사용 모델 - LSTM, 패키지 - MediaPipe
순환 신경망(Recurrent Neural Network)모델
- 오디오, 비디오 또는 텍스트와 같은 시계열 데이터를 학습 및 처리하기 위해 만들어진 모델
LSTM
- 장단기 기억 모델로, 순환 신경망 모델의 장기 의존성을 개선한 모델
- 수어를 번역하는 애플리케이션 연구에서 사용됨.
- 본 논문에서는 LSTM을 활용하여 시계열 데이터인 비디오로부터 동적 데이터인 수어 동작을 인식하는 방법을 제안함.
cf) UNet-LSTM
- 음성에서 수어 번역 모델
미디어파이프(MediaPipe)
- 파이프라인 구축을 통해 비디오 및 오디오와 같은 인지 데이터를 처리 오픈 소스 플랫폼 프레임워크
- Google에서 개발한 MediaPipe는 멀티모달(예: 비디오, 오디오, 시각적) 데이터를 처리하기 위한 프레임워크
- 손가락 추적, 얼굴 랜드마크 탐지, 포즈 추정 등과 같은 특정 컴퓨터 비전 작업을 위한 사전 구축된 솔루션을 제공
cf) OpenCV와 차이점 - penCV는 기본적인 이미지 처리부터 고급 비전 알고리즘에 이르기까지 광범위한 기능을 제공하는 범용 라이브러리입니다. 반면, MediaPipe는 특정 고급 비전 작업(예: 손가락 추적, 포즈 추정)을 위한 고성능 솔루션을 제공하는 것에 더 특화되어 있음.
- MediaPipe는 사전 구축된 솔루션을 제공하여 사용자가 쉽게 복잡한 비전 작업을 수행할 수 있게 해주는 반면, OpenCV는 사용자가 보다 많은 사용자 정의와 구현을 요구할 수 있음.
출처: https://kwakscoding.tistory.com/43
분석 과정
활용 데이터 : 105개 문장 및 419개 단어, 한국 수어 동영상 및 각 프레임의 3D 관절 좌표 포함데이터를 미디어 파이프를 통해 동영상 관련 관절 좌표 추출
영상 데이터 1 초당 10개의 프레임 추출
|
v
[3D 아바타를 통한 수어 표현]
Maya 프로그램을 사용한 관절 좌표 추출
( 각 프레임에 대한 48개의 관절 좌표 추출 (약 50개 프레임)
|
v
LSTM을 활용한 학습 (활성화 함수는 softmax, 완전연결층의 출력 개수 10)
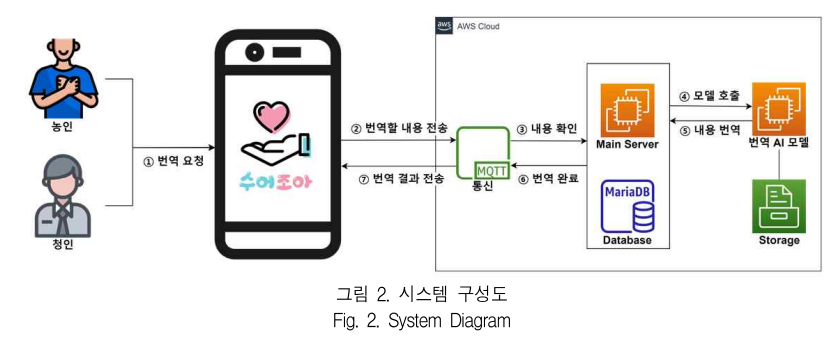
[1] 이재현, 박지수, 성민기, 정세연, 유철중. “딥러닝 기반 양방향 수어 번역 시스템,” 2023 한국정보기술학회 하계 종합학술대회 논문집, pp.801-805, 2023.
사용 모델 - YOLOv5, 패키지 - MediaPipe
YOLOv5
- Backbone 으로는 CSPNet 기반의 CSP-Darknet을 사용하여 이미지에서 특성 맵을 추출하고, head 에서는 추출된 특성 맵을 바탕으로 객체의 위치를 찾음.
3D CNN+LSTM
[2] 김윤기, 지영채, 하정우. "청각장애인을 위한 UNet-LSTM 기반의 자동 음성-수어 번역 모델", 2019 한국정보과학회 2019 한국컴퓨터종합학술대회 논문집, pp709 - 711, 2019
