
주소창에 URL 입력 시 백엔드에서는 무슨 일이 일어날까?
앞에 설명은 모두 이 부분을 이해하기 위한 배경지식 설명이었습니다. 그럼 이제 본격적으로 주소창에 url 입력 시 브라우저에서 어던 일이 벌어지는지 백엔드 관점에서 살펴보겠습니다.
URL 파싱
주소창에 URL 입력 시 브라우저는 먼저 입력받은 URL의 구조를 해석(Parsing)합니다. 브라우저는 어떤 프로토콜을 통해 해당 URL을 요청할 것인지, 어떤 도메인을 요청할 것인지, 어떤 포트로 요청할 것 인지 해석합니다.
DNS 조회
배경지식 편에서 말씀드린 것 처럼 웹 사이트에 접근하기 위해서는 웹 서버의 IP 주소가 필요합니다. 즉 원래는 주소창에 IP 주소를 입력해야 하지만 Domain Name System에 의해 IP 주소가 아닌 문자로 된 URL을 입력해도 우리는 웹 사이트에 접근 할 수 있습니다. 우리가 URL을 입력하면 웹 브라우저는 Domain Name Server에 접속해서 해당 도메인에 해당하는 IP주소를 응답받아 서버에 접속합니다.
우리가 중국집 사장이라고 가정해보겠습니다. 손님이 전화로 ‘여기 OO빌딩인데 짜장면 2개 배달해주세요.’ 라고 했을 때, 우리가 만약 처음 배달 가는 곳이라면 네이게이션으로 위치를 검색 후 찾아갈 것입니다. 그리고 그 위치를 기억해 놨다가 나중에 동일한 장소에서 배달 주문이 오면 네비게이션을 검색하지 않고 바로 찾아가겠죠.
브라우저도 이와 같은 작업을 합니다. 중국집 배달원이 이미 배달 가본 적 있어서 가는 길을 알고 있는데도 네비게이션으로 위치를 검색하고 찾아간다면 배달 시간도 길어지고 비효율적일 것입니다. 이 처럼 브라우저가 이미 방문한 적 있는 웹 사이트의 URL을 DNS에 IP 요청하게 된다면 웹 사이트 응답 시간이 길어지고 비효율적이겠죠. 때문에 브라우저는 DNS에게 응답받은 IP 주소를 캐싱(저장)합니다. 그리고 사용자가 주소창에 URL 입력 시, 브라우저는 먼저 캐싱 된 데이터 중에서 해당 도메인에 해당하는 IP 주소가 있는지를 먼저 확인합니다. 캐싱된 데이터에서 해당 IP주소를 찾으면 그 IP 주소로 바로 이동하고, 해당 IP 주소가 없으면 DNS에 IP 주소를 요청합니다. 이러한 방식은 브라우저가 좀 더 빠르게 서버에게 요청 할 수 있도록 합니다.
IP 주소 탐색 과정
DNS 상에서 IP가 어떻게 찾아지는지 조금 더 상세하게 알아보겠습니다. 그 전에 몇 가지 알아야할 것들이 있습니다. 기본적으로 컴퓨터의 LAN선을 통해 인터넷이 연결되면, 인터넷을 사용할 수 있게 IP를 할당해주는 통신사(KT, SK, LG 등) 에 해당되는 각 통신사의 DNS서버가 등록되는데, 이것을 Local DNS라고 합니다. 그리고 배경지식 편에서 말했던 것처럼 루트 도메인이 있듯이 DNS도 루트 DNS가 있습니다. 루트 DNS는 전 세계에 13대만 존재하며, Local DNS가 IP를 조회할 때 가장 먼저 요청하는 DNS입니다.

우리가 주소창에 domain.co.kr 을 입력했다고 가정할 때 아래의 과정을 통해 IP 주소가 조회됩니다.
- 브라우저는 먼저 Local DNS에
domain.co.kr에 해당하는 IP 주소를 요청합니다. - Local DNS에는 해당 도메인에 대한 정보가 있을 수도 있고 없을 수도 있습니다. 만약 Local DNS에 해당 도메인에 대한 IP 주소가 있다면 브라우저에게 응답하고, 없으면 Local DN는 루트 DNS에게 해당 도메인의 IP를 요청합니다.
- 루트 DNS는 해당 도메인 IP 정보를 갖고 있다면 Local DNS에 응답하고, 없다면 어떤 DNS에 요청해야 하는지를 알려줍니다.
domain.co.kr를 예로들면 루트 DNS는.kr도메인을 관리하는 DNS에 물어보라고 Local DNS에 응답합니다. - Local DNS는
.kr도메인을 관리하는 DNS에 IP 주소 요청을 하고,.kr도메인을 관리하는 DNS는 해당 IP 정보를 갖고 있다면 해당 IP 주소를 Local DNS에 응답하고, 없다면.co.kr도메인을 관리하는 DNS에 물어보라고 응답합니다. - Local DNS는
.co.kr도메인을 관리하는 DNS에 IP 주소 요청을 하고,.co.kr도메인을 관리하는 DNS는 해당 IP 정보를 갖고 있다면 해당 IP 주소를 Local DNS에 응답하고, 없다면domain.co.kr도메인을 관리하는 DNS에 물어보라고 응답합니다. - Local DNS는
domain.co.kr도메인을 관리하는 DNS에 IP 주소 요청을 하고,domain.co.kr도메인을 관리하는 DNS는 Local DNS에 해당 도메인의 IP 주소를 응답합니다. - 이를 수신한 Local DNS는
domain.co.kr도메인에 대한 IP 주소를 캐싱하고, IP 주소를 브라우저에게 응답합니다.
이와 같이 Local DNS 서버가 루트 DNS를 시작으로 하위 도메인을 관리하는 DNS에게 요청하여 IP주소를 찾는 과정을 Recursive Query라고 부릅니다. 그리고 IP 주소를 찾는 과정이 이렇게 길고 복잡하기 때문에 브라우저는 IP 주소를 캐싱합니다.
서버와 연결
패킷 통신
패킷(paket)은 pack과 bucket의 합성어로 컴퓨터 통신에서 데이터를 주고받을 때 네트워크를 통해 전송되는 데이터 조각을 뜻합니다. 패킷 통신은 보내고자 하는 데이터를 작은 조각으로 쪼개서 보내는 방식입니다. 인터넷 통신의 대부분은 패킷 통신을 기본으로 하고 있으며, 웹도 마찬가지입니다.
TCP / IP
패킷 통신을 위한 TCP/IP 인터넷 프로토콜이 있습니다. TCP/IP 프로토콜은 인터넷 프로토콜인 IP(Internet Protocol)와 전송 제어 프로토콜인 TCP(Transmission Control Protocol)로 이루어져 있습니다.
IP는 배경지식 편에서 말한 것처럼 인터넷상의 주소 규칙입니다. 집의 주소를 부여하는 규칙이 존재하듯이, 인터넷상에 연결된 모든 컴퓨터의 위치에도 규칙이 필요합니다. 이전에는 IPv4를 사용하고 있었지만 지금은 IPv6를 사용하고 있습니다.
TCP는 IP 위에서 동작하는 프로토콜로 데이터 전달을 관리하는 규칙으로, 데이터를 작게 나누어서 한쪽에서 다른쪽으로 옮기고, 이를 다시 조립하여 원래의 데이터로 만드는 규칙입니다. 아까 패킷 통신은 데이터를 패킷이라는 조각으로 쪼개서 보낸다고 했습니다. 이렇게 데이터를 잘게 쪼개서 보낼 경우 데이터 순서가 뒤바뀌거나 중간에 데이터가 빠질 수 있습니다. 하지만 이 문제는 목적지에서 데이터를 점검하여 순서를 정렬하고, 빠지거나 잘못된 데이터가 있으면 다시 받아 합치는 방식으로 간단히 해결할 수 있습니다. 이러한 해결방식이 TCP입니다.
IP는 패킷을 최대한 빨리 목적지로 보내는 역할을 합니다. 때문에 패킷 순서가 바뀌거나 누락되더라도 상관하지 않고 일반 최대한 빨리 목적지로 보내는 데에만 집중합니다. 반면 TCP는 IP보다는 느리지만 꼼꼼한 방식을 취합니다. 도착한 패킷을 조립하고, 손실된 패킷을 확인하여 재전송하도록 요청하는 기능을 합니다. 이 두 개는 다른 프로토콜이지만 패킷 통신을 위한 프로토콜이기 때문에 보통 두 가지를 같이 묶어서 말합니다.
서버와 TCP 소켓 연결
이제 다시 돌아와서 브라우저가 도메인의 IP 주소를 응답받은 후 어떤 일이 벌어지는지 알아보겠습니다. 브라우저는 DNS에게서 IP 주소를 응답받으면 해당 IP 주소와 일치하는 서버와 연결하는데, 인터넷 프로토콜(IP)을 사용해 연결을 구축합니다. 또한 브라우저는 클라이언트와 서버와의 데이터 통신을 위해 TCP 소켓 연결을 진행합니다. 소켓 연결은 3-way-handshake라는 과정을 통해 이뤄집니다. 3-way-handshake는 TCP/IP프로토콜을 이용해서 데이터를 전송하기 전에 먼저 정확한 전송을 보장하기 위해 서버와 사전에 세션을 수립하는 과정입니다. 쉽게 말해 클라이언트와 서버가 서로 데이터를 전송하고 받을 준비를 하는 과정이라고 생각하시면 됩니다.
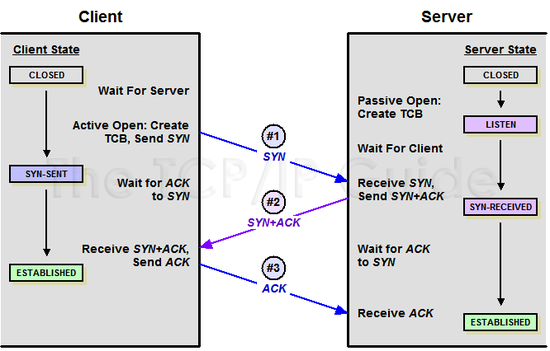
3-way-handshake는 아래의 순서로 진행됩니다.
- 클라이언트가 서버에 접속을 요청하는 SYN(Synchronize Sequence Number) 패킷을 보냅니다.
- 서버는 SYN 요청을 받고, 클라이언트에세 요청을 수락한다는 ACK(Acknowledgment)와 SYN flag가 설정된 패킷을 발송합니다.
- 서버에게 패킷을 전달받은 클라이언트는 서버에게 응답확인했다는 뜻으로 ACK 패킷을 보냅니다. 이제 서버와 연결이 되어 데이터가 오고 갈 수 있습니다.
배경지식 편에서 브라우저와 서버 간에 데이터를 주고받기 위한 방식으로 HTTP라는 프로토콜을 사용하지만 보안상의 이유로 HTTPS를 더 많이 사용한다고 말씀드렸습니다. 3-way-handshake는 HTTP 기준이며, HTTPS를 통해 보안 연결을 설정하려면 TLS(Transport Layer Security) 협상이라고 하는 또 다른 handshake 과정을 거쳐야합니다. TLS는 인터넷에서 정보를 암호화해서 송수신하는 프로토콜입니다. HTTPS로 통신할 경우 브라우저와 서버는 암호화된 데이터를 교환하기 위한 일련의 협상과정을 거치는데 그게 바로 TLS 협상이라고 불리는 TSL Handshake(또는 SSL Handshake)입니다.
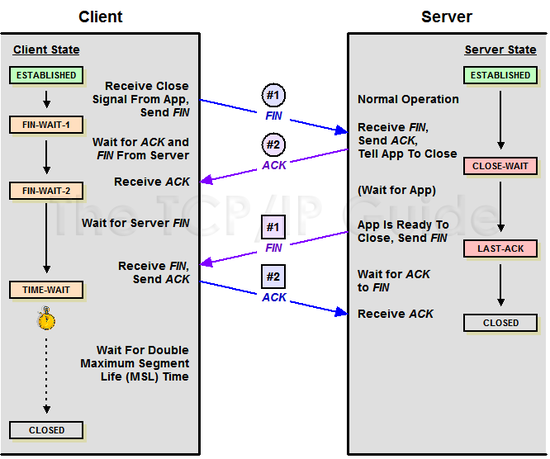
브라우저는 TCP 3-way-handshake 과정을 서버와 연결하고 데이터를 수신받았다면, 4-way-handshake를 통해 연을 종료합니다. 4-way-handshake 과정은 아래와 같습니다.
- 클라이언트가 연결을 종료하겠다는 FIN 플래그를 서버에게 전송합니다.
- 서버는 확인 메시지(ACK)를 보내고 자신의 통신이 끝날때까지 기다립니다.
- 서버가 통신이 끝났으면 연결이 종료되었다고 클라이언에게 FIN 플래그를 전송합니다.
- 클라이언트는 확인했다는 메시지(ACK)를 서버에게 보냅니다.
만약 서버에서 브라우저에게 FIN을 전송하기 전에 전송한 패킷이 여러가지 이유로 FIN 패킷보다 늦게 도착하여 데이터가 유실되는 경우를 막기위해, 브라우저는 서버로부터 FIN 패킷을 수신하더라고 일정시간 동안 세션을 남겨놓고 잉여 패킷을 기다리는 TIME_WAIT 과정을 거칩니다.
HTTP 요청
TCP 연결이 완료되면 이제 본격적으로 데이터 전송이 시작됩니다. 브라우저는 웹 서버에서 사용자가 입력한 URL 웹페이지를 GET 방식으로 HTTP 요청 메시지를 보냅니다.
HTTP
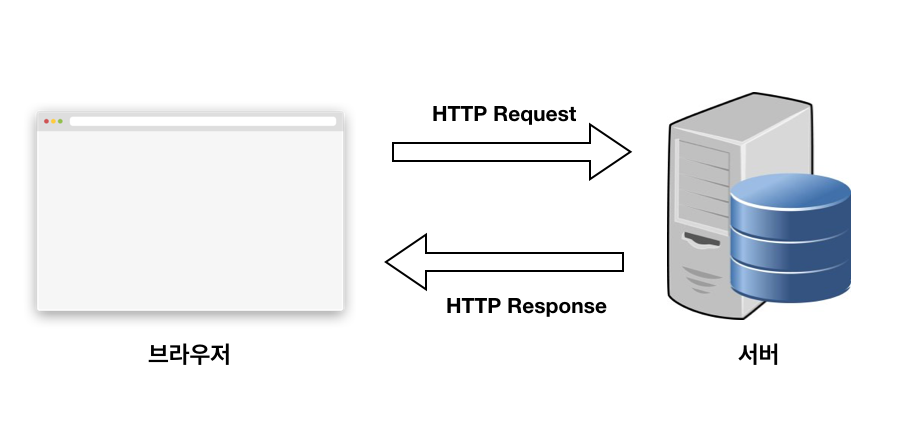
HTTP는 Hypertext Transfer Protocol의 약자로 HTML 문서와 같은 리소스들을 가져올 수 있도록 해주는 프로토콜입니다. 클라이언트와 서버는 개별적인 메시지 교환에 의해 통신합니다. 브라우저인 클라이언트에 의해 전송되는 메시지를 요청(requests)이라고 부르며, 그에 대해 서버에서 응답으로 전송되는 메시지를 응답(responses)이라고 부릅니다. HTTP 프로토콜로 클라이언트와 서버가 데이터를 주고 받기 위해서는 위 사진 같이 요청을 보내고 응답을 받아야 합니다.
클라이언트가 서버에게 요청을 보낼 때 요청에 대한 정보를 담아 서버로 보냅니다. 이는 식당에서 주문서를 작성하는 것과 같습니다. 서버가 주문서를 받아 클라이언트가 어떤 것을 원하는지 파악할 수 있게 하는 것이죠. 서버도 응답할 때 응답에 대한 정보를 담아 클러이언트로 보냅니다. 이런 정보가 담긴 메시지를 HTTP 메시지라고 합니다. HTTP 메시지는 시작줄, 헤더, 본문으로 구성됩니다. 요청 메시지와 응답 메시지의 구조는 아래에서 좀 더 자세히 살펴보겠습니다.
HTTP Request 메시지 구조
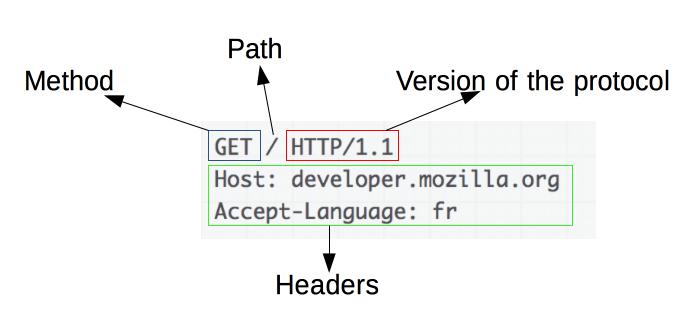
사진 출처 : https://developer.mozilla.org/ko/docs/Web/HTTP/Overview
- 시작줄(첫 줄)
- Method
- URL을 이용하면 클라이언트에서 서버에 특정 데이터를 요청할 수 있는데, 요청하는 데이터에 특정 동작을 수행하고 싶을 때 HTTP 요청 메서드(Http Request Methods)를 이용한다.
- 일반적으로 HTTP 요청 메서드는 HTTP Verbs라고도 불리우며 GET, POST, PUT, PATCH, DELETE 같은 주요 메서드를 갖고 있다.
- 이 외에도 명사형의 HEAD와 OPTIONS 메서드도 갖고 있다.
- HEAD : 서버 헤더 정보를 획득. GET과 비슷하나 Response Body를 반환하지 않음
- OPTIONS : 서버 옵션들을 확인하기 위한 요청. CORS에서 사용
- Path : 가져오려는 리소스의 경로. 포트 번호를 제거한 리소스의 URL을 주로 사용
- Version of the protocol : 프로토콜 버전. HTTP/1.1, HTTP2 등이 있다.
- Method
- Request Headers : 두 번째 줄 부터는 헤더. 요청에 대한 정보를 담고 있다.
- Request Body : 헤더에서 한 줄 띄고 본문이 시작된다. 본문은 요청을 할 때 함께 보낼 데이터를 담는 부분이다.
HTTP Response 메시지 구조
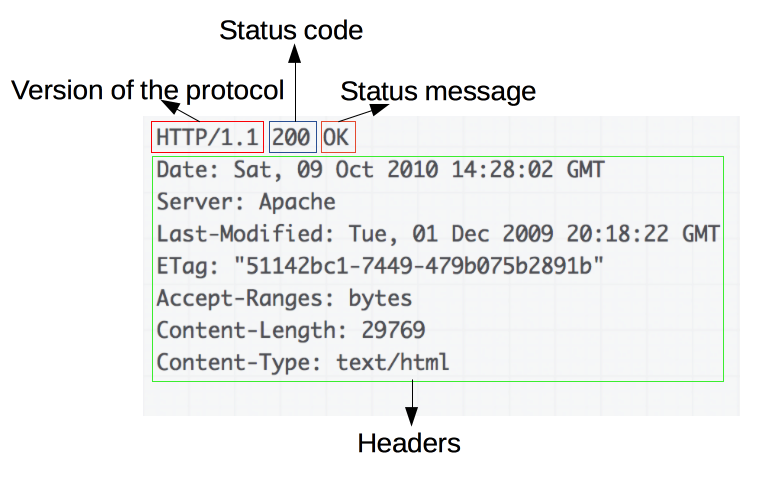
사진 출처 : https://developer.mozilla.org/ko/docs/Web/HTTP/Overview
- 시작줄(첫 줄)
- Version of the protocol : 프로토콜 버전.
- Status Code : 요청의 성공 여부와, 그 이유를 나타내는 상태 코드.
- 2xx - 성공
- 200 : GET 요청에 대한 성공
- 204 : No Content. 성공했으나 응답 본문에 데이터가 없음
- 205 : Reset Content. 성공했으나 클라이언트의 화면을 새로 고침하도록 권고
- 206 : Partial Conent. 성공했으나 일부 범위의 데이터만 반환
- 3xx - 리다이렉션
- 301 : Moved Permanently, 요청한 자원이 새 URL에 존재
- 303 : See Other, 요청한 자원이 임시 주소에 존재
- 304 : Not Modified, 요청한 자원이 변경되지 않았으므로 클라이언트에서 캐싱된 자원을 사용하도록 권고. ETag와 같은 정보를 활용하여 변경 여부를 확인
- 4xx - 클라이언트 에러
- 400 : Bad Request, 잘못된 요청
- 401 : Unauthorized, 권한 없이 요청. Authorization 헤더가 잘못된 경우
- 403 : Forbidden, 서버에서 해당 자원에 대해 접근 금지
- 405 : Method Not Allowed, 허용되지 않은 요청 메서드
- 409 : Conflict, 최신 자원이 아닌데 업데이트하는 경우. ex) 파일 업로드 시 버전 충돌
- 5xx - 서버 에러
- 501 : Not Implemented, 요청한 동작에 대해 서버가 수행할 수 없는 경우
- 503 : Service Unavailable, 서버가 과부하 또는 유지 보수로 내려간 경우
- 2xx - 성공
- Status Message : 상태코드에 대한 짧은 설명을 나타내는 상태 메시지
- Response Header : 요청 헤더와 비슷한, HTTP 헤더
- Response Body : 보통 클라이언트에서 데이터를 요청하고, 응답 메시지에는 요청한 데이터를 담아서 보내주기 때문에 응답 메시지에는 보통 본문이 있다. 응답 메시지에 HTML이 담겨 있다. 이 HTML을 받아 브라우저가 화면에 렌더링한다.
웹 서버와 WAS의 요청 처리 및 응답
정적 페이지(Static Pages)와 동적 페이지(Dynamic Pages)
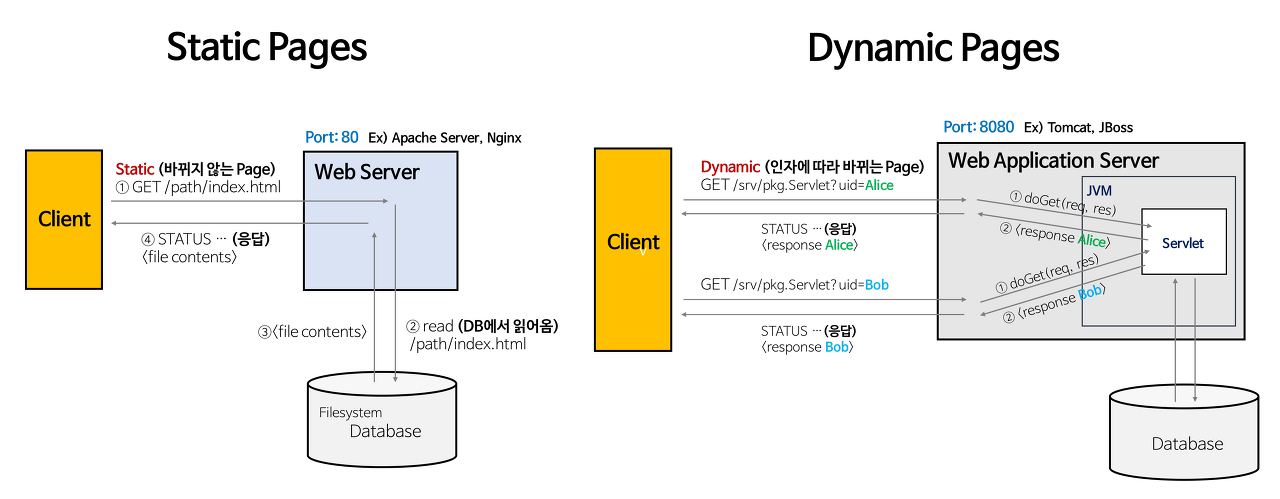
우리가 보는 웹 페이지는 크게 정적 페이지와 동적 페이지로 나뉩니다.
- 정적 페이지 : 언제 접속해도 같은 화면을 보여주는 페이지를 말합니다. 회사 소개 페이지나 해당 벨로그 페이지가 이에 해당합니다. 정적 웹 페이지의 경우 클라이언트가 요청을 보내면 서버는 미리 저장된 웹 페이지를 보내기만 하면됩니다. 때문에 사용자는 서버에 저장된 HTML, CSS, JS등의 파일이 변경되지 않는다면 매번 같은 웹 페이지를 보게 됩니다.
- 동적 페이지 : 클라이언트에게 요청을 받은 후 서버에 의해 추가적인 처리 과정을 거쳐 응답된 페이지를 말합니다. 때문에 매번 같은 화면을 보여주지 않습니다. 네이버의 뉴스, 날씨 등이 이에 해당합니다. 단순 HTML로는 동적 페이지를 만들 수가 없기 때문에, 동적 페이지를 만들기 위해서는 Java와 같은 프로그래밍 언어를 섞어서 사용해야합니다.(예: JSP, PHP, ASP) 웹 서버는 이렇에 Java와 같은 프로그래밍 언어로 동적인 데이터를 정립하면 이것을 다시 HTML 문서로 재조립하여 클라이언트에게 응답합니다.
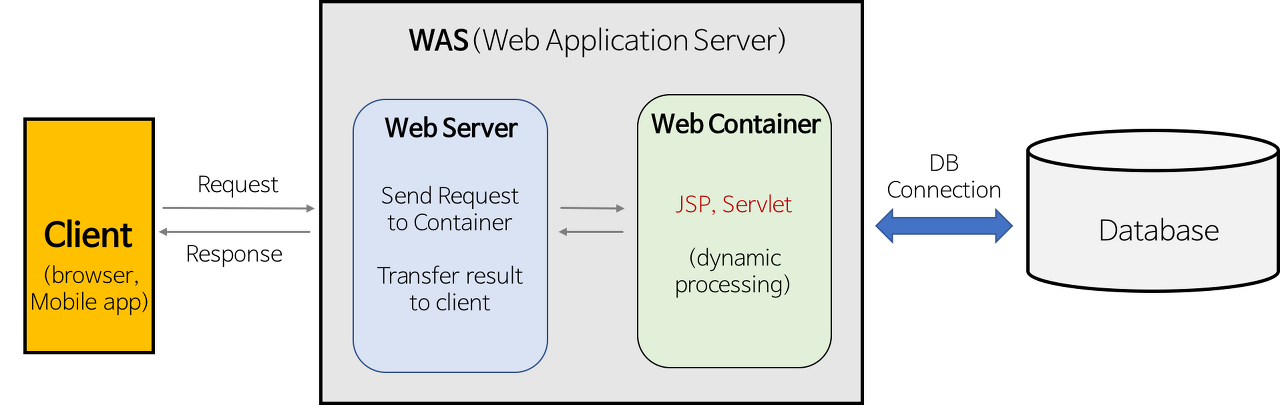
웹 서버란?
웹 서버는 하드웨어 관점과 소프트웨어 관점으로 나눠서 볼 수 있습니다.
- 하드웨어 관점 : 웹 서버가 있는 컴퓨터
- 소프트웨어 관점 : 클라이언트로부터 HTTP 요청을 받아 정적 콘텐츠(html, css 등)를 제공하는 컴퓨터 프로그램
웹 서버는 클라이언트가 요청한 웹 페이지가 정적 페이지라면 웹 서버는 정적 페이지를 응답합니다. 그러나 클라이언트가 요청한 웹 페이지가 동적 페이지라면 WAS라는 미들웨어에게 요청 처리를 맡깁니다. 그리고 WAS에서 처리한 결과를 클라이언트에게 응답합니다. 대표적인 웹 서버로는 Apache, WebtoB, Nginx 등이 있습니다.
WAS란?
WAS란 Web Application Server의 약자입니다. 웹 어플리케이션은 웹에서 실행되는 프로그램을 말합니다. 벨로그도 웹에서 실행되기 때문에 웹 어플리케이션이라고 할 수 있습니다. WAS는 웹 애플리케이션을 실행시켜 필요한 기능을 수행하고 그 결과를 웹 서버에게 전달하는 일종의 미들웨어를 말합니다.
WAS는 웹 서버와 웹 컨테이너가 합쳐진 형태입니다. 웹 컨테이너는 JSP, Servlet을 실행시킬 수 있는 소프트웨어입니다. 즉 WAS는 jsp, Servlet 구동 환경을 제공해줍니다. 이런 이유로 WAS는 웹 컨테이너 혹은 서블릿 컨테이너라고 불립니다.
만약 웹 서버 혼자서 DB를 조회하거나 비즈니스 로직을 처리하게 되면 서버에 과부하가 일어날 확률이 높습니다. WAS는 이런 서버를 돕는 조력자 역할을 합니다. WAS는 웹 서버가 단독으로 처리하기 어려운 DB조회 및 다양한 로직처리가 필요한 동적 페이지를 제공하는 역할을 합니다. 때문에 개발자는 사용자의 다양한 요구에 맞춰 웹 서비스를 제공할 수 있습니다. 대표적인 WAS로는 Tomcat, Jeus, JBoss 등이 있습니다.
웹 서버와 WAS 분리
WAS는 정적인 콘텐츠를 처리하지 못하는 것이 아니라 정적인 콘텐츠 + 동적인 콘텐츠까지 함께 처리할 수 있도록 설계된 서버입니다. 그렇기에 WAS 하나만 사용하여 웹 서비스를 제공하는 것도 가능합니다. 트래픽이 적다면 오히려 WAS하나만 사용하여 서비스하는 것이 복잡하지 않아서 유지 보수하기도 편합니다. 하지만 WAS는 DB 조회나 프로그래밍 로직 처리로 인해 많은 트래픽 처리가 힘들다는 단점이 있습니다. 때문에 트래픽이 많다면 WAS앞에 웹 서버를 하나 더 두어 정적인 요청은 웹 서버가 처리하도록 하여 트래픽을 분산시키는 것이 좋습니다. 웹 서버와 WAS를 분리하면 아래와 같은 이점이 있습니다.
- 기능을 분리하여 서버 부하 방지
- 물리적으로 분리하여 보안 강화
- 여러 대의 WAS를 연결 가능
- 여러 웹 어플리케이션 서비스 가능
정리
오늘 설명드린 것을 토대로 주소창에 URL을 입력하면 일을 간단히 정리하면 아래와 같습니다.
- 브라우저는 먼저 사용자가 입력한 URL을 해석합니다.
- 브라우저는 DNS에 사용자가 입력한 도메인에 해당하는 IP 주소를 요청합니다.
- DNS는 해당 도메인에 해당하는 IP 주소를 찾아 브라우저에게 응답합니다.
- 브라우저는 IP주소를 응답받아 TCP / IP 에 따라 서버와 연결합니다.
- 서버와 연결이 되면 브라우저는 HTTP(S)로 서버에게 요청 메시지를 보냅니다.
- 웹 서버와 WAS는 브라우저의 요청을 받아 처리 후 응답 메시지를 브라우저에게 응답합니다.
참고 블로그
https://www.netmanias.com/ko/post/blog/5353/dns/dns-basic-operation
https://hwan-shell.tistory.com/320
https://brunch.co.kr/@wangho/6
https://enlqn1010.tistory.com/9
https://mindnet.tistory.com/entry/네트워크-쉽게-이해하기-22편-TCP-3-WayHandshake-4-WayHandshake
https://codechasseur.tistory.com/25
https://coding-factory.tistory.com/741
https://velog.io/@tnehd1998/주소창에-www.google.com을-입력했을-때-일어나는-과정
https://velog.io/@minj9_6/브라우저에-url을-입력한-뒤-펼쳐지는-것들#1-브라우저의-url-파싱
