모델링
AST 후반부에서 가장 크게 달라진 점은 체계적인 실험지 기록과 Learning Rate 서치 였다.
AST 전반부 까지는 실험을 굉장히 중구난방식으로 진행하여 실험 결과 트래킹에 어려움을 겪었다. 그래서 모델링을 시작하기 전에 실험 기록지를 스프레드시트에 특정 format에 맞춰 만들었다. 정말 이 번에는 마지막이기도 하고 혹시 모를 대참사를 막기 위해 더 체계적으로 관리를 하였다.
그리고 Learning Rate Search를 통해 모델이 더 안정적으로 학습할 수 있었다.
실험 기록지 소개
- AST Model configuration
- 증강 parameters
- 분류 모델 hyperparameter 설정 값
- 이 에 따른 특정 epoch 의 test accuracy
- Train Validation 그래프
이렇게 크게 4가지로 구분 지어 실험 기록지를 만들었다. 더 자세히 보고 싶으면 아래 링크를 통해 확인할 수 있다.
Learning Rate Search 소개
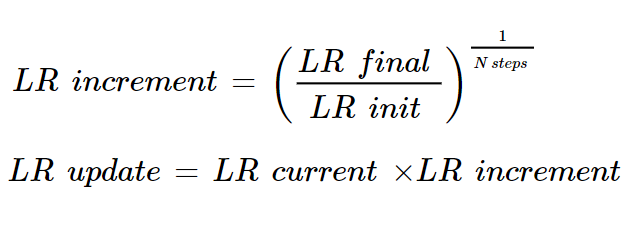
위 수식은 우리가 사용했던 Learning Rate Search 방식이다.
조금 더 부연설명을 하면 한 에폭에 batch가 input으로 들어올 때마다 LR init이 LR final까지 n_step 만큼 LR increment 이 증가하여 loss가 가장 적은 Learning Rate를 선택하는 것이다.
Learning Rate Search 코드는 아래와 같다. (방법 및 코드 출처: ChatGPT)
def find_learning_rate(model, train_loader, loss_fn, device='cpu'):
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
lr_find_loss = []
lr_find_lr = []
lr_init = 1e-8 # <<<< 요기만 바꾸면됨
lr_final = 1e-2
n_steps = 100
current_lr = lr_init
lr_increment = (lr_final / lr_init) ** (1/n_steps)
model.train() # Set model to training mode
for batch_idx, batch in enumerate(train_loader):
inputs, targets = batch
inputs, targets = inputs.to(device), targets.to(device)
optimizer.param_groups[0]['lr'] = current_lr
outputs = model(inputs)
loss = loss_fn(outputs, targets.squeeze())
optimizer.zero_grad()
loss.backward()
optimizer.step()
lr_find_loss.append(loss.item())
lr_find_lr.append(current_lr)
current_lr *= lr_increment
if current_lr > lr_final:
break
return lr_find_lr, lr_find_loss📌 혹시 Classification 부분을 읽기 전에 AST 모델 구조가 궁금하시면 아래를 읽어주세요.
AST 모델 구조 및 forward 과정
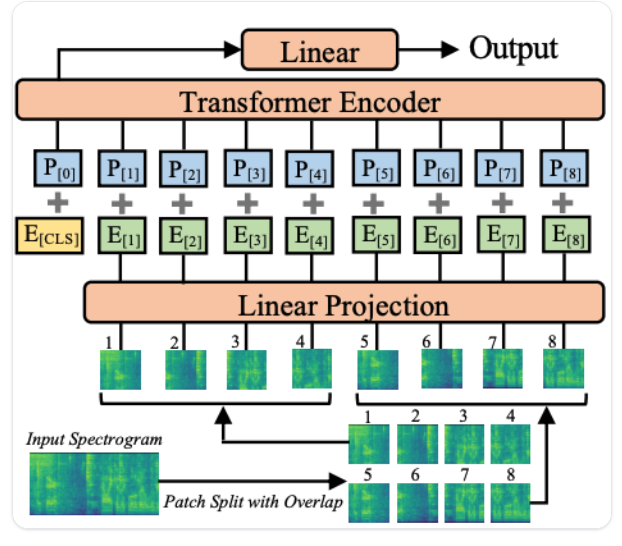
AST 모델 Forward 과정
- (1024, 128)의 형태인 Mel Spectrogram이 input으로 들어간다.
a. 1024는 Time Step(sequence), 128은 mel filter bank 갯 수 - Mel Spectrogram은 16 x 16 patch로 쪼개진다. 위 그림에서 1번, 2번 같이 숫자로 지정된 것들이 patch들이다.
- Linear Projection에서 Convolution 2d로 한 개의 patch를 768개의 값을 추출하여 1d array 형태인 임베딩 값으로 변환한다.
a. out-channel: 768

- 그리고 encoder에 forward 되기 전에 sequence 처음 구간에 CLS 토큰이 추가된다.
- 위치 정보를 담기 위해 Positional Embedding이 더해진다.
- Encoder를 통과 후 최종적으로 Layer Normalization을 거치면 (1214, 768) 형태인 임베딩값이 나온다.
a. 1214: sequence/time step, 768: feature/hidden dimension
이 변화들을 가지고 우리 팀은 두 가지 방향으로 분류를 진행하였다.
1. Dense Layer Classification
처음에는 embedding을 그대로 flatten을 시켜 분류를 진행하였다. 하지만 첫 번째 Dense Layer에서 neuron 크기가 90만 이상이 되어 우려가 됐다. 그래서 Computational Power를 고려해 Pooler Output을 써서 분류해보기로 했다.
flatten 후 분류 실험은 스프레드시트에서 확인 가능
👉 으아앙팀 AST 모델 실험 기록지 👈
처음에는 Pooler Output이 뭔지 잘 몰라서 멘토님께 여쭤봤다.
멘토님께서 설명하길 Pooler Output은 전체 Hidden Attention Layer를 거친 후 압축한 embedding 값이라고 설명했다. 더 자세한 설명은 아래 HuggingFace에서 제공한 Documentation을 읽어보면 된다.

사실 필자는 Documentation을 읽어봤지만 BERT에 대한 이해가 없어 이 부분은 넘겨버렸다. 그냥 압축된 임베딩이라고 머릿속에 담고 진행하였다.
물론 바로 분류 모델을 쌓아서 실험을 진행했지만 한 번 Pooler Output이 Classification에 적합한지 보기 위해 각 클래스마다 Pooler Output을 뽑아 T-SNE로 클러스터 여부를 보았다.
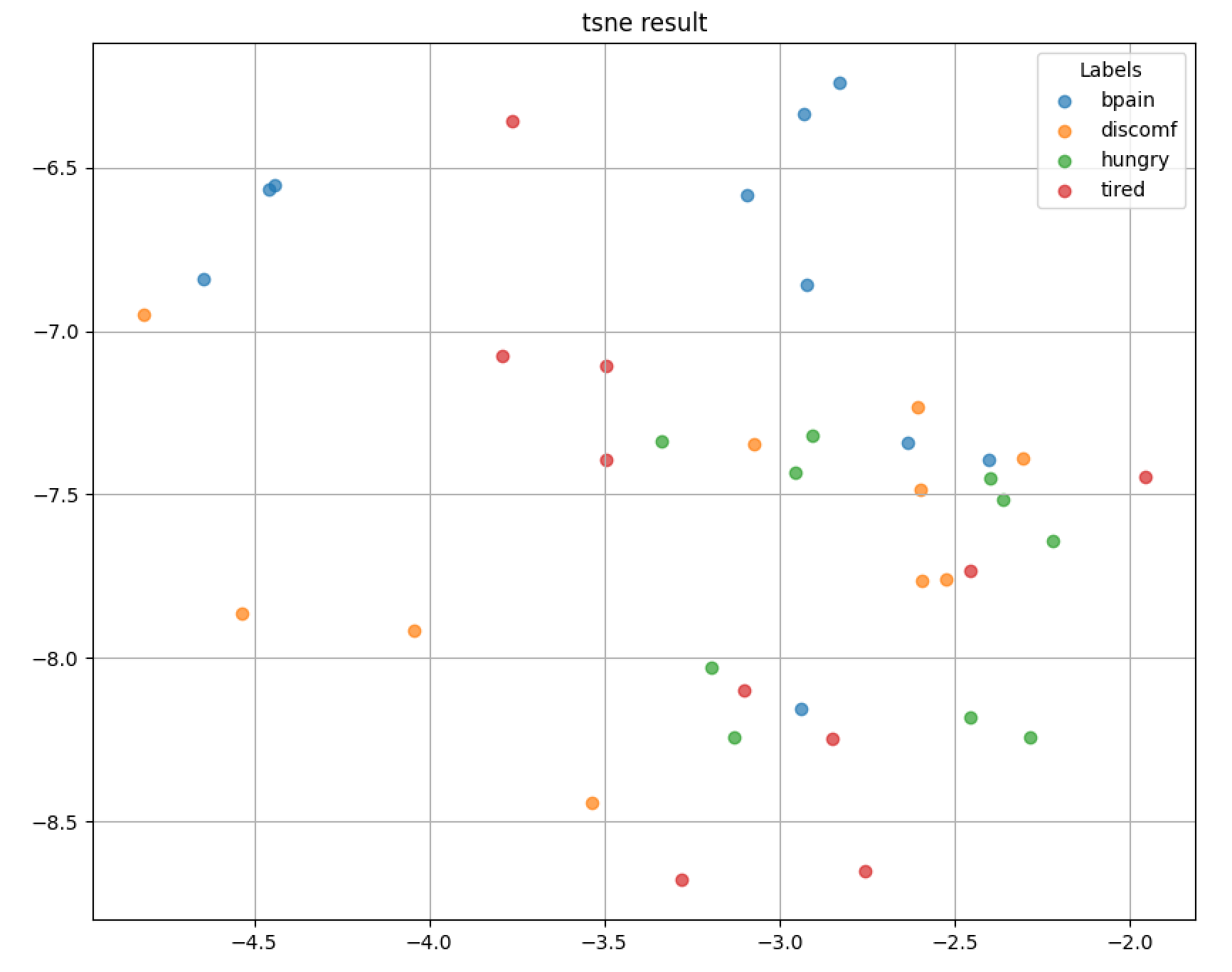
Pooler Output Classification 결과
- 여러 개의 실험이 있었지만 여기서는 그나마 대표적인 것만 표시
- 나머지 실험들은 스프레드시트에서 확인 바람
- Test Accuracy: 53.00%
- Train, Validation 그래프
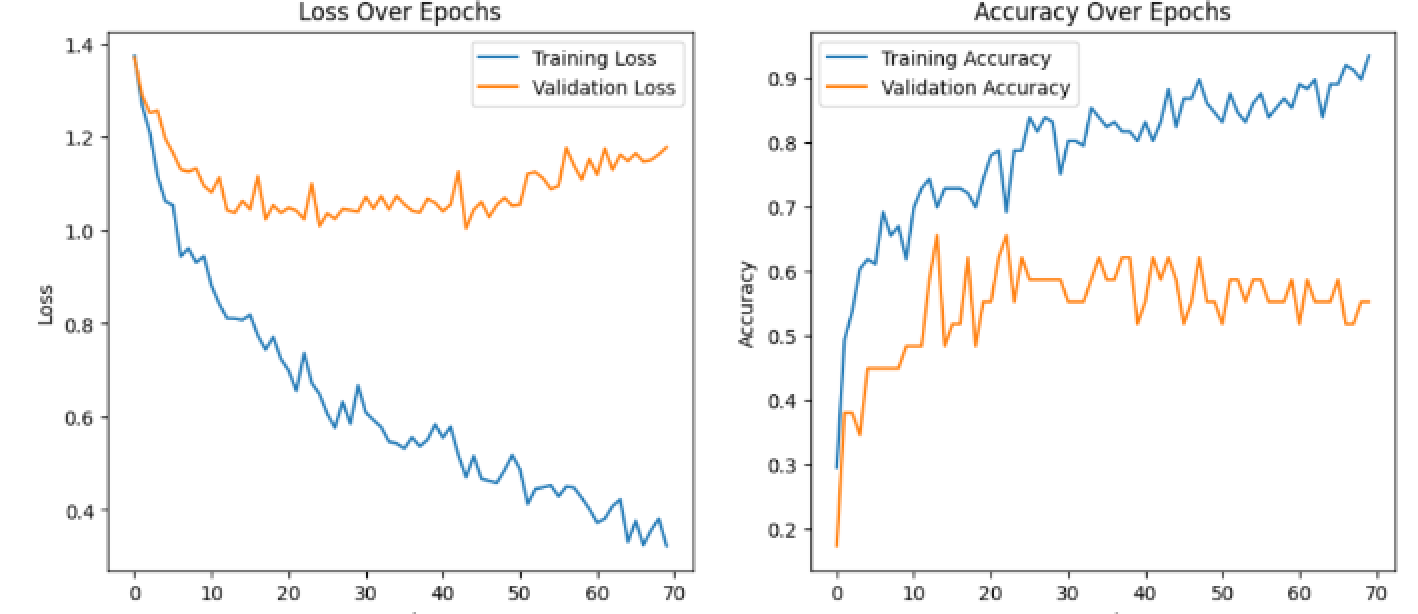
그래프가 보여지는 것 처럼 오버피팅이 심했기 때문에 좋은 결과를 보지는 못했다.
결과적으로 T-SNE에서 클러스터 여부와 그래프, Test Accuracy를 고려했을 때 Pooler Output이 classification에 적합하지 않았다고 생각했다. 물론 그때 상황에서의 판단이었고 더 좋은 하이퍼파라미터나 데이터 셋의 사이즈와 다양성이 컸으면 또 다를 수도 있었기 때문에 Pooler Output에 대한 결론은 사실 조금 객관적이지 않을 수 있다.
아쉬운 실험 결과로 결국 우리 팀은 Convolution 1d에 희망을 걸게 되었다.
2. Convolution 1D Classification(최종 모델 채택)
CNN을 이미지 분류에서 다루어 받기 때문에 처음에는 Convolution 1D는 괜찮을 거라 생각했다. 하지만 우리가 익숙해 있었던 건 일반적인 convolution 2D, 3 채널 이미지에서 Pointwise Convolution 혹은 Depthwise Convolution 연산들이었고 Convolution 1D는 다른 각도로 접근했어야 했기 때문에 생각보다 생소하게 느껴졌다.
그래도 멘토님의 설명 덕분에 빠르게 이해하고 넘어갈 수 있었다.
아래 그림은 우리가 설계한 Conv1d 구조이다.
그림 1
우선 AST 모델을 통과하게 되면 (1214: sequence, 768: hidden dimension) 사이즈의 임베딩 값을 가지게 된다. 그 후 Transpose를 취하고 Convolution을 연산을 하여 1d array의 형식인 512개 channel의 Feature Map을 만든다.
여기서 자세히 볼 건 처음에 2D 임베딩이 어떻게 Convolution 연산을 거치는 것이다. Convolution 2D와 다른 점은 Convolution의 stride 가 횡 이동 없이 세로 방향으로만 이동이 된다. 그래서 Kernel Size 4는 열(Sequence) 기준으로 얼마큼 차지하는지의 의미로만 보면 된다.
더 쉽게 이해하기 위해 아래 그림을 참고하는 게 좋다.
그림 2
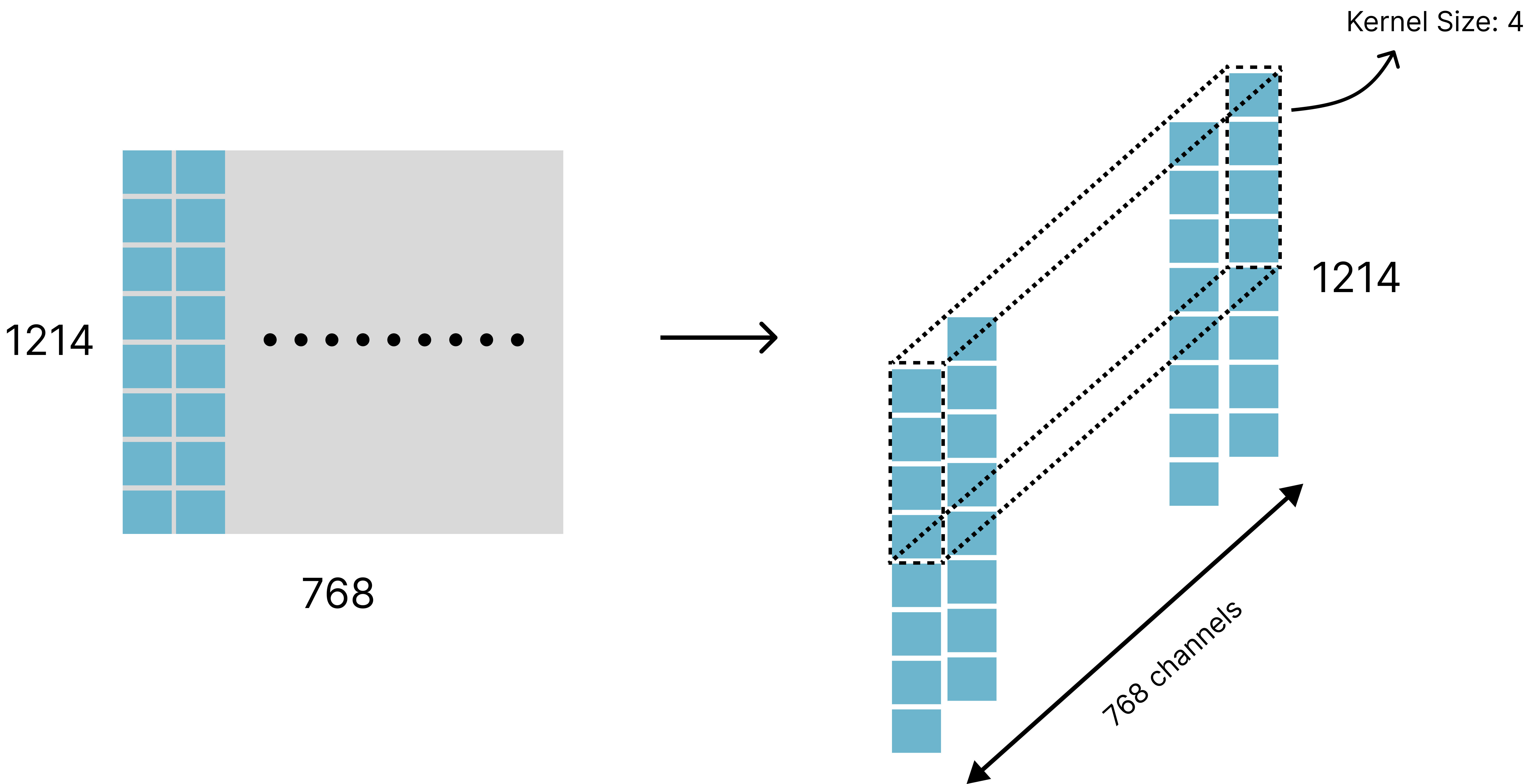
먼저 그림 2 왼쪽 부분에서 (1214, 768) 인 임베딩을 보면 (1214, 1)인 array를 768 만큼 나열된 걸 볼 수 있다. 그리고 그림 2 오른쪽 Feature Map 처럼 다시 나열한다고 생각하면 된다. 그러면 768 channels 의 (1214, 1) array들로 구성된다.
그리고 Kernel Size 가 4인 경우 똑같은 Kernel이 768 번 Convolution 연산이 된다. 그래서 Convolution 2D 로 따져보면 그림 1 처럼 (768, 4)인 커널을 갖게 되는 셈이다. 그림1 의 빨간색 박스를 보면 (768, 4)의 형태인 Kernel를 볼 수 있다. 그림2 에선 점선으로 이어진 Kernel들이 같이 세로로 움직인다고 보면 된다.
conv1d 코드 예시# Conv1d starts self.conv1d1 = nn.Sequential( nn.Conv1d(in_channels=768, out_channels = 512, kernel_size = 4, stride = 1), nn.BatchNorm1d(512), nn.ReLU())
Convolution 1D 이후 Global Average Pooling을 하여 flatten을 시켰고 Dense Layer 하나만 쌓아서 Classifier Layer 로 분류를 진행하였다.
Dense Layer 코드self.adapted = nn.AdaptiveAvgPool1d(1) # Dense Layer self.layer_fc3 = nn.Sequential( nn.Linear(512,128), nn.BatchNorm1d(128), nn.GELU(), nn.Dropout(0.3)) self.add_layer_01 = nn.Linear(128, num_labels) self.num_labels = num_labels
실험 결과는 다음과 같다.
- Epoch 50
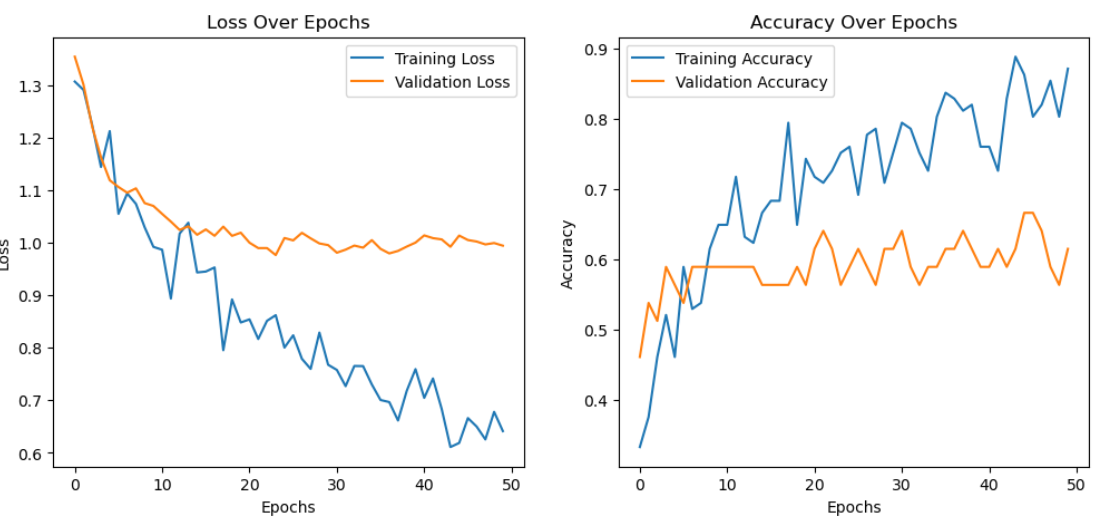
Test Accuracy: 74.36%
- Epoch 75
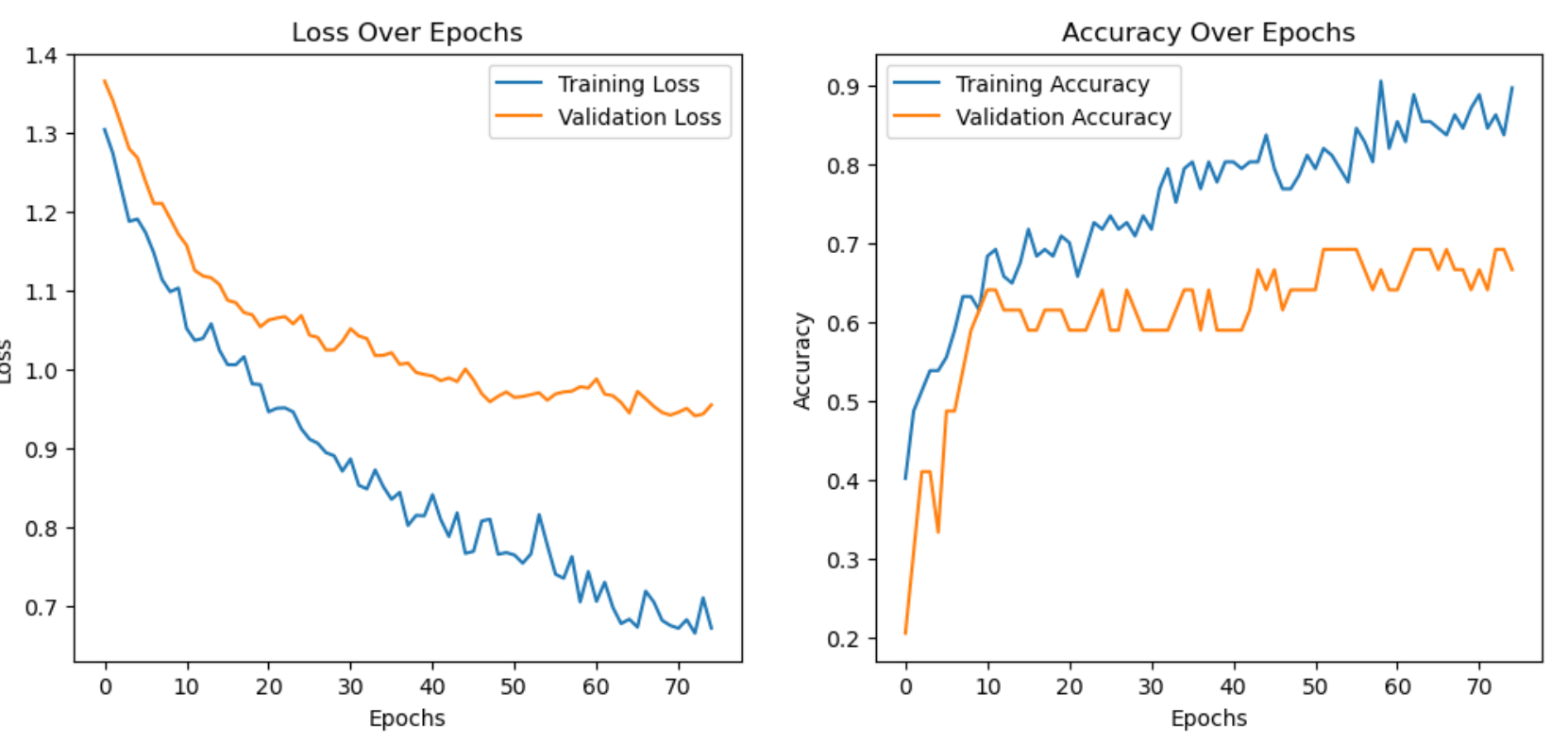
Test Accuracy: 69.23%
그래서 전체 모델별 Test Accuracy 는 아래와 같이 정리해 볼 수 있다.
| Test Accuracy | |
|---|---|
| VGG16 | 35.00% |
| Multi_input_DNN | 58.21% |
| U-Net with Classifier | 58.82% |
| AST | 74.36% |
