AST 여정 후반부
Back to Square One(다시 시작)
AST 전반부에서 훈련한 모델을 서버에 배포 후 앱에서 아기 울음소리를 직접 녹음해 테스트를 진행했다. 이때 앱 테스트 전 Test Accuracy는 70%를 살짝 넘기는 정도여서 나름 만족을 하고 있었다. 하지만 앱에서 테스트 결과 복통에만 치우치는 inference 결과를 확인했다. 전반부 모델링, 데이터 EDA, 전처리를 맡은 나로서 팀원들에게 굉장한 치명타를 안겨주었다. 이때 정말 프로젝트 전체적으로 어떤 Miss 가 있었는지 주마등처럼 스쳐 지나갔다. 그리고 더 최악인 건 프로젝트 끝나기 2주 남기고 이 사태가 벌어진 것이었다. 정말 쥐구멍이 없으면 손톱이 부러지더라도 구멍을 파서 없어지고 싶었다. 하지만 팀원들이 바로 다시 시작해 보자고 했다. 2주 남기고 이렇게 빨리 결단을 내려 대응한 용기가 정말 대단했다고 생각했다. 정말 전생에 어떤 일을 했길래 이렇게 좋은 팀원들을 만났는지 그저 감사할 따름이었다.
우선 팀원들 각각 맡은 울음소리를 하나씩 들으면서 소음이 많거나 울음소리가 잘 안 들리는 오디오를 정제해 나갔다. 이렇게 해서 아래 그래프처럼 다시 데이터 셋을 구축했다.
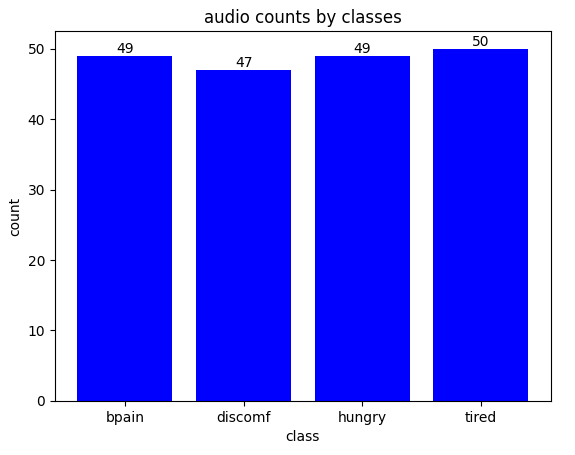
데이터 셋 사이즈가 더 작아졌지만 제대로 된 학습을 위해 양보단 질을 선택해 좋은 데이터를 선별하는 게 맞다고 생각했다.
그리고 이 번에는 EDA를 더 면밀히 진행했다. 진행한 EDA 항목은 다음과 같다.
EDA
- Sampling Rate 체크
- 오디오 길이 체크
- 클래스별 평균 증폭, 배음 갯수, 평균 주파수
- 클래스 별 평균 Mel Spectrogram을 기반으로 주파수 산출
Sampling Rate
Sampling Rate가 중요한 이유는 오디오의 resolution을 나타내기 때문에 얼마나 정보를 담고 있는지 정해주는 요소이다. 그래서 Sampling Rate가 높을수록 음질이 올라간다.
아래 영상을 들어보면 Sampling Rate가 낮아질수록 음의 정보가 점점 없어지는 걸 느낄 수 있다.
https://www.youtube.com/watch?v=hRhVb6iRArg
그래서 오디오 관련 모델링에선 Sampling Rate에 따라 학습되는 정보량이 달라지기 때문에 중요한 요소이다.
또한 어떤 Sampling Rate으로 pretrained model 이 학습되어 있는지도 중요하기 때문에 전처리 부분에서 pretrained model에 설정된 sampling rate에 맞게 오디오를 불러오는 것도 중요하다.
다시 정리해서
- Sampling Rate는 오디오의 Resolution
- Pretrained Model에 설정된 Sampling Rate에 맞게 오디오 load
각 클래스마다 sampling rate을 분석한 결과 아래 같이 정리할 수 있었다.
| Sampling Rate(Hz) | |
|---|---|
| 복통 | 48000: 75.5%/ 44100: 6.1%/ 8000: 18.4% |
| 불편함 | 44100: 36.2%/ 8000: 63.8% |
| 배고픔 | 44100: 12.2%/ 8000: 87.8% |
| 피곤함 | 48000: 44.0%/ 44100: 6.0%/ 16000: 16.0%/ 8000: 34.0% |
생각보다 40kHz 이상인 sampling rate가 상당히 많았다.
오디오 길이
좀 더 일정하게 데이터 input을 맞추기 위해 오디오 길이 체크도 진행했다. 각 클래스마다 오디오 길이는 아래와 같이 확인할 수 있다.
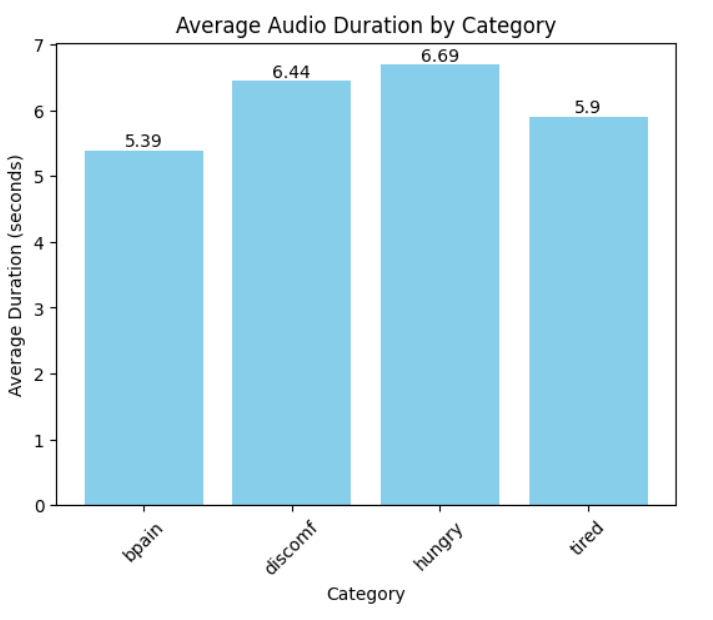
평균 오디오 길이는 약 6초가 나왔다.
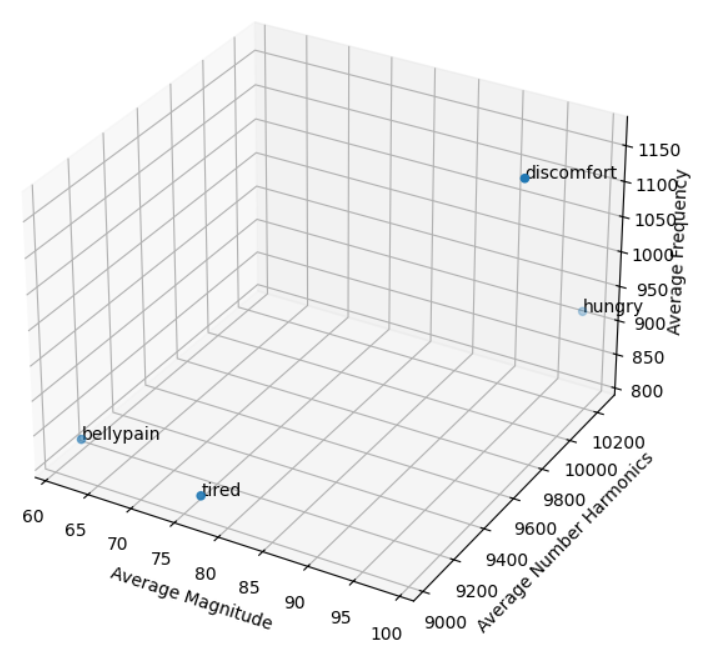
클래스별 증폭(Magnitude), 배음 갯 수, 가중평균 주파수
| 클래스 | 평균 증폭량 (magnitude, peak 25 이상 기준) | 평균 배음 갯 수 (peak 25 이상기준) | 가중평균 주파수 (HZ, 평균 멜스펙트럼 기준) |
|---|---|---|---|
| 복통 | 61.5 | 9082 | 826.8 |
| 불편함 | 97.0 | 9906 | 1164.6 |
| 배고픔 | 98.8 | 10242 | 920.7 |
| 피곤함 | 76.4 | 9030 | 815.4 |
- 증폭은 음의 세기를 의미
- 배음은 주(기본) 주파수외 다른 주파수들을 의미
- 배음의 수가 많을수록 복합적인 소리(음색)를 낸다.
- 주파수는 음의 높 낮이를 의미
위 세 개의 feature를 가지고 각 클래스를 간단히 3d scatter plot으로 분류를 진행해 보았다.
클래스별 평균 Mel Spectrogram
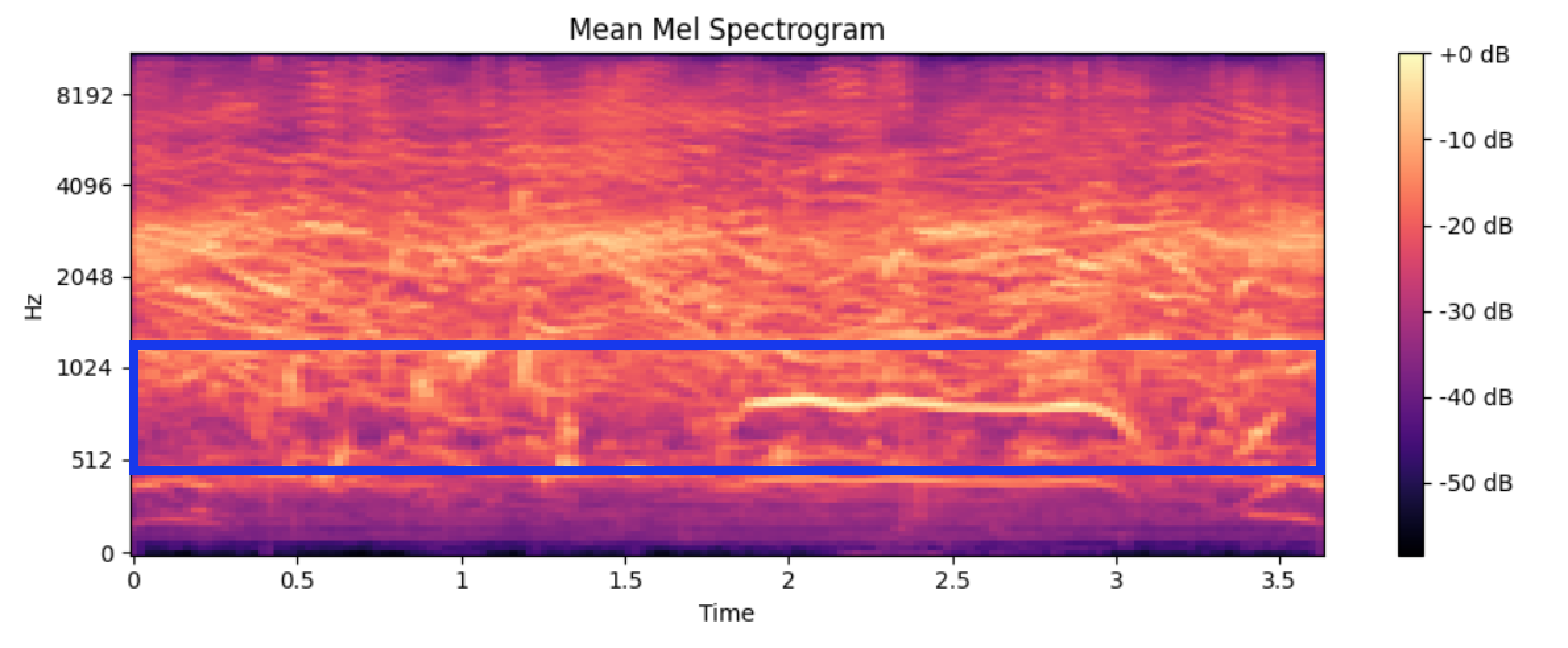
사실 어떻게 보면 평균 Mel Spectrogram이 우리 팀에게 가장 중요한 인사이트를 주었다. 왜냐하면 클래스별 평균적으로 어떤 주파수가 주요한지 볼 수 있었기 때문이다.
먼저 클래스별 평균 Mel Spectrogram을 살펴보면 아래와 같다.
복통
불편함
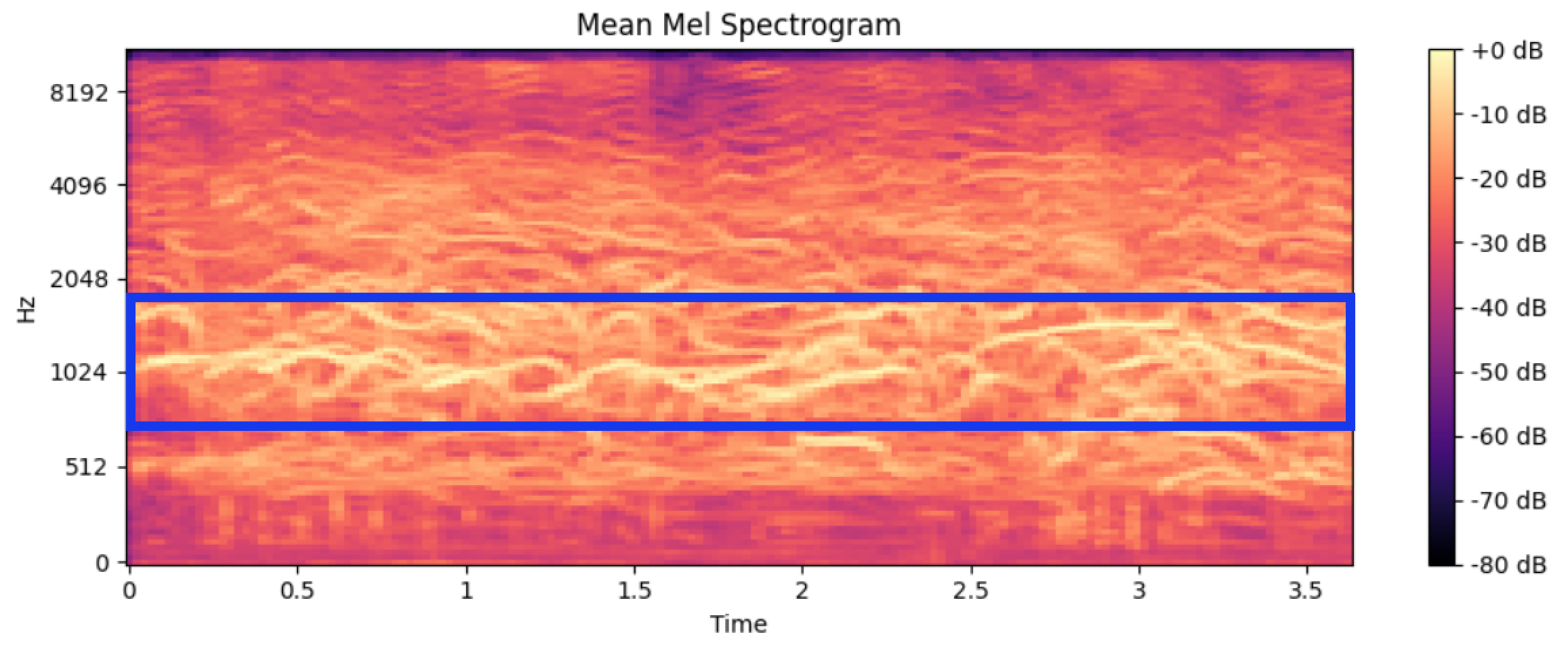
배고픔
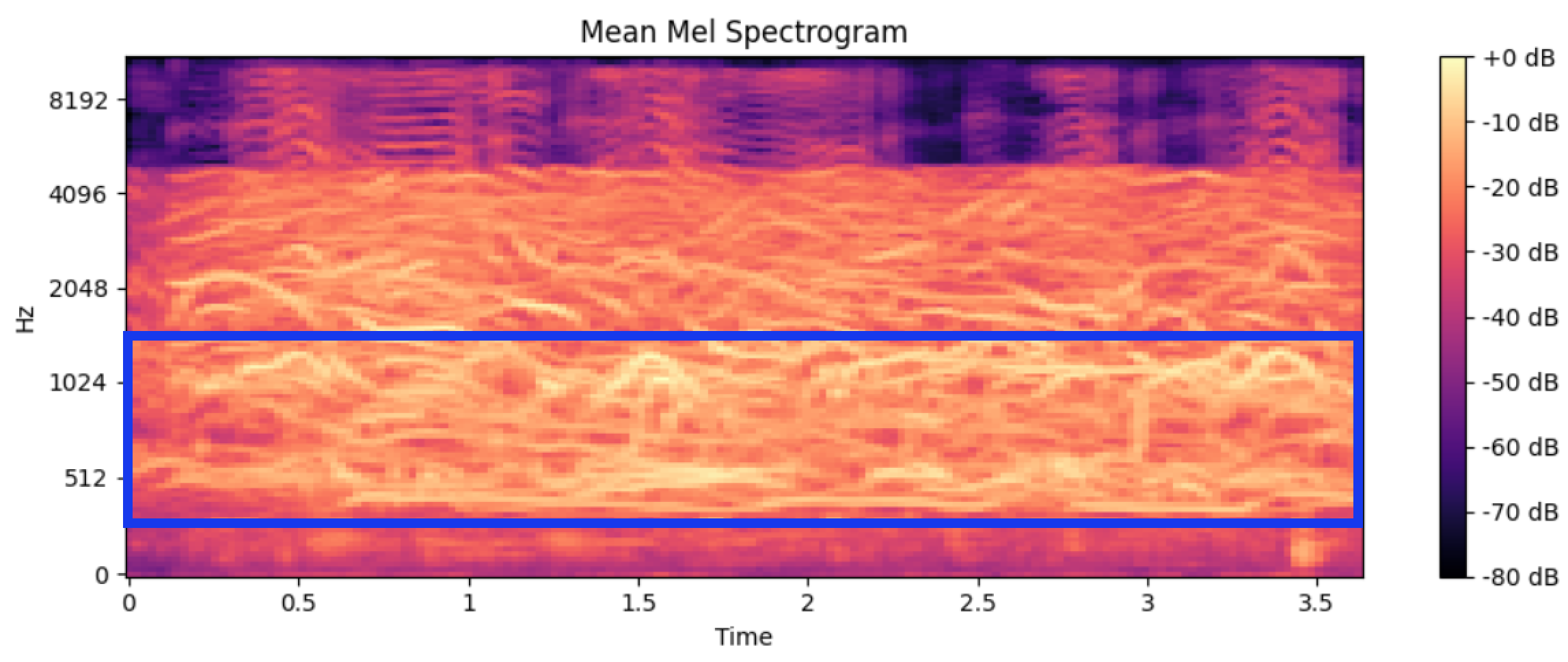
피곤함
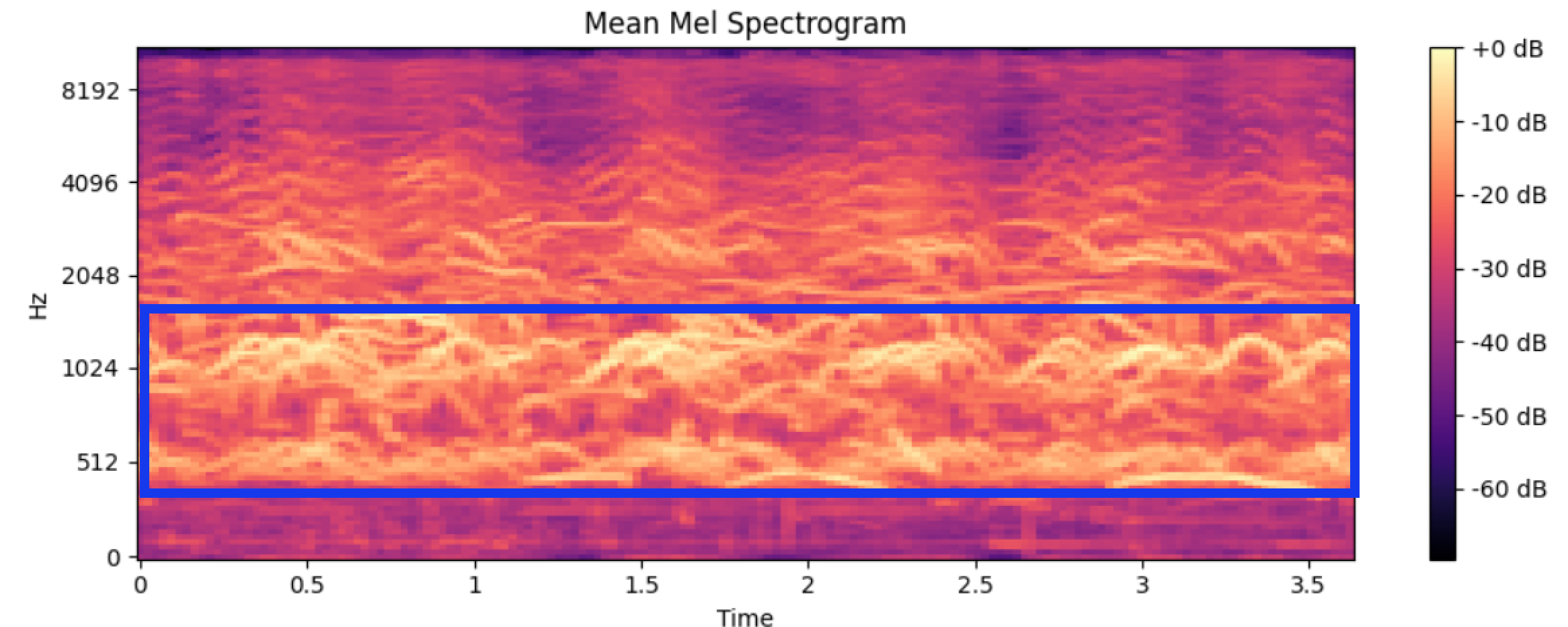
Mel Spectrogram은 x 축에는 시간, y 축에는 주파수(Hz), 색은 Magnitude를 의미한다. 색이 밝을수록 소리의 세기가 크다고 볼 수 있다.
주파수와 Magnitude를 기준으로 파란색 Bounding Box 안에 클래스마다 주요한 주파수를 찾을 수 있었다.
위 표를 다시 가져오면 클래스 별 가중평균 주파수가 Bounding Box 안에 포함되는 걸 확인할 수 있다.
- 산출 방법은 Lower Bound와 Upper Bound를 정하고 각 주파수의 증폭을 가중치로 두어 주파수들의 가중평균을 계산하였다.
- 방법 및 코드 출처: ChatGPT
# find the average frequency in this range
# multiply the magnitude by the frequency to get a weighted sum
weighted_frequencies = np.sum(target_range * mel_frequencies[lower_bound_idx:upper_bound_idx+1, np.newaxis], axis=0)
total_magnitude = np.sum(target_range, axis=0)
average_frequency = np.sum(weighted_frequencies) / np.sum(total_magnitude)
average_frequency이 인사이트를 바탕으로 모델 학습 시 주요한 주파수에 집중할 수 있도록 BandPass Filter를 사용하기로 했다.
👉👉 다음 챕터 읽으러 가기
