PANDAS
Chapter 08. 데이터 사전처리
PANDAS 데이터 사전처리
데이터표준화
- 자료형 변환
- 기본 자료형
↑ ↓
- 데이터 자료형 => 범주형, 연속형
- 함수
객체.astype(‘자료형’) => 자료형으로 변환
객체.dtypes( => 자료형 확인
범주형 데이터 처리
- 구간 분할(Binning)
연속형 데이터를 일정 구간으로 나누어 범주형 데이터로 변환pandas.cut((x=df[컬럼명], # 데이터배열
right=True, # 오른쪽 같 포함
bins=n, # 경계값리스트
labels=bin_names, # bin 이름
include_lowest=True) # 첫경계값포함
)
A < ~ <= B
- 더미변수(Dummy Variable)
- 컴퓨터가인식가능한입력값0, 1로변환특징(Feature)이 있으면 1, 없으면 0 → One-Hot-Encoding
pandas.get_dummies( 구간분할 데이터 )
-
정규화(Normalization)란?
• 각열에 속하는 숫자 데이터의 상대적 크기 차이 해결
• 동일한 크기 기준으로 나눈 비율로 나타내는 것
• 데이터범위: 0 ~ 1 또는 -1 ~ 1 -
방법
• 열의 최대값의 절대값으로 데이터 나누기
• 열의 최대값 - 최소값 결과값으로 데이터 나누기
Chapter 09. 데이터 응용
PANDAS 데이터 응용
함수 매핑
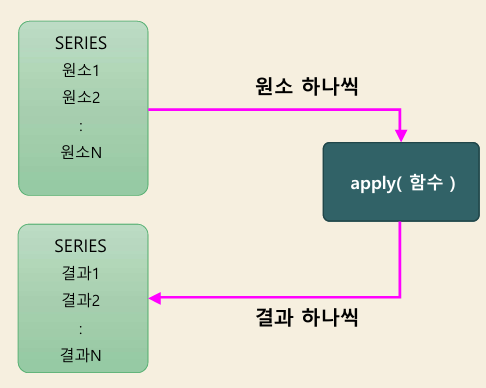
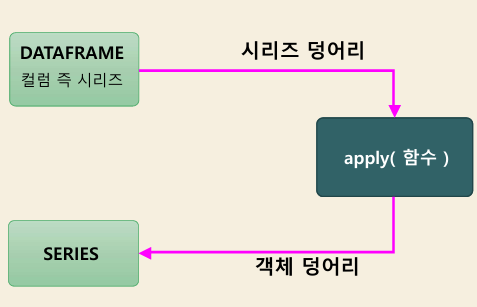
object.apply( 함수명,
args=( ), # 객체 이외에 함수에 전달되는 인자
**kwargs, # 객체 이외에 함수에 전달되는 가변인자
axix=0, # 0 or ‘index’: apply function to each column.
# 1 or ‘columns’: apply function to each row.
result_type= # expand - 열에 리스트와 유사한 결과반환
# reduce - 시리즈 반환,
# broadcast - 데이터프레임
)
반환: 단일값, 시리즈, 데이터프레임
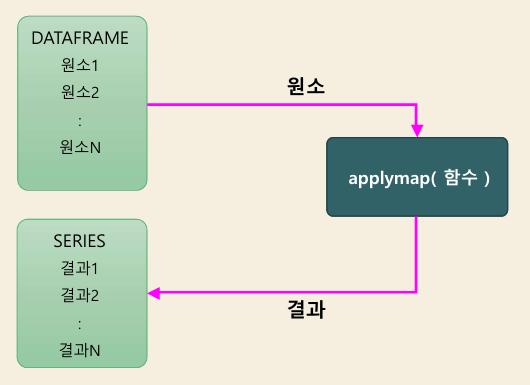
object.applymap( func,
na_action,
# NaN 데이터 처리
**kwargs, # 객체 이외에 함수에 전달되는 가변인자
)반환: DataFrame
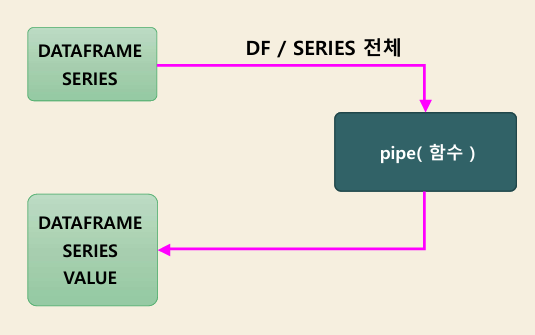
object.pipe( func,
args=( ), # 객체 이외에 함수에 전달되는 인자
**kwargs, # 객체 이외에 함수에 전달되는 가변인자
axis=0
)
반환: 단일값, 시리즈, 데이터프레임
열재구성-열순서변경
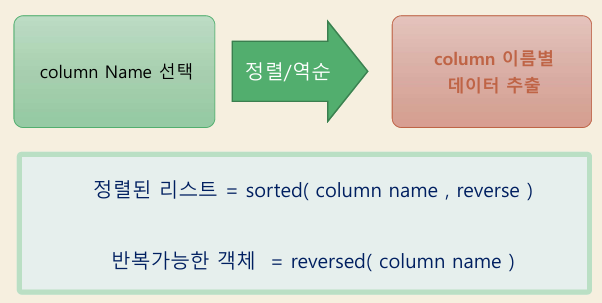
열재구성-열분리

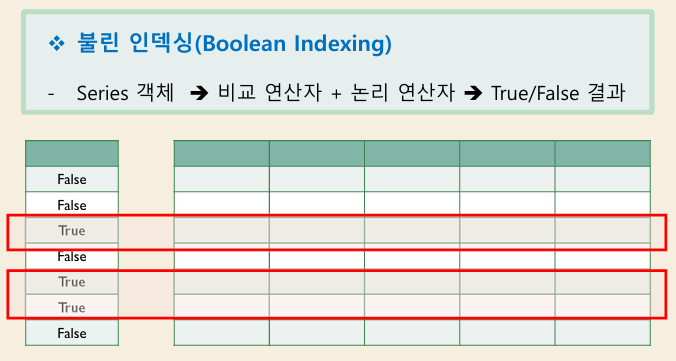
필터링(Filtering)