구현 막바지에 있는 TRILO 프로젝트에서 마지막으로 간단하게 좋아요 기능을 추가하기 위해 발생할 수 있는 여러가지 문제와 해결방법에 대해서 고민해봤고 글을 남깁니다. 😃
연관관계 매핑
좋아요 기능은 한 명의 사용자가 여러 개의 여행에 대해서 좋아요를 누를 수 있어야하고(참조), 반대로 한 개의 여행이 여러 명의 사용자를 참조할 수 있어야한다. 즉, 좋아요 기능은 따라서 N : M 연관관계에 놓여있다.
N : M 연관관계를 매핑하는 방법은 여러가지가 있겠지만, 크게는 두 가지가 있다.
- @ManyToMany 어노테이션을 통해 중간 테이블을 통해 맺어주는 방법
- 별도의 Entity 를 정의하여 두 테이블의 PK를 FK 로 갖는 방법
N:M 매핑을 할 때에 위와 같이 별도의 Entity 를 선언하지 않고, @ManyToMany 를 사용하여 연관관계를 매핑해주는 방법도 있습니다. 구현이 비교적 간단한 경우 해당 방법을 사용할 수도 있겠지만 매핑 뿐만 아니라 비즈니스 로직상 필요한 정보들을 영속화 해야하는 경우에 전자의 방법은 한계가 있고 중간 테이블을 이용하므로 어떤 쿼리가 나갈지 예상이 안된다는 문제가 존재하므로 별도의 Entity 를 정의하는 것이 좋습니다. ( 참고로 실무에서는 단순히 매핑 정보만 처리하고 끝나는 경우가 거의 없다고 합니다 - 김영한님 ORM 강의 참고 )
구현의 편리함과 추가 컬럼을 고려해서 2번 방식을 채택했고 다음과 같이 Entity 를 정의했다.
@Getter
@Entity
@Table(name = "likes")
@EqualsAndHashCode(of = {"tripperId", "tripId"})
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Like {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column
private Long id;
@Column(name = "tripper_id")
private Long tripperId;
@Column(name = "trip_id")
private Long tripId;
private Like(Long tripId, Long tripperId){
this.tripId = tripId;
this.tripperId = tripperId;
}
public static Like of(Long tripId, Long tripperId){
return new Like(tripId, tripperId);
}
}
REST API 설계
API Endpoint 를 정의해야하는데 N:M 이라서 어떻게 정의해야할지 참 난감하다.
API 관점을 좋아요 생성이라고 보면 HTTP METHOD를 POST로 하는게 자연스럽지만, 좋아요 수 증가라고 보면 PUT 이 자연스럽다. 좋아요 기능의 핵심은 좋아요 생성이라고 생각하고 좋아요 수 증가는 그에 따라 부수적으로 이루어지는 것이라는 관점 하에 좋아요 기능의 HTTP 메서드를 POST 로 정했다.
크게 좋아요를 적용할 여행의 식별자, 그리고 좋아요를 요청한 사용자의 식별자 이렇게 2 가지가 필요하고 좋아요를 요청한 사용자의 식별자는 JWT를 통해 받을 수 있으니 Path Param 을 통해 나머지 여행의 식별자를 전달 받는 식으로 다음과 같이 API 를 설계했다.
좋아요 등록
POST /api/trips/{tripId}/likes
좋아요 같은 경우 요청시 RESOURCE 가 추가가 된다는 점에서 HTTP METHOD 를 POST, 응답은 200 OK 로 정했다.
좋아요 취소
DELETE /api/trips/{tripId}/likes
좋아요 취소 같은 경우 요청시 해당 RESOURCE 가 삭제가 된다는 점에서 HTTP METHOD 를 DELETE, 응답은 204 NO CONTENT 로 정했다.
추후 내가 좋아한 여행 목록 조회 요청 API 가 필요한 경우에는 /api/users/me/likes/trips
어느 한 사용자가 좋아하는 여행 목록 조회 요청 API 의 경우
/api/users/{userId}/likes/trips
특정 여행을 좋아하는 사용자 목록 조회 요청 API 의 경우에는
/api/trips/{tripId}/likes/users
이런 식으로 정의가 될 것 같다.
동작 순서
JPA 로 구현한 코드는 다음과 같이 동작한다.
- 여행 조회
- 회원과 여행 사이의 좋아요 생성
- 여행 likeCount 컬럼 + 1
- 변경 감지를 통한 업데이트 쿼리
- 커밋 완료
문제점 (feat. 멀티 쓰레드)
JPA 를 활용해서 변경감지를 통해 객체지향스럽게 해결한 듯 보인다. 핵심 비즈니스 로직은 도메인에 위치하고 있어 서비스 계층에 위치한 코드 양도 많지 않아 테스트하기에도 좋아보인다. 겉보기엔 문제가 전혀 없어보인다. 과연 실사용 환경에서도 문제가 없을까..?
대부분의 웹 서비스는 context-switching 비용, 메모리의 효율적인 사용을 위해 멀티 프로세스가 아닌 멀티 쓰레드 방식을 사용한다. 즉 같은 요청의 경우 같은 프로세스 내에서 생성된 쓰레드가 메모리를 공유하며 동작한다.
메모리를 공유하며 동작하기에 다음과 같은 문제가 발생할 수 있다.
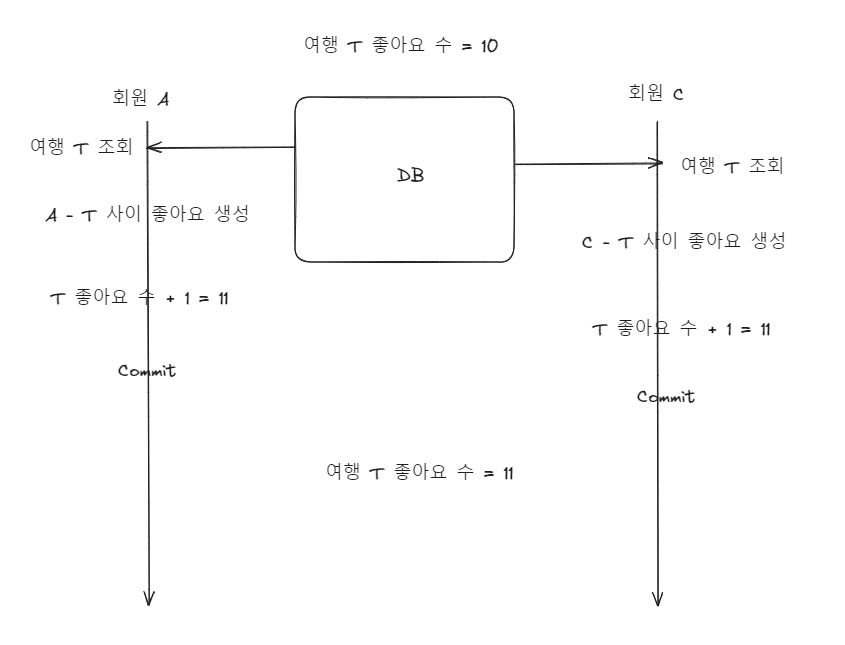
즉, 여러 명의 사용자가 동시에 한 여행에 대해 좋아요를 누르게 되면 위와 같이 12으로 초기화되어야할 컬럼값이 11로 초기화되는 것처럼 정합성이 깨지는 상황이 발생할 수 있다.
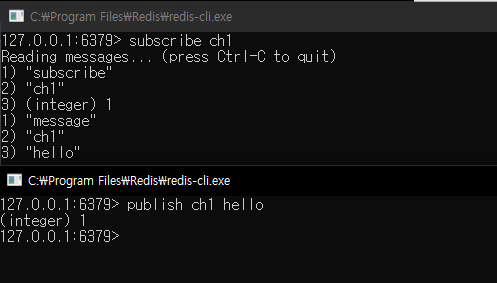
Ngrinder 로 문제 확인해보기
다음과 같이 1000명이 동시에 한 여행에 대해 좋아요 버튼을 누르는 상황을 가정해봤다.
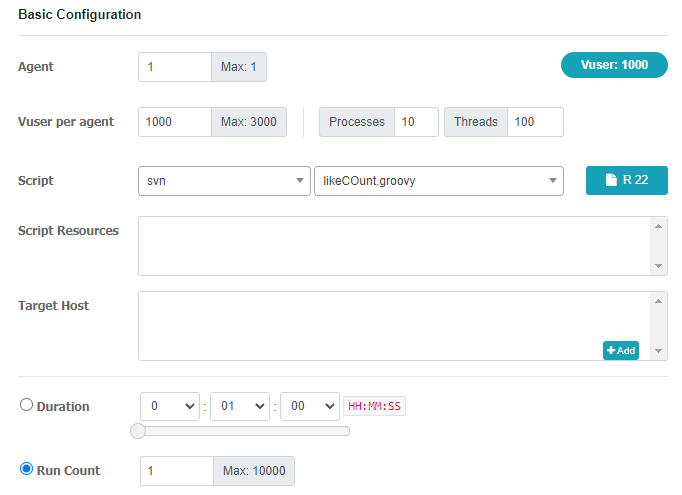
우선 nGrinder 의 실행 결과는 다음과 같이 나온다.

위와 같이 분석 결과를 살펴보면 1000명의 사용자가 동시에 요청했을 때 초당 처리하는 트랜잭션의 수는 약 63개, 실패율은 거의 80 퍼센트에 육박한다.

서버 로그를 살펴보면 위와 같이 한정된 자원에서 DeadLock 으로 인해 많은 요청이 반려된 것을 확인해볼 수 있다.
🤔 여러가지 고민
1. Java syncronized
위와 같이 메서드를 임계영역으로 잡고 Lock 을 획득한 단일 Thread 만 통과시킨다.
public synchronized void addLike(Long tripId, Long tripperId){
// validateNotLiked(tripId, tripperId);
Trip trip = findTrip(tripId);
likeRepository.save(Like.of(tripId, tripperId));
trip.increaseLikeCount();
tripRepository.save(trip);
}결과를 보면 정상적으로 모든 요청이 처리된 것을 확인해볼 수 있다.
이 방식은 @Transactional 를 사용할 수 없다. 트랜잭션 AOP 를 적용할 경우 해당 메서드를 프록시로 감싸서 메서드 수행이 완료가 되고 commit() 이 수행되는데, 이 commit() 은 결국 임계영역 밖에서 수행된다. 즉, 실제 커밋 전에 다른 Thread 가 Lock 을 얻어 수행되어 동일하게 동시성 이슈로 인한 정합성 문제가 발생할 수 있다.

이 방식 확실히 Thread 동기화 문제와 발생할 수 있는 정합성 문제를 해결해준다. 하지만 메서드에 임계 영역을 걸어놓고 Lock 을 획득한 단일 쓰레드만 접근하도록 허용하게 되면, 동일 자원에 대한 접근이 아닌 쓰레드까지 모두 Lock 획득을 위해 기다려야하며.. 그 만큼 쓸데없이 병목이 발생할 것이고 성능저하를 유발한다.
2. Pessimistic Lock (비관적 락)
비관적 락은 쉽게 말해 상황을 비관적으로 보고, 문제가 발생할 것을 예상하여 조회 시점부터 쓰기 락을 획득하여 커밋 시점까지 유지하는 것을 말한다. JPA 를 사용한다면 어노테이션을 통해 쉽게 구현이 가능하다.
@Lock(LockModeType.PESSIMISTIC_WRITE)
@Query("select t from Trip t where t.id =:id")
Trip findByIdWithPessimisticLock(Long id);이전과 동일하게 1000명이 동시에 좋아요를 누르는 상황에서 정상적으로 수행된다.

조회 시점부터 x-Lock 을 획득하여 commit 전까지 락을 유지하기 때문에 정합성은 확실하게 보장할 수 있다. 하지만 그 만큼 읽어 오는 시점부터 x-Lock 을 유지하기 때문에 동시 처리 성능은 떨어진다.
3. Optimistic Lock (낙관적 락)
낙관적 락은 Version 을 통해 구현한다.
비관적 락과 달리 X-Lock 을 조회시점에 획득하는것이 아니라 쓰기 시점에 획득하기 때문에 좀 더 나은 성능을 보일 수 있으나, 수동으로 Rollback 처리 로직을 작성해주어야하고 이 때문에 경합이 자주 발생할 경우 비관적 락 방식보다 오히려 성능이 떨어질 수도 있다.
4. Query 를 직접 작성해주는 방법(DB 중심)
가장 간단하고 손쉬운 방법이다. 복잡하게 생각할 것 없이, 로직을 DB Query 로 구현하는 것이다. 쉽게 말해 로직을 코드로 구현하는것이 아닌 Query 를 통해 구현하는 것으로 객체지향을 포기하고 DB 에 의존해서 구현하는 방법이다.
즉, 다음과 같이 +1 연산을 JPA 의 Dirty Checking 을 활용하는게 아니라 Update 쿼리를 직접 작성해서 DB 계층에서 처리를 하면 된다. JPQL 을 활용해서 손쉽게 구현이 가능하다.
@Modifying(clearAutomatically = true, flushAutomatically = true)
@Query(update Trip t set t.likeCount = t.likeCount + 1 where t.tripId := tripId)
void increaseLikeCount(Long tripId);이 방식은 손쉽게 구현이 가능하지만 핵심 비즈니스 로직을 도메인도 아니고, 서비스도 아닌 DB 쿼리를 통해 데이터 중심으로 해결한다는 점에서 JPQL 을 사용하더라도 객체지향을 어느 정도 포기해야하므로 일단 반려하게되었다.
5. 분산락 활용
단일 서버에서 단일 DB 를 가지고 운영을 하는 경우에는 위와 같은 방법으로 락을 관리하는데 지장이 없다. 하지만 여러 대의 API 서버 혹은 여러대의 DB 서버를 갖는 분산 환경에서는 유효하지 못하다.
예를 들어 대규모 시스템을 설계하게되면 단일 서버로 모든 요청을 처리하지 않는다. 더불어 DB 서버도 여러대 존재하게 된다. 따라서 같은 API 요청이 들어와도 요청을 처리하기 위해 읽어오는 DB 가 다를 수 있다. 비관적 락을 통해 X-Lock 을 걸어도 해당 DB 에서 안 읽고 다른 DB 서버에서 데이터를 읽게 되면 락을 획득해서 DB 데이터를 읽을 수 있게 된다.
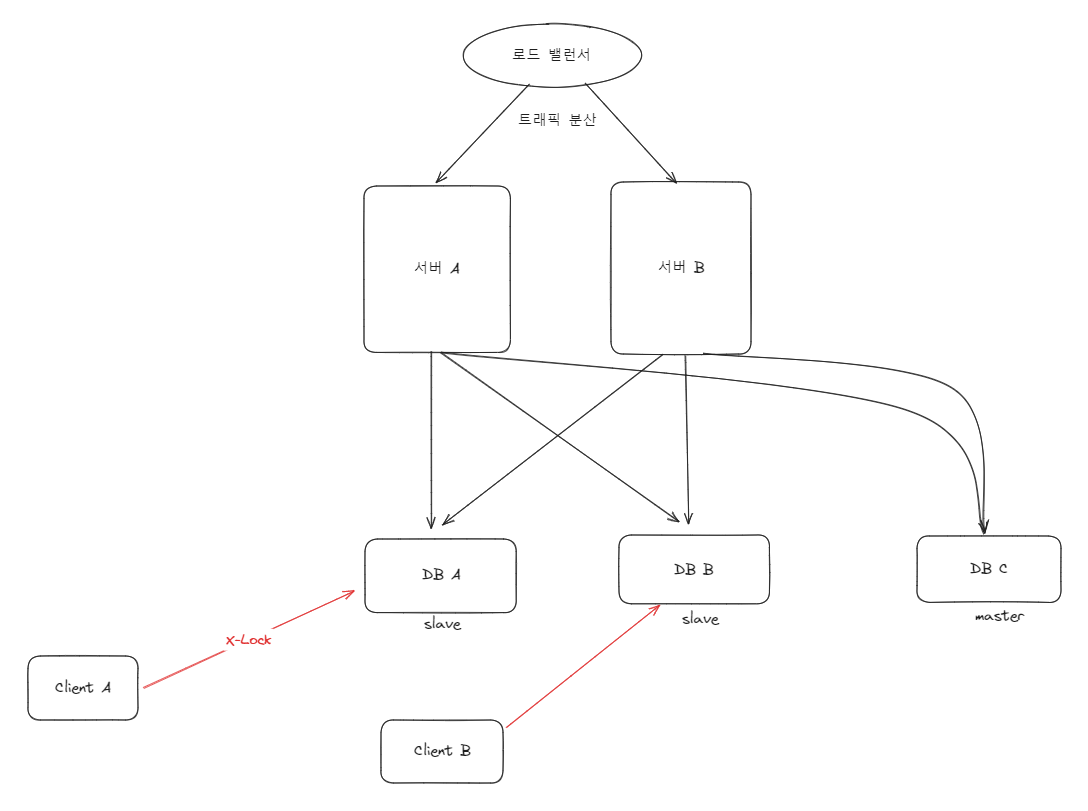
이런 경우 동일하게 동시성 이슈로 인한 정합성 이슈가 발생할 수 있다. 조금 복잡하게 말했는데 정리하자면 다음과 같다.
- 단일 DB 를 사용할 경우엔 Pessimistic Lock 이나 Optimistic Lock 을 활용할 수 있다.
- 다중 DB 를 사용할 경우에는 분산락을 활용한다. (MySQL - named Lock , Redis - Redisson, Lettuce)
👏 해결 방법 - Redisson ✅
결론부터 말하면 Redisson 을 이용하여 분산락을 이용하는 방식을 채택했다. 우선
Redis를 선택한 이유는 이미 Redis라는 기술 스택을 JWT 관리에 사용 중이어서 추가 인프라 구축이 필요 없었고, 또한 MySQL 로도 동일하게 동시성 이슈를 해결할 수 있겠지만 락을 사용하기 위해 별도의 커넥션 풀을 관리해야 하고 락에 관련된 부하를 RDS에서 받는다는 점에서 Redis를 사용하는 것이 더 효율적이라고 생각했기 때문이다.
Redis 를 이용하여 분산락을 구현하는 방법에는 Lettuce 와 Redisson 이렇게 두 가지 방법이 있다. 여기서 Lettuce 는 분산락 구현 시 setnx, setex과 같은 명령어를 이용해 지속적으로 Redis에게 락이 해제되었는지 요청을 보내는 아래와 같은 스핀락 방식으로 동작하기에 요청이 많을수록 Redis가 받는 부하는 커지게 된다.
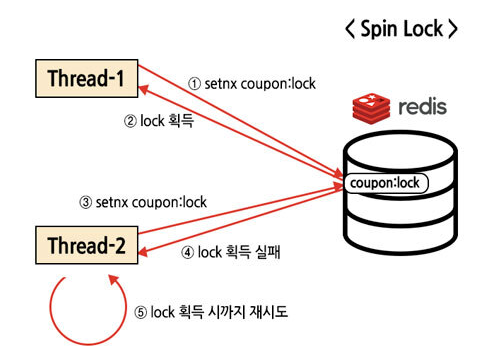
반면 Redisson 의 경우 아래와 같이 Publish & Subscribe 방식을 이용하기에 락이 해제되면 락을 subscribe 하는 클라이언트는 락이 해제되었다는 신호를 받고 락 획득을 시도하게 된다. 즉, 무분별하게 락을 획득할 때까지 Redis 에 요청을 보내지 않아 Redis 가 쓸데없이 많은 부하를 받는 것을 방지해줄 수 있다.
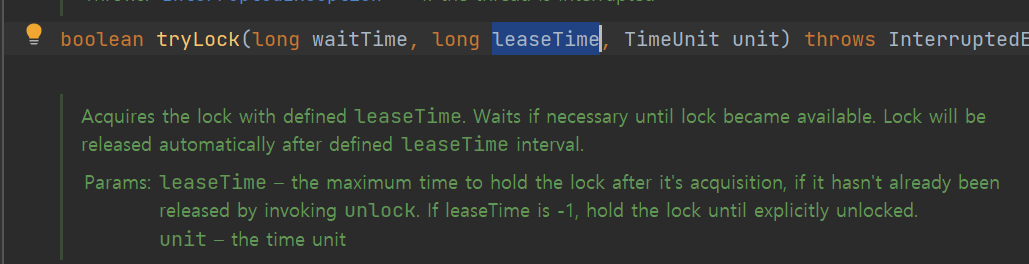
Redisson 라이브러리 의존성을 추가해준다음 tryout 메서드를 살펴보면 아래와 같이
- Lock 획득을 대기할 최대 시간
- Lock 만료 시간
을 파라미터로 정의하고 있다.
즉, race condition 에서는 다음과 같은 동작을 수행한다.
- sub 상태에 들어가 있다가 Lock 이 해제되어 메시지가 도달하면 wait 상태를 해제하고 Lock 획득을 시도한다.
- Lock 획득 실패 시 Lock 이 해제될 때 까지 대기한다.
해당 프로세스를 지정해놓은 타임아웃(Lock 획득 최대 대기 시간) 동안 반복하고 타임아웃이 끝나면 false 를 반환하고 Lock 획득이 실패했음을 알린다.
정리하자면 위와 같은 프로세스로 인해서 Redisson을 사용하면 무한히 Lock 을 대기하지 않아, 무한 루프에 빠질 위험이 없고, Lock 이 해제되면 알림을 통해 구독하는 Client 가 동작하기 때문에 동일하게 분산락을 지원하는 Lettuce 처럼 Lock 확인 요청을 Redis 에 질의하지 않아 가해지는 엄청난 트래픽을 줄일 수 있다.
nGrinder 로 확인해보기
1000명의 사용자가 동시에 한 여행에 대해 좋아요 버튼을 누르는 상황을 가정해서 테스트를 실행해본다.
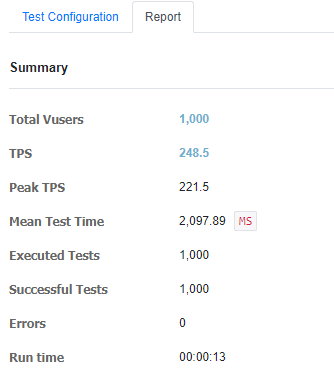
다음과 같이 like_count 컬럼이 1000으로 정상적으로 모든 요청이 처리된 것을 확인할 수 있다.

아키텍처
Facade 패턴을 통해 서비스 계층의 로직과 Redisson 관련 Lock 을 처리하는 로직을 분리했다. JPA Dirty Checking 을 활용하여 핵심 비즈니스 로직은 Domain 계층에 위치시키고 서비스 계층에서는 단순히 도메인 계층에 위임하거나 DB 및 예외 처리 로직만을 남긴다.
의존 방향은 다음과 같다.
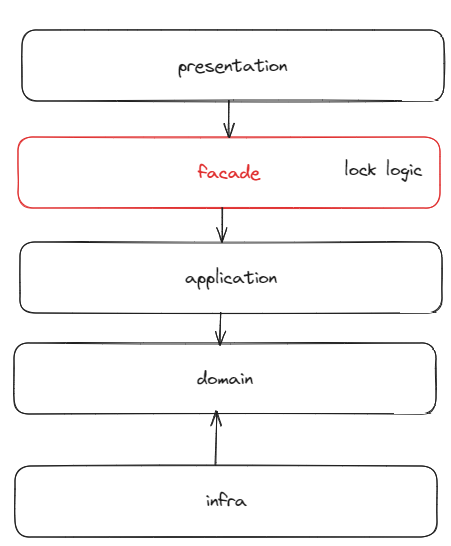
DIP 의 경우, 데이터 접근 기술의 변경 및 확장성을 고려하여 infra 계층에 구현체를 두는 식으로 런타임 & 컴파일 타임 의존성을 분리하여 설계한다. 이외에는 변경 및 확장 가능성이 존재하지 않기에 런타임 & 컴파일타임 의존성을 일치시킨다.
@FunctionalInterface
public interface TripLikeOperation {
void perform(Long tripId, Long tripperId);
}
@Component
@RequiredArgsConstructor
public class TripLikeFacade {
private final RedissonClient redissonClient;
private final TripLikeService tripLikeService;
private void performWithLock(Long tripId, Long tripperId, TripLikeOperation operation){
RLock lock = redissonClient.getLock(tripId.toString());
try{
boolean available = lock.tryLock(1, 3, TimeUnit.SECONDS);
if(!available){
throw new LockNotAcquiredException();
}
operation.perform(tripId, tripperId);
}catch (InterruptedException e){
throw new LockNotAcquiredException();
}finally {
lock.unlock();
}
}
public void addLike(Long tripId, Long tripperId){
performWithLock(tripId, tripperId, tripLikeService::addLike);
}
public void removeLike(Long tripId, Long tripperId){
performWithLock(tripId, tripperId, tripLikeService::removeLike);
}
}
@Service
@RequiredArgsConstructor
@Transactional
public class TripLikeService {
private final TripRepository tripRepository;
private final LikeRepository likeRepository;
public void addLike(Long tripId, Long tripperId){
validateNotLiked(tripId, tripperId);
Trip trip = findTrip(tripId);
likeRepository.save(Like.of(tripId, tripperId));
trip.increaseLikeCount();
}
private void validateNotLiked(Long tripId, Long tripperId){
if(likeRepository.existsByTripIdAndTripperId(tripId, tripperId)){
throw new TripAlreadyLikedException();
}
}
public void removeLike(Long tripId, Long tripperId){
Trip trip = findTrip(tripId);
Like likeRelation = findLikeRelation(tripId, tripperId);
likeRepository.delete(likeRelation);
trip.decreaseLikeCount();
}
private Trip findTrip(Long tripId){
return tripRepository.findById(tripId)
.orElseThrow(TripNotFoundException::new);
}
private Like findLikeRelation(Long tripId, Long tripperId){
return likeRepository.findByTripIdAndTripperId(tripId, tripperId)
.orElseThrow(LikeNotFoundException::new);
}
}
정리
기능 하나를 추가하는데, 생각보다 고려할게 많고 동시성 문제를 해결하기 위한 선택지도 생각보다 많아서 고민했던 모든 내용을 다 기록하지는 못했다. 여전히 고민할 것과 생각할게 많아서 추후에 한번 더 DB Lock 관련 글을 쓰며 한번 더 다시 정리해봐야겠다.
참고자료
- https://yangbongsoo.gitbook.io/study/undefined-1/rest
- https://docs.github.com/ko/free-pro-team@latest/rest/users/followers?apiVersion=2022-11-28#follow-a-user
- https://techvu.dev/116
- https://suhwan.dev/2019/06/09/transaction-isolation-level-and-lock/
- https://hyperconnect.github.io/2019/11/15/redis-distributed-lock-1.html
