인덱스는 데이터베이스 테이블에 대한 검색 성능을 높혀주는 도구이다. 이런 인덱스를 구현하는 알고리즘에는 여러가지가 있는데, 각 상황에 맞게 사용된다.
먼저 인덱스가 무엇인지 알아보고, 어떤 기준으로 상황에 맞는 알고리즘을 고르면 될지 알아보도록 하자
그리고, 이 글은 꽤나 길기때문에 원하는 정보가 있다면 우측의 인덱스를 잘 활용하길 바란다 👉
🤔 인덱스란?
인덱스는 메모리 영역에 존재하며, 지정된 컬럼을 기준으로 생성된 목차를 의미한다. 아래 그림을 예시로 들어보자.
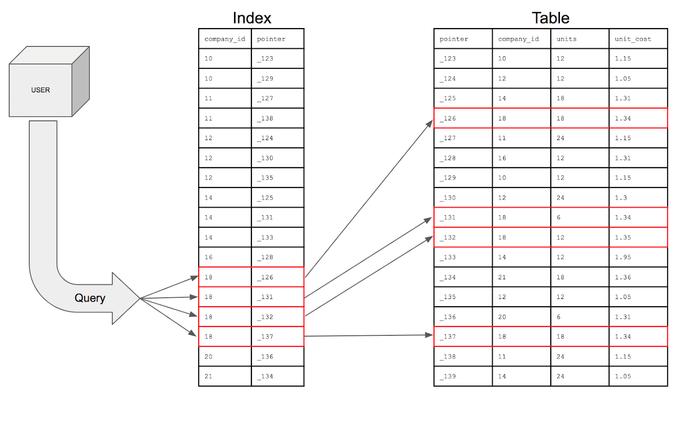
위 인덱스는 지정된 컬럼(company_id)을 기준으로 정렬되어 있고, pointer가 테이블의 row를 가리키고 있다.
만약 인덱스를 거치지 않고 company_id가 18인 값을 찾으러면 테이블은 company_id 로 정렬되어 있지 않기 때문에 모든 row를 탐색해야 할 것이다 (full scan)
이런 인덱스를 정렬하는 알고리즘은 B-tree, Hash, 비트맵 등 여러가지가 있는데, 알고리즘 마다 쓰이는 상황이 다르다. 자세히 알아보자!
B-tree
B-tree 알고리즘은 인덱스에서 가장 일반적으로 사용되는 알고리즘이다.
B tree의 구조는 아래와 같은데,
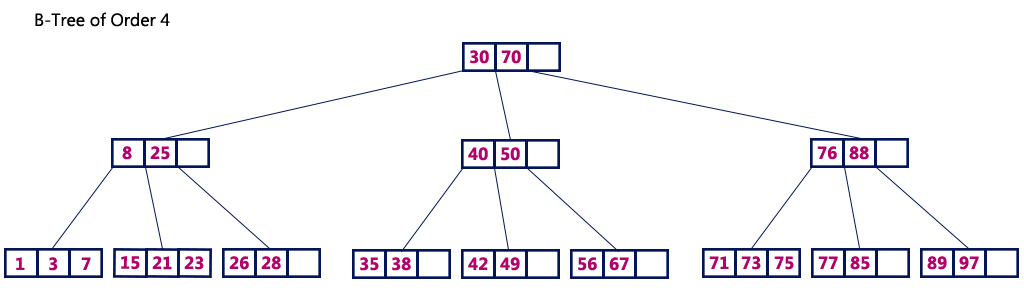
이 구조의 특징은
- 하나의 노드가 여러개의 데이터를 가질 수 있으며
- 하위 노드의 최대 갯수는
상위 노드 데이터 수 + 1로 결정된다는 점이 있다.
이런 구조 덕분에 검색 속도의 균일성(logN)을 보장할 수 있는데, 그 이유는 다음과 같다.
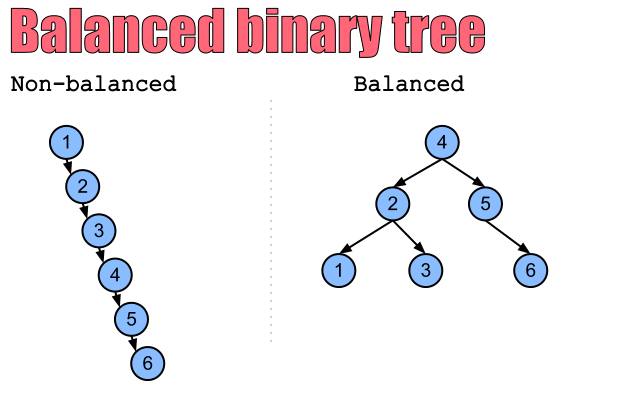
트리가 만약 왼쪽과 같이 비균형상태라고 쳐보자,
그럼 6이라는 값을 찾기 위해서는 몇개의 노드를 탐색해야 할까? 루트 노드부터 순서대로 6번 탐색해야 할 것이다.
하지만 트리 구조가 오른쪽과 같이 균형이 잡혀있다면 최대 3번의 탐색 안에 무엇이든 원하는 값을 가지게 될 수 있을 것이다.
이런 B-tree 인덱스는 보통 데이터의 값의 종류가 많고 동일한 데이터가 적은 컬럼에 사용된다.
주의할 점은 OR 오퍼레이터를 사용하는 쿼리문에 비효율적이다. 이를 해결하기 위해 보통 IN 오퍼레이터를 사용한 쿼리문으로 튜닝하곤 한다.
Hash
Hash 인덱스는 범용적으로 쓰이는 인덱스는 아니지만 동등 비교 검색(=)에서 빠른 속도를 보여주는 인덱스이다.
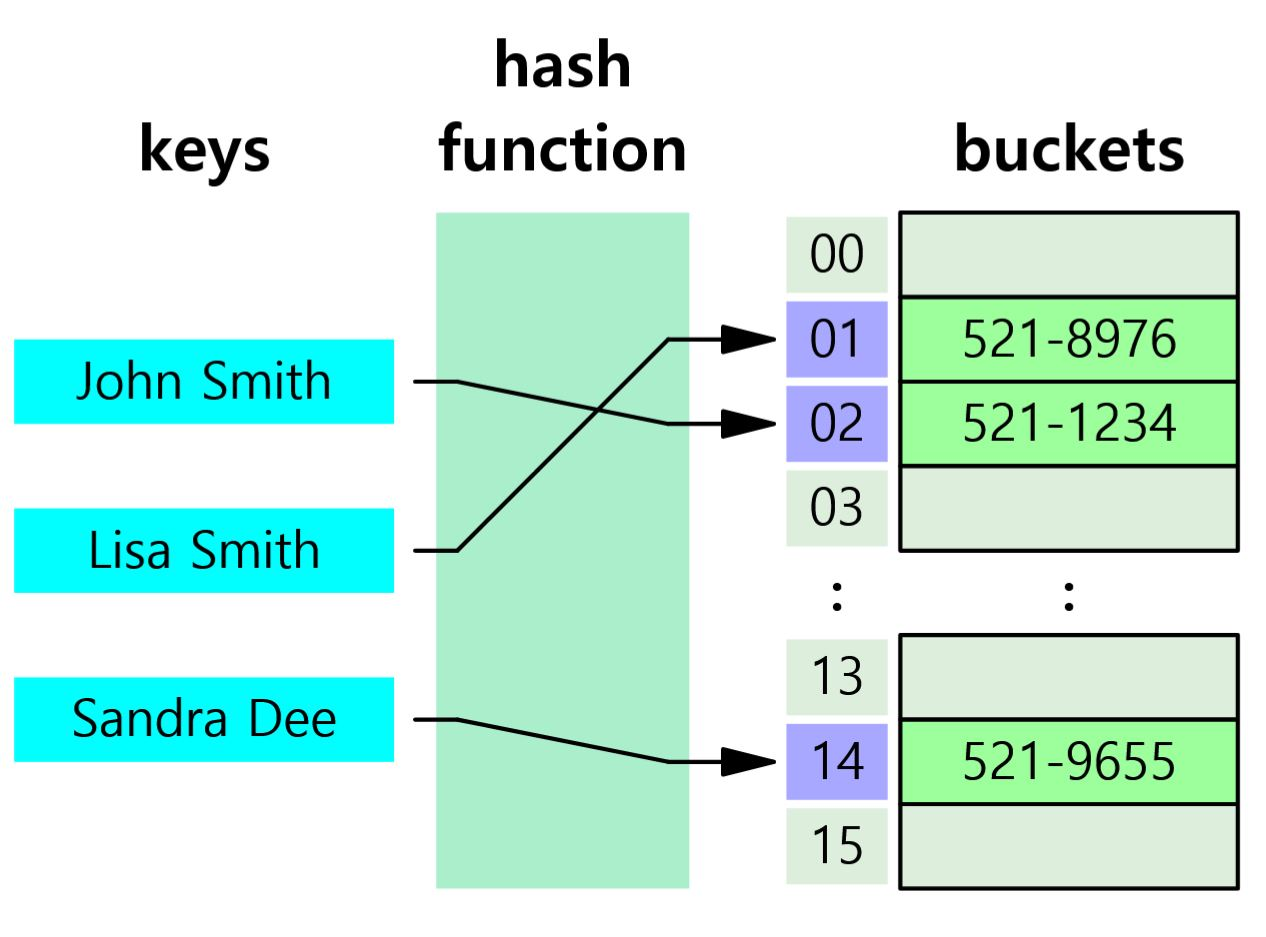
동작 방식은 아래와 같다
- 지정된 컬럼의 검색하고자 하는 값을 hash function에 입력
- hash function 출력값으로 해시값을 bucket에서 찾아 데이터 레코드 주소를 알아냄
- 알아낸 데이터 레코드 주소로 원하는 데이터 레코드에 접근
해시맵을 사용하기 때문에 (hash collision이 없는 경우) 시간 복잡도가 1이라는 장점이 있다.
시간 복잡도가 1이라면 Hash 인덱스가 최고 아닌가? 라는 의문이 들 수도 있다. 물론 동등 비교 검색에서는 빠른 성능을 보여주지만, 범위 검색(>, between) 에서는 N의 시간 복잡도를 가지게 때문에 특수한 상황에서만 쓰이는 것이다.
이런 Hash 인덱스는 아래의 상황에서 쓰인다.
- 데이터 값의 종류가 많음 (hash collision 방지)
- InnoDB Adaptive Hash Index(자주 사용되는 값만 해싱하여 버킷에 저장)
비트맵
비트맵 인덱스는 기존 B-Tree가 가지고 있던 단점을 보완하기 위해 등장한 인덱스다.
B-Tree는 아래와 같은 단점을 가지고 있었다.
- 실제 칼럼 값을 인덱스에 저장하고 있다보니 저장 공간 낭비가 심하다
- NOT 이나 NULL을 사용하거나 복잡한 OR 조건에서 성능이 떨어짐
이런 단점을 비트맵 인덱스는 아래와 같이 해결했다.
- 칼럼 값을 인덱스에 저장하는 것이 아닌 컴퓨터의 가장 작은 단위인 비트로 값을 저장해 저장 공간 절약
- bitwise(|, &, ^) 연산으로 복잡한 OR 연산이 빠름
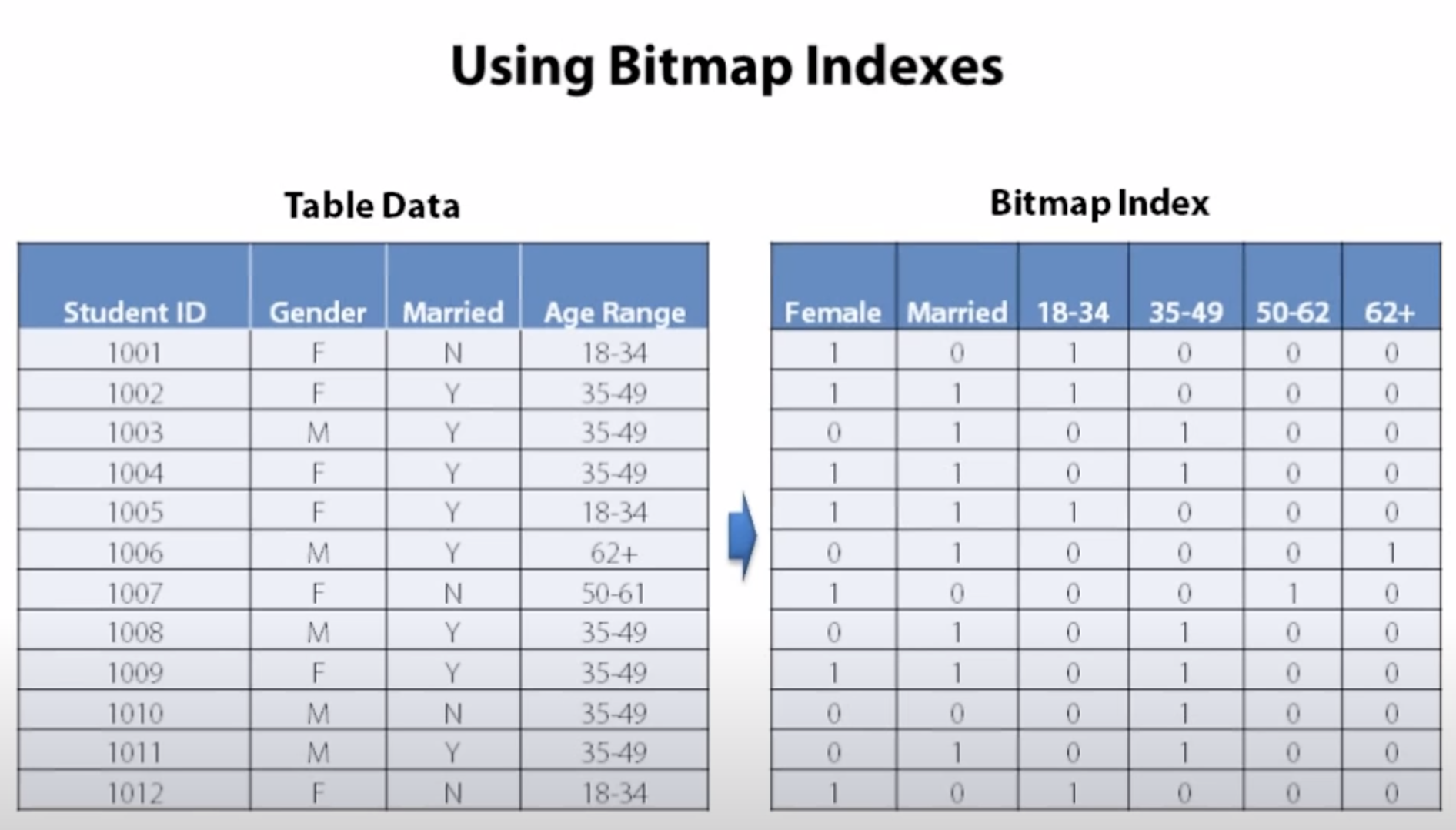
비트맵 탐색을 예시를 들어보자면 아래 조건에 만족하는 row를 찾고 싶다고 가정해보자
- 여성
- 미혼
- 18 - 34세
위 조건과 같을 때 비트맵 값이 101000인 컬럼을 찾으면 되는 것이다.
이런 비트맵 인덱스는 아래의 상황에서 쓰인다.
- 데이터 값의 종류가 적음(성별, Enum)
- 쿼리가 OR 연산자를 포함하는 여러개의 WHERE 조건을 가질 때
하지만 비트맵 인덱스는 레코드 하나만 변경되더라도 모든 레코드에 lock이 걸린다는 점 때문에 다른 인덱스 알고리즘에 비해 데이터 갱신비용이 크다는 단점이 있다.
또한, 하나의 비트맵 인덱스만으로는 별로 효과가 없고, 여러 비트맵 인덱스를 동시에 사용할 때 성능 향상에 도움을 준다.
full text search
클러스터링
Ref.
https://jojoldu.tistory.com/243
http://www.gurubee.net/lecture/1109
