[Paper Review] AutoRec: Autoencoders Meet Collaborative Filtering
Suvash Sedhain, Aditya Krishna Menon, Scott Sanner, and Lexing Xie. 2015.
Autorec: Autoencoders meet collaborative filtering. In Proceedings of the 24th
International Conference on World Wide Web. ACM, 111–112.
1. Introduction
Collaborative Filtering(CF) 모델들은 아이템에 대한 유저의 선호도를 뽑아내 개인화된 추천을 제공하는 것을 목표로 한다. Netflix challenge를 통해 여러 종류의 CF 모델들이 제안되었고, 그 중 matrix factorization과 neighbourhood 모델이 인기를 끌었다.
본 논문에서는 AutoRec이라는 새로운 CF 모델을 제안한다. AutoRec은 최근 vision과 speech task 분야에서 좋은 성능을 보이고 있는 neural network, 그 중에서도 autoencoder를 추천시스템에 적용한 모델이다. 저자는 AutoRec이 기존에 있던 neural approach에 비해 representational, computational advantages를 가지고 있다고 말한다.
2. The AutoRec Model
rating-based collaborative filtering에서는 명의 유저와 개의 아이템, 그리고 partially observed 유저-아이템 rating matrix 이 존재한다. 각각의 유저 은 partially observed vector 으로 표현될 수 있다. 비슷한 방법으로 각각의 아이템 역시 partially observed vector 로 표현될 수 있다.
논문에서 AutoRec 모델은 아이템 기반 autoencoder를 학습한다. 즉 partially observed vector 를 input으로 받아 저차원의 latent space에 투영시키고, 이를 다시 output space의 벡터 로 reconstruct하여 관찰되지 않았던 rating을 예측해내는 것이 목표이다. 유저 기반 autoencoder를 학습시키고 싶다면 를 이용해 같은 과정을 반복하면 된다.
의 벡터 집합 가 주어져 있을 때, 어떤 자연수 에 대해 autoencoder는 다음과 같이 RMSE를 최소화하는 방향으로 학습된다.
는 활성화 함수 , 를 이용한 input 의 reconsturction을 나타낸다.
식에서 는 모델 파라미터로, backpropagation을 통해 학습된다. , 는 transformation matrix, , 는 bias이다.
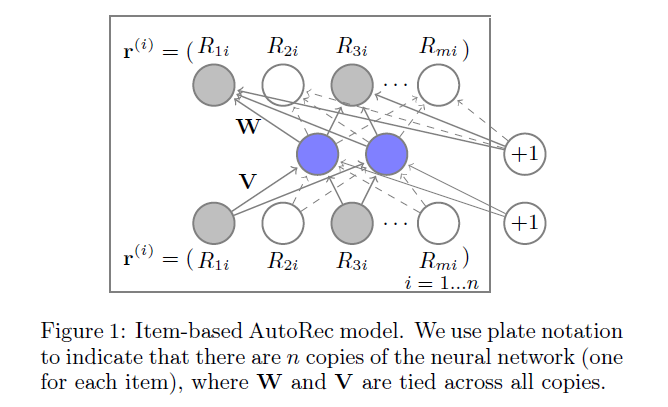
아래 그림은 아이템 기반 AutoRec 모델의 구조이다.
AutoRec은 벡터 집합 을 autoencoder에 통과시킨다. 이때 각 에서 관측된 요소에 대해서만 backpropagation으로 가중치를 업데이트하였다. 또한 학습된 파라미터를 regularize하여 과적합을 방지하였다.
따라서 Item-based AutoRec(I-AutoRec) 모델의 목적 함수는 아래와 같다.
식에서 는 연산 시 관찰된 rating만 고려했다는 것을 의미한다. User-based AutoRec(U-AutoRec)의 경우엔 으로 식을 대체하면 된다.
결론적으로, I-AutoRec은 개의 파라미터를 요구한다. 학습된 파라미터 에 대해 I-AutoRec이 도출해내는 rating은 다음과 같다.
위 Figure 1에서 색칠된 노드는 관찰된 rating을 뜻하고, 실선 화살표는 input 에 대해 업데이트되는 가중치를 의미한다.
3. Conclusion
AutoRec은 autoencoder에 기반한 discriminative model로, gradient 기반 backpropagation을 통해 빠르게 학습되는 장점을 가지고 있다. 파라미터 수가 적기 때문에 연산에 필요한 메모리가 적고 과적합 가능성도 낮다. 또 activation function 을 통해 nonlinear latent representation도 학습할 수 있다.
짧은 논문이었지만 인상적이었다..! encoding-decoding 과정을 통해 관찰되지 않은 rating을 얻어낸다는 아이디어가 신선했다👍
