker_sg.id] # Worker만 허용
}
}3. SQS 기반 Auto Scaling (Core Logic)
- Scale Out: SQS 메시지 10개 이상 → 최대 5대까지 자동 증설
- Scale In: 메시지 0개 (3분 유지) → 최소 2대까지 축소
- 안정성: Multi-AZ 분산 배치와 300초 Cooldown으로 급격한 변동 방지
resource "aws_cloudwatch_metric_alarm" "sqs_high" {
alarm_name = "nanogrid-sqs-high"
comparison_operator = "GreaterThanOrEqualToThreshold"
threshold = 10
alarm_actions = [aws_autoscaling_policy.scale_out.arn]
dimensions = {
QueueName = data.aws_sqs_queue.job_queue.name
}
}4. 멀티클라우드 데이터 영속성 (Persistence)
- AWS S3: 소스 코드 원본 저장
- GCP Cloud Storage: 실행 성공한 코드와 결과의 영구 보존
- 보안 전송: Worker가 NAT Gateway를 경유, AWS Secrets Manager로 관리된 인증 키를 사용하여 GCP로 직접 전송
resource "aws_iam_role_policy" "worker_policy" {
Statement = [
{
Effect = "Allow"
Action = ["secretsmanager:GetSecretValue"]
Resource = "arn:aws:secretsmanager:${var.aws_region}:*:secret:nanogrid/gcp-credentials-*"
}
]
}5. Redis Pub/Sub 실시간 상태 관리
- 비동기 통신: Controller ↔ Worker 간 고속 상태 동기화
- 상태 추적: PENDING → PROCESSING → SUCCESS/FAILED 실시간 가시화
- 자동 정리: TTL 24시간 설정으로 메모리 관리
🛡️ 보안 구성 (Security)
AWS WAF 규칙
| Rule | 설명 |
|---|---|
| AWSManagedRulesSQLiRuleSet | SQL Injection 방어 |
| AWSManagedRulesCommonRuleSet | XSS, Path Traversal 방어 |
| AWSManagedRulesKnownBadInputsRuleSet | Log4j, 악성 입력값 방어 |
| RateLimitRule | IP당 5분에 1000 요청 제한 |
| SizeConstraintRule | Body 1GB 제한 (Zip Bomb 방어) |
IAM 최소 권한 원칙 적용
V1 (과도한 권한):
# AWS Managed Policy 사용 - 불필요한 권한 포함
policy_arn = "arn:aws:iam::aws:policy/AmazonS3ReadOnlyAccess"
policy_arn = "arn:aws:iam::aws:policy/AmazonSQSFullAccess"V2+ (최소 권한):
# Custom Policy - 필요한 Action만 명시
Statement = [
{
Effect = "Allow"
Action = ["s3:GetObject"]
Resource = "${data.aws_s3_bucket.code_bucket.arn}/*"
},
{
Effect = "Allow"
Action = ["sqs:ReceiveMessage", "sqs:DeleteMessage", "sqs:GetQueueAttributes"]
Resource = data.aws_sqs_queue.job_queue.arn
}
]네트워크 분리
| Subnet | CIDR | AZ | 용도 | 라우팅 |
|---|---|---|---|---|
| Public 1 | 10.0.1.0/24 | ap-northeast-2a | Controller, NAT GW | IGW |
| Public 2 | 10.0.2.0/24 | ap-northeast-2c | Controller | IGW |
| Private Data 1 | 10.0.20.0/24 | ap-northeast-2a | Worker, Redis, AI | NAT GW |
| Private Data 2 | 10.0.21.0/24 | ap-northeast-2c | Worker | NAT GW |
🧐 기술적 도전과 해결 (Troubleshooting)
Challenge 1: API Gateway 29초 타임아웃 한계
Problem:
초기 V1 아키텍처에서 API Gateway + Lambda 조합을 사용했으나, API Gateway의 29초 타임아웃 제한으로 인해 AI 추론, 대용량 데이터 처리 같은 장기 실행 작업이 불가능했습니다.
Solution (V2):
ALB + EC2 Controller 아키텍처로 전환:
# V1: API Gateway → Lambda (29초 제한)
# V2: ALB → EC2 Controller (무제한)
# 비동기 처리 + Redis Pub/Sub으로 실시간 결과 반환
1. Controller가 SQS에 작업 등록 후 즉시 job_id 반환
2. Worker가 SQS에서 작업 가져와 실행 (시간 제한 없음)
3. 실행 완료 시 Redis에 결과 Publish
4. Controller가 Redis Subscribe로 결과 수신 후 클라이언트에 반환Challenge 2: 단일 장애점(SPOF) 제거
Problem:
V2까지 Single-AZ 구성으로 AZ 장애 시 전체 서비스 중단 위험이 있었습니다.
Solution (V3):
Controller와 Worker 모두 Multi-AZ 배치:
# Controller: ap-northeast-2a, ap-northeast-2c 분산
# Worker ASG: 두 AZ에 걸쳐 분산 배치
vpc_zone_identifier = [
aws_subnet.private_data.id, # ap-northeast-2a
aws_subnet.private_data_2.id # ap-northeast-2c
]Challenge 3: Vendor Lock-in 리스크
Problem:
AWS 단일 클라우드 의존 시 장애 발생 시 데이터 손실 위험과 Vendor Lock-in 문제가 있었습니다.
Solution (V4):
AWS S3 + GCP Cloud Storage 이중화:
- 실행 성공한 코드를 GCP에도 영구 보존
- Secrets Manager로 GCP 인증 정보 안전하게 관리
Challenge 4: 보안 강화 요구
Problem:
인터넷에 노출된 서비스로서 SQLi, XSS, DDoS 등 다양한 공격에 대한 방어가 필요했습니다.
Solution (V5):
AWS WAF 도입 + 폐쇄망 설계:
- 5가지 WAF 규칙으로 다층 방어
- 모든 데이터 처리를 VPC 내부에서만 수행
- Private Subnet에 Worker, AI Node, Redis 배치
Challenge 5: Private AI 추론 환경 구축
Problem:
외부 AI API(OpenAI, Bedrock 등) 사용 시 데이터 유출 우려와 Vendor Lock-in 문제가 있었습니다.
Solution (V6):
VPC 내부에 격리된 AI Node 구축:
- Private Subnet에 Ollama 기반 AI 서버 배치
- Security Group으로 Worker에서만 접근 허용
- 인터넷 접근 완전 차단으로 데이터 유출 원천 방지
📝 배운 점 & 회고 (KPT)
Keep (잘한 점)
-
버전별 점진적 개선: V1~V6까지 명확한 목표를 가지고 단계적으로 아키텍처 발전. 팀원 간 공통 목표 공유에 효과적
-
Lambda 한계 인식과 과감한 전환: API Gateway 29초 한계를 인식하고 EC2 Controller로 전환. 장기 실행 작업 지원이라는 핵심 요구사항 충족
-
Multi-AZ 고가용성: Controller 2대, Worker ASG를 서로 다른 AZ에 배치하여 단일 장애점 제거
-
VPC Endpoint 활용: S3, DynamoDB Gateway Endpoint로 NAT Gateway 비용 절감 및 보안 강화
-
IAM 최소 권한 원칙: V1의 AWS Managed Policy에서 Custom Policy로 전환하여 보안 강화
-
AWS WAF 적용: SQLi, XSS, Rate Limit 등 다층 방어로 엔터프라이즈급 보안 수준 달성
-
멀티클라우드 설계: AWS + GCP 연동으로 Vendor Lock-in 방지 및 데이터 이중화
-
Terraform IaC: 전체 인프라를 코드로 관리하여 재현 가능하고 버전 관리 가능한 인프라 구축
Problem (아쉬운 점)
-
Terraform State 로컬 관리: 팀 협업 시 충돌 위험. S3 Backend + DynamoDB Lock 적용 필요
-
모니터링 부족: CloudWatch 기본 메트릭만 사용. 커스텀 대시보드, 알람, X-Ray 트레이싱 미구현
-
CI/CD 파이프라인 부재: Terraform 수동 배포. GitHub Actions 또는 CodePipeline 연동 필요
-
환경 분리 부재: Production 환경만 존재. Terraform Workspace로 Dev/Staging/Prod 분리 필요
-
로그 중앙화 미구현: Controller, Worker 로그가 각 인스턴스에 분산. CloudWatch Logs Agent 필요
-
분산 효과 정량화 부족: 심사위원 피드백대로 분산에 의한 Pros/Cons 깊은 분석과 NanoGrid에서의 효과 측정 미흡
-
SDK 미제공: 심사위원 피드백대로 stdin/stdout만으로 입출력 관리. 전용 SDK로 다양한 인수/반환값 표현 가능했음
-
비용 모니터링 부재: AWS Budgets, Cost Explorer 연동 없이 진행. 실시간 비용 파악 불가
Try (시도할 점)
- Terraform Remote State:
terraform {
backend "s3" {
bucket = "nanogrid-terraform-state"
key = "prod/terraform.tfstate"
region = "ap-northeast-2"
dynamodb_table = "terraform-locks"
encrypt = true
}
}- 모니터링 강화:
- CloudWatch Dashboard: ALB 요청 수, SQS 메시지 수, ASG 인스턴스 수
- CloudWatch Alarms: 에러율, 지연 시간 임계치 알림
- X-Ray: 분산 트레이싱으로 병목 구간 파악
- CI/CD 파이프라인:
# GitHub Actions
name: Terraform Deploy
on:
push:
branches: [main]
jobs:
deploy:
steps:
- uses: hashicorp/setup-terraform@v2
- run: terraform init
- run: terraform plan
- run: terraform apply -auto-approve- 환경 분리:
environments/
├── dev/
│ └── terraform.tfvars # 작은 인스턴스, ASG min=0
├── staging/
│ └── terraform.tfvars # 중간 규모
└── prod/
└── terraform.tfvars # 프로덕션 규모, Multi-AZ-
분산 효과 측정: 부하 테스트 도구(k6, Locust)로 분산 전/후 성능 비교, Latency/Throughput 정량화
-
NanoGrid SDK 개발: Python/Node.js SDK로 함수 입출력 추상화, HTTP 요청 핸들링 간소화
💬 마치며
NanoGrid 프로젝트는 "API Gateway 29초 타임아웃을 넘어서"라는 명확한 기술적 도전에서 시작했습니다. V1부터 V6까지 버전별로 명확한 목표를 설정하고 점진적으로 아키텍처를 발전시킨 것이 팀 협업과 프로젝트 관리에 큰 도움이 되었습니다.
가장 큰 배움은 "서버리스가 항상 정답은 아니다"라는 것이었습니다. Lambda와 API Gateway는 훌륭한 서비스지만, 장기 실행 작업이나 실시간 통신이 필요한 경우에는 EC2 기반 아키텍처가 더 적합할 수 있습니다. 각 서비스의 특성과 한계를 이해하고, 요구사항에 맞는 최적의 조합을 찾는 것이 클라우드 아키텍트의 역할이라는 것을 배웠습니다.
심사위원분들의 피드백처럼 "Lambda에 의존하지 않는 설계의 참신함"과 "안정성/보안에 대한 배려"가 인정받아 기뻤고, 동시에 "분산 효과의 정량화"와 "SDK 제공" 같은 개선점도 명확히 인식하게 되었습니다.
이번 프로젝트에서 우승하신 분들은 Infra를 효율적으로 사용하는 k8s의 spin cube와 같은 기술을 적용하셨습니다. 이번 결과를 토대로 인프라 서비스에만 집중하는 것이 아닌 기술적으로 창의적인 부분을 적용시키고자 노력하고자 합니다.
