
다양한 연관관계 매핑
📌 [N:1]
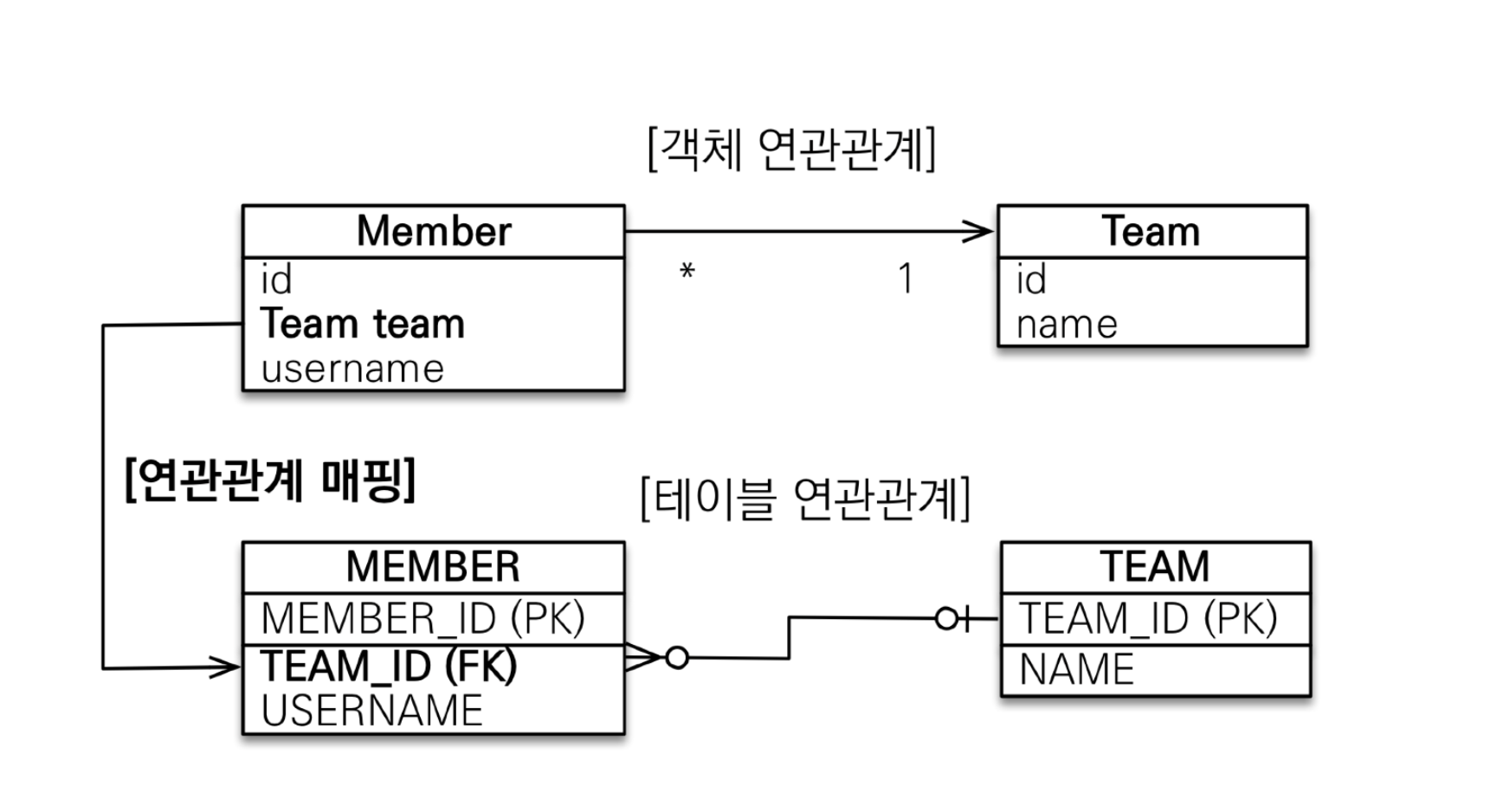
아래 사진은 n:1 단방향일 때 테이블과 객체의 설계이다.
객체에서 연관관계 주인을 FK를 가진 테이블로 설정하여 단방향으로 Team의 정보를 매핑할 수 있도록 설정한 것이다.
📌 [1:N]
n:1과 달리 1:n에서 1을 연관관계의 주인으로 하는 경우 아래 사진과 같은 문제가 생긴다.
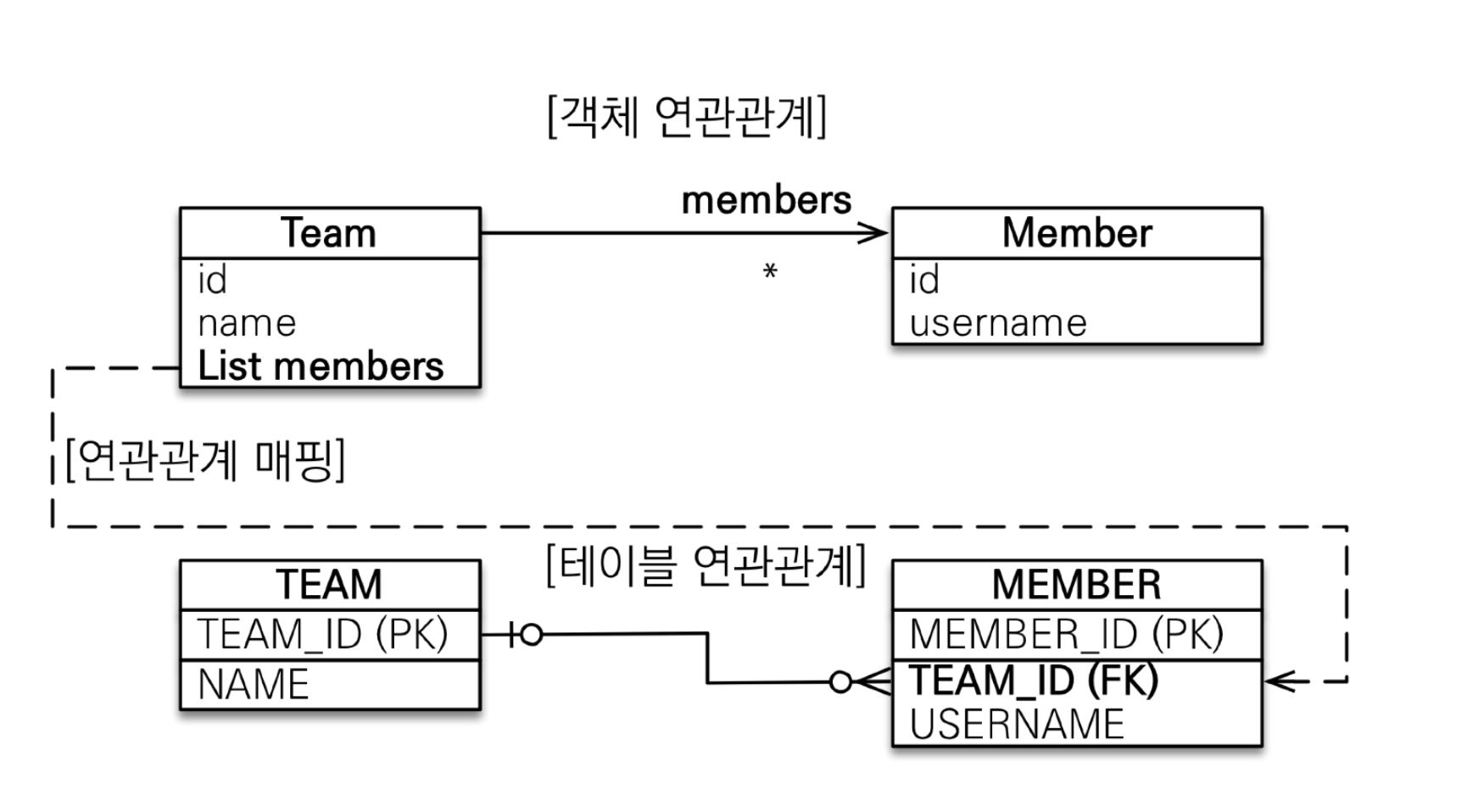
테이블에서는 FK를 가지는 테이블을 통해 join을 하는데 객체에서는 연관관계의 주인이 FK를 가지지 않는 테이블의 엔티티가 되는 것이다. 이렇게 되면 데이터를 읽기가 어렵다. 따라서 읽기 전용 객체를 설정하도록 하자.
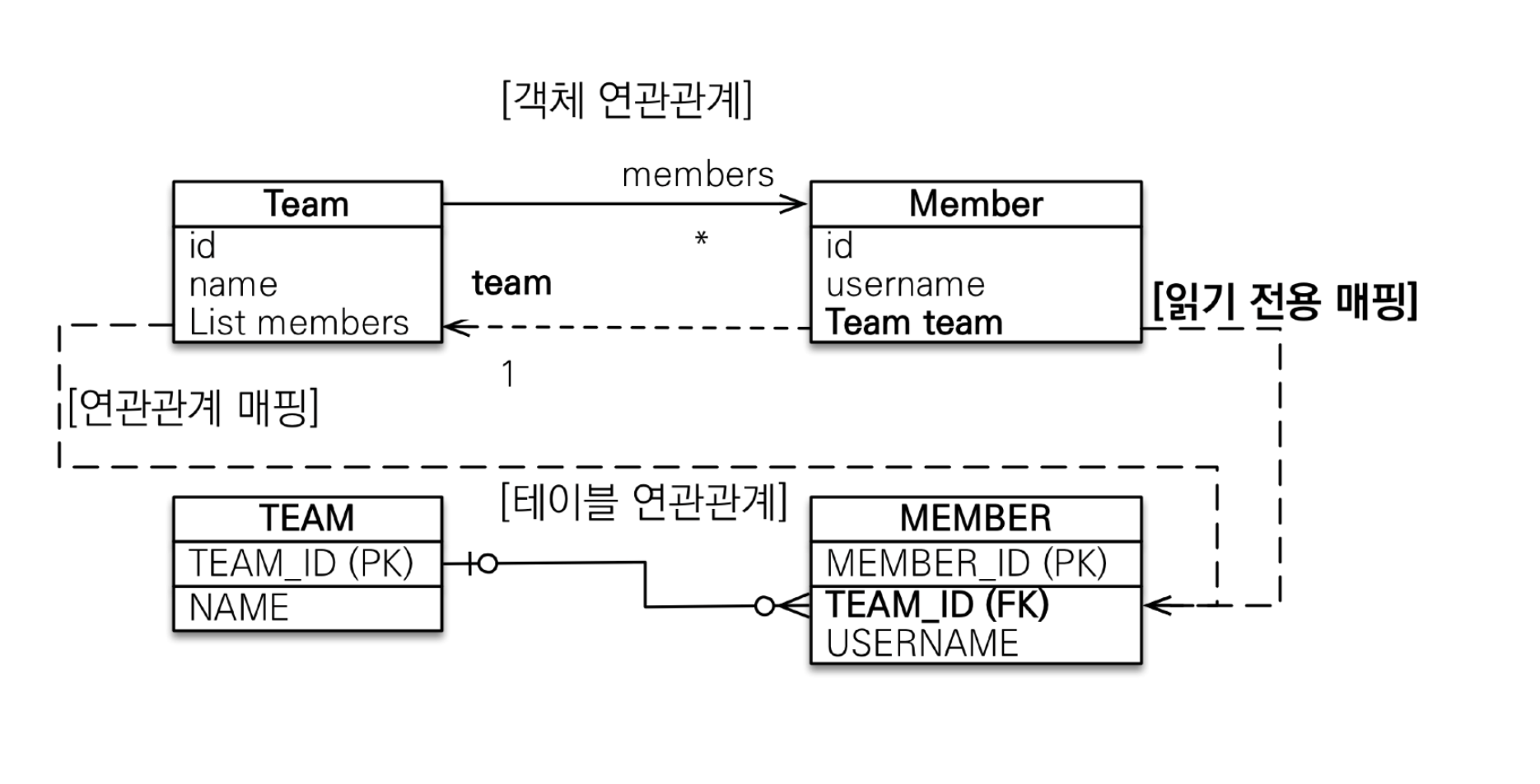
대충 봐도 N:1관계와는 달리 쓸데없는 매핑과정이 존재한다. 따라서 위의 연관관계는 권장하지 않는다.
고급매핑
📌 상속관계 매핑
RDB에는 상속관계란 것이 없다. 그저 유사한 슈퍼타입, 서브타입 관계라는 모델링 기법이 존재하는 것이다.
슈퍼타입 서브타입 논리 모델을 실제 물리 모델로 구현하는 방법
1. join strategy
2. single table strategy
3. table per class strategy(모두 jpa에서 지원하는 방식이다.)
실제로 어노테이션으로는 아래와 같이 사용된다.
@inheritance(strategy=InheritanceType.XXX)
1. JOINED
2. SINGLE_TABLE
3. TABLE_PER_CLASS- table per class
table_per_class는 각 구현 클래스마다 테이블을 만들어 주는 전략이다.
table_per_class에서는 abstarct class를 사용해주어야 한다. 그 이유는 추상클래스를 사용하지 않으면 슈퍼타입 테이블 자체만으로도 사용이 가능하다고 여겨지기 때문이다.
예를 들어 item테이블이 슈퍼타입, album, movie, book이 서브타입이라고 하자. 객체를 생성했을 때 item을 abstract class로 만들지 않고 생성한다면 item class 객체 생성이 가능할 것이다.
이 방식은 여러 자식 테이블을 함께 조회할 때 성능이 저하되고 자식테이블을 통합해서 쿼리하기 어렵기때문에 권장하지 않는 방식이다.
- join
특징
말그대로 필요에 의해 수퍼타입 테이블과 서브 타입 테이블을 join하는 방식이다.(필요한 부품을 끼운다는 느낌?)
장점
1. 테이블 정규화
2. 외래 키 참조 무결성 제약 조건 활용 가능 -> 외래키를 통해 테이블을 매핑할 때 필요한 테이블만을 볼 수 있다는 뜻
3. 저장 공간 효율화
단점
1. 조회 시 조인을 많이 사용
2. 조회 쿼리가 복잡
3. 데이터 저장 시 insert SQL 2번 -> 단점이라기에는 애매
- single table
특징
모든 서브테이블을 수퍼타입 안의 필드로 넣어버리는 형식. 구별은 dtype을 통해 한다.
장점
1. 조인이 필요 없으므로 일반적으로 조회 성능이 빠름
2. 조회 쿼리가 단순
단점
1. 자식 엔티티가 매핑한 컬럼은 모두 null 허용(중요)
2. 단일 테이블에 모든 것을 저장하므로 테이블이 커질 수 있고 상황에 따라서 조회 성능이 오히려 느려질 가능성도 있다.
📌 Mapped SuperClass - 매핑 정보 상속
@MappedSuperclass
* 공통 매핑 정보가 필요할 때 사용(상속이랑 무관)
* 엔티티x, 테이블과 매핑 x
* 부모 클래스를 상속받는 자식 클래스에 정보만 제공
* 조회, 검색 불가
* 추상 클래스 권장프록시와 연관관계 관리
📌 proxy
프록시 개념을 이해하는 것이 중요하다. 프록시, 대리라는 의미를 가지고 있지만 jpa에서는 허위, 가짜라는 뜻과 더 유사한 것 같다. 이 프록시 객체의 생성은 다음과 같은 상황에 이루어진다.
예를 들어 아래 사진과 같은 연관관계를 가진다고 했을 때, member 정보를 조회한다고 하자. 그러면 team의 정보도 같이 조회해야할까?
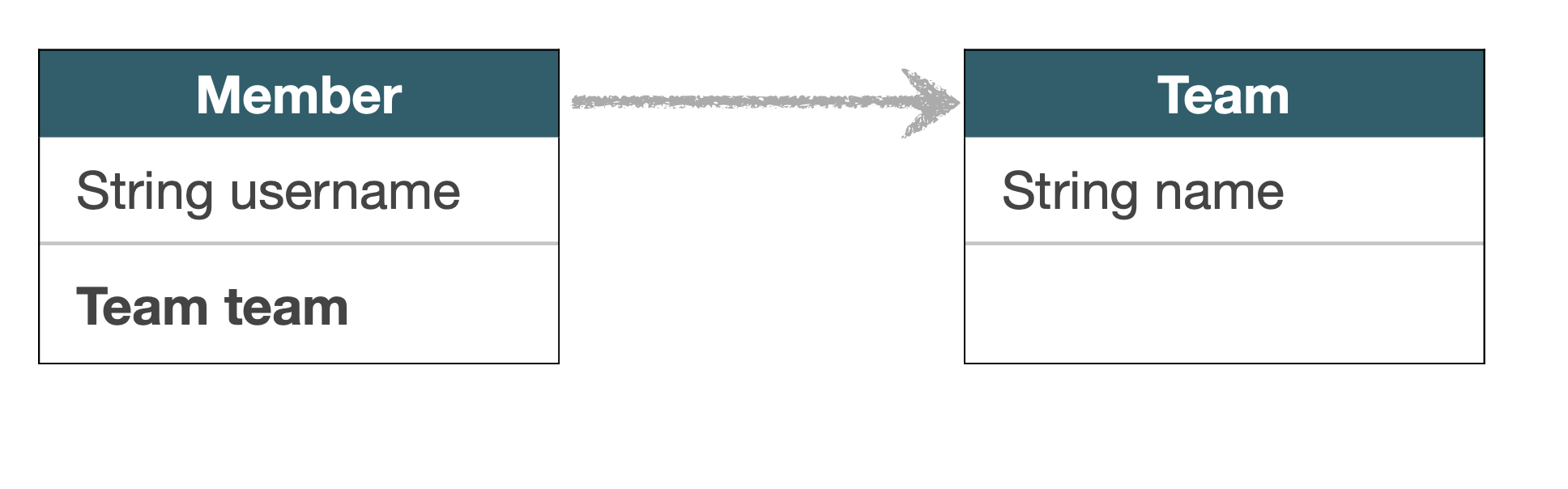
항상 team에 대한 정보를 가져올 필요가 없다. (정보를 가져온다 = 쿼리문 소모)와도 같기 때문에 필요도 없을 때 쿼리문을 던지는 것은 쓸데없는 소모이다. 이런 상황에서 사용되는 것이 프록시 객체이다.
프록시 객체는 member안의 team 정보를 "필요로 할때"까지 가짜 객체로 존재하는 것이다. 필요란 곧 조회를 의미한다.
1. em.find() : 데이터베이스를 통해서 실제 엔티티 객체 조회
2. em.getReference() : 데이터베이스 조회를 미루는 가짜(프록시)엔티티 객체 조회위 명령어를 통해 실제 데이터와 프록시 엔티티 객체 조회를 구별하여 사용할 수 있다. em.getReference()메서드를 사용하면 해당 객체는 프록시 객체로서 실제 객체의 참조를 보관하게된다. 후에 실제 객체의 메서드를 호출하게 되면 실제 객체의 정보 초기화를 영속성 컨텍스트에 요청하게되고, DB 조회를 통해 실제 entity에 접근 가능하게된다.
프록시 특징
* 실제 클래스를 상속받아 만들어짐
* 실제 클래스와 겉모양이 같다.
* 사용입장에서는 구분하지 않아도 됨.
* 프록시 객체는 실제 객체의 참조를 보관
* 호출 시 실제 객체 메소드 호출 <<<중요>>>
프록시 객체는 처음 사용할 때 "한번"만 초기화한다. 프록시 객체를 초기화 할 때, 프록시 객체가 실제 엔티티로 바뀌는 것이 아니다. 초기화되면 프록시 객체를 통해서 실제 엔티티에 접근 가능한 것이다.
프록시 객체는 원본 엔티티를 상속받는다. 따라서 타입 체크시 주의해야한다. (==비교실패, 대신 instance of사용)
영속성 컨텍스트에 찾는 엔티티가 이미 있으면 em.getReference()를 호출해도 실제 엔티티를 반환한다.(반대로 프록시를 호출하면 em.find()를 호출해도 프록시 리턴)
- 프록시 확인
1. 프록시 인스턴스의 초기화 여부 확인: PersistenceUnitUtil.isLoaded(Object Entity)
2. 프록시 클래스 확인 방법: entity.getClass().getName()
3. 프록시 강제 초기화: org.hibernate.Hibernate.initialize(entity)📌 즉시로딩과 지연로딩
즉시로딩과 지연로딩은 프록시 객체와 밀접한 관계에 있다.
fetch = FetchType.Lazy --> proxy객체로 저장
fetch = FetchType.EAGER --> 실제 entity 객체 저장 따라서 조회의 경우에는 지연로딩으로 설정해두어야 성능 최적화를 이룰 수 있다.(권장)
@XXXToOne 어노테이션은 기본이 즉시로딩으로 설정되어있기 때문에 LAZY로 직접 설정해주어야한다. 반대의 경우는 기본이 LAZY로 설정되어있다.
📌 영속성 전이(CASCADE)와 고아 객체
CASCADE : 특정 엔티티를 영속상태로 만들 때 연관된 엔티티도 함께 영속 상태로 만들고 싶을 때
parent entity와 child entity가 존재할 때, parent객체 하나와 child 객체 2개를 만들어보자. parent 위주로 코드를 짜서 영속시키고 싶은데 persist는 세 객체 모두 던져야한다. 하지만 이때 parent class에서 join된 child객체를 "cascade=all"과 같이 작성한다면 연관관계 메서드를 이전에 호출했다는 가정하에 parent만 영속시켜도 두 child객체 또한 영속된다.
영속 전이는 연관관계가 많아지면 사용하는 것이 어렵다. 완전 종속의 경우에 사용한 것이 효과적이다.
영속전이 사용이 효과적인 경우
1. 라이프 사이클이 유사할 때
2. 단일 소유자일때 고아 객체 제거 : 부모 엔티티와 연관관계가 끊어진 자식 엔티티를 자동으로 삭제
orphanRemoval=true
즉, 객체에서 연관관계가 끊어지면 RDB에서도 적용이 되는 것이다.
고아 객체 제거 또한 참조하는 곳이 하나일 때 사용해야한다.(개인소유)
값 타입
JPA 데이터 타입 분류
* entity type
* value type entity type은 @Entity로 정의하는 객체이다. 데이터가 변해도 식별자로 지속해서 추적가능하다.
vlaue type은 int, Integer, String처럼 단순히 값으로 사용하는 자바 기본 타입이나 객체이다. 식별자가 없고 값만 있으므로 변경 시 추적 불가하다.
값타입 분류
1. 기본값 타입
* 자바 기본 타입 : int, String...
* 래퍼 클래스 : Integer, Long
* String
2. 임베디드 타입
3. 컬렉션 값 타입📌 기본값 타입
기본값 타입은 생명주기가 엔티티에 의존한다. 값타입은 공유하면 안된다. 자바의 기본 타입은 절대 공유할 수 없기때문이다. Integer같은 래퍼 클래스나 String 같은 특수 클래스는 공유 가능한 객체이지만 변경할 수 없다.
📌 임베디드 타입
임베디드 타입
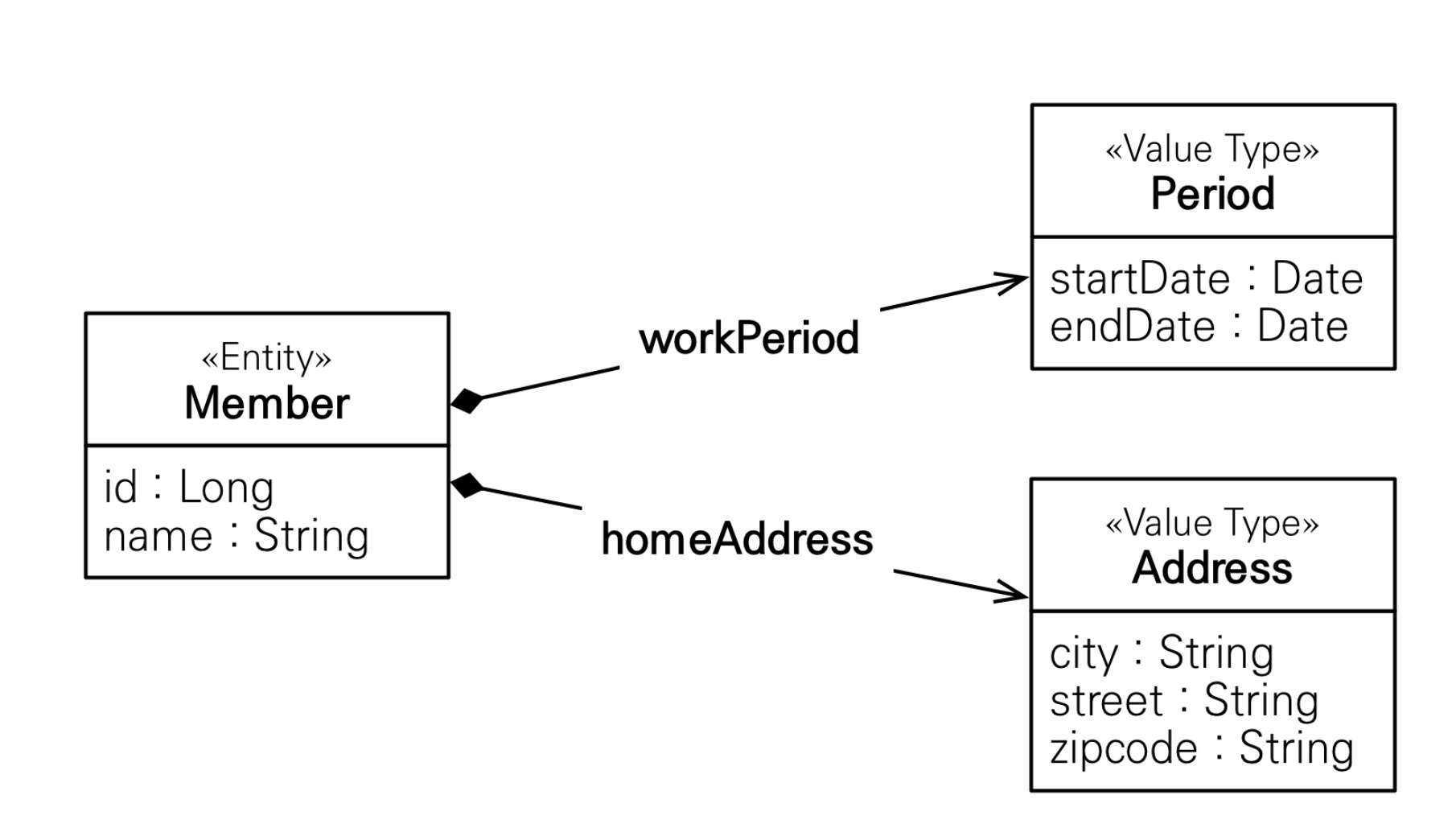
1. 새로운 값 타입을 직접 정의할 수 있다.
2. JPA는 임베디드 타입이라고 함.
3. int, String과 같은 값 타입장점은 아래와 같다.
1. 재사용
2. 높은 응집도
3. 해당 값 타입만 사용하는 의미있는 메소드 생성 가능
4. 임베디드 타입을 포함한 모든 값 타입은 값 타입을 소유한 엔티티에 생명주기를 의존함@AttributeOverride : 속성 재정의
한 엔티티에서 같은 값 타입을 사용하면 컬럼명이 중복된다. 이때 @AttributeOverrides, @AttributeOverride를 사용해서 컬럼 명 속성을 재정의한다.
📌 값 타입과 불변 객체 & 비교
<<주의>>
임베디드 타입 같은 값 타입을 여러 엔티티에서 공유하며 위험하다.(side effect발생)
예를 들어 회원1과 회원2가 같은 주소 OldCity값을 임베디드로 가지고 있을 때, city값을 NewCity로 변경한다면 둘다 같은 값을 참조하기 때문에 둘다 같은 NewCity로 변경된다.
그렇기 때문에 값 타입의 실제 인스턴스 값을 공유하는 것은 위험하다. 따라서 값(인스턴스)를 복사해서 사용하는 것이 좋다.
불변객체
위의 오류발생 대문에 객체 타입을 수정할 수 없게 만들면 부작용을 원천 차단할 수 있다. 따라서 값 타입은 불변 객체로 설계해야한다. 이것을 불변 객체라 한다. 생성자로만 값을 설정하고 수정자를 만들지 않으면 된다.
값 타입의 비교
값 타입은 인스턴스가 달라도 그 안에 값이 같으면 같은 것으로 봐야한다.
- 동일성 비교 : 인스턴스의 참조 값을 비교, ==사용
- 동등성 비교 : 인스턴스의 값을 비교, equals()사용
📌 값 타입 컬렉션
* 값 타입을 하나 이상 저장할 때 사용
* @ElementCollection, @CollectionTable 사용
* 데이터베이스는 컬렉션을 같은 테이블에 저장할 수 없다. 따라서 컬렉션을 저장하기 위한 별도의 테이블이 필요하다.값 타입 컬렉션의 생명주기는 자신을 가지는 엔티티의 생명주기와 같이한다.(영속성 전이 + 고아객체 제거 기능을 필수로 가짐) 컬렉션들은 지연로딩이다.(임베디드 객체는 지연로딩이 아니다.)
값 타입 컬렉션 제약사항
1. 값 타입은 엔티티와 다르게 식별자 개념이 없다.
2. 값은 변경하면 추적이 어렵다.
3. 값 타입 컬렉션에 변경사항이 발생하면, 주인 엔티티와 연관된 모든 데이터를 삭제하고,
값 타입 컬렉션에 있는 현재 값을 모두 다시 저장한다.
4. 값 타입 컬렉션을 매핑하는 테이블은 모든 컬럼을 묶어서 기본 키를 구성해야한다. : null 입력 x, 중복저장 x--> 결론적으로 효울이 떨어져서 사용하면 안된다.(쿼리가 굉장히 많아진다. 값 하나 지우는데 따라 지워지는 데이터가 굉장히 많아질 수 있고 입력되는 데이터 또한 굉장히 많아질 수 있다.)
값 타입 컬렉션 대안으로는 일대 다 관계가 있다.
엔티티타입 특징
* 식별자 o
* 생명주기 관리
* 공유값타입 특징
* 식별자 x
* 생명주기를 엔티티에 의존
* 공유하지 않는 것이 안전(복사해서 사용)
* 불변 객체로 만드는 것이 안전
(위 모든 자료와 사진의 출처는 inflearn 김영한 강사님의 강의자료입니다.)
