
01. DB
✴︎ 데이터 유형(Data Type)
① Bolean
- true or false
② Character (문자형 데이터 타입)
| 데이터 유형 | 정의 |
|---|---|
| CHAR(n) | 고정 길이 문자열(최대 2000 BYTE) 지정된 길이 보다 짧게 데이터 입력될 시 나머지 공간은 공백으로 채운다. |
| VARCHAR2(n) | 가변 길이 문자열 (최대 4000BYTE) 지정된 길이보다 짧게 데이터가 입력될 시 나머지 공간은 채우지 않는다. |
| NCHAR(n) | 고정 길이 유니코드 문자열(최대 2000BYTE) |
| NVARCHAR2(n) | 가변 길이 유니코드 문자열(최대 4000BYTE) |
| LONG | 가변 길이 문자열(최대 2GBYTE) |
| CLOB | 대용량 텍스트 문자열(최대 4GBYTE), ex) 소설 |
| NCLOB | 대용량 텍스트 유니코드 문자열(최대 4GBYTE) |
전화번호나 국가번호는 문자 유형을 선택하는 것이 좋다.
전화번호/국가번호는 숫자 연산을 할 필요가 없으며, 앞자리가 '0'으로 시작하기 때문에 숫자 유형을 사용하면 '0'이 무시될 수 있다.
③ Numberic (숫자형 데이터 타입)
| 데이터 유형 | 정의 |
|---|---|
| NUMBER(P,S) | P: 1~38자리,디폴트 값은 38 (22BYTE) S: 소수점 이하 자리 (디폴트 : 0) |
| BINARY_FLOAT | 부동 소수형 데이터 타입(4BYTE) / 32bit 부동 소수 |
| BYNARY_DOUBLE | 부동 소수형 데이터 타입(4byte) / 64bit 부동 소수 |
④ Temporal (날짜형 데이터 타입)
| 데이터 유형 | 정의 |
|---|---|
| DATE | 고정 길이 날짜 데이터 타입. (날짜 연산 수행시 많이 쓰인다.) |
| INTERVAL_YEAR | 날짜(년도, 월) 형태의 기간 표현 |
| INTERVAL_DAY | 날짜 및 시간(요일, 시, 분, 초) 형태의 기간 표현 |
| TIMESTAMP | 밀리초(ms)까지 표현 |
| TIMPSTAMP_WITH TIME ZONE | 날짜 및 시간대 형태의 타입 |
| TIMESTAMP_WITH LOCAL TIME ZONE | 저장시 데이터베이스의 시간대를 준수, 조회시 조화하는 클라이언트 시간 표현 데이터 타입 |
✴︎ SQL의 Key
KEY란 검색, 정렬 시 튜플(레코드, 행)을 구분할 수 있는 기준이 되는 속성을 말한다.
즉 무언가를 식별하는 고유한 식별자(identifier) 기능을 한다.
키의 종류로는 키본키, 슈퍼키, 후보키, 대체키, 외래키 등이 있다.
🔑 기본키 (Primary Key, PK)
- 최소성과 유일성을 만족하는 속성으로, 테이블에서 오직 1개만지정할 수 있다.
- 기본키는 테이블에서 특정 튜플을 구별하기 위한 속성(Attribute)이다.
- 기본키는 절대 NULL 값을 가져선 안되며, 중복되지 않는 고유한 값이여야 한다.
🗝️ 외래키 (Foreign Key, FK)
- 참조되는 테이블의 기본키와 대응되며, 테이블 간의 참조관계를 표시하는 키이다.
- 다른 테이블의 값을 참조할 때 없는 값을 참조할 수 없도록 제약을 주는 것으로, 테이블 간의 잘못된 매핑을 방지하는 역할을 한다.
- 이때 참조될 열(A)의 값은 해당 테이블에서 기본키(Primary Key)로 설정되어야 한다.
🔎 SQL에서 key 확인하는 방법
❶ Object Explorer에서 확인하기
step1 step2 step3 ❷ Dependents에서 확인하기
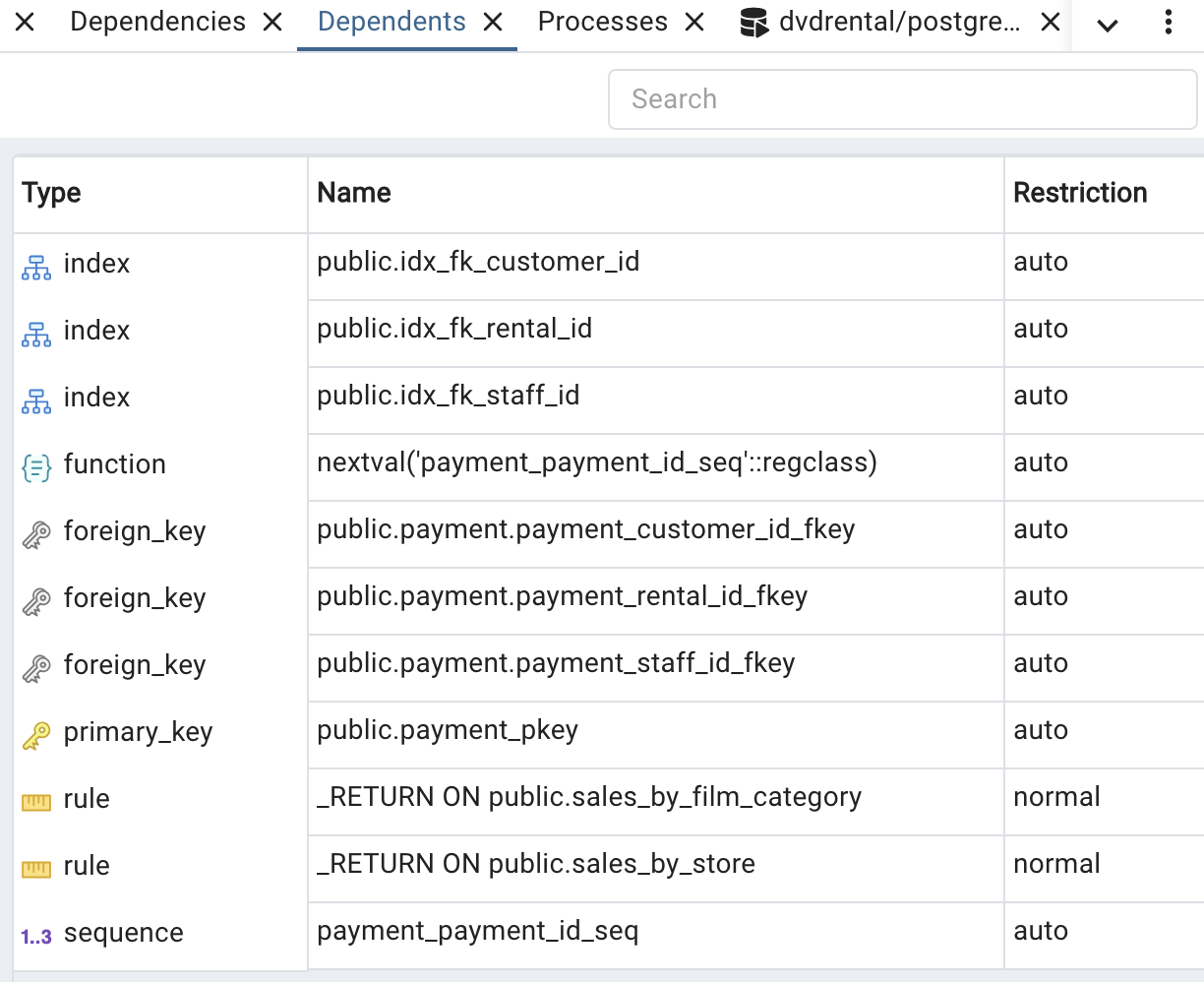
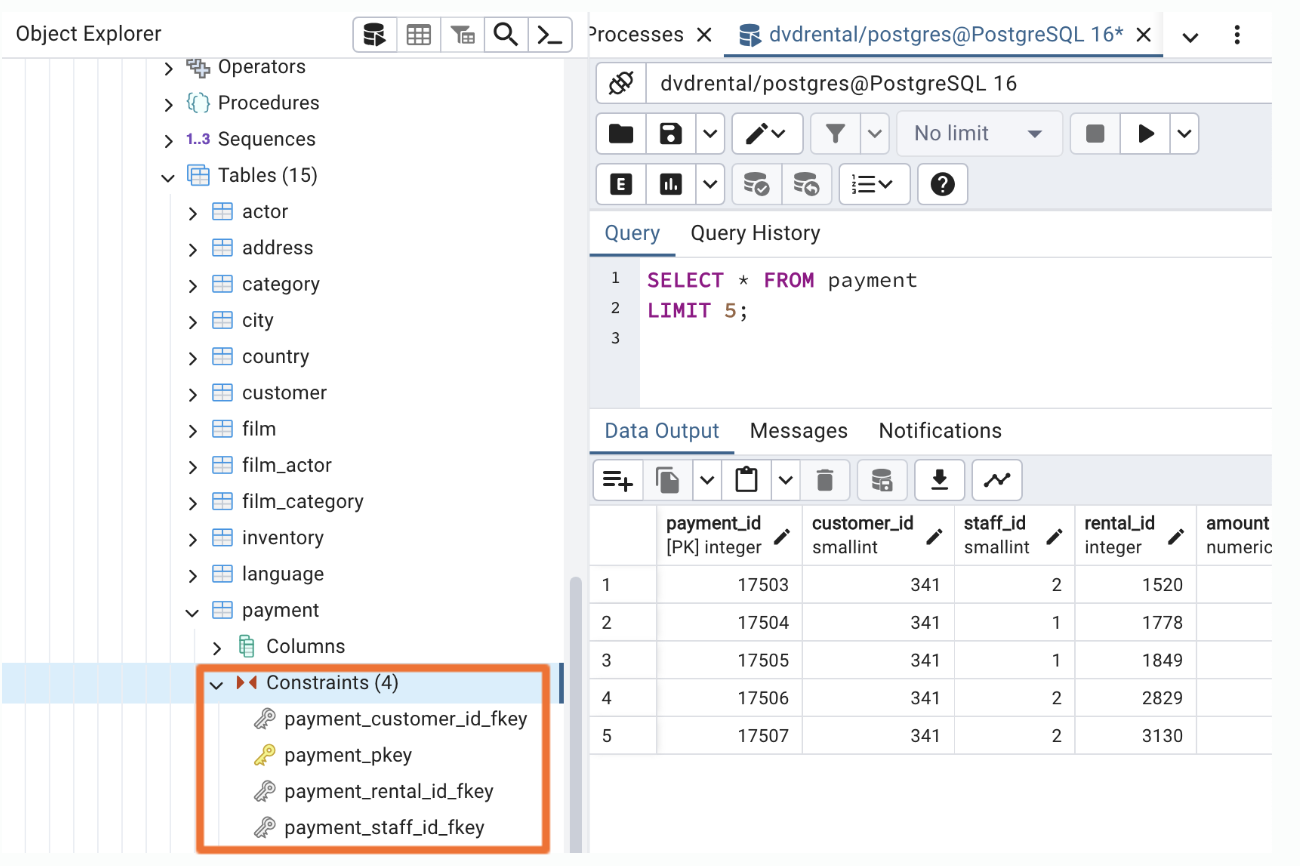
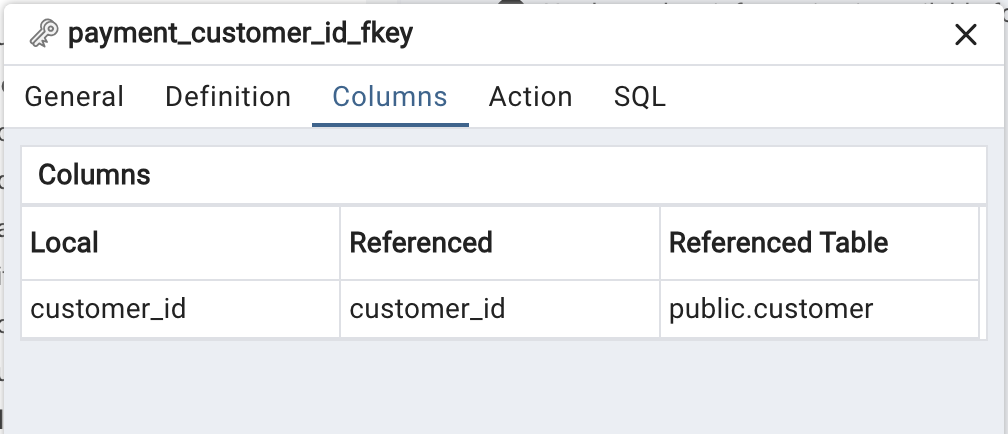
✴︎ 제약 조건(constraint)
표에 있는 데이터 열에 적용되는 규칙을 제약 조건이라고 한다.
표에 있는 모든 것에 제약 조건을 걸 수 있다.
👀 제약조건을 사용하는 이유
- 데이터베이스에 유효하지 않은 데이터가 쓰이지 않도록 방지할 수 있다.
- 데이터베이스의 데이터에 대한 정확도와 신뢰도를 보장한다.
🐥 제약조건의 범위
① 개별 열 제약 조건
- 특정 조건에 연결된 하나의 열에 있는 데이터만 제약한다.
② 표 대상 제약 조건
- 개별 세로단이 아닌 전체 표에 적용되어 제약한다.
✴︎ 범위별 제약조건의 유형
① 개별 열 제약 조건
특정 조건에 연결된 하나의 열에 있는 데이터만 제약한다.
❶ NOT NULL 제약 조건
해당 칸에 빈 값(NULL)이 입력될 수 없다. 즉 반드시 값이 존재해야한다.
❷ UNIQUE 제약 조건
해당 열에 존재하는 모든 값들은 중복되지 않는 고유의 값이여야 한다. (ex. customer_id)
❸ Primary Key / Foreign Key 제약 조건
표를 만들 때(create) 두 키를 규정하는 제약 조건
-
Primary Key : 기본 키는 전체 데이터베이스 자료나 각 행을 고유하게 식별해야 한다.
-
Foreign Key : 외래 키(기타 키)는 현재 데이터베이스의 열이나 다른 데이터베이스에 제약 조건을 거는 역할을 한다.
이때 Fkey를 세팅하려면, 연결할 다른 데이터베이스와의 관계 셋업이 필요하다.
❹ CHECK 제약 조건
선택한 열의 모든 값이 특정한 조건(case)를 만족해야 한다는 조건이다.
ex) 'salad' 열의 값은 0보다 커야 한다.
❺ EXCLUSION 제약 조건
특정 오퍼레이터(연산 기호)를 사용해 두 열을 비교할 때, 모든 비교 값이 참으로 판명되지 않아야 한다는 조건이다.
② 표(TABLE) 대상 제약 조건
개별 세로단이 아닌 전체 표에 적용되어 제약한다.
❶ CHECK 제약 조건
전체 테이블에 적용할 조건을 CHECK뒤의 (괄호)안에 적으면 된다.
테이블에 데이터를 삽입하거나 업데이트할 때 일괄적으로 조건을 적용하고 싶을 때 사용하면 유용하다.
❷ REFERENCES 제약 조건
열의 값에 제한을 거는 것으로, 해당 열의 값은 다른 표의 열의 값을 참조해야 한다.
즉 다른 테이블에서 열의 값을 참조해 불러와야 한다.
❸ UNIQUE (column_list) 제약 조건
개별 열 뿐만 아니라 테이블에 있는 모든 열의 값이 고유해야 한다.
즉 다중 열(테이블에 존재하는 모든 열)에 대한 제약 조건이다.
❹ Primary Key 제약 조건
마찬가지로, 개별 열 뿐만 아니라 테이블에 있는 모든 열의 값이 고유하게 식별되어야 한다.
02. Table CRUD
① CREATE
CREATE 키워드를 이용해 테이블과 column을 만들 수 있다.
✔️ 기본 문법
CREATE TABLE 테이블_이름 (
열_이름 데이터_유형 열_제약조건,
열_이름 데이터_유형 열_제약조건,
테이블_제약조건 테이블_제약조건
) INHERITS 다른_테이블_이름; // 다른 표와 연관 관계가 있다면 그 표와 INHERITS를 한다.SERIAL(시리얼) 데이터 유형
기본 키(Primary Key)의 데이터 유형은 항상 SERIAL이다.
SERIAL 유형엔 특별한 프로퍼티들이 있는데, 그중 시퀀스(sequence)가 대표적이다.
👉 SERIAL은 시퀀스 오브젝트를 만들고, 해당 열의 디폴트 값으로 시퀀스에 의해 발생한 값을 자동으로 세팅한다.
✔️ SERIAL의 특징
- 값을 입력하지 않아도 시퀀스가 대신 정수값을 생성해 고유한 값으로 넣어준다.
- 열의 중간 행이 삭제되거나 에러 등이 발생하면 해당 번호는 뛰어넘는다.
- 열의 2번째 칸에 데이터를 추가하는 과정에서 에러 발생 → 수정 후 정상적으로 추가되었다면 해당 칸의 고유 번호는 2번이 아닌 3번을 부여 받는다.
- 1, 2, 3, 4의 데이터 중 4번 데이터를 삭제하고 하나를 추가하면 추가한 데이터의 시리얼은 5가 된다.
✔️ 예제
❶ account TABLE
// 테이블_이름
CREATE TABLE account (
// 열_이름 데이터_유형 열_제약조건,
user_id SERIAL PRIMARY KEY,
username VARCHAR(50) UNIQUE NOT NULL,
password VARCHAR(50) NOT NULL,
email VARCHAR(250) UNIQUE NOT NULL,
created_on TIMESTAMP NOT NULL,
last_login TIMESTAMP
)👀 정상적으로 create되었다는 메세지
👀 Constraints
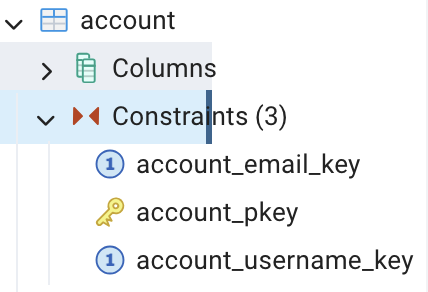
- 기본 키(pkey)는 금색으로 칠해진다.
- 외래 키(fkey)에 제약조건이 있을 경우, '1'로 표시된다.
❷ account_job TABLE
INTERGER : 다른 표의 기본키를 레퍼런스(참고)한다는 키워드
CREATE TABLE account_job (
user_id INTEGER REFERENCES account(user_id),
job_id INTEGER REFERENCES job(job_id),
hire_date TIMESTAMP
)② INSERT
✔️ 기본 문법
INSERT INTO 테이블_이름(열_이름, 열_이름, ...)
VALUES
(값, 값, ...)✔️ 다른 표의 값을 삽입하고 싶다면
INSERT INTO 테이블_이름(열_이름, 열_이름, ...)
SELECT 열_이름, 열_이름, ...
FROM 다른_테이블_이름
WHERE 조건✔️ 예제
INSERT INTO account(username, password, email, created_on)
VALUES
// username는 pk이므로 값이 자동 생성된다.
('Jose', 'password', 'jose@mail.com', CURRENT_TIMESTAMP)
🚨 주의! 제약조건을 지켜야 한다.
NOT NULL등 해당 열의 제약조건을 준수해야 한다.- 기타키의 경우, 유효한 테이블의 열을 reference 해야 한다.
③ UPDATE
✔️ 기본 문법
UPDATE 테이블_이름
SET 열_이름 = 값,
열_이름 = 값, ...
WHERE
조건;✔️ 예제
❶ 빈 값에 대해 업데이트
UPDATE account
SET last_login = CURRENT_TIMESTAMP
WHERE last_login IN NULL;❷ 전체 행 값에 대해 업데이트
UPDATE account
SET last_login = CURRENT_TIMESTAMP❸ 다른 열의 값으로 업데이트
UPDATE account
SET last_login = created_on❹ UPDATE JOIN : 다른 Table의 열을 가져와 업데이트
UPDATE TableA
SET origin_col = TableB.now_col
FROM TableB
WHERE TableA.id = TableB.id❺ 업데이트된 값 확인하기
UPDATE account
SET last_login = created_on
RETURNING account_id, last_login④ DELETE
✔️ 기본 문법
DELETE FROM table
WHERE row_id = 1;✔️ DELETE JOIN
다른 테이블(표)에 해당 행의 존재하는지 확인 후 조건이 일치하면 삭제한다.
DELETE FROM tableA USING tableB WHERE tableA.id = tableB.id;
✔️ Table의 모든 행/열 삭제
DELETE FROM table;✔️ 삭제 후, 삭제 값 확인하기
첫 번쨰 실행떄는 삭제된 값을, 두 번째 실행때는 이미 값이 사라진 후이므로 아무 값도 나타나지 않는다.
DELETE FROM job WHERE job_name = 'cowboy' RETURNING job_id, job_name;
03. ALTER Table과 CHECK 제약조건
✴︎ ALTER Table
더 많은 ALTER Table 명령어는 여기서 !
테이블이나 테이블의 값을 바꿀 수 있는 ALTER Table 구문에 대해서 알아보자
✔️ 기본 문법
ALTER TABLE 테이블_이름 action ||
ALTER COLUMN 컬럼_이름 action ||
SET DEFAULT VALUE❶ 열 추가 / 삭제하기
ALTER TABLE 테이블_이름 action
ADD COLUMN 새_컬럼 컬럼_유형
ALTER TABLE 테이블_이름 action
DROP COLUMN 컬럼_이름❷ Table / Column 명 변경하기
ALTER TABLE information
RENAME to new_info
ALTER TABLE new_info
RENAME COLUMN person❸ 제약조건 추가 / 삭제하기
ALTER TABLE new_info
ALTER COLUMN people SET NOT NULL
ALTER TABLE new_info
ALTER COLUMN people DROP NOT NULL✴︎ DROP
DROP은 특정 열을 삭제할 때 사용한다.
❶ 특정 열 삭제하기
ALTER TABLE 테이블_이름
ALTER COLUMN 컬럼_이름❷ JOIN 끊기
CASCADE : 모든 연결을 끊어주는 키워드
ALTER TABLE 테이블_이름 DROP COLUMN 컬럼_이름 CASCADE
❸ IF EXISTS : DROP 에러 방지하기**
: 존재하지 않은 열을 삭제하려고 하면 에러가 발생한다.
이를 방지하기 위해 IF EXISTS키워드를 사용하면, 표에 해당 열이 존재할 떄만 동작하여 삭제된다.
ALTER TABLE 테이블_이름
DROP COLUMN IF EXISTS 컬럼_이름 ❹ 여러 열 삭제하기
ALTER TABLE 테이블_이름
DROP COLUMN 컬럼_이름_1,
DROP COLUMN 컬럼_이름_2, ...✴︎ CHECK 제약조건
CHECK은 특정 조건에 맞춤화된 제약 조건을 사용할 수 있다.
예제코드 ❶
CREATE TABLE example(
ex_id SERIAL PRIMARY KEY,
age SMALLINT CHECK (age > 21),
parent_age SAMLLINT CHECK (parent_age > age)
);예제코드 ❷
CREATE TABLE employees(
emp_id SERIAL PRIMARY KEY,
name VARCHAR(50) NOT NULL,
birthdate DATE CHECK (birthdate > '1900-01-01'),
hire_date DATE CHECK (hire_date > birthdate),
salary INTEGER CHECK(salary > 0)
);05. 조건식과 프로시저
✴︎ CASE 키워드
특정 조건이 충족되었을 떄, SQL(시퀄) 코드를 실행하기 위해 사용한다.
✔️ CASE 문법
① 기본 CASE 문법
이미 존재하는 열을 기본 CASE 문법을 사용해 특정 조건에 따라 도출된 결과값으로 새 열을 만든다.
- 좀 더 유연하기 활용 가능하며, 보다 다양한 조건을 확인 할 수 있다.
- WHEN 다음에 개별적이고 고유한 특정 조건을 대량으로 확인할 때 유리하다.
SELECT a,
CASE WHEN a = 1 THEN 'one'
WHEN a = 2 THEN 'two'
ELSE 'other'
// as를 안쓸 시 default값인 case가 열제목이 된다.
END AS label
FROM test;| a |
|---|
| 1 |
| 2 |
| 3 |
⬇️
| a | label |
|---|---|
| 1 | one |
| 2 | two |
| 3 | other |
② CASE 표현 문법
CASE 바로 전에 표현을 평가하고, 조건 대신 WHEN 구문을 바로 사용해 값을 적는다.
- 표현을 평가하고, 조건에 대한 값을 목록화한다.
- 값이 동일한지 확인하는데 중점을 두고 있기 때문에, 단일 열을 대상으로 할 때 적절하다.
- 즉 값의 동일성 조건만 확인 가능하며, 그 외의 비교(< , > 등) 조건은 기본 CASE 문법을 사용해야 한다.
SELECT
CASE expression
WHEN value1 THEN result1
WHEN value2 THEN result2
ELSE some_other_result
END
SELECT a,
CASE a WHEN 1 THEN 'one'
WHEN 2 THEN 'two'
ELSE 'other'
END
FROM test;✔️ 예제
❶ 고객 id에 따른 회원 등급을 표시해라. (case 기본 문법)
SELECT customer_id
CASE
WHEN (customer_id <= 100) THEN 'Premium'
WHEN (customer_id BETWEEN 100 AND 200) THEN 'Plus'
ELSE 'Normal'
END
FROM customer;❷ 고객id에 대해 추첨 결과를 반영해 표시해라 (case 표현 문법)
SELECCT customer_id
CASE customer_id
WHEN 2 THEN 'Winner'
WHEN 5 THEN 'Second Place'
ELSE 'Fail'
END AS results
FROM customer;❸ 0.99달러로 할인되고 있는 품목의 수를 구하라 (case 표현 문법)
0.99달러인 경우 +1, 아닌 경우엔 +0이 되므로 합계값은 할인되고 있는 품목의 수가 된다.
SELECT
SUM (CASE rental_rate
WHEN 0.99 THEN 1
ELSE 0
END) AS number_of_bargains
FROM film❹ 할인/기본/프리미엄 항목 각각의 수를 구하라 (case 표현 문법)
SELECT
SUM (CASE rental_rate
WHEN 0.99 THEN 1
ELSE 0
END) AS bargains,
SUM (CASE rental_rate
WHEN 2.99 THEN 1
ELSE 0
END) AS regular,
SUM (CASE rental_rate
WHEN 4.99 THEN 1
ELSE 0
END) AS premium
FROM film❺ 등급별(R/PG/PG-13) 영화 개수를 구하라
SELECT
SUM (CASE rating
WHEN 'R' THEN 1 ELSE 0
END) AS RATE_R,
SUM (CASE rating
WHEN 'PG' THEN 1 ELSE 0
END) AS RATE_PG,
SUM (CASE rating
WHEN 'PG-13' THEN 1 ELSE 0
END) AS RATE_PG_13
FROM film;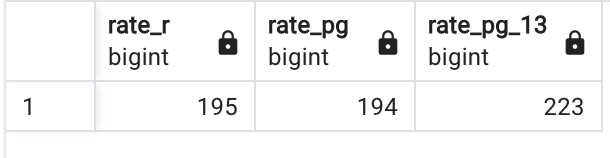
✴︎ COALESCE 키워드
인자(arguments)로 2개의 값(a, b)을 받아 만약 해당 값이
1. null이 아니라면 첫번째 인자를 반환(a)하고,
2. null이라면 두 번째 인자(b)를 반환한다.
- NULL 값을 가진 테이블을 쿼리할 때 유용하다.
✔️ 기본 문법
COALESCE(a, b)✔️ 예제
price - discount 금액을 계산하려고 할 때, <discount: null>인 항목의 null 값을 → 0으로 바꿔 계산하는데 활용할 수 있다.
| Item | Price | Discount |
|---|---|---|
| A | 100 | 20 |
| B | 300 | null |
| C | 200 | 10 |
SELECT item, (price - COALESCE(discount, 0))
AS final_price
FROM table;👉 첫번째 인자값이 null이 아니라면 값 그대로, null이라면 0을 적용한다.
| Item | final_price |
|---|---|
| A | 80 |
| B | 300 |
| C | 190 |
✴︎ CAST 키워드
CAST 함수는 데이터 유형을 바꿔주는 역할을 한다.
✔️ 기본 문법
SELECT CAST(데이터유형_a AS 데이터유형_b)
FROM table
// 문자형 -> 숫자형
SELECT CAST('5' AS INTEGER)
table
// ❌ 불가 (비합리적)
SELECT CAST('five' AS INTEGER)
table
SELECT CAST(date AS TIMESTAMP)
FROM table✔️ PostgreSQL만의 특별한 CAST 문법
SELECT 데이터유형_a::데이터유형_b
FROM table
// 문자형 -> 숫자형
SELECT '5'::INTEGER
FROM table✔️ 예제
Q. inventory_id의 자리수를 구하여라.
SELECT CHAR_LENGTH(CAST(inventory_id AS VARCHAR)
FROM rental;✴︎ NULLIF 키워드
두 개의 값을 인자로 받아,
1. 두 값이 같으면 → NULL
2. 두 값이 다르면 → 첫번째 값을 반환한다.
👉 NULL 값으로 에러가 발생하는 것을 방지하고 싶거나, 원하지 않는 결과가 나오는 것을 방지하고 싶을 때 유용하다.
✔️ 기본 문법
NULLIF(arg1, arg2)
NULLIF(10, 10) // NULL
NULLIF(10, 12) // 10✔️ 예제
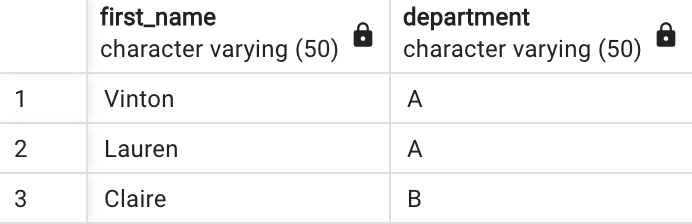
❶ CREATE TABLE
CREATE TABLE depts(
first_name VARCHAR(50),
department VARCHAR(50)
)❷ INSERT
INSERT INTO depts(
first_name,
department
)
VALUES
('Vinton', 'A'),
('Lauren', 'A'),
('Claire', 'B')👉 결과
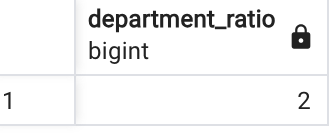
❸ A/B부서의 비율을 구별하고 싶다면(CASE)
SELECT (
SUM (CASE WHEN department = 'A' THEN 1 ELSE 0 END) /
SUM (CASE WHEN department = 'B' THEN 1 ELSE 0 END)
) AS department_ratio
FROM depts👉 결과
❹ 만약 B부서의 직원이 퇴사했다면? (DELETE)
DELETE FROM depts
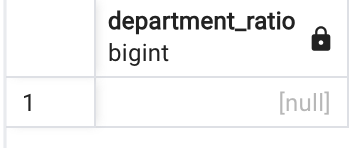
WHERE department = 'B'❺ 퇴사 후 현재 비율 구하기 (NULLIF)
현재 B부서의 인원은 0이므로 아래 코드는 error가 발생한다.
이때 NULLIF를 사용해 error가 아닌→ NULL값이 반환되게 할 수 있다.
SELECT (
SUM (CASE WHEN department = 'A' THEN 1 ELSE 0 END) /
// NULLIF의 두 인자 값이 같으면 NULL을, 다르다면 첫 번쨰 인자 값이 반환된다.
NULLIF(SUM (CASE WHEN department = 'B' THEN 1 ELSE 0 END), 0)
) AS department_ratio
FROM depts👉 결과
✴︎ VIEW
CREATE VIEW customer_info AS
SELECT first_name, last_name, address
FROM customer
INNER JOIN address
ON customer.address_id = address.address_id;
SELECT * FROM customer_info
CREATE OR REPLACE VIEW customer_info AS
SELECT first_name, last_name, address, district
FROM customer
INNER JOIN address
ON customer.address_id = address.address_id;
DROP VIEW IF EXISTS customer_info
ALTER VIEW customer_info RENAME to c_info