최근, 파이썬으로 데이터 분석을 하려고 도서관에서 책을 빌려와서 하던 도중 인코딩 에러가 발생했다.
인코딩 에러
'cp949' codec can't decode byte 0xeb in position 18: illegal multibyte sequence
utf-8로 되지 않아 cp949로 진행했는데, 다시 cp949가 안되어 utf-8로 진행했고, 문제 없이 챕터를 마칠 수 있었다. 왜 번복해서 사용하게 되었는지는 모르겠으나, 일단 인코딩 에러이므로, 이에 대해 정리하고자 한다.
인코딩
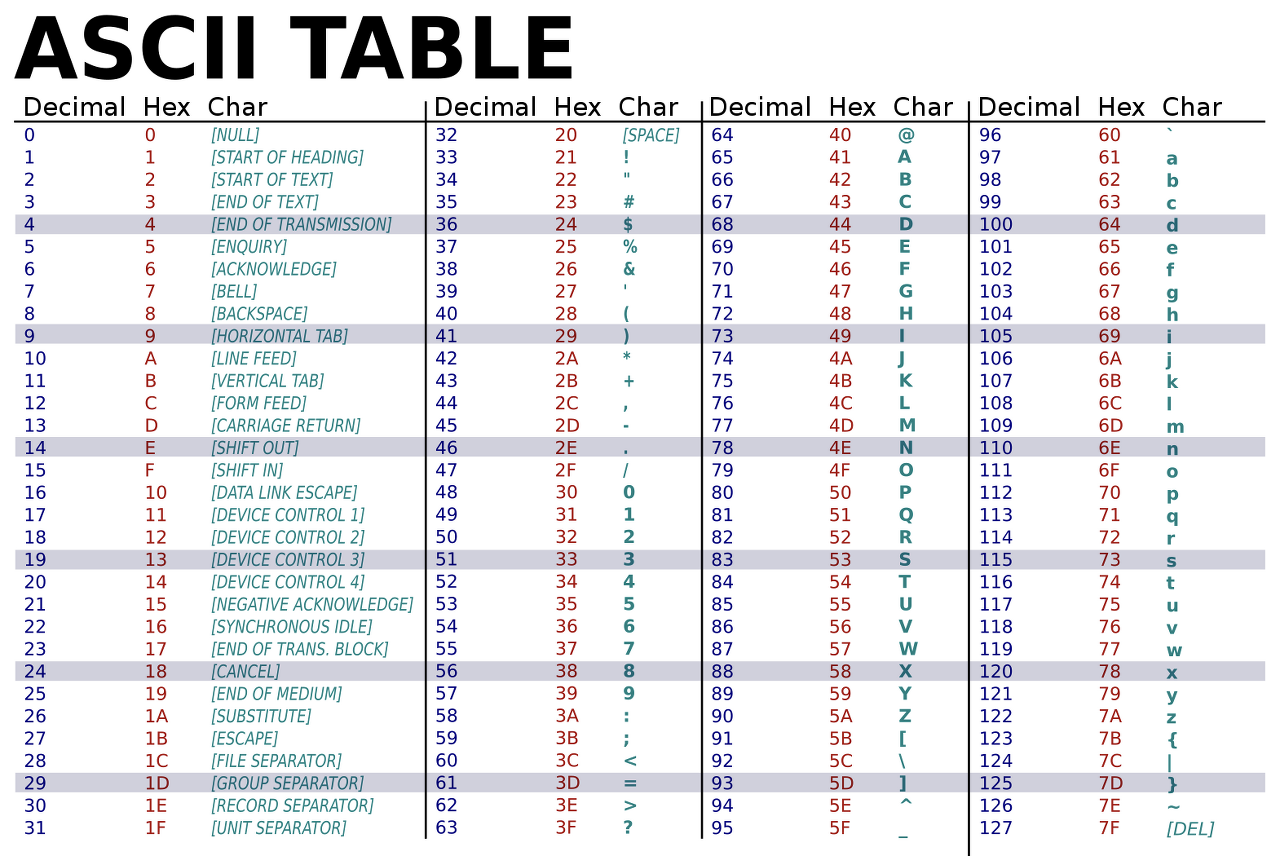
인코딩은 어떤 정보를 특수한 목적을 가지고, 다른 형태로 변환하는 행위를 의미한다. 즉, 여기서는 텍스트(문자)를 기계가 이해할 수 있는 언어(기계어)로 표현하는 방법을 뜻한다.예를 들면, 대문자 A는 65로, 소문자 a는 97로 나타나진다. 아래는 ASCII (American Standard Code for Information Interchange) 테이블로, 컴퓨터에 사용할 문자를 2진수로 인코딩하기 위한 7비트의 고정길이 코드 체계이다.
한글
한글은 총 글자수가 11,172자가 존재하기 때문에, 아스키테이블과 같은 1바이트(8비트) 체계로는 불가능하다. 더불어 한글은 자음과 모음을 조합하여 (초성, 중성, 종성을 조합) 글자를 표현하기 때문에, 이를 표현하기 위해 조합형과 완성형 방식으로 나뉘게 되었다.조합형 방식
조합형 방식은 자음 + 모음 또는 초성 + 중성 + 종성을 조합하여 글자를 만들어 내는 방식이다. 조합형은 2바이트 체계로 총 16바이트에서 앞의 1비트는 한글임을 알리는 비트로 사용하고, 나머지 15비트는 초성, 중성, 종성을 각 5비트로 구분지어서 사용한다.자음과 모음 모든 조합을 표현할 수 있지만, 중성의 첫비트가 0일 경우 다른 ASCII 코드와 충돌할 수 있다는 단점이 있다.
완성형 방식
완성형 방식은 사용빈도가 낮은 글자(예 : 첣, 껽 등)들을 제외하고 한글의 모든 글자(가 ~ 힣)를 각각 숫자로 매핑한 방식이다. EUC-KR, CP949, MS949 등이 완성형 인코딩 방식이다. 자음과 모음의 조합을 해석하는데 들어가는 비용이 줄어 조합형보다는 효율적이라 할 수 있으나, 사용하지 못하는 글자가 있다는 단점이 있다.유니코드
1991년 전 세계 모든 문자를 매핑하는 문자 집합인 유니코드가 등장하게 되었다. 유니코드는 완성형과 같이 각 글자에 숫자를 매핑한 방식으로, 문자 하나를 4바이트(32비트)로 지정하고 있다. ASCII 코드가 1바이트 공간을 차지하는데 비해, 유니코드가 4바이트를 차지하여 비효율인 점을 보완하기 위해 UTF-8, UTF-16 등이 등장하게 되었다.UTF-8(Unicode Transformation Format - 8)은 가변 길이 문자 인코딩 방식으로, ASCII 포함 전 세계의 문자를 지원하고, 한글을 표현하는데는 3바이트를 사용한다.
오류 해결
생각보다 오류 해결은 간단하다. 뒤에 encoding을 더해주기만 하면 된다.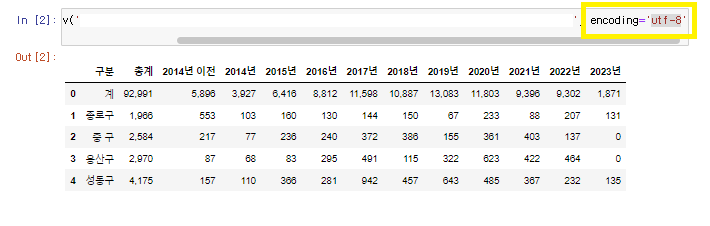
utf-8로 인코딩을 하고 다시 실행했을 때, 문제 없이 진행할 수 있었다.

개인 공부용