1. 동적계획법
Dynamic Programming, 메모리를 누적하거나 적절히 활용하여, 알고리즘을 수행하는 시간을 최소화할 수 있는 알고리즘 기법이다.
프로그래밍 분야에서 Dynamic은 프로그램이 실행되는 도중을 의미하는데, DP에서의 Dynamic은 프로그래밍을 실행하는 도중에 필요한 메모리를 활용(누적)한다는 의미에서 사용된다.
- 완전탐색을 통한 방안이 복잡하고 그로인한 계산이 불필요하게 반복될때, DP를 활용하면 획기적으로 시간복잡도를 줄일 수 있다.
- DP를 적용하는 방식은 Topdown(하향식), Bottomup(상향식)으로 크게 두가지가 존재한다.
동적계획법을 적용하기전에 주어진 상황이 적용하기에 알맞은지 먼저 판단해본다.
- optimal substructure : 최적부분구조, 큰 문제를 작은 문제로 나눌 수 있고 작은 문제들의 solution을 활용 및 누적하여 큰 문제를 해결할 수 있다.
- overlapping subproblem : 부분문제의 반복, 작은 문제가 동일하게 반복 및 중첩되면 다시 계산하지 않고 호출해서 그대로 사용할 수 있다.
이때 유의해야할 점은
※ memoization을 이전에 계산된 결과를 일시적으로 저장하고 활용한다는 개념으로, 이 개념자체가 DP에 국한된 개념은 아니다(다만 활용시 시간복잡도 O(N)으로 최적).
※ DP를 적용하되 memoization을 지속적으로 활용하지 않는 방안으로 구현할 수 있다.
※ 결과를 저장하는 별도의 배열(리스트)이 존재하며, 이를 DP table이라 일컫는다.
1-1. 피보나치 수열
인접항들간의 특정 관계식(점화식)을 이용하여 특정 항을 도출할 수 있는 수열을 의미한다.
피보나치 수열은 DP를 활용하여 결과를 도출할 수 있다는 점에서 짚고 넘어갈 필요가 있다.
- 단순재귀 : 단순하게 재귀함수를 이용하여 선형적으로 해결하는 방식(O(2^N))
- 하향식 : solution의 관점을 f(N)에서 출발하여, f(N-1),, 방식으로 분할하면서 각각의 하위 element를 구하는 과정에 초점을 두는 방식
※ 알고리즘 자체는 상향식 풀이로 느껴질 수는 있지만, 문제를 접근하는 과정을 본다면 하향식이다. - 상향식 : f(1), f(2), ..의 값을 차례로 저장하면서 최종적으로 f(N)의 값을 도출하는 방식
※ 문제를 접근하고 해결하는 과정이 아래에서 위로 올라가는 상향식이다.
1-2. 상향식 관점에서의 접근
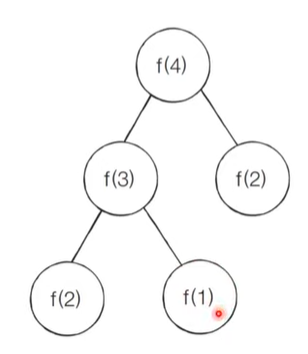
말 그대로 element의 최상단부터 접근한다.
dpTable = [0] * 100
def fibo(x):
if x==1 or x==2:
return 1
if dpTable[x] != 0: #이미 계산한적이 있는 문제
return dpTable[x]
dpTable[x] = fibo(x-1) + fibo(x-2)
return dpTable[x]
print(fibo(99))1-3. 하향식 관점에서의 접근
말 그대로 최하단 element부터 순차적으로 저장 및 접근한다.
dpTable = [0] * 100
dpTable[1] = 1
dpTable[2] = 1
n = 99
for i in range(3, n+1):
dpTable[i] = dpTable[i-1] + dpTable[i-2]
print(dpTable[n])2. 분할정복과의 비교
분할정복은 문제를 특정 기준(pivot)에 의해 부분화 한 후, 각 부분의 solution을 도출하여 해결하는 과정을 의미한다.
큰 문제를 작은 문제로 분할한다는 관점은 DP와 비슷하지만, 작은 문제의 solution이 반복적으로 활용되지 않는다는 점에서 DP와 다르다.
이때 작은 문제의 solution이 반복적으로 활용되지 않는다는 점은 말 그대로 동일한 solution의 반복활용을 의미하며, 분할정복은 substructure의 solution이 동일하게 활용되지는 않는다는 점에 유의한다.
- DP : 부분문제가 반복적으로 사용된다.
- 분할정복 : 동일한 부분문제가 반복적으로 계산되지는 않는다.
퀵정렬을 살펴보면 이해가 조금 더 용이할 수 있는데, 퀵정렬에서의 pivot 값은 고정되어있지 않고 항상 바뀐다.
보통 중간값, pivot값을 분할정복에서 최적의 해로 가정하면서 알고리즘을 구현하기 때문에 이러한 관점에서 본다면 DP와 다르다는 것을 알 수 있다.
3. 어떠한 알고리즘을 활용하는 것이 좋을까
많은 알고리즘을 구현해보면서 문제 및 상황을 빠르게 인지하는 능력을 함양해야 한다.
즉 다시 말해 많은 문제상황을 접하면서, 알고리즘을 생각해내는 연습을 많이 해봐야 한다.
- 어떠한 알고리즘을 활용할 수 있을지
→ 그리디, 완전탐색 or 시뮬레이션, 분할정복 - 위 알고리즘에서 적용할 부분이 없다면 DP를 적용할 수 있는 아이디어를 떠올릴 수는 있는데, 이를 너무 이분법적으로만 생각하지는 말자.
→ 위 알고리즘에서 memoization을 통해 개선된 알고리즘을 적용할 수 있다.
→ 작은 solution이 여러번 활용된다면 그때 memoization을 통한 DP를 활용할 수 있다. - 그러나 보통은 인접항 및 노드 간의 관계가 명확하다면(=점화식의 관계), 바로 DP를 적용한다면 간결하게 solution을 도출할 수 있다.
4. 알고리즘 구현
4-1. 비연속적인 노드의 최대 합
개미전사는 부족한 식량을 조달받기 위해 일렬로 나열된 창고에 접근하고자 한다.
나열된 창고에서 서로 인접한(연속된) 창고에서 조달하지 않고, 최소한 한 칸 이상 떨어진 창고들로부터 식량을 조달받고자 한다.
위 조건을 만족하면서 개미전사가 얻을 수 있는 최대식량을 구하는 알고리즘은 무엇인가?
첫번째 줄에는 식량창고의 수인 N, 두번째 줄에는 각 창고에 저장된 식량의 개수가 배열로 주어진다.
- step 1
N=4 일때 구할 수 있는 경우의 수는 아래와 같고, 이에 따라 최적의 해는 8이 도출된다.

- step 2
위 과정을 통해 solution을 도출하기위한 핵심은 아래와 같다.
- i번째까지 최적의 해를 구하였다고 했을때, 해당 해는 다음 최적의 해를 사용하는데 그대로 활용된다.
→ optimal substructure - i번째까지의 최적의 해는 반복적으로 사용할 수 있다.
→ overlapping subproblem - 인접노드 간의 관계가 명확한 편이다.
- 점화식을 도출할 수 있다.
최종적으로 위 문제를 해결하기 위한 핵심적인 점화식을 도출할 수 있다.
-
ai = max(ai-1, ai-2 + ki)
※ 즉, 현재 식량과 i-2번째 최적의 해를 더한 값 및 i-1번째 최적의 해를 더한 값 중 최소값
※ ai = max((ki + ai-1),(ki + ai-2))의 점화식은 인접하지 않은 조건을 고려하지 않은 경우이다. -
ai는 i번째 식량창고까지 최적의 해
-
ki는 i번째 식량창고에 담겨있는 식량의 양
-
불연속적인 노드들을 선택해야하는 조건 상, i-1번째 혹은 i-2번째까지 도출한 값들 중 가장 최적의 해(본 문제에서는 최대값)를 도출한 후 현 식량의 양을 더한다.
※이때 ai-1 + ki는 연속된 두 창고에 저장된 식량의 양이 아니라, i-1번째 창고까지 도출할 수 있는 최적의 해이다.
import sys
N = int(input())
array = list(map(int, sys.stdin.readline().split()))
d = [0] * 100
#bottomup
#dpTable 부터 bottom up 시작되고, 식량의 양이 아닌 최종 결과임을 기억.
#0은 최초값, 1은 0과 1중에 큰 값을 선택하면 된다.
d[0] = array[0]
d[1] = max(array[0], array[1])
#이전에 도출한 최적의 해는 이후에도 그대로 적용된다.
for i in range(2, N):
d[i] = max(d[i-1], d[i-2] + array[i])
#d[i] = max((d[i - 1] + array[i]),(d[i-2] + array[i]))
print(d[i])4-2. 숫자 1 만들기
정수 X가 주어졌을 떄 정수X에 사용할 수 있는 연산은 다음과 같이 4가지가 존재한다.
- X가 5로 나누어 떨어지면 5로 나눈다.
- X가 3으로 나누어 떨어지면 3으로 나눈다.
- X가 2로 나누어 떨어지면 2로 나눈다.
- X 에서 1을 뺀다.
위 연산 4가지를 적절히 활용하여 1을 만들고자 할 때, 연산을 사용하는 횟수의 최소값은?
※ 단순히 greedy(나누기 기준)를 적용할 수는 없다.
※ 2/3/5를 나누는 과정을 적절히 섞어서 적용해야 하는데, 점화식으로 설정할 수 있다.
※ 적절히 섞어서 사용하는 과정을 점화식으로 표현할 수 있다.
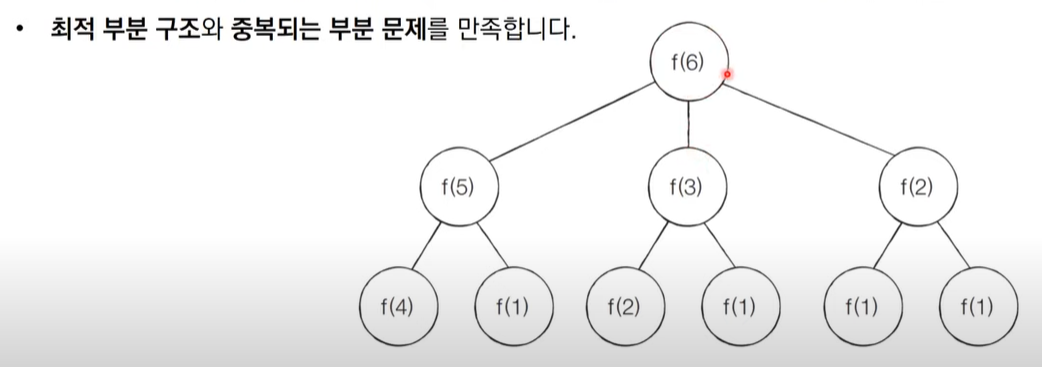
연산의 경우가 "적절히" 나눠지는 경우 및 특정기준을 적용하기 어려운 경우(greedy), 이전의 최적의 해에 누적되는 점화식을 설정할 수 있다.
위 과정에 대한 아이디어를 떠올리는 것이 핵심.
- f(N) = min(f(N//2)+f(N//3)+f(N//5)+f(N-1)) + 1
- 단 f(N)은 N에 대한 optimal solution
X = int(input())
d = [0] * 30001
#0과 1에 대한 해는 연산 과정이 없으므로 0으로 설정
for i in range(2, X+1):
#2,3,5로 나누어 떨어지는 경우
#각 숫자를 나눈 경우, 특히 나누는 수가 여러개가 적용될 수 있는 경우
#각 경우의 수마다 최적의 해(최소값)를 교체하는 조건식을 작성
#위 과정에서 핵심은 나누는 수가 여러번 가능할때
#나누면서 최적의 해(최소값)을 교체하는 과정인 점이다.
if i%2 == 0:
d[i] = min(d[i], d[i//2] + 1)
if i%3 == 0:
d[i] = min(d[i], d[i//3] + 1)
if i%5 == 0:
d[i] = min(d[i], d[i//5] + 1)
#나누어 떨어지지 않는다면
d[i] = d[i-1] + 1
print(d[X])4-3. 필요한 화폐의 개수
N가지 종류의 화폐가 있다.
화폐의 개수를 최소한으로 이용해서 그 가치의 합이 M원이 되도록 구성하고자 한다.
M원을 만들기 위한 최소 화폐의 개수는?
이 과정을 이해하면 위의 과정을 이해하는데도 더 수월하게 느껴질 수 있다.
화폐단위개수가 3이고, 각 단위가 2 3 5라 가정하자.
7원을 만든다고 가정할때, 아래와 같은 과정을 통해 알고리즘 구현 아이디어를 떠올릴 수 있다.
먼저 최소 단위인 1원이 최대 10000원을 만드는데 10000개가 필요하므로, 10000을 최대값(INF, 해당 값을 구현하는게 불가능한 경우)으로 설정할 수 있다.
- step 1
2원만을 사용할 경우
2원은 0원에 +2원을 더하여 만들 수 있으므로 1가지의 경우가 나온다.
마찬가지로 4원은 2원에 2원을 더하여 만들 수 있고, 이는 2의 경우에 +1을 하여 도출할 수 있다.
마찬가지로 6원은 4원에 2원을 더하여 만들 수 있고, 이는 2의 경우에 +1을 하여 도출할 수 있다.
최종적으로 7원은 만들 수 있는 경우가 없으므로(2원을 사용해서), 가능한 경우가 INF가 된다.
여기서 점화식 관점에서 살펴보았을때, 7(최종 목표)-2(화폐 단위)에 대한 경우가 존재하지 않으므로 그대로 INF의 경우의 수가 도출된다.
다만 7원은 4원에 3원을 더하여 만들 수 있고, 이는 4의 경우에 +1을 하여 도출할 수 있다.
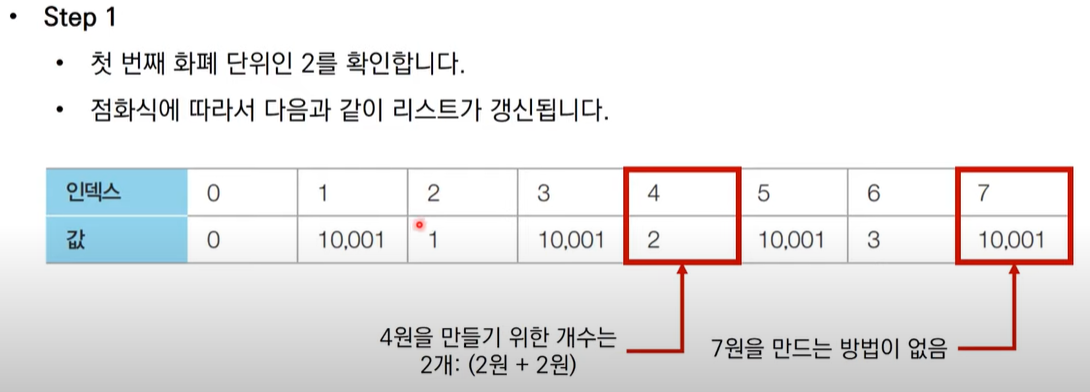
- step 2
3원의 경우의 수를 추가하여 2원/3원을 사용할 경우
위와 마찬가지 과정을 통해 3원의 경우의 수에 1을 추가,
특히 기억! 7-3을 한 경우의 수에 그대로 +3을 해주면 7이 도출되므로 4가 나오는 경우의 수에 +1을 해준다면 그것이 그대로 결과값이 된다.
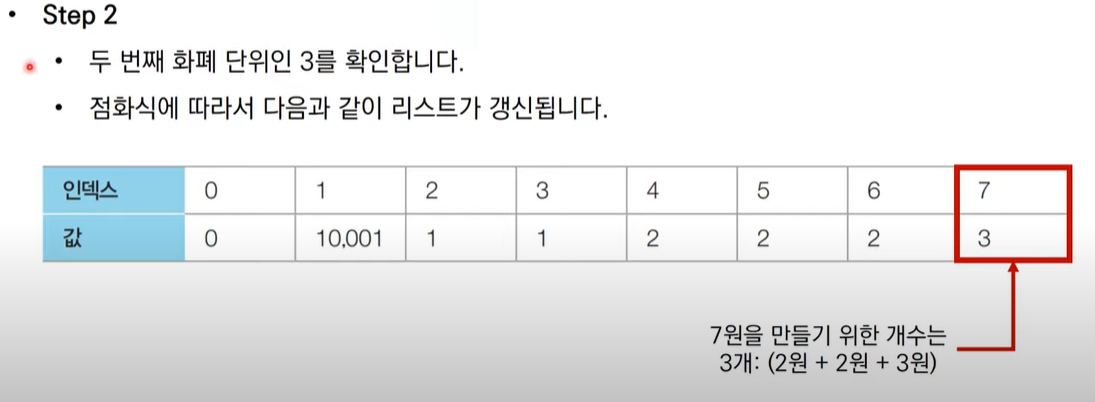
- step 3
5원을 추가로 고려하였을때, 2원에서 5원을 더하면 나오는데
이때 기존 도출한 결과값과 비교하여 최소값을 결과값으로 바꾸면 된다.
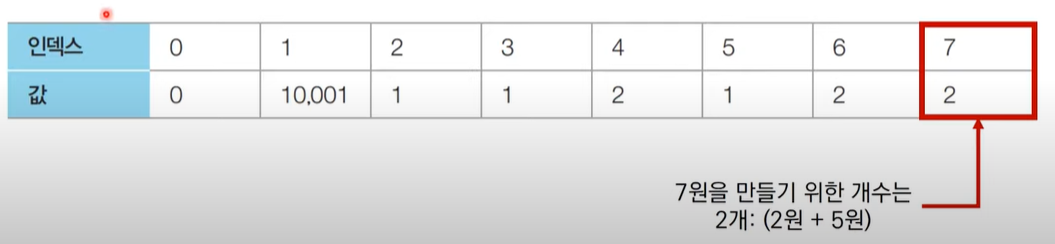
- 최종 점화식
ai = min(ai, ai-k+1) (단 k는 화폐단위)
이를 활용하여 알고리즘을 구성할 수 있다.
#첫째줄에 N, M이 주어진다
#N개의 줄에는 화폐의 가치가 주어진다.
#"적절한", "여러가지 종류"를 이용하여 최적의 해를 구하는 방법
#전형적인 DP, bottom up
##ai는 금액 a원을 만드는데 필요한 최소한의 화폐 개수(최적의 해)
##DP연산에서 나오는 최적의 해처럼
##INF = 10001
import sys
n, m = map(int, sys.stdin.readline().split())
#n줄의 화폐 정보를 입력받을때
currency = [int(sys.stdin.readline().strip()) for i in range(n)]
d = [10001] * (m+1)
d[0] = 0
#n개의 화폐 정보
for i in range(n):
#화폐금액
for j in range(currency[i], m+1):
#최소 화폐단위부터 m원까지 가능한 경우의 수를
#bottom up으로 계산한다.
print(j)
if d[j-currency[i]] != 10001:
d[j] = min(d[j], d[j-currency[i]]+1)
if d[m] == 10001:
print -1
else:
print(d[m])4-4. 금광
nm 크기의 금광이 있고, 각 11크기의 칸으로 나뉘어져 있다.
각 칸 별로 특정 개수의 금광이 들어있다.
채굴자는 첫번째 열부터 금을 캐되 시작 행은 정할 수 있다.
특정 행에서 출발하여 m-1번에 거쳐 오른쪽위, 오른쪽, 오른쪽 아래 중 하나로 이동이 가능하다.
채굴자가 얻을 수 있는 금의 최대 크기는 구하는 알고리즘은?
- 이는 모든 노드에 대한 경우의 수를 고려하는 것도 아니고 최단경로를 구하는 것도 아니다.
- 일전 인접하지 않은 식량창고 유형과 상당히 비슷한데, 일전 최적의 해에 무엇인가 누적할 수 있을 방안으로 구하면 될 것 같다는 아이디어가 핵심.
첫째줄에 테스트 케이스 T가 입력된다.
매 테스트 케이스 첫째 줄에 n m이 공백으로 구분되어 입력된다.
둘째 줄에 n*m의 위치에 매장된 금의 개수가 공백으로 구분되어 입력된다.

※ 테스트 케이스를 입력하는 것 또한 관건
테스트 케이스마다 금의 최대 크기를 출력하도록 구성한다.
- 모든 위치에 대하여 이동할 수 있는 경우의 수는 3가지이다.
- 이때 bfs인가 생각할 수도 있겠지만, 결국 금의 최대 개수(최적화 해)를 갱신하는 것이 관건.
- 각 케이스 별 가능한 경우의 수마다 금의 최대 개수를 바꾼다 -> 점화식 이용.
점화식을 구성하는 것에 대한 아이디어 구상 과정을 살펴보자.
- 지금까지 구한 최대의 해 교체, 최적의 해
- d[i][j] = array[i][j] + max(dp[i-1][j-1], dp[i+1][j-1], dp[i][j-1])
단 각 경우의 수마다 인덱스가 범위 내인지 체크, 다만 마찬가지로 이동 가능한 경우 모두 고려한다(이동경로를 모두 고려해야한다는 관점에 한해서만 bfs).
import sys
for tc in range(int(input())):
n, m = map(int, sys.stdin.readline().split())
array = list(map(int, sys.stdin.readline().split()))
dp = []
index = 0
#입력받은 후 2차원 dp table 초기화
for i in range(n):
dp.append(array[index:index+m])
# 0부터 m까지 단위로 열이 분할됨
# 열이 분할되는 순간 행이 바뀌는 반복문을 구현한 것
index = index + m
#DP진행, 열을 하나씩 이동하면서 최대값 도출
for j in range(1, m):
for i in range(n):
#왼쪽 위에서 오는 경우(범위도 확인) 이전 경로의 값
if i == 0: left_up = 0 #0번째 행
else: left_up = dp[i-1][j-1]
#왼쪽 아래에서 오는 경우(범위도 확인) 이전 경로의 값
if i == n-1: left_down = 0
else: left_down = dp[i+1][j-1]
#왼쪽에서 오는 경우 이전 경로의 값
left = dp[i][j-1]
#이전 경로의 값은 이미 최대값이 반영된 상태
#그 중에서 최대값을 선택해서 반영하면 됨
dp[i][j] = dp[i][j] + max(left_up, left_down, left)
result = 0
#결과는 가장 오른쪽 "열"에 모두 적혀져 있다.
for i in range(n):
result = max(result, dp[i][m-1])
print(result)4-5. 병사배치하기
N명의 병사가 무작위로 나열되어 있다.
병사를 배치할 때는 전투력이 내림차순으로 배치하고자 한다.
무작위로 나열되어있는 상태에서 병사들을 열외시켜 내림차순 배열을 구현하고자 할때, 병사수가 최대로 남게하는 방안은?
- 첫째줄에 N(병사수)이 주어지고, 둘째줄에 공백을 기준으로 전투력이 나열된다.
- 첫째줄에 남아있는 병사수가 최대로 남아있도록 열외시켜야하는 병사의 수
DP를 통해 최적의 해를 도출하는 과정 중 LIS 수열을 적용하면 된다.
- LIS : Longest Increasing Subsequence, 오름차순수열의 길이를 최대로 유지하면서 부분적으로 감소하는 수열을 제거하는 알고리즘
본 문제 역시 가장 긴 길이의 내림차순 수열을 구현하는 유형이고, LIS를 오름차순적으로 구성하면 된다.
먼저 LIS의 과정을 이해해보자.
- step 1
LIS의 점화식은 아래와 같다.
※ 부분수열의 최대 길이에서 특정 인덱스(i)를 더하면 길이가 1이 더해지므로, D[j] + 1이된다.
※ 단 모든 j에 대해 비교하면서 D[i]의 최종적인 값을 최적으로(최대로) 교체하는 것이 중요하므로, D[i]와 비교하여 max값을 취하도록 설정한다.

- step 2
출발점이 i = 0일 경우
각 원소(자기 자신) 하나를 취하는 부분 수열들을 최초 선언했다고 가정한다(이때 초기상태의 길이는 모두 1).

- step 3
출발점이 i = 1일 경우
비교대상인 i=0(4)와 비교하여 점화식에 따라 LIS가 그대로 유지된다.
- step 4
출발점이 i = 2일 경우
비교대상인 i=0를 최초 비교하였을때 점화식에 따라 1(node2)+1 = 2가 되고, i=1과 비교하면서 역시 LIS가 2로 전환된다(다만 두 값의 최대값은 2이므로 2로 유지).
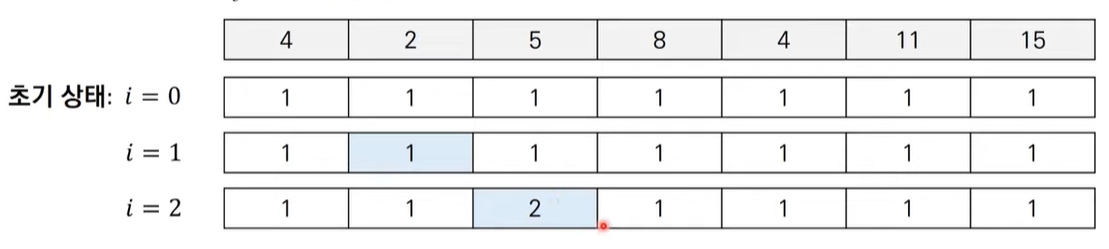
- step 5
위 과정을 반복하면서 i가 마지막 인덱스까지 도달할때 LIS를 구성해주면 된다.
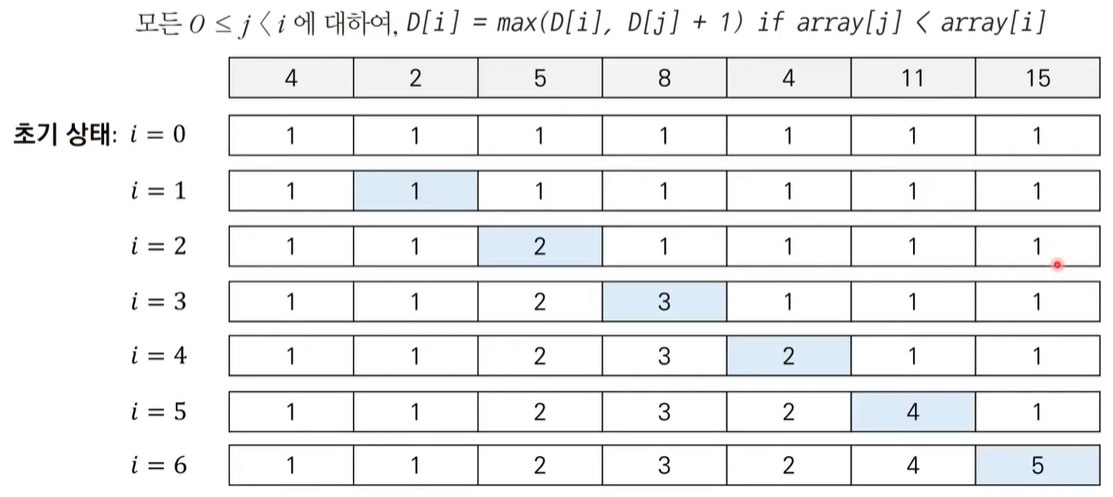
각 인덱스에 해당하는 값은 각 인덱스까지 오름차순을 구현하였을때 생성될 수 있는 수열의 최대길이이다.
이를 내림차순으로 적용하면되는데, 굳이 알고리즘을 바꿀 필요는 없고 병사 정보의 순서를 뒤집어서 오름차순 배열을 그대로 사용하면 된다.
#오름차순에서 부분적으로 감소하는 수열을 제거하는 LIS 알고리즘을 적용하는 전형
#D[i]는 array[i]를 마지막 원소를 가지는 부분수열의 최대 길이라 할 때
#점화식은 D[i] = max(D[i], D[j]+1) (단, j<i이고 array[j] < array[i])
#D[j]까지의 최적의 해에 i가 추가되면 길이가 1이 늘어나므로 +1을 한 것.
#기존의 LIS는 오름차순정렬이고, 본 문제에서는 이를 내림차순으로 적용하면 된다.
import sys
N = int(input())
array = list(map(int, sys.stdin.readline().split()))
array.reverse()
dp = [1]*N
#DP를 적용하여 LIS구현
for i in range(1, N):
#이중반복으로 비교대상 순회
for j in range(0, i):
#오름차순 정렬을 만족하였을때 점화식 적용
#비교대상 array[j]는 항상 순회하고 바뀌다는 것에 유의
if array[j] < array[i]:
dp[i] = max(dp[i], dp[j]+1) #dp[i]는 최적의 해를 구하는 과정으로 순회하면서 바뀔 수 있음
#열외해야하는 병사의 최소 수
print(N-max(dp))5. 참고자료
이코테 DP강의
https://www.youtube.com/watch?v=5Lu34WIx2Us&list=PLRx0vPvlEmdAghTr5mXQxGpHjWqSz0dgC&index=6

1-2, 1-3가 반대로된거아닌가요?