
캐글 2021년 경진대회인 PetFinder.my - Pawpularity Contest 를 바탕으로 딥러닝 기반 컴퓨터 비전 연구 프로젝트를 진행한 내용을 정리하고자 한다.
아래 내용은 연구 기획 단계인 중간 발표 자료이다.
이미 종료된 Competition을 기반으로 discussion과 공개 코드를 면밀히 검토하는 방식은 머신러닝을 공부하는 좋은 방법 중 하나라는 것을 알게 되었다.
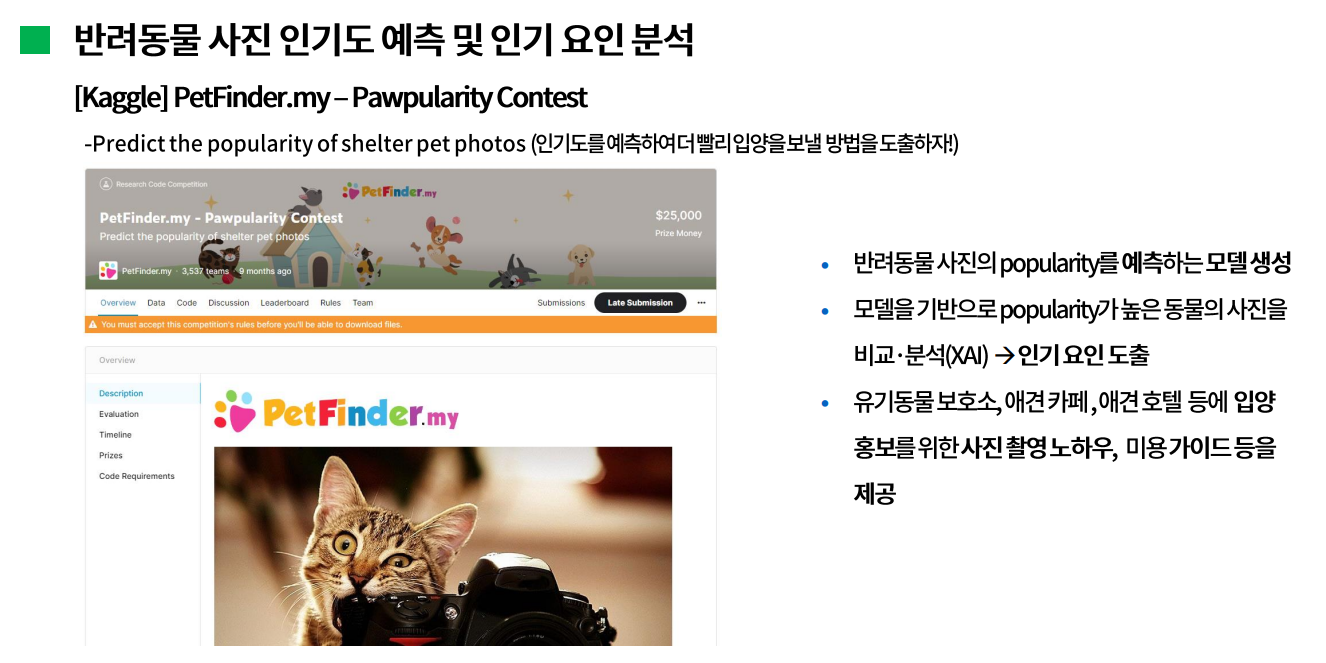
이 Competition의 목적은 'Predict popularity of shelter pet photos(인기도를 예측하여 더 빨리 입양을 보낼 방법을 도출하자)'이다. 즉, 반려동물 사진으로 인기도를 더 정확하게 예측하는 사람이 높은 순위를 차지한다. 그래서 discussion에서는 예측 정확도를 높이기 위한 기법이나 노하우에 대한 내용은 많이 논의되었지만 인기도가 높은 또는 낮은 사진들의 특성을 분석한 내용은 논의되지 않았다.
따라서, 이 프로젝트를 통해 모델의 정확도를 높이는 것 뿐만 아니라 인기도가 높은 동물의 사진을 분석하여 인기 요인을 도출하고자 하였다. 즉, 특정 사진이 왜 인기가 높은지 또는 없는지를 분석하면 인기 요인을 알아낼 수 있고 해당 정보를 유기동물 보호소, 애견 카페 등에 입양 홍보를 위한 사진촬영 노하우, 미용 가이드를 제공할 수 있을 것이라는 가정(기대?)을 해보았다.
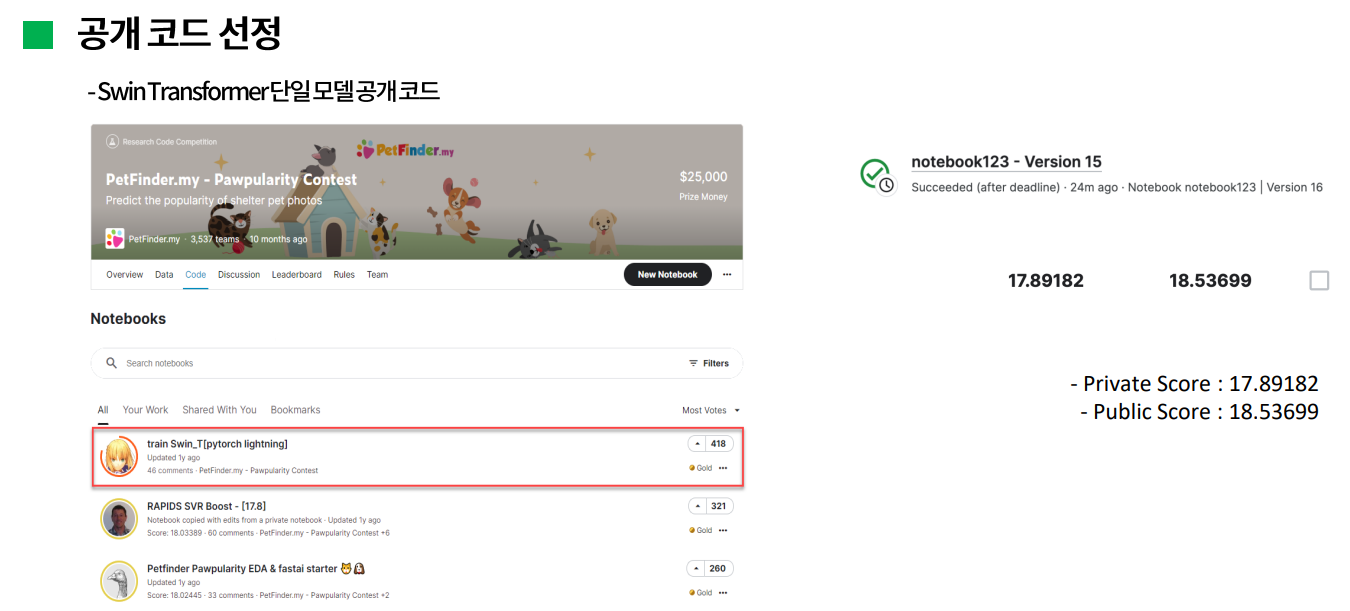
이미 종료된 competition이라 기존 참가자들이 공개한 몇가지 코드를 참고할 수 있었다. 이 대회의 discussion을 참고해보면 상위 팀 대부분이 swin transformer를 활용했다는 것을 알 수 있었는데, 공개 코드 중 최다 득표를 받은 swin transformer를 적용한 코드를 선정했다. 사실 1등팀이 공개한 코드를 선정하려고 했었는데, 거의 30개가 넘는 모델을 앙상블하고 구조가 다 달라서 이해하기가 굉장히 복잡하고 어려웠다. 따라서, 단일 모델로 약간의 변형을 적용해보면서 성능을 확인해보기로 했다. 이 모델 그대로 학습해서 캐글에 제출한 score는 RMSE가 17.9로 확인되었는데, 캐글에 제출하는 방식이 생각보다 굉장히 까다로워서 성능확인 방법은 좀 더 고민이 필요할 것 같다.(캐글 노트북에서 코드를 돌려서 나온 submission file을 제출해야 하는데 캐글 노트북에서 import가 안되는 라이브러리들이 많았다.)
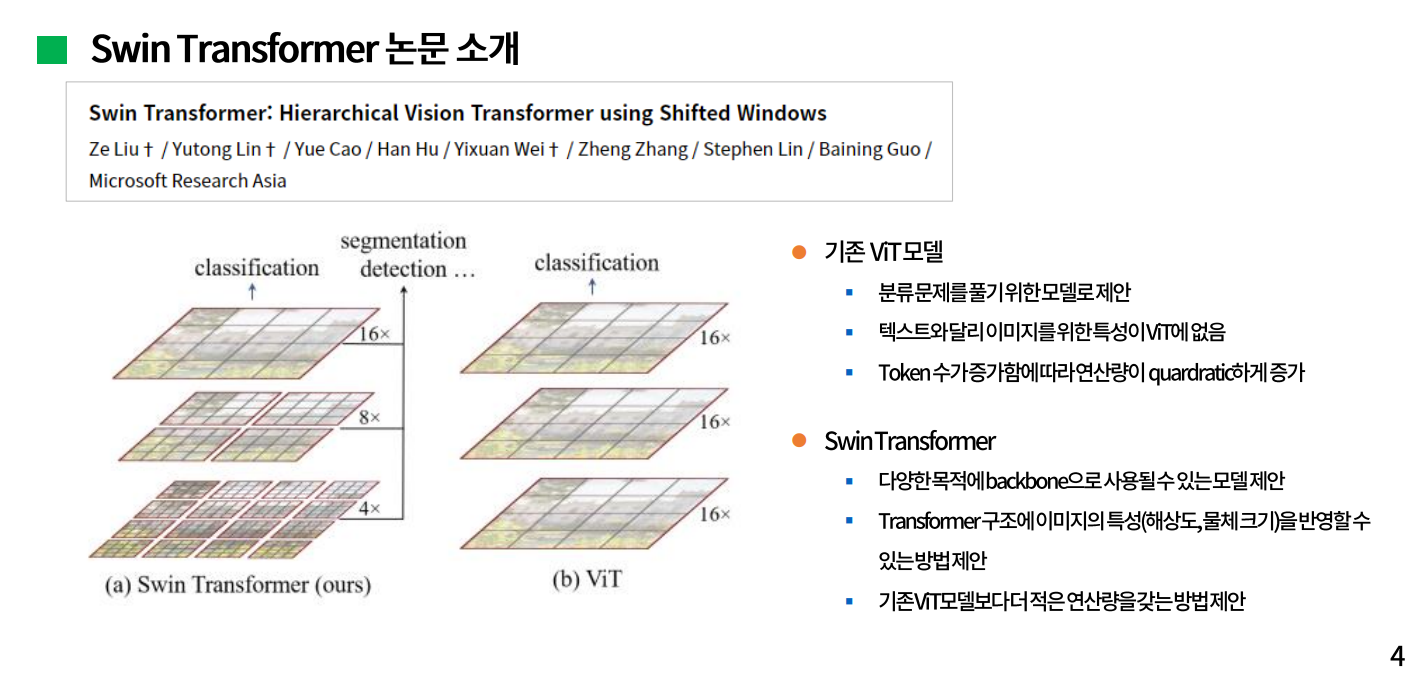
선행연구로 Swin Transformer의 논문을 참고했다. 해당 논문은 2021년 3월에 마이크로소프트에서 발표되었다. 기존의 Vision transformer 모델은 그림에서 처럼 patch라고 하는 작게 쪼개진 사각형들 모두가 self attention을 하는 구조다. Swin transformer는 각 patch를 window로 나누어 해당 window 안에서만 self attention을 수행하고 그 window를 한번 shift하고나서 다시 self attention을 하는 구조를 제시했다. 그래서 모델 이름이 shift window를 축약한 swin transformer 라고 한다. 또한, 일반적인 Transformer와 달리 마치 Feature Pyramid Network같은 계층적 구조를 제시하면서 계층마다 다른 해상도의 결과값을 얻을 수가 있어서 이미지의 특성인 해상도나 물체 크기 등을 고려할 수 있고, 분류 문제뿐만 아니라 Object Detection, Segmentation에서 backbone으로 사용되어 좋은 성능을 내게 된다고 설명하고 있다.
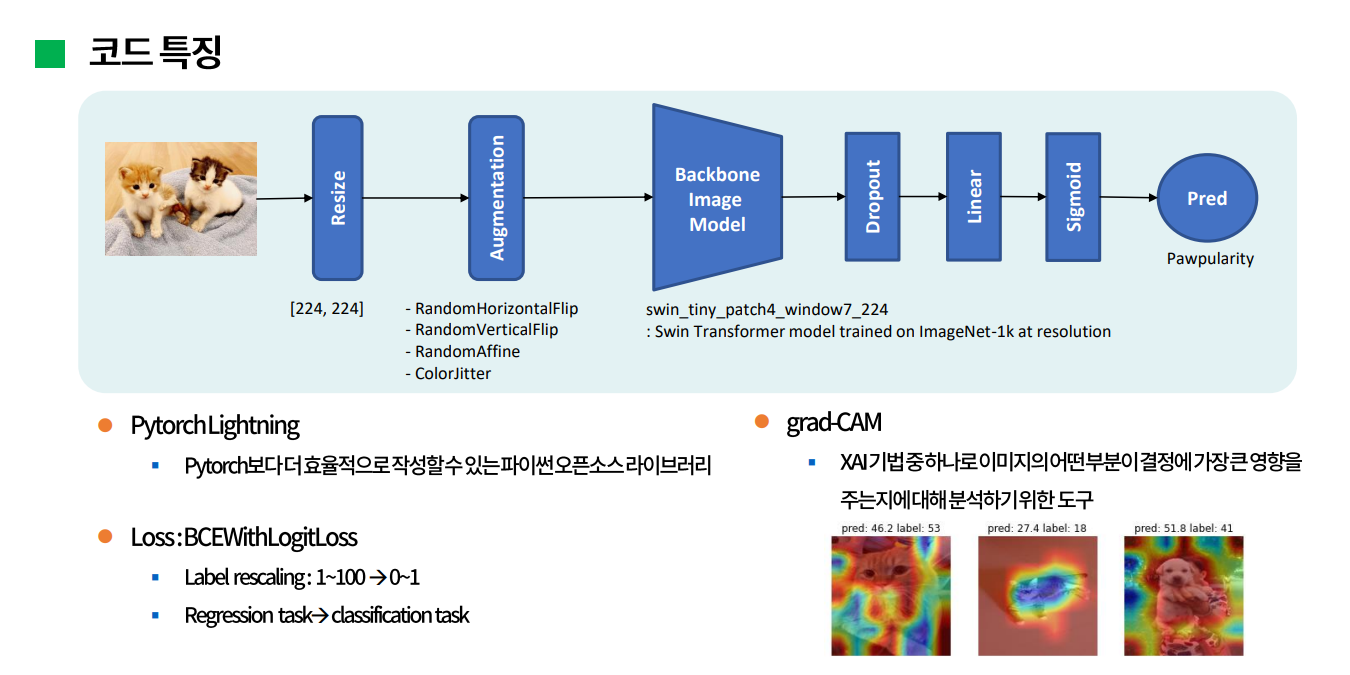
선정한 공개 코드의 특징을 살펴보면 대략적인 구조는 다음과 같다.
이미지를 입력받아 244 by 244로 resize해서 이미지 크기를 통일시키고, 이미지 증강을 한 다음 backbone 이미지 모델로 feature map을 생성한다. 이때 사용된 backbone은 이미지넷으로 사전학습된 swin transformer 모델이다. 그 다음 drop_out, linear, sigmoid layer를 거쳐 해당 이미지의 target값인 인기도를 예측한다.
주요 특징 중 하나는 프레임워크로 파이토치 라이트닝을 활용한 것인데, 이는 파이토치보다 좀 더 효율적으로 작성할 수 있는 파이썬 오픈소스 라이브러리라고 한다.
Loss는 BCEWithLogitLoss를 사용했는데, 이는 binary cross entropy loss에 sigmoid layer를 결합한 것으로 0과 1사이의 확률을 출력하게 된다. 사실 이 대회에서 target값은 1~100사이의 점수로 되어있는 regression 문제라서 loss로 Mean Square Error를 사용하지 않는 것이 의아했었는데, 참가자 대부분이 loss를 MSE보다 BCE를 활용해서 학습한 것이 더 성능이 좋았다고 언급한 것을 알게 되었다. 즉, 1~100사이의 target값을 0~1사이로 rescaling하고 regression문제를 분류 문제로 변환해서 접근하는 방식이다.
마지막으로 grad-CAM을 활용했는데, 이는 XAI 기법 중 하나로 이미지의 어떤 부분이 결정에 가장 큰 영향을 주는지에 대해 분석하기 위한 도구다. 위 그림은 해당 모델 직접 돌려봤을 때 예측값에 대해서 grad-CAM을 적용한 결과인데, 이미지의 어떤 부분이 예측값을 올리는데 혹은 낮추는데 기여했는지를 보여주고 있다.
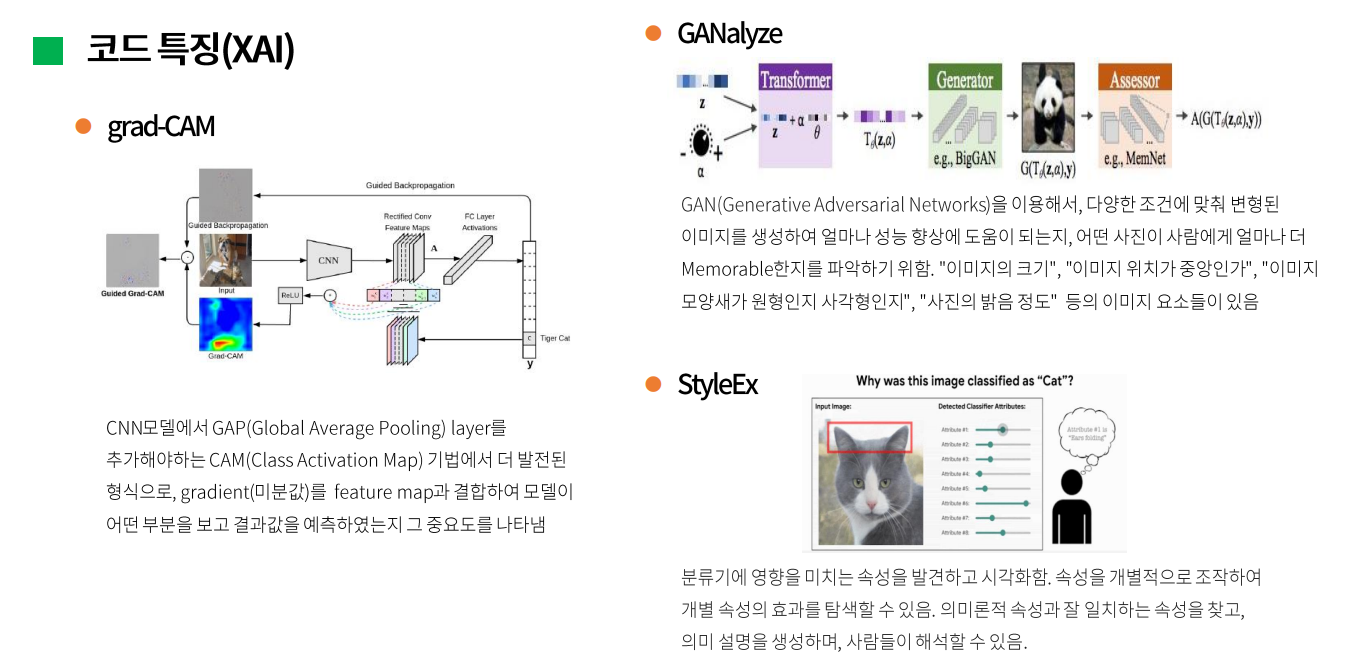
그래서 인기도를 높이는 요인을 분석하기 위해서 XAI기법에 대해서 좀 더 찾아보았다. grad-CAM뿐만 아니라 대표적으로 GAN으로 변형 이미지를 생성하여 파악하는 GANalyze와 구글에서 발표한 StylEX라는 방법이 있었는데, StylEX는 이미지의 속성을 파악하고 각 속성의 개별적인 효과를 탐색할 수 있다고 한다.
그래서 이러한 사전 연구 내용을 토대로, 해당 문제를 해석하기에 가장 용이한 방법을 선택해서 적용해보고자 한다.

그리고 사용할 수 있는 다른 공개 데이터셋으로는 Petfinder가 주최한 이전 kaggle competiton의 데이터셋이 있었다. 참가팀 중에서 실제로 이 데이터셋을 활용한 사례가 있는데, 2등 팀에서는 해당 대회와 이전 대회 간의 일부 이미지가(약 1,500장 가량) 겹치는 것을 발견하여, 이전 대회의 메타 데이터를 feature로 결합하여 활용했다고 밝혔다.
이 데이터셋 활용 방안으로는 이전 대회의 target을 해당 대회의 target으로 변환하는 방식과 준지도학습 방식을 적용한 pseudo labeling 방식이 있을 수 있다. discussion을 참고해보니 pseudo labeling 방식이 좀 더 유의미할 것으로 보여서 해당 방식을 적용해보고자 한다.
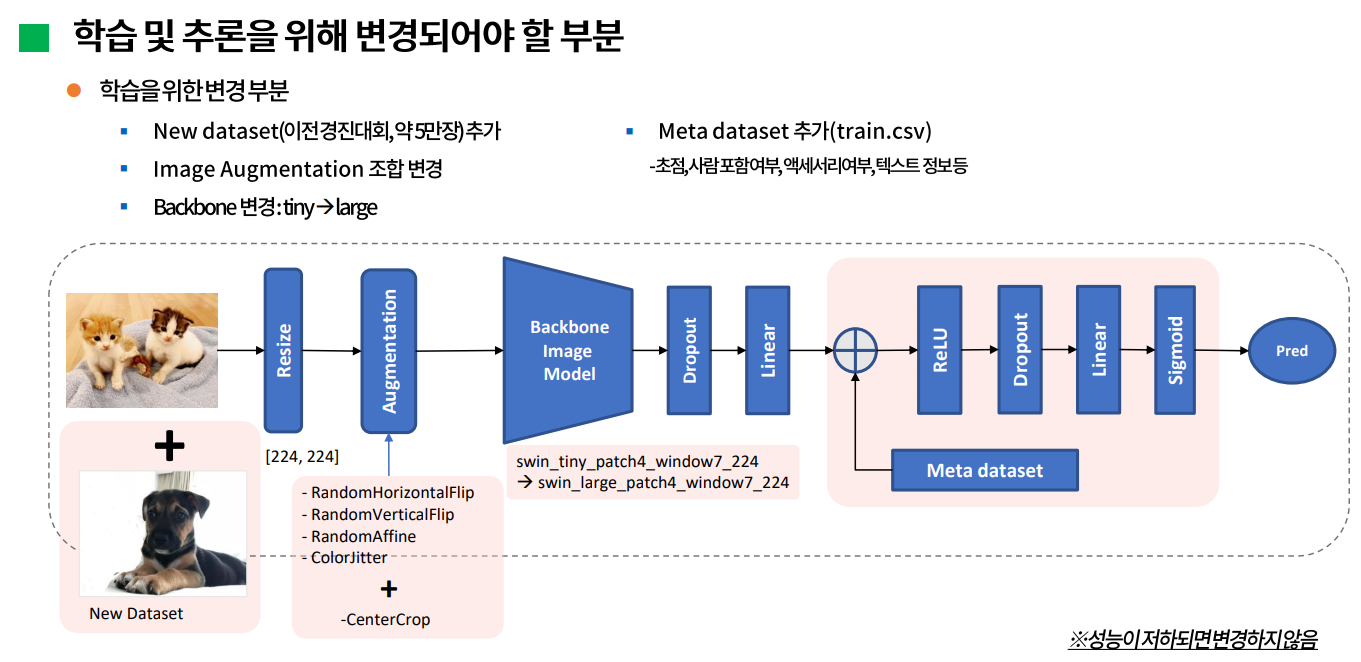
학습을 위해 변경되어야 할 부분으로 고민한 내용은 다음과 같다.
앞에서 언급한 이전 대회의 데이터셋을 추가하는 것과, augmentation은 기존에서 좀 더 나은 조합을 찾아보고자 한다. discussion에서는 vertical flip은 제외하고 centerCrop을 추가하는것이 효과가 있었다는 의견이 있었는데 이 부분을 직접 확인해보고자 한다.
그리고 단순히 backbone을 기존에 적용했던 tiny swin transformer 모델을 large 모델로 변경해보는 것이 있다. 또 추가할 부분이 meta dataset인데, 경진대회에서 제공하는 데이터는 이미지 데이터 뿐만 아니라 사진에 대한 정보, 초점이나 사람 포함 여부 등을 binary 값으로 표현한 csv파일도 있다. 공개 코드에는 학습에 이미지 데이터만 사용했는데 메타 데이터셋도 추가해서 성능을 확인해보고자 한다. 하지만 성능이 많이 떨어진다면 추가하지 않을 예정이다.
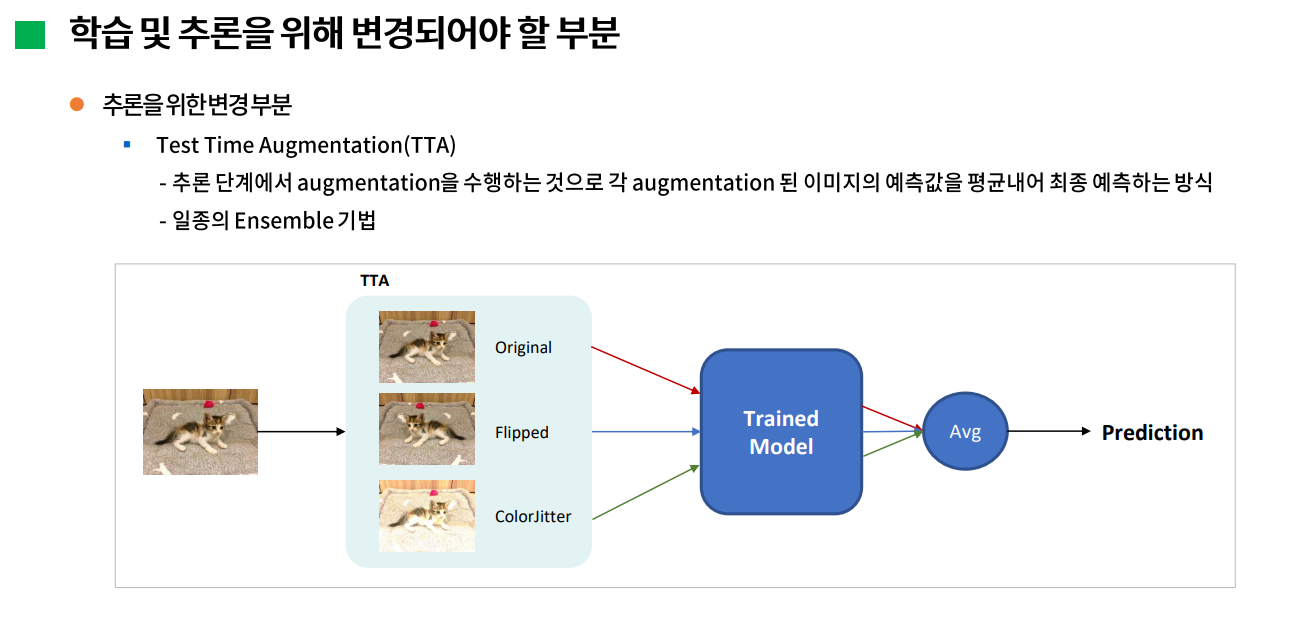
다음으로는 추론을 위해 변경되어야 할 부분이다. 추론할 때에는 test image를 그대로 모델에 입력하는 것이 아니라 augmentation을 수행해서 각 증강된 이미지마다 예측하고 그 예측값을 평균내서 최종 예측을 하는 방식인 Test Time Augmentation을 적용해볼 예정이다. 일종의 앙상블 기법인데, 실제로 대회 참가자들도 대부분 이 TTA방식을 적용해서 제출한 것으로 보인다.
.jpg)