바인드 변수 인풋값에 따라 실행계획을 바꿔가면서 실행하기
주문 테이블에서 배송지 첫 글자에 따라서 분포 %가 나뉜다.
A로 시작하는 배송지는 40%
B로 시작하는 배송지는 20%
C~H로 시작하는 배송지는 5%
I~R로 시작하는 배송지는 1%
분포되어있기 때문에 A와 B로 시작하는 배송지에 대한 주문번호를 가져올때는 TABLE FULL SCAN으로 조회하고 C~R로 시작하는 배송지에 대해서는 INDEX RANGE SCAN으로 가져오는게 좋다. 물론 TABLE FULL SCAN하는 것 보다 INDEX RANGE SCAN이 더 빠르다거나 DB와 테이블의 상태에 따라서 조정해주면 좋다. 아래와 같이 SQL을 작성하면 인풋값에 따라서 실행계획이 다르게 생성된다.
create index ORDER_IDX_01 ON 주문(배송지);
select /*+FULL(A)*/ 주문번호
from 주문 A
where 1=1
and :deliverylocation in ('A','B')
and 주문.배송지 between concat(:deliverylocation,'A') and concat(:deliverylocation,'Z')
union all
select /*+ INDEX(O ORDER_IDX_01)*/주문번호
from 주문 O
where 1=1
and :deliverylocation between 'C' and 'Z'
and o.배송지 between concat(:deliverylocation,'A') and concat(:deliverylocation,'Z');
인풋값을 'A'로 실행할 경우 LAST_CR_BUFFERGETS가 C~Z사이의 인풋값을 받았을 때는 0이 나오고 위 TABLE ACCESS 에서만 버퍼 리드가 있다.
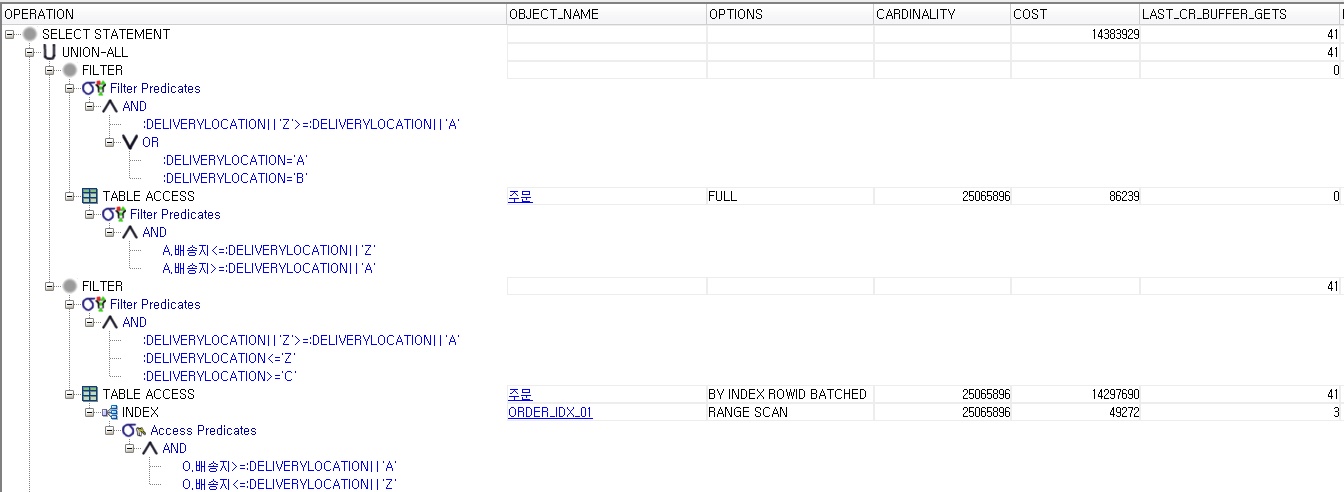
인풋값을 'D'로 실행할 경우 LAST_CR_BUFFERGETS가 A~B사이의 인풋값을 받았을 때는 0이 나오고 아래 INDEX RANGE SCAN과 TABLE ACESS BY INDEX ROWID BATCHED 에서만 버퍼 리드가 있다.
