Hash란?
- 데이터를 다루는 기법 중 하나
- 검색과 저장이 아주 빠름
- key와 value로 이루어져있고, key값이 배열의 인덱스로 변환되기 때문- 검색, 저장의 평균적인 시간 복잡도 : O(1)
Hash Function
- 임의의 길이의 데이터를 고정된 길이의 데이터로 매핑하는 함수
- 저장되는 값들의 key값을 hash function을 통해서 작은 범위의 값들로 바꿔줌
- 이를 통해 반환된 데이터의 고유 숫자 값을 hashcode라 함
- ex) 데이터를 문자열로 받았을 때 문자들의 아스키코드 값을 더하는 과정으로 문자열을 정수값으로 변환할 수 있음
hello -> h(104) + e(101) + l(108) + l(108) + o(111) = 532
좋은 hash function이란?
- key의 일부분이 아닌 전체를 참조하여 해쉬값을 만들어 냄
- 계산이 간단해야 함
- 입력 원소가 해시 테이블 전체에 고루 저장되어야 함
- hash table 성능 향상에 필수적
- hash function을 무조건 1:1로 만드는 것보다 충돌을 최소화하는 방향으로 설계,
발생된 충돌에 대응하는 것이 중요 - 충돌이 많아질 수록 검색 시 시간 복잡도가 O(n)에 가까워짐
충돌 해결법
-
Open Address(개방 주소법)
해시 충돌 시(= 삽입하려는 해시 버킷이 이미 사용중인 경우) 다른 해시 버킷(데이터를 저장하기 위한 공간)에 해당 자료를 삽입하는 방식
- 충돌이 발생하면 데이터를 저장할 장소를 찾아헤맨다.
- Worst case : 비어있는 버킷을 찾지 못하고 탐색을 시작한 위치까지 되돌아올 수 있음
- 버킷을 채운 밀도가 높아질 수록 Worst case발생 빈도가 높아짐
- 여러 방법들
1. Linear Probing(선형 탐사)

: 순차적으로 탐색하며 비어있는 버킷을 찾을 때까지 계속 진행
2. Quadratic Probing(2차 탐사)

: 2차 함수를 이용하여 탐색할 위치 찾기
3. Double hashing Probing(이중 해싱) : 하나의 해시 함수에서 충돌이 발생하면 2차 해시 함수를 이용해 새로운 주소를 할당하며, 1,2번 방법에 비해 많은 연산량을 요구 -
Seperate Chaining (분리 연결법)
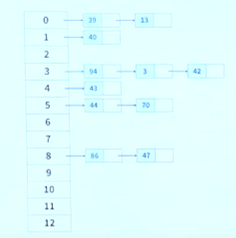
해시 충돌이 잘 발생하지 않도록 보조 해시 함수(Key의 해시 값을 변형하여 충돌 가능성을 줄임)를 통해 조정할 수 있다면 Worst case에 가까워지는 빈도를 줄일 수 있음
-> Java 7에서는 분리 연결법을 이용하여 HashMap 구현하고 있음
두 가시 구현 방식이 있으며, 데이터의 개수로 방법 선택- 연결 리스트 방식(Linked List)
: 각각의 버킷들을 연결 리스트로 만들어 충돌이 발생하면 해당 버킷의 리스트에 추가
삭제, 삽입이 간단함
작은 데이터들을 저장할 때 연결 리스트 자체의 오버헤드가 부담됨.
버킷을 계속해서 사용하는 Open Address 방식에 비해 테이블의 확장을 늦출 수 있음 - 트리 방식(Red-Black Tree)
: 메모리 측면에서 보았을 때 데이터 개수가 많을 때 트리 이용, 적을 때 연결 리스트 이용 * 데이터의 크기 기준 : 6개의 key-value쌍 => 연결리스트 이용 / 8개의 key-value 쌍 => 트리 이용Open Address vs Seperate Chaining
- 연결 리스트 방식(Linked List)
-
두 방식 모두 Worst Case : O(n)
-
Open Address방식은 연속된 공간에 데이터를 저장하기 때문에 Seperate Chaining에 비해 캐시 효율이 높음 -> 즉, 데이터의 개수가 충분히 적다면 Open Address 방식이 더 성능 좋음
-
Seperate Chaining 방식에 비해 Open Address 방식은 버킷을 계속해서 사용하기 때문에 Seperate Chaining 방식을 사용한다면 테이블의 확장을 보다 늦출 수 있음
해시 버킷 동적 확장
해시 버킷의 개수가 적다면 메모리 사용을 아낄 수 있으나 충돌로 인해 성능 상 손실 발생함 -> HashMap은 key-value 쌍 데이터가 일정 개수 이상이 되면 해시 버킷의 개수를 두배로 늘림
`* 일정 개수 : 현재 데이터의 개수가 해시 버킷의 개수의 75%가 되게 하는 될 때
0.75 = load factor 라고 불림
Secure Hash Algorithm(SHA)
- NSA(미국 국가 안보국)에 의해 1993년 처음 개발된 해시 알고리즘
- 현재 주로 사용되는 것은 SHA-2함수군으로, 다이제스트(메시지의 해시 함수 결과값)의 길이에 따라 SHA-256, SHA-512 등으로 나뉨
- SHA-0, SHA-1까지는 해시 충돌성이 존재하나 SHA-256, SHA-512는 해시 충돌성이 사실상 0에 수렴함
* 256 : 해싱을 하면 2^256개의 해시값 중 하나가 나옴
해시의 응용
- 무결성 검증
- 클라우드 스토리지에서 동일한 파일 식별 및 수정된 파일 검출
- 패스워드 암호화 및 검증
- 블록체인
- Git
SHA-256 해시 변환
input : NATHAN_CS_STUDY
output : 26E9D96EDE39CB9FC7B61134DCDD7B9B1F46191C74BAEF939ABC3952BE86B2F1
input : NATHAN_CS_STUDY.
output : E004168F4260E23B8297DD46241B5E9AAE5A54B076ED4558BEDCECC24F410A37
input
: 매주 목요일 21시에 모여서 1시간정도 스터디
선행과제
발표를 맡은 사람은 스터디전까지 해당 주제에 대해 깊게 공부해오기
발표를 하지 않는 사람도 발표주제를 보고 질문할 부분 생각해보기
발표에 사용할 자료는 자유롭게 준비해서 PR 날려두기
스터디 시간에 할 일
매주 돌아가면서 발표하는 사람, 듣는 사람 나누어 진행
발표하는 사람은 자신이 정한 이번주 주제에 대해 공부한 것을 설명
듣는 사람은 발표를 듣고 이해가 안되거나 궁금한 점 적극적으로 질문
스터디 이후에 할 일
다음 주 발표주제 정하기
output : A29142873A808E028E23E9DC59FE1CD7F57F27F2C349895B46695ACF206C15D0
참고자료
https://siyoon210.tistory.com/85
https://github.com/JaeYeopHan/Interview_Question_for_Beginner/tree/master/DataStructure#hash-table
https://www.youtube.com/watch?v=Rpbj6jMYKag
