개발환경
22.06.14 - 22.06.17
HW : Windows10 64bits
IDE : PyCharm (파이참)
사용언어 : Python
앞선 프로젝트와 날짜가 겹치는 이유는 다른 성격의 프로젝트이기 때문이다.
파이썬의 requests, BeautifulSoup 라이브러리를 사용하여
웹사이트 크롤링을 하려고 한다.
파이썬 문법 복습
시작하기 앞서
파이썬 문법을 간단하게 리마인드 해보자
리스트(list) & 딕셔너리( dictionary)
a_list = [] # 리스트는 대괄호 a_list.append(1) # 리스트에 값을 넣는다 a_list.append([2,3]) # 리스트에 [2,3]이라는 리스트를 다시 넣는다a_dict = {} # 딕셔너리는 중괄호 a_dict = {'name':'bob','age':21} # key 와 value 로 구성 a_dict['height'] = 178Dictionary 형과 List형의 조합
people = [{'name':'bob','age':20},{'name':'carry','age':38}] # people[0]['name']의 값은? 'bob' # people[1]['name']의 값은? 'carry' person = {'name':'john','age':7} people.append(person) # people의 값은? [{'name':'bob','age':20},{'name':'carry','age':38},{'name':'john','age':7}] # people[2]['name']의 값은? 'john'
함수
# 기본형태 def 함수이름(매개변수): # 코드 내용 return 결과 # 예시) def sum_all(a,b,c): abc = a+b+c return abc result = sum_all(1,2,3) # result라는 변수의 값은? 6
조건문
# 기본형태 if 조건식: #코드내용 # 조건이 참일 때 실행 else: #코드내용 # 조건이 거짓일 때 실행# 예시 def oddeven(num): # oddeven이라는 이름의 함수를 정의한다. num을 변수로 받는다. if num % 2 == 0: # num을 2로 나눈 나머지가 0이면 return True # True (참)을 반환한다. else: # 아니면, return False # False (거짓)을 반환한다.
반복문 (for, while)
# for문 기본형태 for 변수 in 리스트(또는 튜플, 문자열): # 반복할 코드 내용 ...# 예시 fruits = ['사과','배','감','귤'] for fruit in fruits: print(fruit) # 사과, 배, 감, 귤 하나씩 꺼내어 찍힙니다.# while문 기본형태 while (조건식): #반복할 코드내용# 예시 (1부터 100까지 합계 구하기) num = 1 result = 0 while num <= 100: result += num num += 1 print(result)
웹 크롤링
기본 세팅
import requests from bs4 import BeautifulSoup # # 타겟 URL을 읽어서 HTML를 받아오고, headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'} data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers) # HTML을 BeautifulSoup이라는 라이브러리를 활용해 검색하기 용이한 상태로 만듦 # soup이라는 변수에 "파싱 용이해진 html"이 담긴 상태가 됨 # 이제 코딩을 통해 필요한 부분을 추출하면 된다. # soup = BeautifulSoup(data.text, 'html.parser') ############################# # (여기에 코딩 내용) #############################
오늘의 지니뮤직 차트를 크롤링해보자
- 크롤링할 정보가 무엇인가
- 1위 부터 200위 오늘의 차트
- 순위, 노래제목, 가수, 썸네일이미지url 이렇게 4가지를 크롤링 한다.
- 지니 뮤직 웹의 형태를 살펴본다
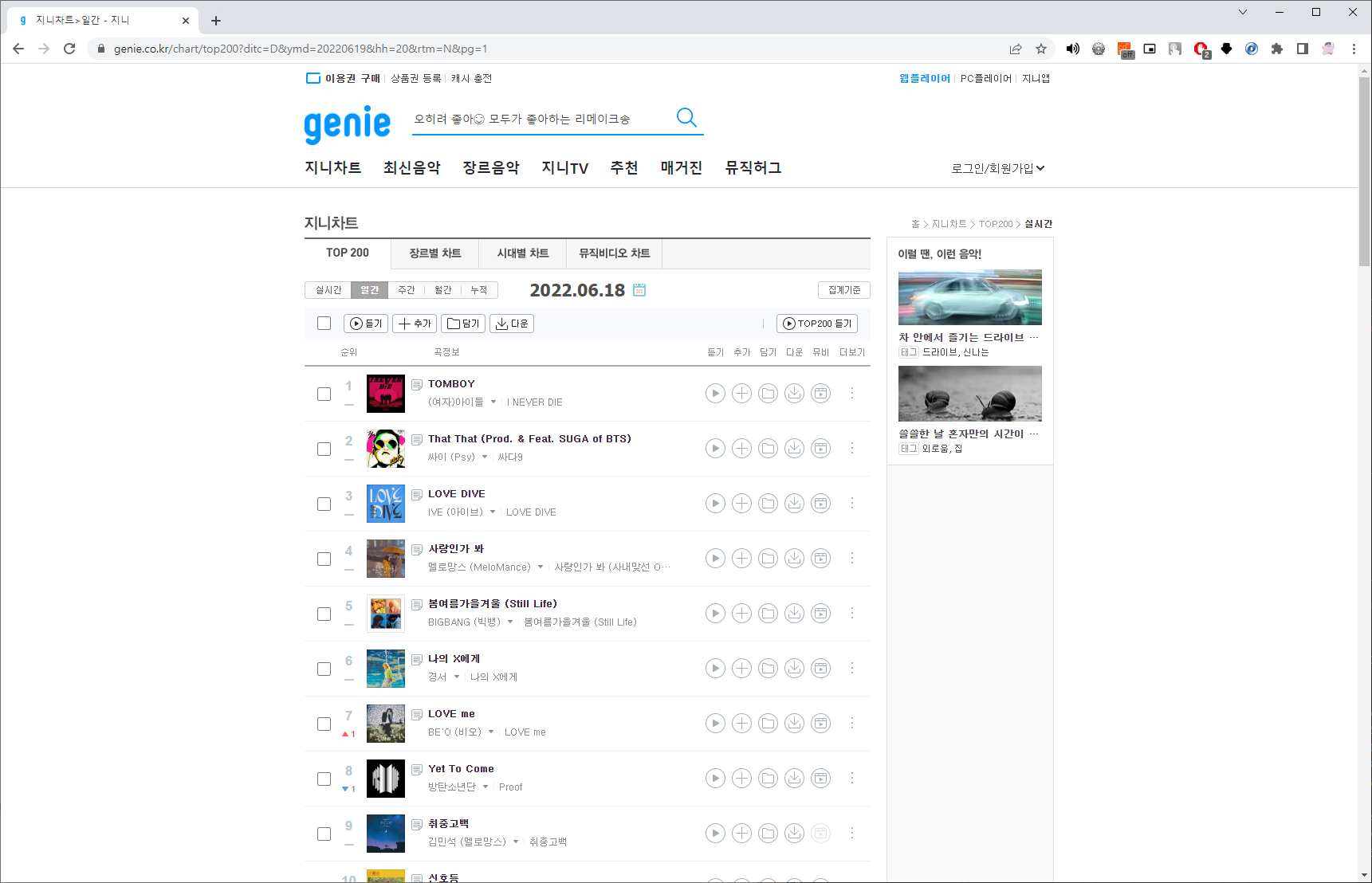
1) 사이트 상단
2) 사이트 하단
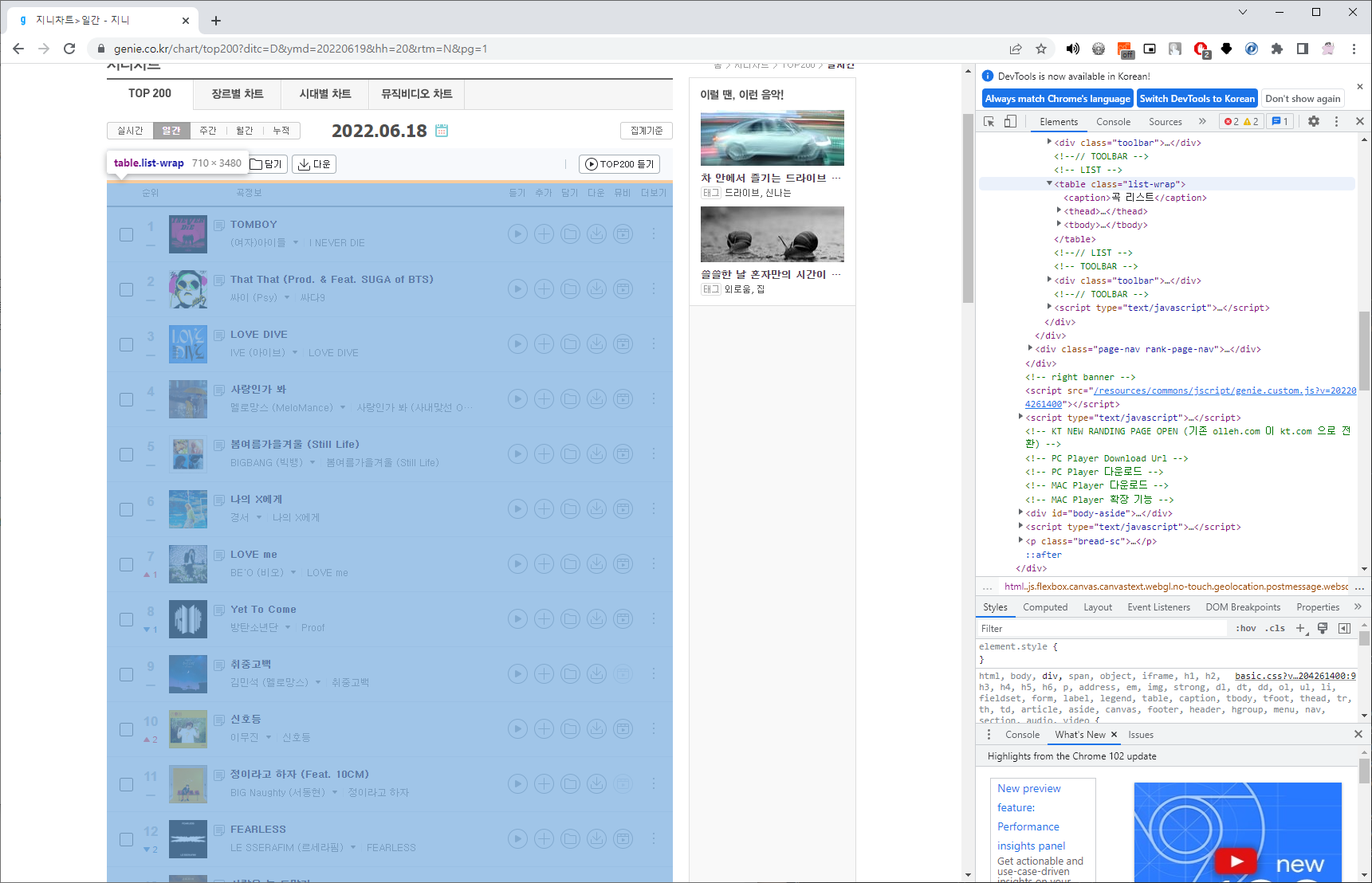
- table 태그안에 차트가 왼쪽부터 차례대로 순위, 썸네일이미지, 노래제목 그리고 그 아래 가수이름이 나오는 것을 확인 할 수 있다.
- 1~50위, 51~100위, 101~150위, 151~200위 이렇게 50단위로 페이징이 되어있다.
- 따라서 각 페이지의 url 4개가 필요하다. 반복문 활용하면 된다.
크롤링을 잘 하려면?(내 생각임.)
1) 사이트의 구조를 잘 파악해야한다.
2) 지니뮤직의 경우엔 크롬의 copy selector 기능으로 거의 커버가 가능하지만 그렇지 않은 곳이 더 많다. 따라서 눈으로 태그를 잘 쫒아서 찾아보는 습관을 들여보자
3) url도 잘 분석하자.
크롤링 코드
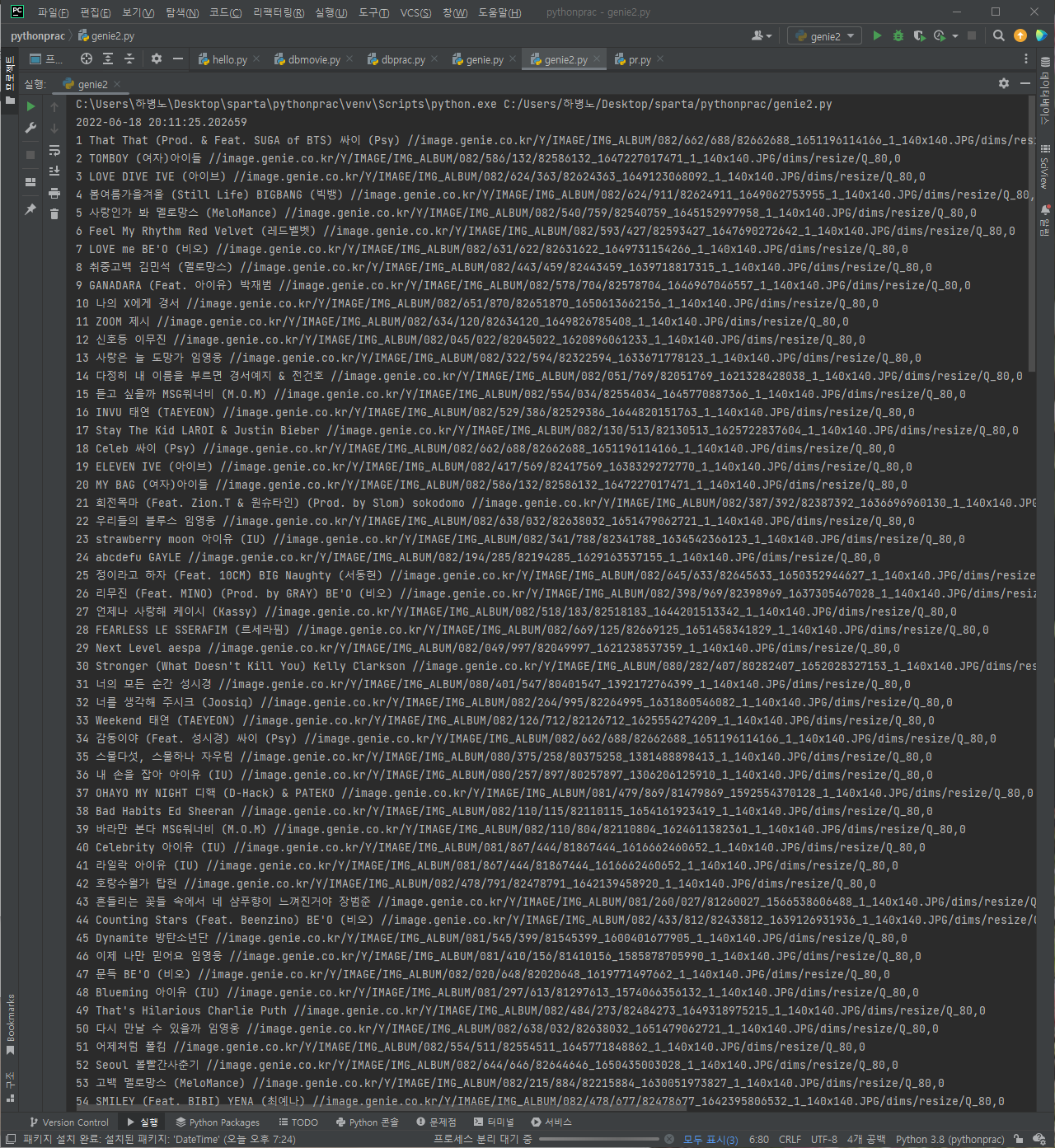
url 분석 https://www.genie.co.kr/chart/top200?ditc=M&ymd=날짜(yyyymmdd형식)1&hh=시간(24시형식)&rtm=N&pg=페이지번호# 필요한 라이브러리 import import requests from bs4 import BeautifulSoup # 크롤링을 위한 requests, BeautifulSoup 라이브러리 from datetime import datetime, timedelta #오늘 날짜를 가져오기 위한 datetime 라이브러리# 오늘 날짜와 시간 가져와서 url 리스트 만들기 today = str(datetime.today())[:10].replace('-','') # 작성 시간 기준 '20220619' hour = str(datetime.today().hour) # 작성 시간 기준 '20' # # # 어제 날짜를 구하고 싶다면 timedelta 활용 yesterday = datetime.today() - timedelta(1) # 2022-06-18 20:11:25.202659 # 지니뮤직은 오늘 날짜를 넣어 request 해도 알아서 어제 날짜로 바꿔 보여준다# url 리스트 만들기 url_list = [] for page in range(1,5): # print(page) page = str(page) url_list.append('https://www.genie.co.kr/chart/top200?ditc=M&ymd=' + today + '&hh=' + hour + '&rtm=N&pg=' + page)# 크롤링 코드 작성 for url in url_list: headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'} data = requests.get(url,headers=headers) soup = BeautifulSoup(data.text, 'html.parser') # # 순위 셀렉터 #body-content > div.newest-list > div > table > tbody > tr:nth-child(1) > td.number # 곡 이름 셀렉터 #body-content > div.newest-list > div > table > tbody > tr:nth-child(1) > td.info > a.title.ellipsis # 가수 셀렉터 #body-content > div.newest-list > div > table > tbody > tr:nth-child(1) > td.info > a.artist.ellipsis # 썸네일 셀렉터 #body-content > div.newest-list > div > table > tbody > tr:nth-child(1) > td:nth-child(3) > a # music_chart = soup.select('#body-content > div.newest-list > div > table > tbody > tr') for music in music_chart: rank = music.select_one('td.number').text[0:3].strip() title = music.select_one('td.info > a.title.ellipsis').text.replace('19금', '').strip() singer = music.select_one('td.info > a.artist.ellipsis').text thumbNail = music.select_one('td:nth-child(3) > a') for img in thumbNail: if img.has_attr('src'): thumbNail_url = img['src'] print(rank, title, singer, thumbNail_url)
완성 코드
import requests from bs4 import BeautifulSoup from datetime import datetime, timedelta today = str(datetime.today())[:10].replace('-','') hour = str(datetime.today().hour) yesterday = datetime.today() - timedelta(1) # print(today,hour,yesterday) url_list = [] for page in range(1,5): page = str(page) url_list.append('https://www.genie.co.kr/chart/top200?ditc=M&ymd=' + today + '&hh=' + hour + '&rtm=N&pg=' + page) for url in url_list: headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'} data = requests.get(url,headers=headers) soup = BeautifulSoup(data.text, 'html.parser') music_chart = soup.select('#body-content > div.newest-list > div > table > tbody > tr') for music in music_chart: rank = music.select_one('td.number').text[0:3].strip() title = music.select_one('td.info > a.title.ellipsis').text.replace('19금', '').strip() singer = music.select_one('td.info > a.artist.ellipsis').text thumbNail = music.select_one('td:nth-child(3) > a') for img in thumbNail: if img.has_attr('src'): thumbNail_url = img['src'] print(rank, title, singer, thumbNail_url)
- 결과물
프라고