
-
개념
- 주의 메커니즘만을 사용한 Seq2Seq 모형(like 번역기, 챗봇)
- 문장 내, 문장 간 주의 메커니즘 적용
-
모델 구조
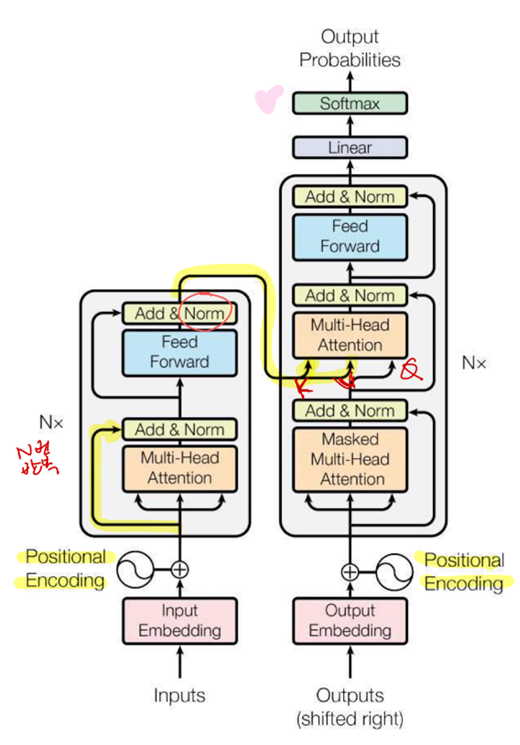
- Query-Key-Value
- 하나의 입력값을 Query, Key, Value 세 가지 값으로 변환
- 사전 검색과 비슷
- Query(질의, 검색어)와 비슷한 Key를 가지는 Value에 높은 주의를 부여
- Multi-Headed Attention
- Q, K, V를 여러가지로 변환하여 주의 메커니즘 적용
- 트랜스포머는 head가 8개
- 문장에서 여러 가지 방식으로 여러 위치에 주의를 줄 수 있음
- Positional Encoding
- 트랜스포머 모형은 순서를 다루는 구조가 없으므로, 문장에서 단어의 위치를 인코딩하여 단어 임베딩에 더해줌
- 정현파 위치 인코딩(sin, cos)
- Residual Block
- 레이어의 입력값을 그대로 레이어의 출력값에 더함
- Residual Block의 레이어는 입력값과 출력값의 차이(잔차, residual)를 학습
- 사라지는/폭발하는 경사 문제에도 효과
- Layer Normalization
- 사례별로 feature들의 평균과 표준편차를 구하여 normalization
- Batch Normalization의 문제점
- 배치가 충분히 커야 하므로, 작은 배치 크기를 쓸 수 없음
- 이미지의 경우 배치 안에 다양한 이미지를 포함할 수 있지만, 자연어 처리는 같은 문장 안의 단어들이 하나의 배치에 포함되므로 분포가 편중
- Query-Key-Value
-
트랜스포머가 잘 작동하는 이유
- CNN은 국소적 관계에 대해, RNN은 순차적 관계에 대해 강한 가정을 가짐
- RNN은 데이터를 순서대로 처리하므로 순서상 가까운 단어가 더 강한 영향
- 그러나 자연어는 반드시 순서대로 처리되는 것은 아님(e.g. 주술 호응)
- 트랜스포머는 순서나 위치에 대한 가정이 없음 → 편향이 적음
귀납 편향(inductive bias)
- 머신러닝 모형이 훈련데이터를 일반화 시킬 수 있는 이유는 모형이 데이터의 구조에 대해 일정한 가정을 하기 때문(e.g. 선형 모형은 데이터가 직선의 패턴을 가질 것으로 가정) ⇒ 이러한 가정을 귀납 편향이라고 함
-
Transformer의 계산 복잡도
- 단어 수가 개면 번 계산이 필요
- 트랜스포머의 장점은 멀리 떨어진 단어 간의 관계도 다룰 수 있다는 것이지만, 실제로 그 관계를 다루려면 지나치게 많은 계산이 필요
- 현재 대부분의 모형은 512~2048개 토큰 정도만을 계산에 포함
-
Transformer의 효율성 높이기
- Longformer : 일정 범위, 일정 간격으로만 attention 적용
- Linformer : attention 적용 전, 입력 값을 작은 차원으로 축소
- Reformer : 처음부터 비슷한 애들끼리만 attention
- Query와 Key를 하나로 통일( → )
- 비슷하다는 걸 어떻게 알 수 있나? LSH(Locality Sensitive Hashing)
비슷한 입력은 최대한 같은 버킷에 들어가게 함(벡터를 일정 방향으로 회전 후, 공간을 분할) 비슷한 데이터를 일일이 검색하는 대신, 같은 버킷의 데이터만 찾으면 됨
.jpg)
ML/DL swimmer