SQLD 자격증 공부하면서 정리한 내용들을 작성한 글입니다.
6. 분산 데이터베이스와 성능
(1) 분산 데이터베이스란?
- 여러 곳으로 분산되어있는 데이터베이스(DB)를 하나의 가상 시스템으로 사용할 수 있도록 한 데이터베이스(DB)
- 논리적으로 동일한 시스템에 속하지만, 컴퓨터 네트워크를 통해 물리적으로는 분리되어 있는 데이터 집합
(2) 분산 데이터베이스를 만족하기 위한 투명성 6가지
-
분할 투명성(단편화)
- 하나의 논리적 Relation이 여러 단편으로 분할되어 각 사본이 여러 site에 저장
-
위치 투명성
- 사용하려는 데이터의 저장 장소 명시 불필요
- 위치정보가 시스템 카탈로그에 유지
-
지역사상 투명성
- 지역 DBMS와 물리적 DB 사이의 Mapping 보장
- 각 지역 이름과 무관한 이름 사용
-
중복 투명성
- DB 객체가 여러 site에 중복되어 있는지 알 필요가 없는 성질
-
장애 투명성
- 구성요소의 장애에 무관한 트랜잭션의 원자성 유지
-
병행 투명성
- 다수 트랜잭션 동시 수행시 결과의 일관성 유지
- TimeStamp
- 분산 2단계 Locking 이용
(3) 분산 데이터베이스 장/단점
-
장점
- 지역 자치성, 신뢰성, 가용성, 효용성, 융통성, 빠른 응답속도, 비용절감, 각 지역 사용자 요구 수용
-
단점
- 비용증가, 오류의 잠재성 증대, 설계 관리의 복잡성, 불규칙한 응답 속도, 통제의 어려움, 데이터 무결성 위협
(4) 분산 데이터베이스 적용 기법
- 테이블 위치 분산
- 테이블 구조는 변경되지 X
- 테이블이 다른 DB에 중복으로 생성되지 X
- 정보를 이용하는 형태가 각 위치별로 차이가 있을 경우에만 사용
(위치 : 서버 컴퓨터) - 테이블의 위치를 파악할 수 있는 도식화된 위치별 DB 문서가 필요함
- 테이블 분할 분산
-
수평 분할
- 로우(행) 단위로 분리/열이나 칼럼은 분리X
- 지사별로 다를 때 / 자사의 데이터만 수정 가능
→ 데이터가 지사별 별도로 존재하기 때문에 중복 발생 X
→ 데이터 무결성 보장
-
수직 분할
- 칼럼 단위로 분리
- 각 테이블에 동일한 PK가 있어야 함
- 데이터 중복 발생 X
- 테이블 복제 분산
- 동일한 테이블을 다른 지역이나 서버에서 동시에 생성하여 관리하는 유형
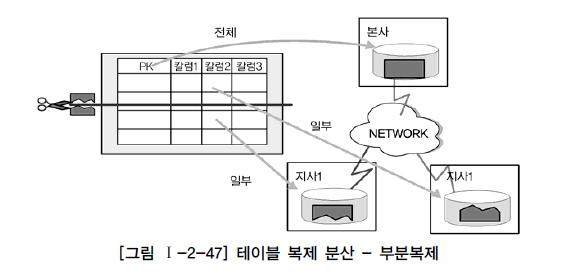
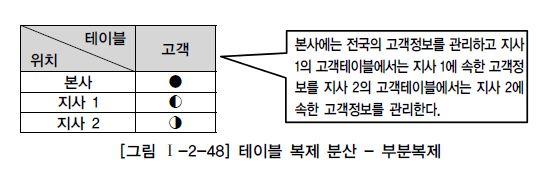
- 부분 복제
- 마스터 DB에서 테이블의 일부의 내용만 다른 지역이나 서버에 위치시킴
- 통합된 테이블은 본사에 저장, 지사별로 각 지사에 해당하는 로우(행)를 가지는 형태
- 지사에서 데이터 선 발행 후 본사는 지사 데이터 통합(↔ 광역 복제)
- 다른 지역간 데이터 복제는 실시간 처리보다 배치 처리를 이용
- 데이터의 정합성 일치 어려움
- 본사의 데이터를 이용하여 통계, 이동 등을 관리하며 지사에 있는 데이터를 이용하여 지사별로 빠른 업무수행을 한다.
(출처)https://dataonair.or.kr/db-tech-reference/d-guide/sql/?pageid=4&mod=document&uid=336
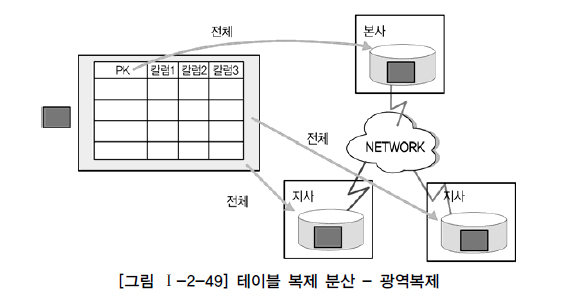
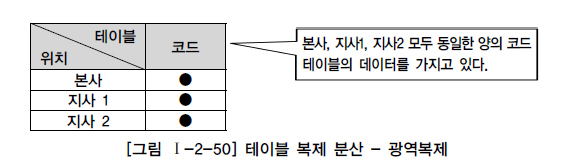
- 광역 복제
- 통합된 테이블은 본사에 저장하고, 각 지사에 동일한 데이터를 저장
- 본사에서 데이터 입력,수정,삭제하고 이것을 지사에서 이용(↔ 부분 복제)
- 복제하는데 많은 시간이 소요되고 데이터베이스와 서버에 부하가 발생하므로 실시간 처리보다는 배치 처리를 이용한다.
(출처)https://dataonair.or.kr/db-tech-reference/d-guide/sql/?pageid=4&mod=document&uid=336
- 테이블 요약 분산
(5) 분산 DB 설계를 고려해야 하는 경우
- 성능이 중요한 사이트
- 공통코드, 기준정보, 마스터 데이터의 성능 향상
- 실시간 동기화가 요구되지 않는 경우, Near Real Time(거의 실시간)
- 특정 서버에 부하가 집중되어 부하를 분산
- 백업 사이트를 구성하는 경우

안녕하세요, 웹 개발자 이하영입니다!