인공신경망 분석
- 뉴런의 활성화 함수
- Relu 함수
- softmax 함수 : 표준화지수함수로도 불리며, 출력값이 여러개로 주어지고 목표치가 다범주인 경우 각 범주에 속할 사후확률을 제공하는 함수
- Relu 함수
- 가중치의 초기값과 다중 최소값 문제
- 역전파 알고리즘은 초기값에 따라 결과가 많이 달라지므로 초기값의 선택은 매우 중요
- 가중치가 0이면 시그모이드 함수는 선형이 되고 신경망 모형은 근사적으로 선형모형이 됨
- 초기값이 0이면 반복하여도 값이 전혀 변하지 않고, 너무 크면 좋지 않은 해를 주는 문제점을 내포하고 있어 주의 필요
- 학습모드
- 온라인 학습 모드
- 각 관측값을 순차적으로 하나씩 신경망에 투입하여 가중치 추정값이 매번 바뀜
- 국소최솟값에서 벗어나기가 더 쉽다
- 확률적 학습 모드 : 온라인 학습모드와 같으나 신경망에 투입되는 관측값의 순서가 랜덤함
- 배치 학습 모드 : 전체 훈련자료를 동시에 신경망에 투입
- 온라인 학습 모드
군집분석
- 거리 1) 연속형 변수의 경우
-
유클리디안 거리 : 통계적 개념 없음. 변수들의 산포 정도가 전혀 감안되어 있지 않음
-
표준화 거리
- 해당 변수의 표준편차로 척도 변환한 후 유클리드안 거리를 계산하는 방법.
- 표준화하게 되면 척도의 차이, 분산의 차이로 인한 왜곡을 피할 수 있다.
-
마할라노비스 거리
- 통계적 개념 포함. 변수들의 산포를 고려하여 이를 표준화한 거리
- 변수의 표준화와 변수 간의 상관성을 동시에 고려한 통계적 거리
- 그룹에 대한 사전 지식 없이는 표본공분산S를 계산할 수 없으므로 사용하기 곤란
-
체비셰프(Chebychev) 거리 :
-
맨하탄 거리 :
-
캔버라 거리 :
-
민코우스키 거리: 맨하탄 거리와 유클리디안 거리를 한번에 표현한 공식
- L1 거리 (맨하탄), L2 거리(유클리디안)2) 범주형 변수의 경우
-
자카드 거리 : boolean 속성으로 이루어진 두 객체 간의 유사도 측정
- 자카드 계수
- 자카드 계수
-
코사인 거리
- 코사인유사도
- 코사인유사도
-
- 계층적 군집분석
- 합병형 방법(agglomerative:bottom-up)과 분리형 방법(Divisive: top-down)
- 최단 연결법: 거리행렬에서 거리가 가장 가까운 데이터를 묶어서 군집을 형성(계산량이 적다?)
- 최장 연결법
- 평균 연결법
- 와드(ward) 연결법 : 군집 내 편자들의 제곱합을 고려한 방법
-
비계층적 군집분석
- K-평균 군집분석 과정
- 원하는 군집의 개수와 초기 값(seed)들을 정해 seed 중심으로 군집 형성
- 각 데이터를 거리가 가장 가까운 seed가 있는 군집으로 분류
- 각 군집의 seed값을 다시 계산
- 모든 개체가 군집으로 할당될 때까지 위 과정들을 반복
- K-평균 군집분석 특징
- 연속형 변수에 활용 가능
- 초기 중심으로부터 오차 제곱합을 최소화하는 방향으로 군집이 형성되는 탐욕적(greedy) 알고리즘으로 안정된 군집은 보장하나 최적이라는 보장은 없다
- 볼록한 형태가 아닌(non-convex) 군집이(e.g. U형태의 군집) 존재할 경우에는 성능이 떨어진다
→ 이상값에 민감하여 군집 경계의 설정이 어렵다. 이러한 단점을 극복하기 위해 등장한 비계층적 군집 방법은 PAM(Partioning Around Medoids)
- K-평균 군집분석 과정
-
혼합 분포 군집(mixture distribution clustering)
- EM(Expectation-Maximization) 알고리즘의 진행 과정
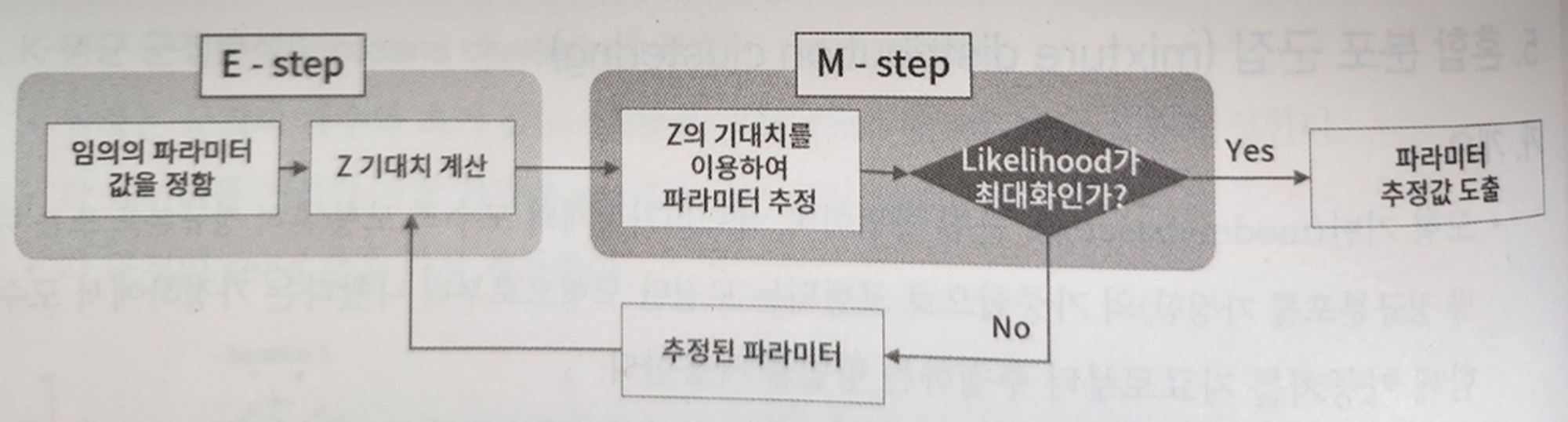
- 혼합 분포 군집 모형의 특징
- K-평균군집의 절차와 유사하지만 확률분포를 도입하여 군집을 수행한다
- 데이터가 커지면 수렴에 시간이 걸릴 수 있다
- 군집의 크기가 너무 작으면 추정의 정도가 떨어지거나 어려울 수 있다
- K-평균군집과 같이 이상치 자료에 민감하므로 사전에 조치가 필요하다
- EM(Expectation-Maximization) 알고리즘의 진행 과정
-
SOM(Self Organizing Map)
-
코호넨 맵(Kohonen Map)이라고도 알려짐
-
SOM은 비지도 신경망으로 고차원의 데이터를 이해하기 쉬운 저차원의 뉴런으로 정렬하여 지도의 형태로 형상화. 입력변수의 위치 관계를 그대로 보존한다는 특징이 있음
-
구성
1) 입력층
- 입력 변수의 개수와 동일하게 뉴런 수가 존재
2) 경쟁층(2차원 격자로 구성된 층)
- 입력벡터의 특성에 따라 벡터가 한 점으로 클러스터링 되는 층
- 경쟁학습으로 각각의 뉴런이 입력 벡터와 얼마나 가까운가를 계산하여 연결 강도(connection weight)를 반복적으로 재조정하여 학습한다. 이 과정을 거치면서 연결강도는 입력 패턴과 가장 유사한 경쟁층 뉴런이 승자가 된다.
- 입력 층의 표본 벡터에 가장 가까운 프로토타입 벡터(BMU, Best-Matching-Unit)를 선택해, 코호넨의 승자 독점의 학습 규칙에 따라 위상학적 이웃에 대한 연결 강도를 조정
- 승자 독식 구조로 인해 경쟁층에는 승자 뉴런만이 나타나며, 승자와 유사한 연결 강도를 갖는 입력 패턴이 동일한 경쟁 뉴런으로 배열
-
특징
- 고차원 데이터를 저차원의 지도 형태로 형상화하기 때문에 시각적으로 이해가 쉽다
- 패턴 발견, 이미지 분석 등에서 뛰어난 성능
- 역전파 알고리즘이 아닌 단 하나의 전방 패스(feed-forwad flow)를 사용함으로써 속도가 매우 빠르다. 실시간 학습처리 가능
-
SOM과 신경망 모형의 차이점
구분 신경망 모형 SOM 학습 방법 오차역전파법 경쟁학습방법 구성 입력층, 은닉층, 출력층 입력층, 2차원 격자 형태의 경쟁층 기계 학습 방법의 분류 지도 학습 비지도 학습
-
연관분석
- 연관성 분석은 장바구니분석 또는 서열분석이라고 불림
- 연관규칙의 측도
- 지지도(support) :
- 신뢰도(confidence) :
- 향상도(Lift) :
- 연관규칙 A→B는 품목A와 품목B의 구매가 서로 관련이 없는 경우에 향상도가 1이 된다
- 연관규칙의 절차 ① 최소 지지도 결정 → ② 품목 중 최소 지지도를 넘는 품목 분류 → ③ 2가지 품목 집합 생성 → ④ 반복적으로 수행해 빈발품목 집합을 찾음
-
연관성 규칙의 장단점
- 장점
- 비목적성 분석기법(목적변수 없음)
- 간단한 자료 구조, 계산 간단
- 단점
- 품목 수 증가하면 계산량 기하급수적으로 늘어남
- 너무 세분화한 품목을 갖고 연관성 규칙을 찾으면 의미 없는 분석이 될 수 있다
- 거래량이 적은 품목은 당연히 포함된 거래수가 적을 것, 규칙 발견시 제외하기 쉽다
- 장점
-
순차 패턴(Sequence Analysis)
- 연관성 분석에 시간이라는 개념을 포함시켜 순차적으로 구매 가능성이 큰 상품군을 찾아냄
- 연관성 분석 데이터 + 구매시점 정보 포함
-
최근 연관성분석 동향
품목 수 n개, 품목 부분집합의 개수 = 개,
가능한 모든 연관규칙의 개수 = 개- Apriori 알고리즘
- 최소 지지도 이상의 빈발항목집합(frequent item set, 최소 지지도보다 큰 지지도 값을 갖는 품목의 집합)을 찾은 후 그것들에 대해서만 연관규칙 계산
- 아이템 수 많아지면 여전히 계산 복잡도 증가
- inspect() : 생성된 연관 규칙을 보기 위해 사용되는 함수
- FP-Growth 알고리즘
- 후보 빈발항목집합을 생성하지 않고, FP-Tree(Frequent Pattern Tree)를 만든 후 분할정복 방식을 통해 더 빠르게 빈발항목집합을 추출할 수 있는 방법
- Apriori 알고리즘의 약점을 보완하기 위해 고안된 것으로 데이터베이스를 스캔하는 횟수가 적고 빠른 속도로 분석 가능
- Apriori 알고리즘
.jpg)
ML/DL swimmer