Graph Neural Network
1.Node2Vec 모델 응용 : GraphSAGE 성능 향상
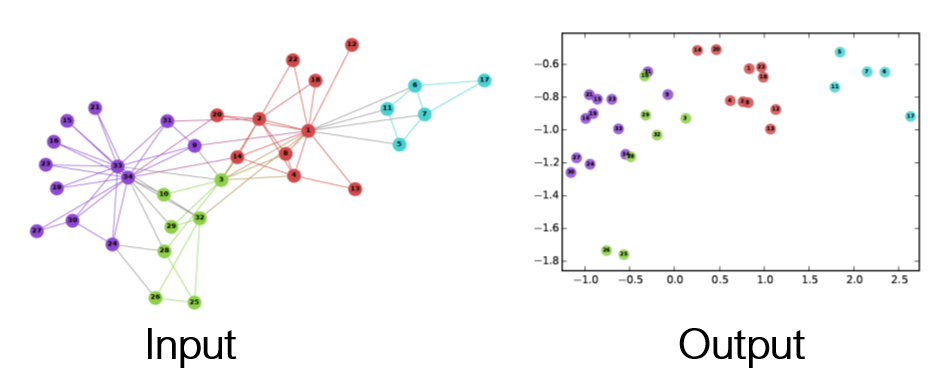
본 포스팅에서는 GraphNN 모델을 연계해 성능을 향상시키는 방법에 대해 다룬다.정확히는 Node2Vec 모델과 GraphSAGE 모델을 함께 사용해 Graph 정보를 모델에 더욱 효과적으로 전달하는 방법론을 이론적으로 설명한다.node2vec과 GraphSAGE 모
2.GNN과 문자형 변수 처리

표제어 추출이 완료된 'Book-Title' column을 벡터로 만드는 두 가지 방법이 있다.Label Encoder+Embeddign Layer : 하지만 각 책 제목을 하나의 벡터로 표현하기 때문에, 책 제목 내의 개별 단어들 사이의 관계를 고려하지 못할 수 있다
3.Graph Data와 교차 검증

Graph Data로도 교차 검증(Cross validation)이 가능하다. 다시 말해, 일반적인 ML 학습처럼 train-test 분할이 가능하다는 것이다. 여기엔 두 가지 방법이 있다.그래프의 일부 엣지를 테스트용으로 제거하고, 나머지 엣지를 사용해 모델을 학습한
4.Graph data Split : 그래프 데이터 분할

Graph Data를 train-test 셋으로 나누는 가장 일반적인 방법은 노드 기반 분할(Node-based splitting)과 엣지 기반 분할(Edge-based splitting)이다.또한 Task마다 Graph 분할 방법은 그래프의 구조와 모델의 목적에 따라
5.GNN 성능 향상 : Batch Normalization
배치 정규화(Batch Normalization)은 모델의 학습 속도와 정확도를 향상시키기 위해 각 GraphSAGE 레이어 이후에 적용하는 정규화 기법이다.배치 정규화(Batch Normalization)는 딥러닝 모델의 학습 과정에서 가중치의 변화에 따른 활성화 출
6.Custom GNN Layer (GraphSAGE)
기본 GraphSAGE 모델은 노드 정보와 연결 관계를 기반으로 노드 임베딩을 학습하도록 설계되어 있습니다. 이는 많은 그래프 구조의 문제에 적합한 접근 방식이지만, 엣지 정보를 직접 활용하고 싶은 경우 기본 GraphSAGE 모델만으로는 부족할 수 있습니다.SAGEC
7.Graph Data의 Batch 학습 (DataLoader, Custom DataLoader)

그래프 데이터도 배치 단위로 모델에 넣을 수 있다. DataLoader() 메서드를 사용하면 된다. 다시 말해, Graph Data를 모델에 넣기 위해서는 먼저 DataLoader를 설정하고, 그 다음 학습 과정을 구현해야 한다.DataLoader() 메서드는 기본 P
8.GNN과 NeighborSampler

만약 회귀 예측을 목표로 하고 있다면, 전체 그래프에서 지역적인 이웃 정보를 사용하여 추론하는 작업이 필요하다. 그럴 때는 Data로 그래프를 구성한 뒤, DataLoader를 바로 사용해서는 원하는 결과를 얻을 수 없다. 아마도 수많은 인덱스 에러를 마주칠 것이다.
9.GNNs과 추천시스템
노드 분류, 엣지 예측, 그래프 분류가 추천 시스템의 영역에서는 각각 어떻게 활용될 수 있는지,프로젝트 설계에 기본 뼈대가 될 만한 내용을 정리해둔다.사용자의 선호도나 사용자 그룹을 분류하는 데 사용될 수 있다. 예를 들어, 각 사용자 노드가 '고객 세분화(Custom
10.GNN과 범주형 변수 처리
Category Embedding 방식을 통해, 지정한 임의 차원의 벡터로 변환할 수 있다. Embedding Layer을 사용해야 한다. 물론 One-Hot Encoding 방식을 쓸 수도 있지만, 여기서는 벡터 임베딩 방식을 다룬다. Label Encoder를 통해