리덕스 설치와 필요성 소개
리덕스란?
리덕스를 사용하기 전까지는, 여러 컴포넌트들에서 쓰이는 공통적인 데이터들을 전달하려면 하나의 부모 컴포넌트에서 자식 컴포넌트들에게 일일히 전달해주는 방식을 사용해야 했다. 그러나 컴포넌트들의 양이 너무 많아지고, 매번 수동적으로 부모 컴포넌트들을 만들어준 뒤에 자식 컴포넌트들에게 보내주는 방식이 매우 비효율적이었기 때문에, 하나의 중앙 스토어에서 데이터를 관리해주는 방식이 필요해졌다. 그 역할을 해주는 것이 바로 리덕스(Redux)이다.
Next에 리덕스를 붙이려면 과정이 매우 복잡한데, 이를 쉽게 하기 위해서는 next-redux-wrapper 라이브러리를 사용하면 된다. next-redux-wrapper에서는 store 폴더를 별도로 생성하여 그 안에 configureStore.js 파일을 생성하여 사용하면 된다.
import { createStore } from "redux";
const { createWrapper } = require("next-redux-wrapper");
const configureStore = () => {
const store = createStore(reducer);
return store;
};
const wrapper = createWrapper(configureStore, {
debug: process.env.NODE_ENV === "development",
});
export default wrapper;configureStore.js 파일을 생성했으면 _app.js 파일의 마지막 export 구문을 wrapper.withRedux로 감싸주면 된다.

리액트를 사용할때는 중앙 저장소 역할을 하는 것을 하나 정도는 두는 것이 좋다. (Context API, Redux, MobX, Apollo..) 데이터 관리가 용이한데 컴포넌트 별로 데이터를 들고 있게되면 서로 컴포넌트간에 데이터가 불일치해서 다른 화면을 렌더링 할 수도 있다. 그러므로 데이터는 중앙에서 한번에 관리하는 것이 좋다.
여기서 MobX와 Redux의 차이는 Redux는 코드의 양이 많아지는 대신, 원리가 매우 간단하기 때문에 에러가 발생하여도 해결이 용이하고, MobX는 코드의 양이 훨씬 줄어드는 대신 에러가 발생하였을때 tracking 하기가 힘들어진다.
만일 라이브러리를 사용하고 싶지 않다면, Context API를 사용하면 되는데 라이브러리에 비해 비동기를 지원하기에 어렵다는 단점이 있다. 중앙 저장소가 존재할 경우, 서버에서 데이터를 많이 받게 되는데 이는 비동기이다. 비동기를 다룰 때에는 서버의 고장이나 네트워크 에러와 같은 실패에 대비해야 하는데 (데이터 요청 - 성공 - 실패), 이를 Context API에서 구현하려면 사용자가 일일히 구현을 해줘야 한다.
// UserProfile.js에 있는 코드
useEffect(() => {
axios.get('/data')
.then(() => {
setState(data)
})
.catch(() => {
setError(error);
})
})
// LoginForm.js에 있는 중복된 코드
useEffect(() => {
axios.get('/data')
.then(() => {
setState(data)
})
.catch(() => {
setError(error);
})
})컴포넌트는 화면을 그리는데에만 집중하는 것이 좋은데, 데이터까지 다루게 될 경우 의도치 않은 코드 중복이 발생하게 된다. 하지만 Redux와 MobX와 같은 라이브러리를 사용하게 되면 위와 같은 비동기 동작을 맡길 수 있다. 그렇기 때문에 데이터를 관리할때에는 처음부터 Redux와 MobX와 같은 라이브러리를 사용하는 편이 좋다.
리덕스의 원리와 불변성
Redux는 Reduce에서 이름을 따온 것이다. Redux에서는 데이터를 변경하려면 action을 필수적으로 만들어야 한다. 중앙 저장소에 있는 데이터를 수정할 일이 생기면 action을 생성하고 이 action을 dispatch 하면 중앙 저장소에 있는 data가 수정되게 된다. 이때 이 중앙 저장소에 있는 data들을 가져다 쓰는 컴포넌트들의 데이터도 모두 수정된다.
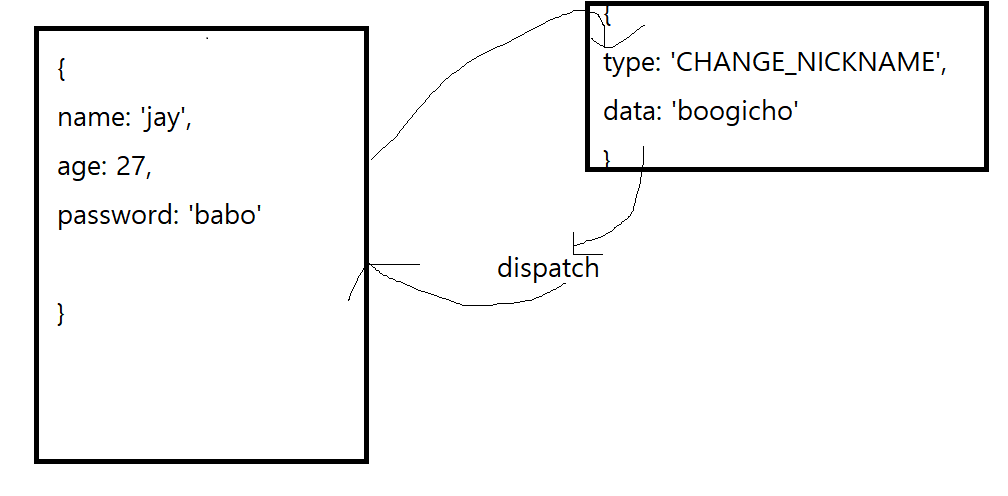
하지만 자바스크립트에서는 dispatch만 해준다고 해서 해당 action이 뭘 의미하는지 모르기 때문에, reducer를 사용해서 데이터를 어떻게 바꿀 것인지 사용자가 명시해주어야 한다.
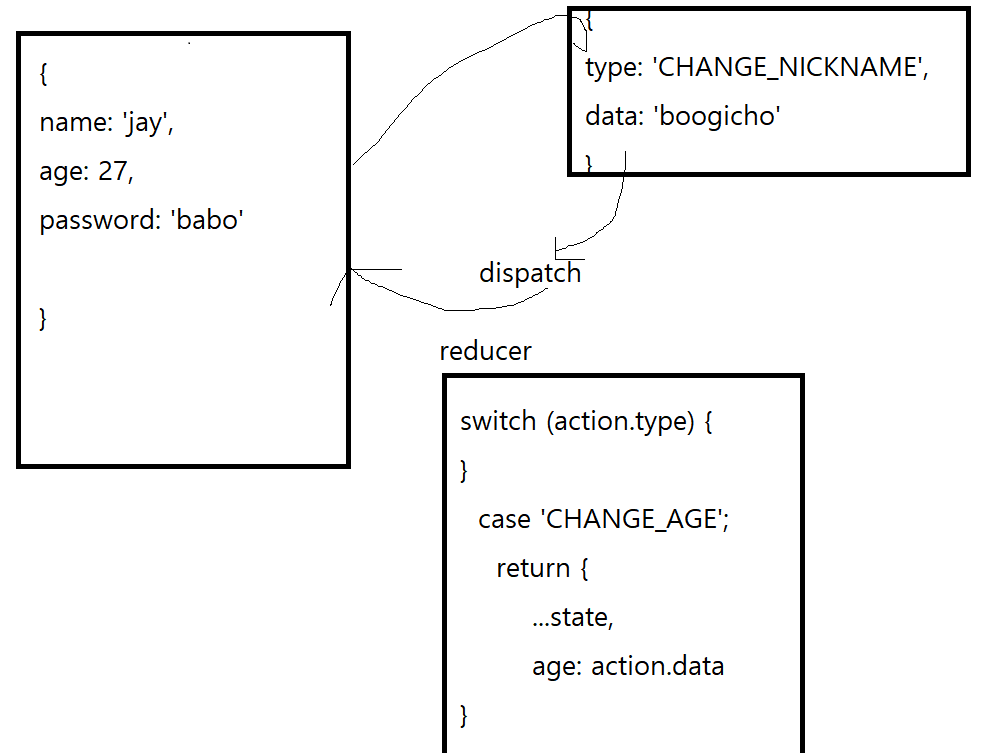
이렇게 reducer와 action을 사용하게 되면 어떤 action과 reducer가 무슨 일을 하고 있는지 한눈에 확인할 수 있기 때문에, 에러가 발생했을 시에 tracking 하기에 몹시 용이하다.
또한 히스토리처럼 Reducer와 action이 나열되어 있기 때문에, devTools를 사용하면 데이터를 뒤로 돌렸다가 다시 앞으로 감는 등의 테스트를 하기에 용이하다.
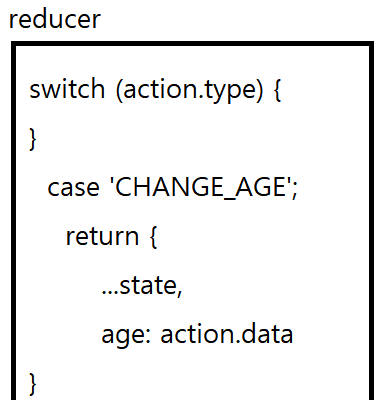
그리고 reducer 구문 안에서 위 그림과 같이 return을 적어 주는 이유는 불변성(Immutability) 때문이다. JavaScript에서 {} === {}는 false이고, const a = {}; const b = a; a === b // true이기 때문에 객체를 새로 만들면 false이고 객체의 참조관계가 있으면 true라는 사실을 알 수 있다. 그러므로 위 구문에서는 return 안에 새로운 객체를 만들어 주었기 때문에 계속 다른 객체를 return 하는 것이다. 여기서 객체를 새로 만드는 이유는 변경된 내용들을 추적하기 위함이다.
아래 코드를 보면 prev에는 이전 기록이 있고 next에는 다음 기록이 있는데 이전기록도 남아있고 다음 기록도 남아있다. 즉, 이전 기록과 다음 기록이 남아있기 때문에 새롭게 객체를 만들어 주는 것이다.
const prev = { name: 'zerocho'}
const next = { name: 'boogicho'}만일
const prev = { name: 'zerocho'}
const next = prev;
next.name = 'boogicho'라고 직접 바꿔버리면
prev.name; // boogicho참조관계이기 때문에 위와 같이 나오게 된다. 즉, 히스토리가 사라진다. 그리고 스프레드 연산자를 통해 참조관계를 유지하는 것은 메모리를 아끼기 위해서이다.
{
...state,
name: action.data,
}
// vs
{
name: action.data,
age: 27,
password: 'babo'
}리덕스 실제 구현하기
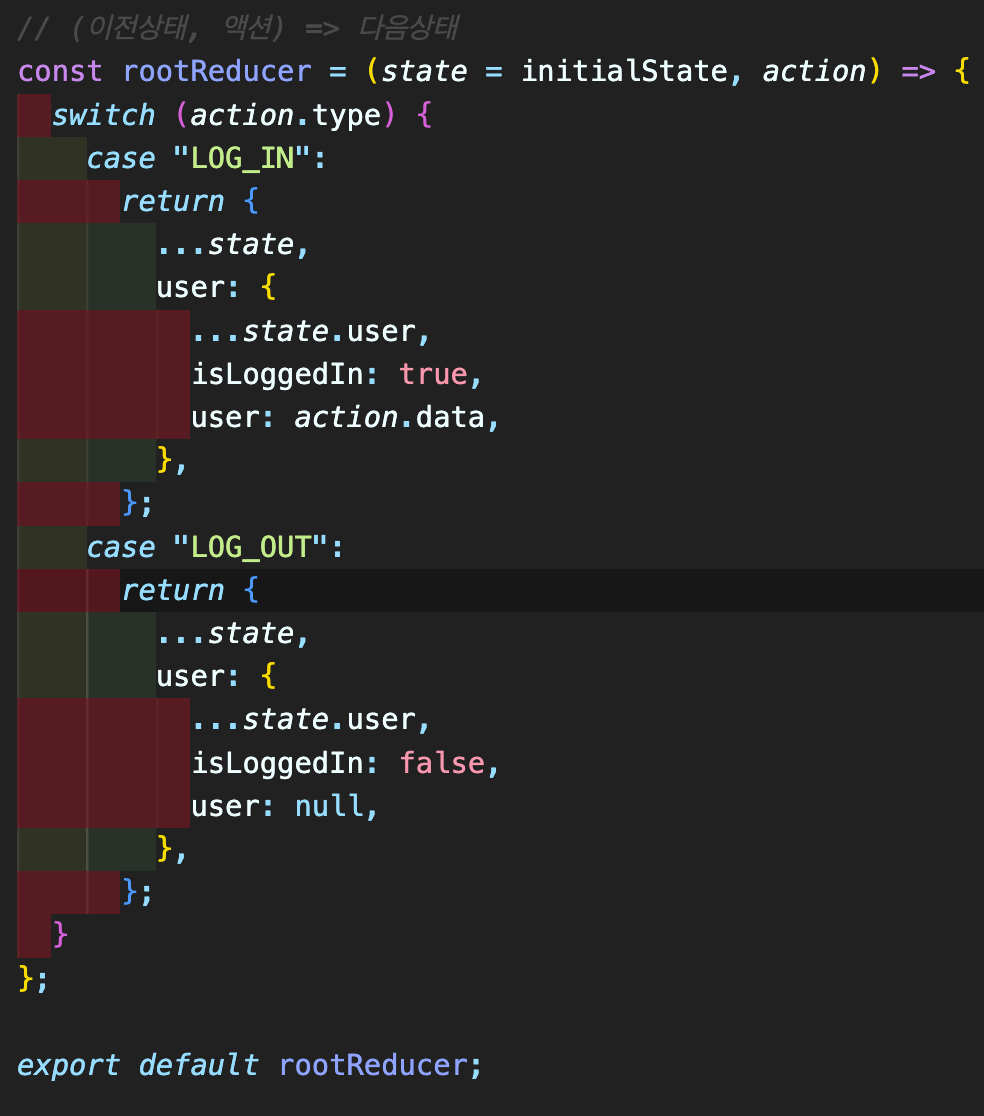
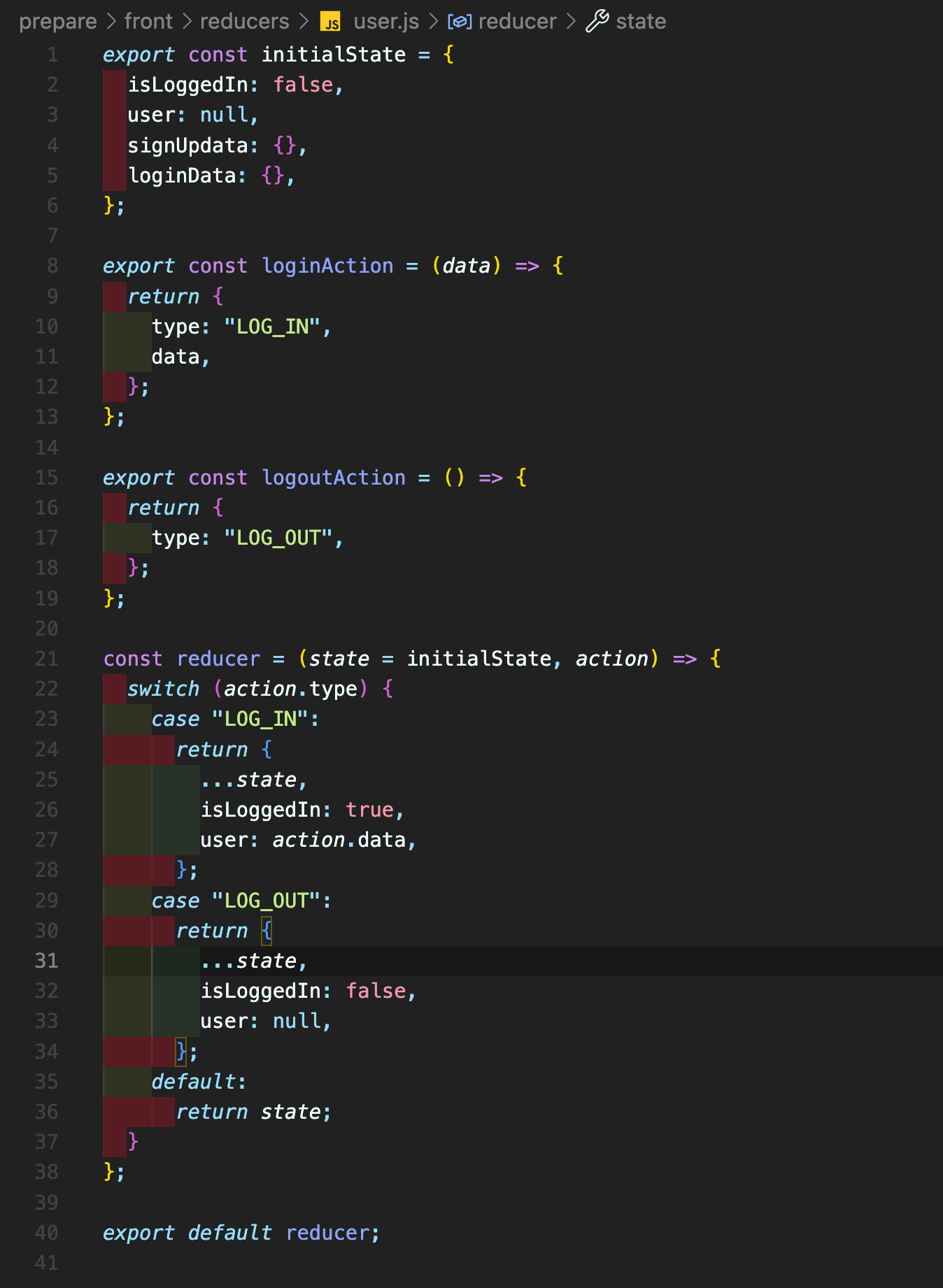
우선, reducer를 모아놓을 폴더일 reducers 폴더를 생성한 후, index.js 파일을 생성한다. rootReducer에는 이전 상태와 action을 parameter로 받아, switch 문으로 다음 상태를 업데이트 해준다. 지금은, 로그인, 로그아웃 기능을 구현하기 위해 상단에 initialState를 선언해 준 뒤, 로그인, 로그아웃 case를 구현해 놓았다.
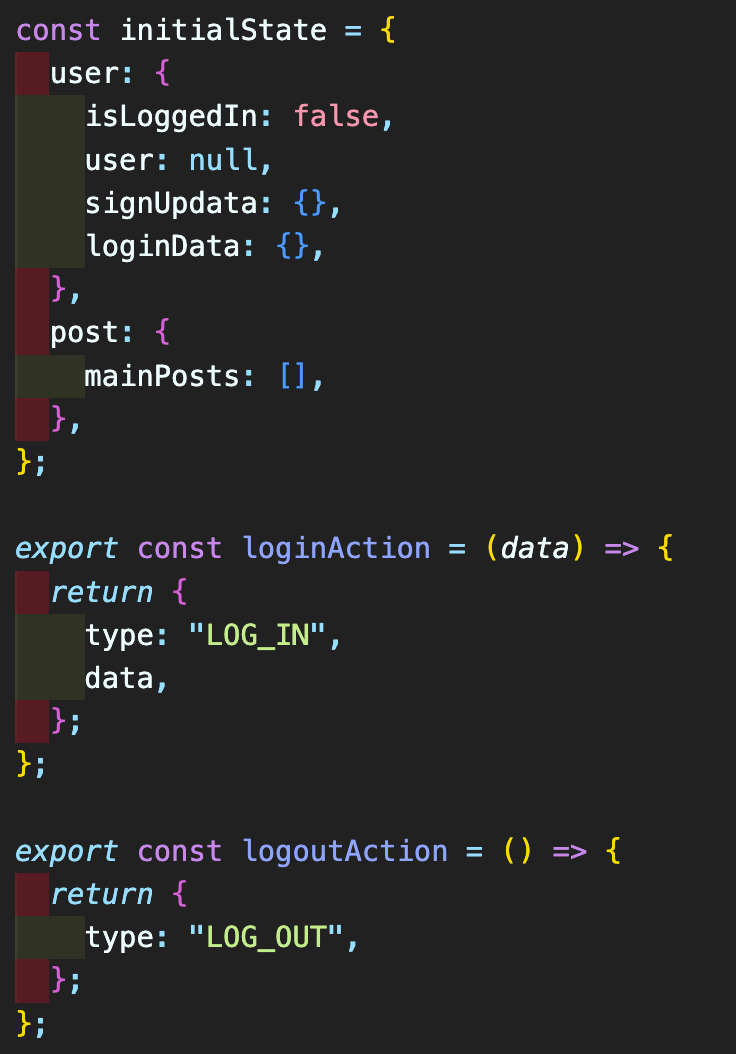
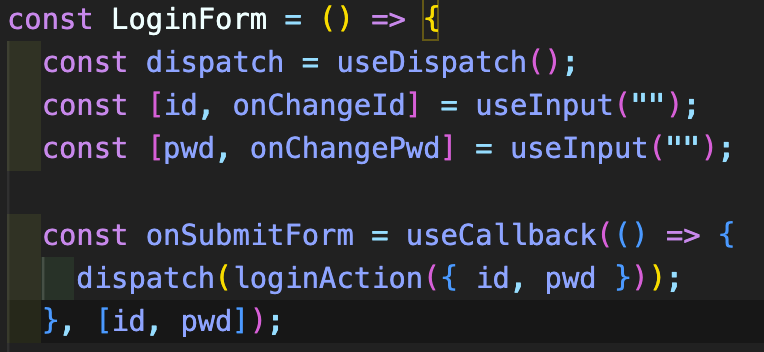
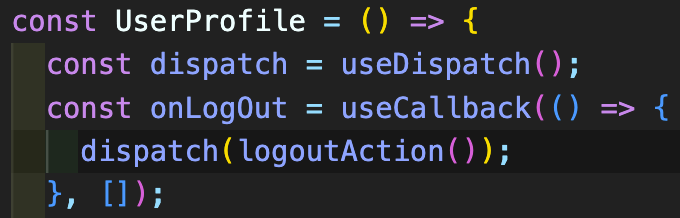
그런 다음, 앞서 useState로 구현해놓았던 AppLayout, LoginForm, UserProfile 컴포넌트들의 state를 변경해 주었다. 여기서, useSelector와 useDispatch는 react-redux 라이브러리의 Hooks들로, 각각 스토어의 상태값 반환과 action 발생을 해준다.

리듀서 쪼개기
지금은 리듀서의 양이 작지면, 프로젝트의 규모가 커지게 되면 사용하게 될 리듀서의 양이 늘어나게 된다. 그렇기 때문에, 컴포넌트처럼 리듀서도 공통적인 파일로 쪼개서 사용하는 것이 좋다.
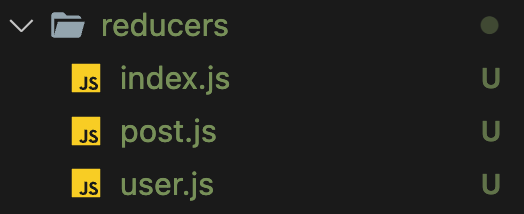
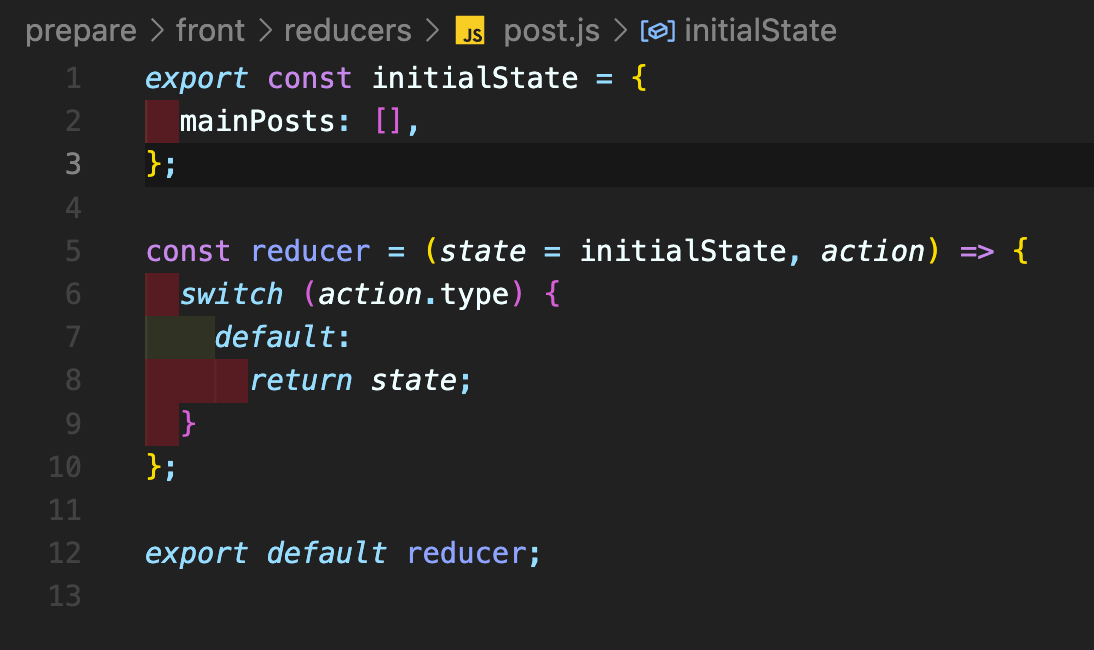
reducer 폴더 안에 분리시킬 post, user.js 파일을 생성하고, index.js에 있던 initialState와 action, reducer들을 각각의 파일로 옮겨 주었다.
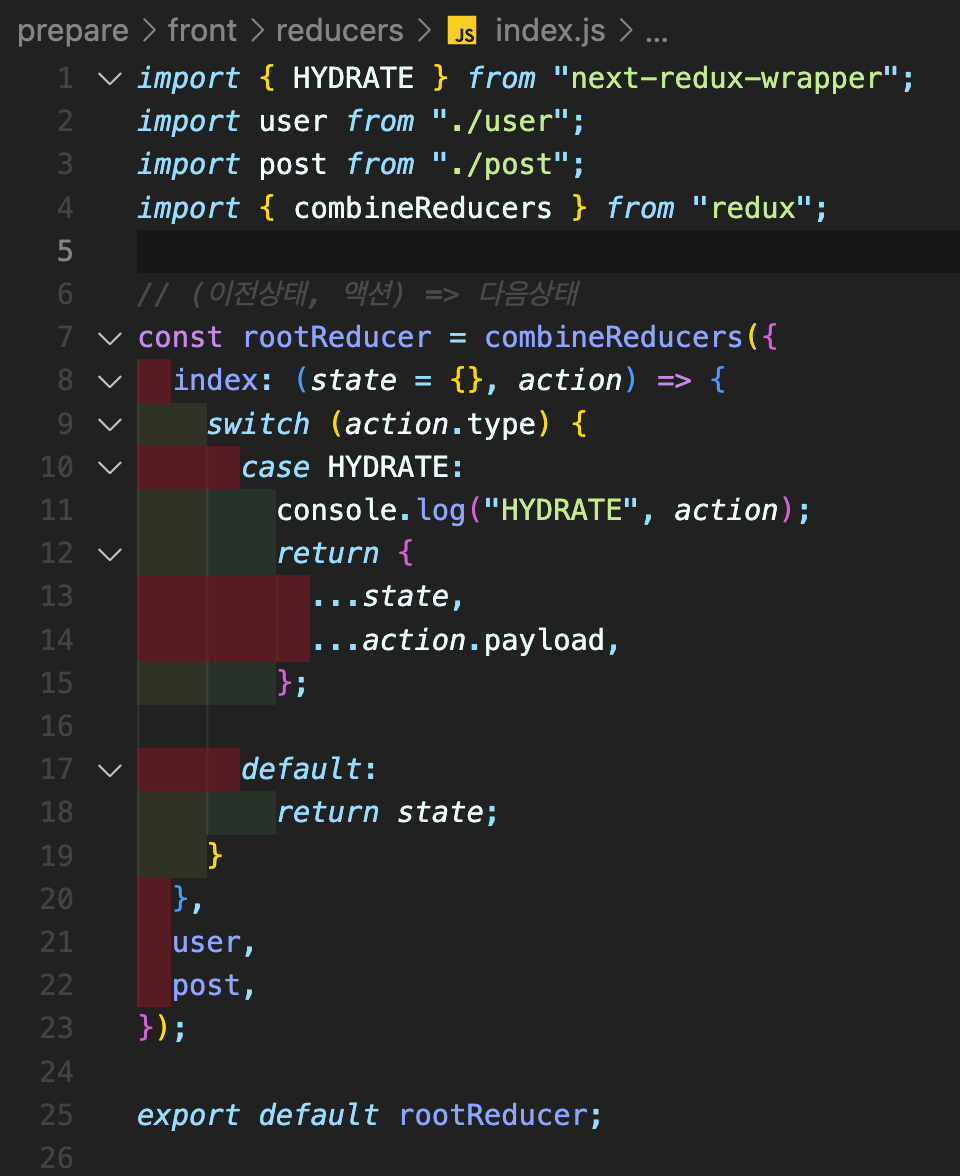
그리고 index.js에서 해당 reducer들을 import 해오면 되는데, 리덕스에서는 분리한 reducer들을 합쳐서 사용하기 위해 combineReducers를 사용한다. 이때, 추후 SSR 때문에 HYDRATE를 위해 index 항목을 추가해 준다.
더미 데이터와 포스트폼 만들기
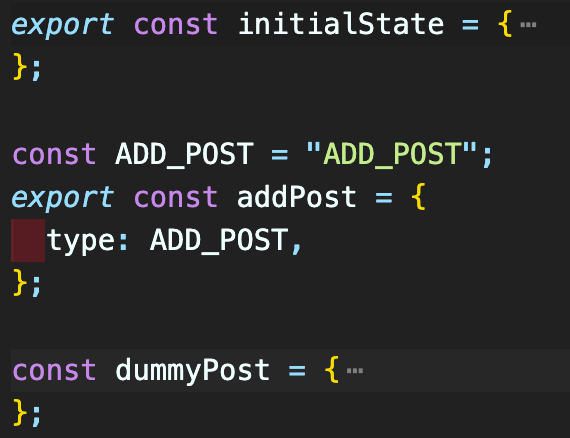
더미 데이터로 게시글을 구현하기 위해, 기존 게시글과 추가될 게시글을 더미 데이터로 만들어 놓았다. 그리고 action type을 상수로 분리해 놓았는데, 이렇게 해놓는 이유는 자동완성이 되어서 오타가 줄고, 재활용하기 편리하기 때문이다.
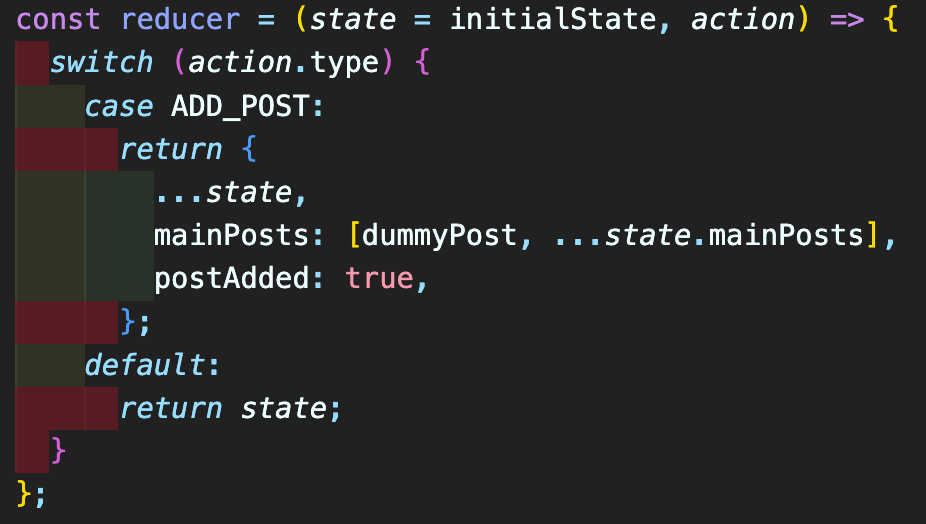
ADD_POST action이 dispatch 되면, postAdded가 true가 되고, mainPosts에 dummyPost가 추가되게 된다. 이때 ...state.mainPosts 앞에 dummyPost를 쓴 이유는, 새 게시글이 추가되면 기존 게시글의 위로 나타나게 해야 하기 때문이다.
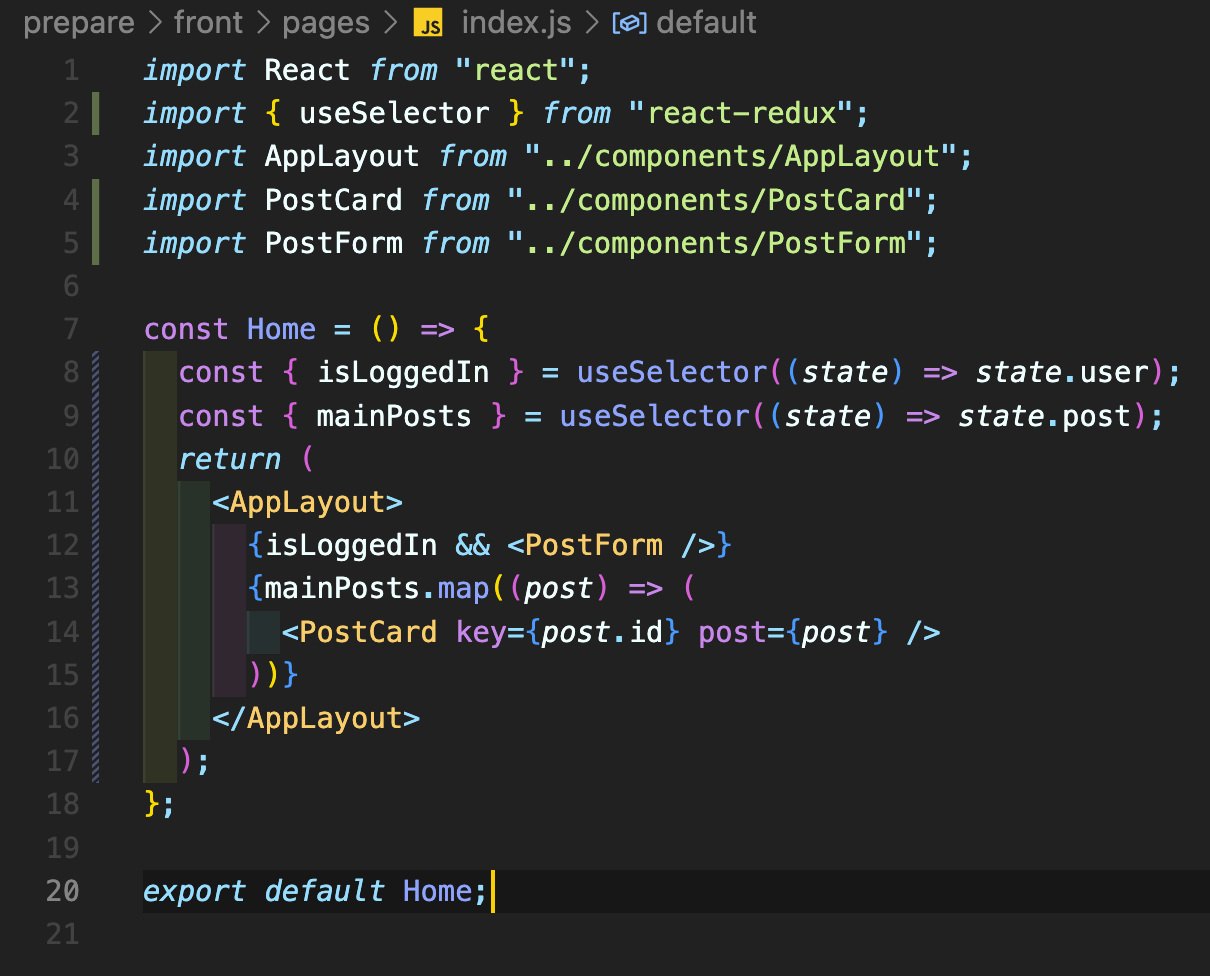
기존의 index.js를 위와 같이 수정하였다. 로그인이 되었을 시에만 postForm, 즉 게시글 입력창을 보여주고, 아래에는 mainPosts를 map으로 돌려 게시글들을 나타내게 하였다.
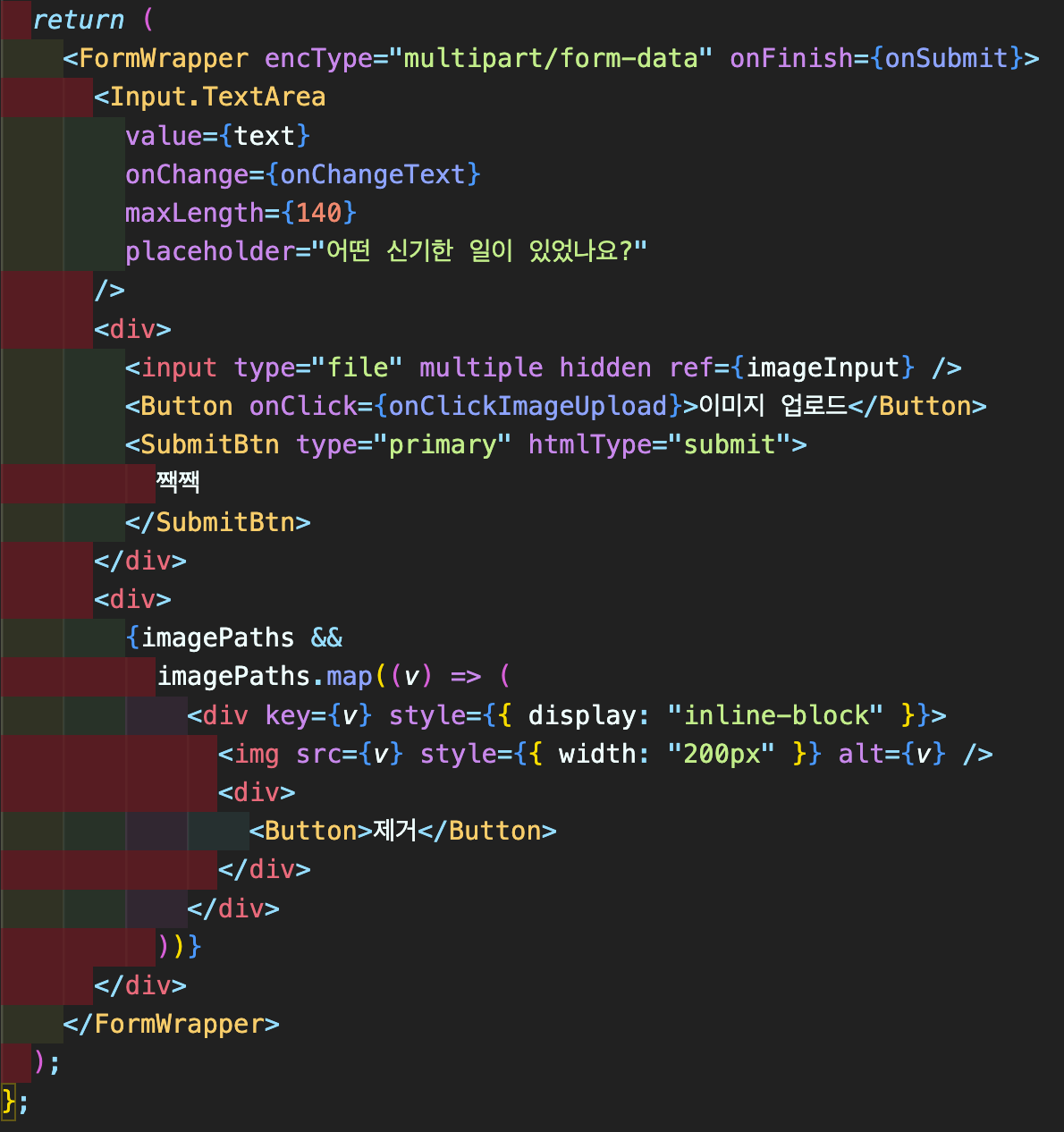
PostForm의 형태이다. 여기서 이미지 업로드 버튼을 눌렀을 때, 파일 선택기가 나오게 하기 위해서 useRef를 활용해 버튼을 클릭했을 때, imageInput.current.click() 함수가 실행되게 하였다.