[Paper Review] Wide & Deep Learning for Recommender Systems
Chen et al., 2016 Wide & deep learning for recommender systems. CoRR, abs/1606.07792, 2016.
1. Introduction
추천시스템의 주요 과제 중 하나는 memorization과 generalization 측면에서 동시에 좋은 성능을 내는 것이다. 여기서 memorization이란, 자주 함께 등장하는 아이템 쌍 혹은 feature 조합을 학습하는 것을 말한다. 그리고 generalization이란 상관관계의 transitivity에 기반하여 과거에 나타나지 않았던 새로운 feature 조합을 찾아내는 것을 말한다.
memorization에 기반한 추천은 주로 topical한 정보나 유저가 이미 취했던 action에 기반하여 item 랭킹을 매긴다. 반면 generalization에 기반한 추천은 추천된 아이템의 다양성을 높이는데 목적이 있다.
규모가 큰 온라인 추천시스템에서는 주로 로지스틱 회귀와 같은 generalized linear model이 쓰인다. 간단하고, 확장성이 있고, 해석 가능하기 때문이다. 이때 모델은 sparse feature 벡터 간의 cross-product로 feature interaction을 학습한다. 함께 등장하는 feature 쌍을 target label과 연관지어 memorization 성능을 높이는 것이다. 그러나 이러한 경우 training data에 없는 feature 조합에 대해서는 일반화시킬 수 없다는 한계가 존재한다.
반대로 factorization machine이나 DNN과 같은 embedding-based 모델은 관찰되지 않은 feature 조합에 대해서도 generalization 성능이 높다. 하지만 sparse, high-rank한 유저-아이템 matrix에서는 효과적으로 low-dimensional representation을 학습하기 어렵다. 결국 over-generalize 현상과 함께 전혀 관계없는 아이템 추천으로 이어질 수도 있다.
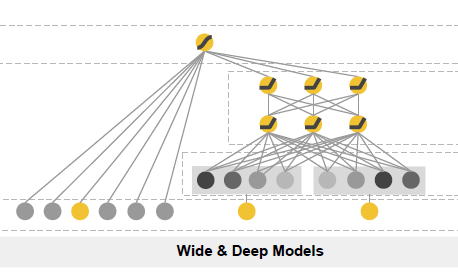
저자는 위 딜레마를 해결하기 위해 wide & deep learning framework를 제안한다. 아래 그림과 같이 linear model component와 neural network component를 공동으로 학습시켜 memorization과 generalization 측면에서 모두 좋은 성능을 내고자 했다.
2. Recommender System Overview
논문에서는 학습을 위한 데이터로 구글 플레이스토어의 앱 추천 task를 다루었다. 앱 추천 시스템의 flow는 다음과 같다.
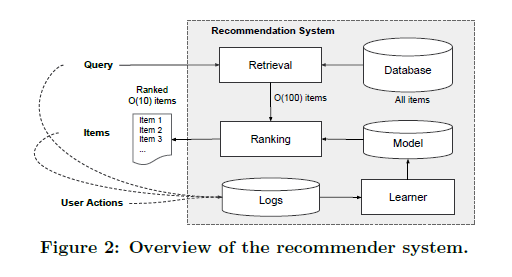
유저가 플레이스토어에 진입하면 유저와 아이템에 대한 feature 데이터가 생성된다. 이때 추천시스템은 ranking된 앱 리스트를 반환하고 유저는 클릭, 설치와 같은 action을 수행한다. 그리고 이런 action 기록들은 training data가 된다.
다만 데이터베이스에 수백만 개의 앱이 존재하기 때문에, 짧은 시간 내에 모든 앱에 대해 순위를 매기는 것이 불가능하다. 따라서 유저가 특정 단어를 검색했을 때 해당 검색어와 관련된 앱 후보군을 먼저 rule-based 방식으로 추출한다. 그리고 이렇게 추출된 후보군들에 대해서만 추천 알고리즘을 이용해 score를 매긴다. score는 보통 를 사용하는데, 이는 feature 벡터 하에서 유저의 action이 일어날 확률을 의미한다.
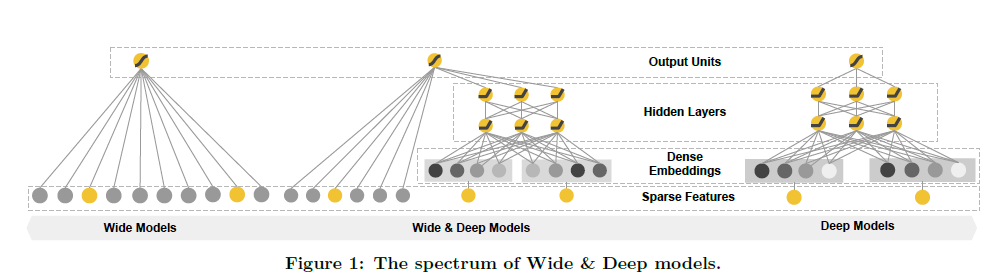
3. Wide & Deep Learning
3.1 The Wide Component
wide & deep model에서 wide component는 generalized linear model로, 형태이다. 이때 는 예측값, 는 개의 feature로 이루어진 vector, 는 모델 파라미터이고 는 bias를 의미한다.
feature set은 가공되지 않은 raw input feature와 transformed feature로 나뉜다. transformed feature를 만들어내기 위해 cross-product를 사용하는데, 다음과 같은 식으로 표현된다.
는 이진 변수로 번째 feature가 번째 transformation 에 포함되면 1, 아니면 0이다. cross-product transformation은 모든 binary feature가 1일 때에만 1을 도출하고, 하나라도 0이 포함되어 있으면 0을 도출한다. 즉, cross-product를 통해 binary feature 간의 interaction을 잡아낼 수 있고, 이는 generalized linear model에 nonlinearity를 추가해준다.
3.2 The Deep Component
이어서 wide & deep model의 deep component는 feed-forward neural network로 두었다. 먼저 고차원의 categorical feature를 embedding vector로, 즉 저차원의 dense한 real-valued 벡터로 변환한다. 만들어진 embedding vector는 final loss function이 최소화되는 방향으로 학습된다. 이 과정에서 low-dimensional dense embedding vector는 neural network의 hidden layer를 통과하게 된다. 구체적인 수식은 아래와 같다.
은 hidden layer 번호, 는 활성화 함수를 의미하고 , , 은 각각 번째 layer에서의 activation, bias, model weight을 의미한다.
3.3 Joint Training of Wide & Deep Model
이렇게 학습된 wide component와 deep component의 output log odds는 가중합해져 joint training을 위한 logistic loss function에 투입된다. 각 모델이 독립적으로 학습되는 ensemble 방식과 달리, joint training에서는 wide & deep 파트와 가중합을 모두 고려하여 파라미터들이 동시에 최적화된다. 또 deep model의 단점을 보완하기 위해 커다란 wide model을 학습할 필요 없이 작은 규모의 cross-product feature transformation만을 추가하면 된다.
wide & deep model의 joint training은 output gradient에 대한 back-propagation으로 수행된다. 저자는 학습을 위한 optimizer로 wide part에서는 FTRL 알고리즘을 이용했고 deep part에서는 AdaGrad를 이용했다.
마지막 logistic regression을 통한 모델의 prediction은 다음과 같다.
는 binary class label, 은 sigmoid 함수, 는 bias, 는 original feature 에 대한 cross product transformation 결과를 의미한다. 와 은 각각 wide model의 가중치 벡터, deep model에서 마지막 activation 의 가중치 벡터이다.
4. Conclusion
추천시스템에 있어서 memorization과 generalization은 모두 중요하다. wide linear model은 cross-product transformation을 통해 희소한 feature간의 interaction을 효과적으로 memorize할 수 있다. 그리고 deep neural network는 이전에 관찰되지 않은 feature interaction을 low-dimensional embedding을 통해 generalize할 수 있다.
본 논문에서 제안된 wide & deep model은 앱 추천시스템에 큰 발전을 가져왔다.
앙상블의 효과는 역시 대단하다😀
