U-Net Encoder의 데뷔 무대
비지도 학습이 끝이 난 후 드디어 우린 U-Net Encoder의 데뷔 무대를 볼 수 있었다. 뭐든 시작에는 설렘과 긴장이 반반 섞여있듯이 기대반 긴장반인 상태로 훈련에 들어갔다.
우선 Dense Layer는 아래 같이 쌓았다.
# Dense layers after the encoder
inputs = layers.Input(shape= X_train_dim[0].shape)
input_layer = load_encoder(inputs)
full01 = layers.Flatten()(input_layer)
dense01 = layers.Dense(1024, activation='relu')(full01)
batch01 = layers.BatchNormalization()(dense01)
drop01 = layers.Dropout(0.25)(batch01)
dense02 = layers.Dense(512, activation='relu')(drop01)
batch02 = layers.BatchNormalization()(dense02)
drop02 = layers.Dropout(0.25)(dense02)
dense03 = layers.Dense(128, activation='relu')(drop02)
batch03 = layers.BatchNormalization()(dense03)
drop03 = layers.Dropout(0.25)(dense03)
# classifier
out_layer = layers.Dense(4, activation='softmax')(drop03)실험 결과
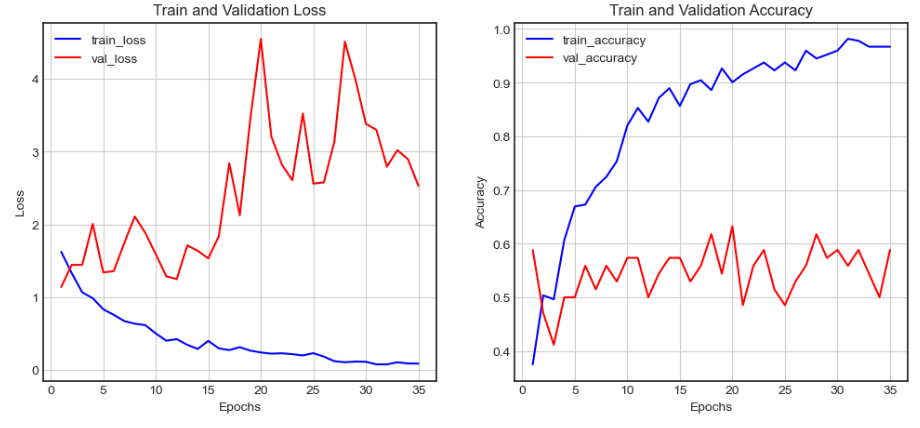
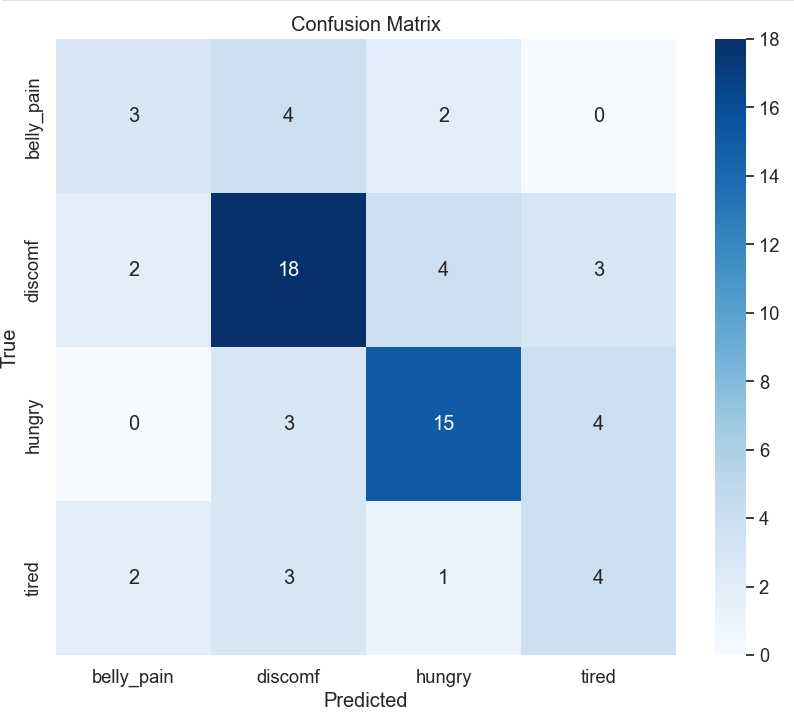
Test Accuracy: 58.82%
이 실험을 요약해 보면 Encoder의 데뷔전은 아쉬운 결과로 볼 수 있다. 그래프를 살펴보면 YAMnet에 비해 오버피팅이 확연하게 드러났고 Confusion Matrix를 통해 두 개의 클래스(불편함, 배고픔)를 주로 예측하는 모습을 볼 수 있다. Test Accuracy는 YAMNet 보다 소폭 증가하긴 했지만 그래프와 혼동행렬이 Robust하지 않음을 증명해주고 있다.
회고
가장 큰 문제였던 건 데이터셋 구성이 아닐까 싶다. 사실 이 프로젝트가 끝난 후 가장 크게 깨달은 점이 기본을 먼저 지키는 것이었다. 모델링 전에 데이터 셋 Balance가 어떤지 그리고 Input 사이즈의 의미 등등 EDA 부터 전처리까지 제대로 이루어지지 않았기 때문에 모델링에서 좋은 결과를 바라기에는 무리가 있다.
아래 그래프는 U-Net Classification에 사용된 데이터 셋 구성을 나타낸 그래프이다. 살펴보면 불편함, 배고픔이 가장 많다.
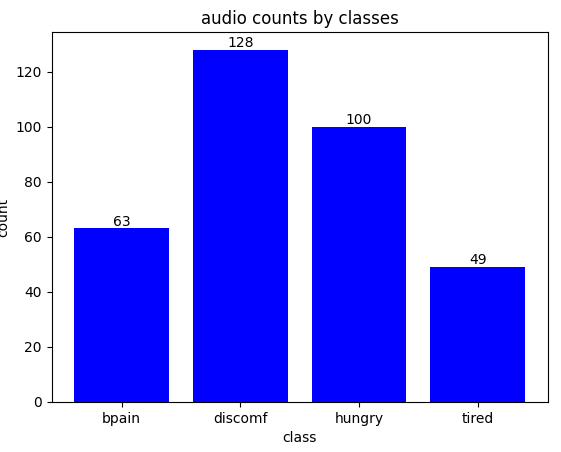
첫 번째로 Data Imbalance의 문제를 잡지 않고 모델링을 한 것이 치명타로 다가왔다.
두 번째로 Mel Spectrogram의 사이즈 의미에 대한 파악 없이 진행한 것이다. Data Imbalance 만큼 치명적이진 않지만 이 부분을 유심히 봤으면 좀 더 좋은 성능을 내지 않았을까 하는 아쉬움이 있다.
아래 코드가 우리가 사용한 Mel Spectrogram 추출 코드의 파라미터 들이다. 여기서 주목할 파라미터는 n_fft와 hop_length 이다. 이 두 개가 Mel Spectrogram의 사이즈에 영향을 주기 때문이다.
librosa.feature.melspectrogram(y=None,
# sr=22050,
# S=None,
n_fft=2048,
hop_length=512,
# win_length=None,
# window='hann',
# center=True,
# pad_mode='constant',
# power=2.0, **kwargs)좀 더 구체적으로 설명하면 n_fft는 window size인데 여기서 window size는 얼마만큼 전체 오디오를 잘라서 볼 것인지에 대한 파라미터다. 마치 CNN에서 Kernel Filter와 비슷한 역할을 한다. 단위는 millisecond(ms)이 기 때문에 위의 2048은 2.48초만큼 오디오를 들여다보는 것이다.
Hop Length 같은 경우 stride의 개념으로 보면 된다. Kernel Size에 맞춰 움직이듯이 Window Size 기준으로 얼큼 이동시키면서 오디오를 들여다볼 것인지에 대한 파라미터이다.
그래서 window size와 hop_length를 줄여 더 촘촘한 Mel Spectrogram을 뽑은 후에 학습을 돌려보면 좀 더 나은 결과 나오지 않을까 하는 추측을 해본다.
👉👉 다음 챕터 읽으러 가기
