데이터가 적을땐 Pretrained-model 이 인지상정! 그러나…
VGG16 성능에서 기대에 못 미치는 결과를 본 이유는 MFCC에 맞게 Kernel size와 stride를 설정을 못해준 이유도 있지만 데이터셋 사이즈 영향이 있는 것도 확실하다.
하지만 데이터 수집 부분에서 말했듯이 우리 팀은 만족할 수 있는 데이터 수량을 맞추지 못했다. 그래서 차 선택으로 pretrained model 을 써보는 방향으로 논의가 진행됐다.
마침 Kaggle에서 구글에서 제공한 AudioSet으로 학습된 pretrained-model이 있었다.
- Google에서 공개한 YouTube 영상에 기반한 오디오 데이터셋
a. 2,084,320 개의 영상을 오디오 셋으로 묶은 데이터셋
b. 이 중 아기 울음소리 영상은 무려 2390개나 포함
Pretrained-model 이름은 YAMNet이고 Mobilenet_v1 구조를 갖고 있다.
YAMNet 과의 여정
YAMNet을 찾은 후 왠지 안도감이 들었다. 따로 모델을 구축해서 분류할 필요 없이 바로 분류가 될 거라는 희망으로 김칫국 한 사발을 들이켰다. 역시 설레발 드링킹이 주는 안도감은 금방 꺼지기 마련이다.
그렇게 희망에 가득 찬 눈빛으로 분류를 시작하려 하는데…

또잉하는 맛은 역시 Documentation을 읽을 때 재 맛인 것 같다. 하하하하….. 😂😂
Documentation을 읽은 결과 YAMnet 의 output은 Scores, Embeddings, Mel-spectrogram이었다. Embedding은 YAMNet 을 거쳐서 Global Average 된 값이고 Score는 521 클래스에 해당하는 점수이다. Mel Spectrogram은 아래 설명을 참고 바람.
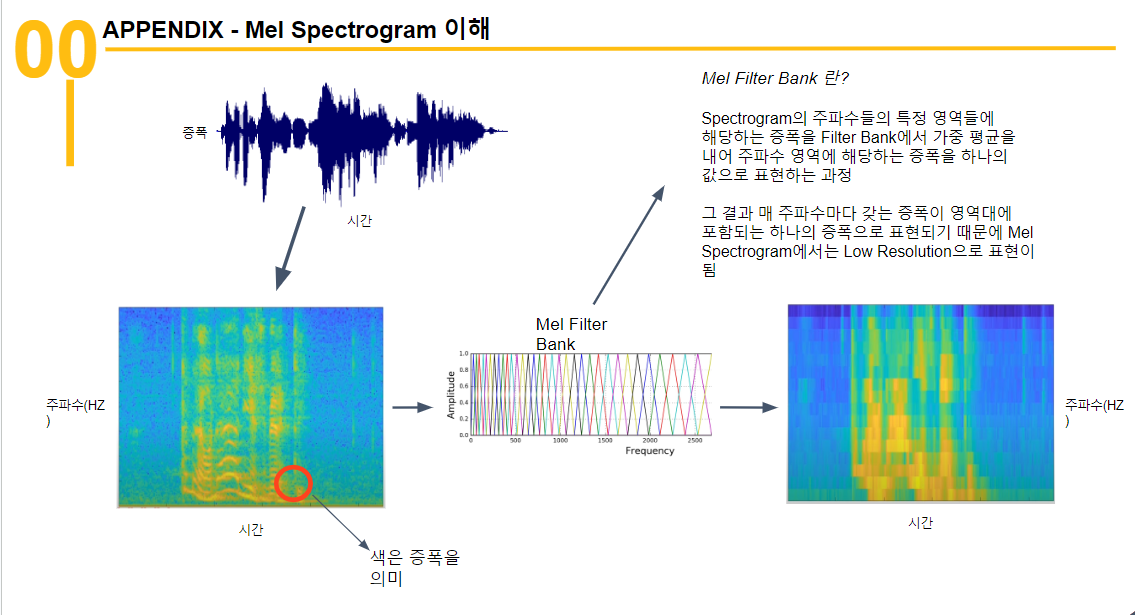
Mel-spectrogram 이란?
쉽게 설명해서 시간축과 증폭축에서 시간축과 주파수축으로 변환된 상태라 보면 된다. 위 사진은 변환과정을 나타낸 것이다. 더 정확하게 이해하려면 Fourier Transform을 봐야 한다. 그래서 Fourier Transform이 어떻게 Frequency Domain으로 변환하는지 알면 더 깊게 이해할 수 있다. 하지만 나도 여기까지 자세히 이해하는데 어려움을 겪어 아쉽게 Pass 하였다.
분류기는 따로 없는 걸 확인 한 순간 나의 안도감은 저 세상으로 가버렸다. 어떻게 보면 멍청한 실수를 한 것일지도 모른다. 모든 Pretrained-Model에서는 Embedding이나 Feature Map을 뽑아주는 역할이 주인데 분류기까지 바라는 어리섞은 희망이 나에게 가시로 돌아왔다. 더 군다나 VGG16으로 팀원들과 분류까지 했었는데 Convolution 이후 Dense Layer를 쌓는 과정 자체를 잠시 까먹은 나에게 참 어떤 말을 해줘야 할지 난감했다.
나의 일시적 수난시대는 잠시 뒤로 하고 팀원들과 어떻게 YAMNet을 활용 방안에 대해 얘기를 나눠본 결과 Multi-Input Deep Neural Network로 해보기로 결정했다.
이렇게 결정한 이유는 하나의 input 보다 3 가지 input(scores, embeddings, Mel Spectrogram)을 동시에 입력받아 Forward 시키면 좋은 성능을 기대할 수 있지 않을까 하는 이유로 시도해 보기로 했다.
Multi-Input Dense Layer Architecture
분류 모델 구조는 아래 그림과 같다.
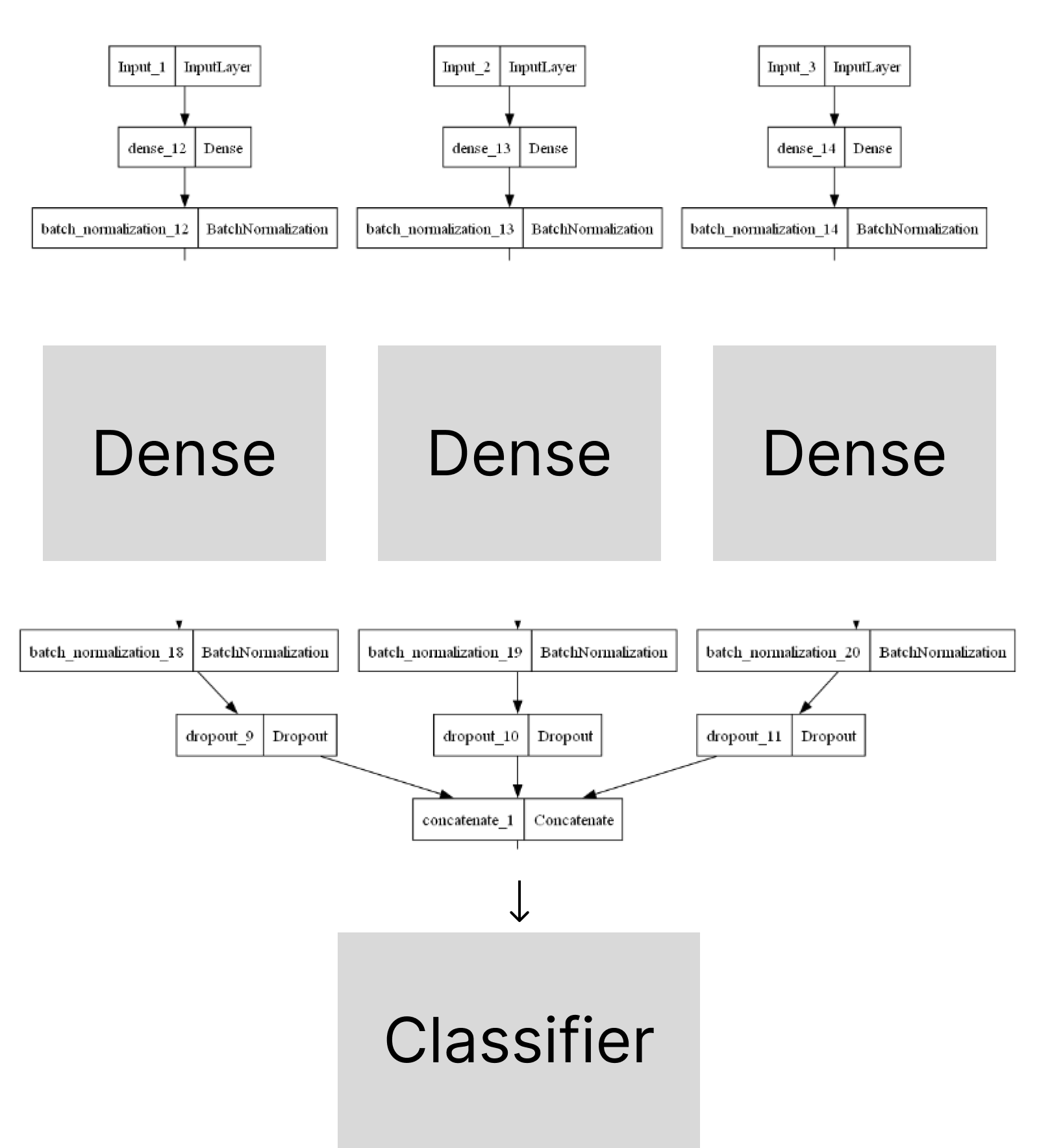
자세한 코드를 보시려면 아래 링크를 클릭 해주세요.
Multi-Input-DNN Notebook
실험결과
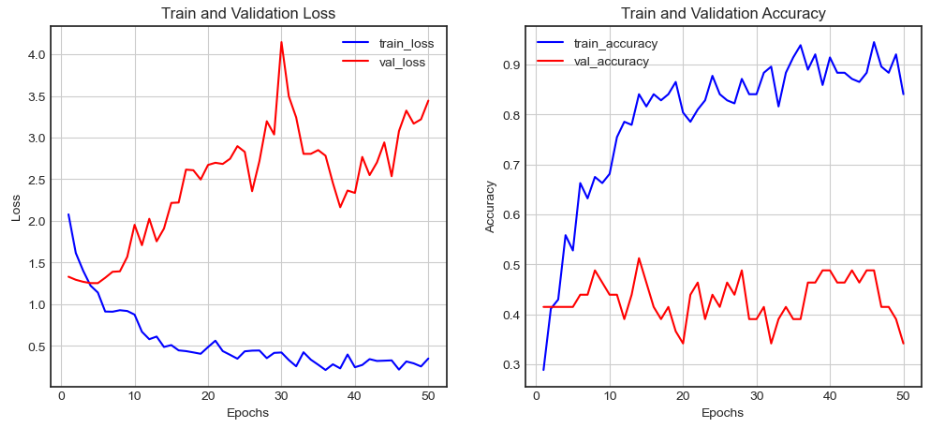
Test Accuracy: 34.15%
실험결과 좋은 성능을 내지 못하였다. 그래서 다시 논의 후 Mel Spectrogram을 입력받는 대신 MFCC로 진행해 보기로 하였다.
MFCC 실험결과
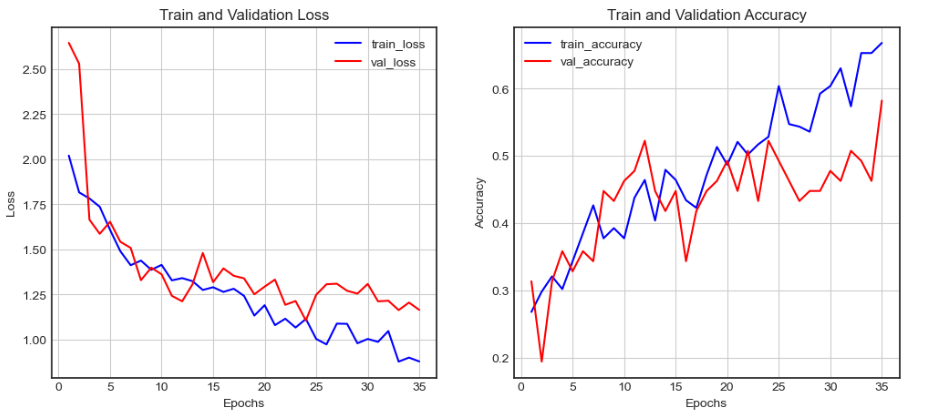
Test Accuracy: 58.21%
이전 실험보단 좋은 성능을 보였고 그래프도 전 보다 overfitting 덜한 걸 확인할 수 있었다. 그래서 우선 이걸로 추론 모델로 지정하였다. 하지만 여전히 낮은 성능을 개선하기 위해 우리 팀은 멘토링을 받기로 했다.
다만 Training Accuraccy가 아직 1.0을 못 찍었기 때문에 에폭을 더 늘려봤으면 하는 아쉬움이 남아 있다.
그리고 어차피 flatten 시켜서 입력을 받기 때문에 Score 대신 MFCC를 flatten 해서 입력을 주는 방식도 괜찮았을 것 같다.
감사 인사 to 우리 팀장님
이번 전반부 모델링은 팀원이자 팀장님인 임구 님께서 맡아 주셨는데 VGG16과 Multi Input DNN을 직접 다 구현해 주신 덕에 좋은 인사이트를 얻을 수 있었다. 모델 구현을 직접 하는 게 힘드셨을 텐데 감사 인사말로 마무리 지어 봅니다. 수고하셨어요 임구 님!!! 👍
강임구(팀장님스): 깃헙링크
👉👉 다음 챕터 읽으러 가기
