SQL
SQL은 구조화 된 쿼리언어(Structured Query Language)로 관계형 데이터베이스(RDBMS)에서의 데이터 처리를 목적으로 만들어진 프로그래밍 언어를 의미한다.
SQL을 사용하는 관계형 데이터베이스는 두가지 특징을 가지고 있는데
첫번째는 정해진 구조에 따라 테이블에 데이터가 저장된다는 것이고,
두번째는 데이터는 기본키를 통해 여러 테이블과 연결되어 분산된다는 것이다.
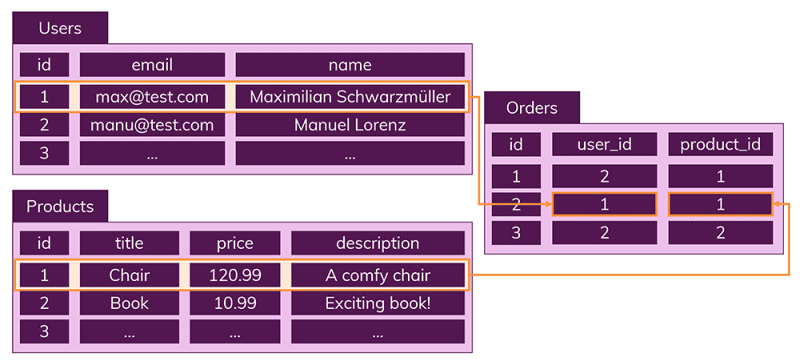 데이터는 테이블에 레코드 형식으로 저장되며, 각 테이블은 정해진 구조가 있기 때문에 해당 구조를 따르지 않으면 레코드를 추가할 수 없다. 또한 테이블 별로 데이터가 나눠져 저장되기 때문에 데이터들의 중복이 없고, 다른 테이블에서 부정확한 데이터를 다룰 위험이 없어진다.
데이터는 테이블에 레코드 형식으로 저장되며, 각 테이블은 정해진 구조가 있기 때문에 해당 구조를 따르지 않으면 레코드를 추가할 수 없다. 또한 테이블 별로 데이터가 나눠져 저장되기 때문에 데이터들의 중복이 없고, 다른 테이블에서 부정확한 데이터를 다룰 위험이 없어진다.
NoSQL
NoSQL은 관계형 데이터베이스 이외의 형식으로 데이터를 저장하는 데이터베이스를 의미한다. 따라서 NoSQL에는 스키마도 없고 관계도 없다.
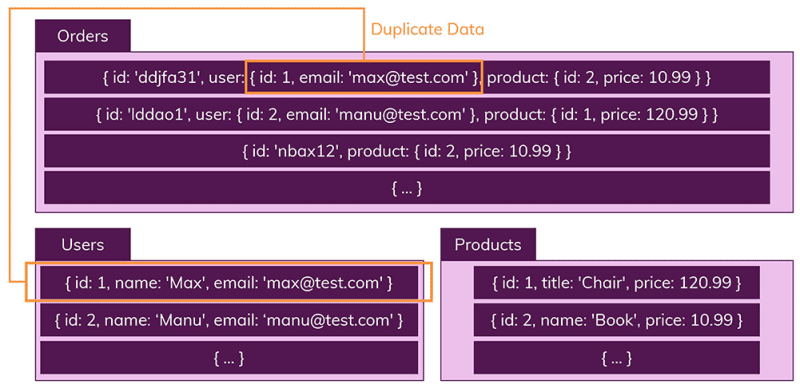 정해진 구조가 없기 때문에 관계형 데이터베이스와는 다르게 정해진 구조 없이 데이터를 저장할 수 있다.
정해진 구조가 없기 때문에 관계형 데이터베이스와는 다르게 정해진 구조 없이 데이터를 저장할 수 있다.
NoSQL에서는 레코드를 문서(documents)라고 말하는데 문서는 JSON과 비슷한 형태를 가지고 있기 때문에 구조를 신경 쓸 필요가 없고, 관계형 데이터베이스에서 각각의 테이블에 나눠서 저장했던 데이터를 하나의 테이블에 저장하기 때문에 join같은 연산이 필요하지 않게 된다.
SQL과 NoSQL의 장단점
SQL 장점
- 테이블의 구조가 명확하게 정의되어 데이터의 무결성을 보장한다.
- 관계에 따라 데이터가 분산되기 때문에 데이터의 중복이 없다.
SQL 단점
- 테이블의 구조가 정해져있기 때문에 나중에 구조 수정이 번거롭거나 불가능하다.
- 데이터가 분산되어있기 때문에 조회 테이블에 따라 많은 join을 요구하게되고, 이는 성능 저하로 이어질 수 있다.
- RDBMS의 경우 수직 확장(Scale-up)만이 가능하며 수직 확장은 성능 확장의 한계가 있고, 성능 증가에 대한 비용이 크다.
NoSQL 장점
- 정해진 테이블 구조가 없기 때문에 유연하고, 데이터 형식이 변경되어도 데이터를 저장하는데 문제가 없다.
- 데이터를 원하는 형식으로 저장하기 때문에 join을 사용하지 않고, 데이터를 조회하는 속도가 향상된다.
- 수평 확장(Scale-out)이 가능하며 확장의 한계가 없고, 가격이 비교적 저렴하며, 읽기/쓰기가 여러대의 서버에 분산 처리되기 때문에 부하가 줄어든다.
NoSQL 단점
- 데이터가 중복되어 저장되기 때문에 데이터를 업데이트하게 되면 모든 컬렉션에서 데이터를 수정해야한다.
- 데이터 구조가 정해져 있지 않기 때문에 데이터의 일관성이 없다.
SQL과 NoSQL 선택
SQL과 NoSQL 모두 각각의 다른 특징을 가지고 있기 때문에 어떠한 구조가 좋다고는 말할 수 없지만
- 데이터의 구조가 변경되지 않으며, 명확한 구조를 가지고 있어야하는 경우와 데이터가 자주 변경되는 경우에는 SQL 사용이 효율적이며
- 정확한 데이터 구조가 정해져 있지 않거나, 데이터를 읽기만 할 뿐 변경하지 않는 경우, 방대한 양의 데이터를 다뤄야 하는 경우에는 NoSQL 사용이 효율적이다.
NoSQL의 종류
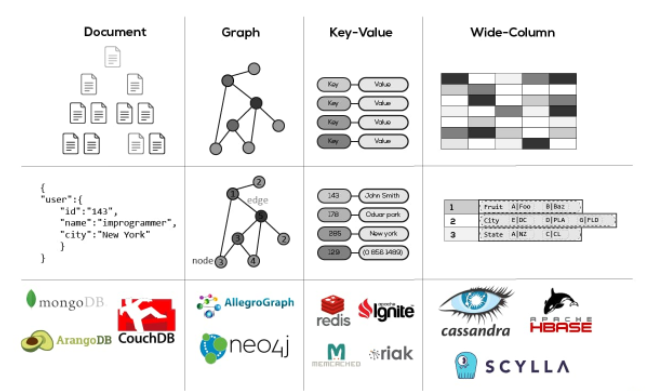
Key-Value Database
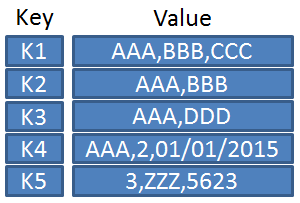
- 유니크한 key와 key에 연결되는 value를 가지고 있다.
- 구조가 단순하기 때문에 저장이나 단순 조회의 경우 빠른 속도이지만 value값의 검색이 어렵다.
- 사용 예시
- 세션스토어 : 세션 데이터는 기본키 외 다른 키가 필요하지 않으므로 속도가 빠른 key-value가 적합하다. 일반적으로 관계형 데이터베이스보다 페이지당 제공하는 오버헤드가 적다
- 장바구니 : 키-값 데이터베이스는 분산 처리 및 저장을 통해 한꺼번에 수백만 명의 사용자에게 서비스를 제공하는 동시에 대량의 데이터 처리와 매우 많은 양의 상태 변경 작업을 처리가 가능. 또한, 키-값 데이터베이스에는 내장형 중복 기능이 있어서 스토리지 노드의 손실을 방지할 수 있다.
- 캐싱,채팅,메시징 및 대기열, 랭킹, 세션 스토어, 미디이 스트리밍 등 주로 실시간 처리가 필요하며 대용량의 데이터를 처리하는데 사용
- Redis, Amazon DynamoDB
Document Database
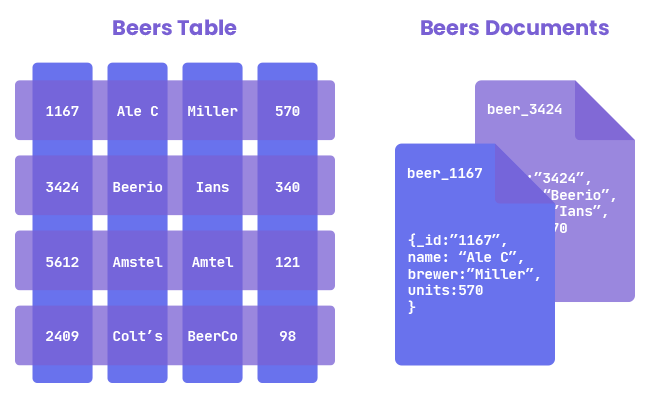
- key-value와 비슷하지만 value에 저장되는 데이터가 XML이나 JSON 형식의 데이터가 저장된다.
- 계층적 트리 데이터를 가지고 있다.
- 여러개의 테이블을 하나의 Document내에 모아둘 수 있기 때문에 한번의 조회로 필요한 데이터를 획득할 수 있다.
- MongoDB, CouchBase
- 사례
Graph Database
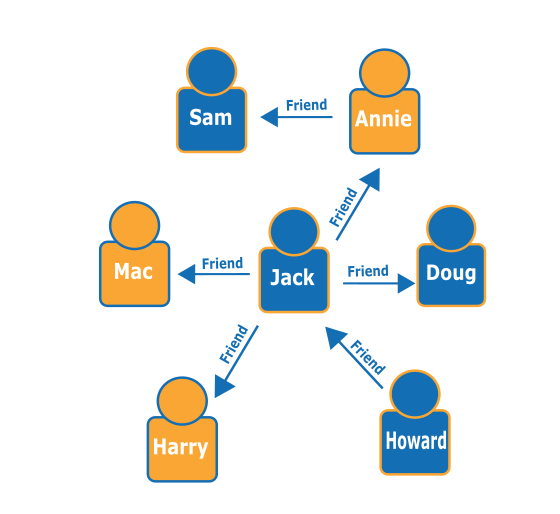
- 객체를 표현하는 노드와 객체 간의 관계를 표시하는 엣지로 구성되어있다.
- 서로 연결된 데이터는 빠르게 찾을 수 있다.
- 사용 예시
- 소셜 네트워킹 : 서로 연관 되어있는 사람들간의 데이터를 가져오고 알릴 수 있다.
- 운전경로 : 현재 트래픽과 일반적인 트래픽 패턴을 고려하여 시작점에서 목적지까지의 최적의 경로를 빠르게 찾을 수 있다.
- Neo4j, OrientDB
Wide-Columm Database
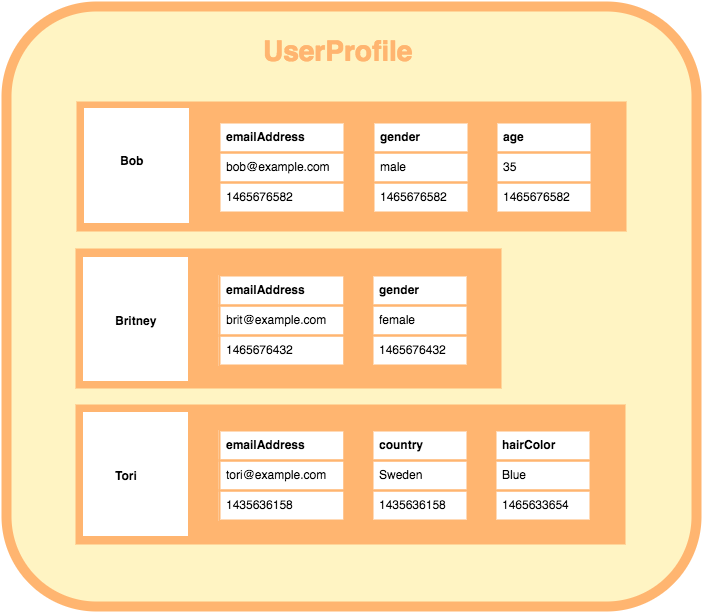
- 행을 저장할때마다 각각 다른값의 스키마를 가질 수 있다.
- 대량의 데이터 압축, 분산처리, 집계 처리등의 속도가 뛰어나다.
- Cassandra, Google Cloud Bigtable

으쌰으쌰🐜🐜