1. 개요
지금까지 Devops, Docker, MSA 등 여러 프로젝트를 진행하면서 느낀점은 내가 과연 로그 활용을 잘 하고 있다고 단언할 수 있을까하는 생각이었다.
아무 생각없이 도커 컨테이너의 docker log를 확인하거나, 디버깅을 하거나, 디버깅을 할때도 slf4j를 이용하여 문제점이 예상되는 지점에서 로그를 확인하는 등..로깅을 하는 방식을 단순히 시스템에서 내뱉는 메시지를 확인하는 용도로 사용하고 있다는 생각이 들었다.
시스템과 상호작용, 단순히 API나 인터페이스의 개념이 아니라 시스템의 상태를 확인하고 동작이 잘 이루어지는지 확인할 수 있는 가장 간단하면서 강력한 도구가 Logging이지만, 단순히 level을 INFO, DEBUG로 바꿔가면서 log를 확인하는 요소로, 매우 단편적으로 생각하고 있는건 아닌가라는 생각이 들었다.
로그는 시스템이 내뱉는 단순한 메시지가 아닌, 장애해결을 위한 가장 기본적이고 강력한 도구이다.
심지어 로그 관리를 위한 시스템 모델링이 별도로 이루어지기도 하고, 영속화하여 관리하든 로그 파일을 통해 관리하든 그 형태에 구애받지 않고 어찌되었든 main 시스템에서 별도로 반드시 고려되어야 하는 중요한 요소인것이고, 프로젝트를 진행하면서 새삼 느끼게 되었던 것 같다.
이러한 부분들에 대해 일관성있는 로그 메시지 구축, 로그를 사용하는 방법, 나아가 그 "체계" 등 장애를 관리하고 시스템을 더욱 안정성있게 운용할 수 있는 방안에 대해 알아보고자 이 글을 작성하게 되었다.
정말, 말 그대로 바닥부터 마음을 다잡으면서 분석하고 기록해보고자 한다.
2. logging에 임하는 자세 - what, where, why
개발, QA, Producing 환경이든, 시스템에 장애가 발생하였을때 가장 먼저 확인해야 하는 것은 바로 로그이다.
로그는 위에서 기술하였듯이, 단순히 시스템이 내뱉는 메시지가 아닌, 장애가 발생하였을때 무슨 문제가(What), 어디서(Where), 왜(Why) 발생하였는지 바로 알 수 있게 해주는 가장 기본적이면서도 강력한 모니터링 장치라 할 수 있다.
이러한 로그는, 생각보다 다양한 데이터들을 출력할 수 있고, 나아가 기능 동작의 과정, Exception, 실행 소요시간 등, 사실상 출력 메시지 이상의 의미를 지닌다.
따라서, 이러한 로그를 문제가 발생하거나, 발생할 것 같은 지점에 아무 생각없이 단순히 데이터 로그를 출력하는 용도로 사용하는 것은 분명 개발자로서 부적절하게 사용하고 있다고 볼 수 있겠다.
문제가 발생할 수 있는 예상 지점에 로그를 남겨두는 것이 좋은 접근법은 될 수 있겠지만, 로그를 단순히 이러한 자신만이 알아볼 수 있는 메시지 출력을 위한 접근을 하면 곤란하다는 의미이다.
운용(유지보수) 환경에서 로그와 모니터링 도구를 연동하여 관리할 수 있고, 별도의 message 패턴을 만들어 기록할 수도 있고, 장애 시 복구를 위한 체크포인트 등 수많은 활용 방안이 존재한다.
- 검색엔진으로, 대규모로 쌓인 로그 데이터 속에서 원하는 에러 메시지 및 기록을 찾기 위해 사용하는 ElasticSearch,
- 위 ElasticSearch에 보관된 로그 데이터를 편리하게 검색하고, 차트 및 통계 화면으로 시각화하여 분석할 수 있는 Kibana,
- 특정 엔드포인트 호출 시 리소스, latency, 호출횟수, 에러발생횟수 등 다양한 자원 정보 및 로그 데이터를 수집하여(Metric) 별도의 서버에 저장하는 OpenTelemetry 프레임워크인 Prometheus,
- 메트릭으로 수집한 데이터를 시각화하는 Grafana 등,
장애가 발생하였을때 대응할 수 있도록, 나아가 시스템을 안정적으로 운용할 수 있도록 기본적인 도구, 체계로 활용할 수 있는 것이 바로 로그이다.
단순 로그 출력을 위해 slf4j를 사용한다면, 시간이 지나서 로그가 많이 쌓일수록 알아볼 수 있는 것은 그것을 의도한 개발자뿐, 아무도 모른다.
이러한 마음가짐을 바탕으로 로그를 다시 바라보고, 어떠한 것을 로그 데이터로 활용해야 하는지, 로그를 개발자답게 활용하기 위한 접근 방법을 좀 더 깊게 알아보고 파악해보고자 한다.
참고. OpenTelemetry
현대시대의 계측표준은 단순 추적이 아닌, 데이터 수집까지 포함하는 것이 표준이 되었다.
이러한 통합 계측을 하나의 패러다임으로 전환해준 것이 CNCF(Cloud Native Computing Foundation)의 OpenTelemetry이다.
OpenTelemetry는 이러한 통합 관측의 개념이 아니라, CNCF 재단이 만든, 특정 벤더에 종속되지 않고 데이터를 추적, 수집하는 통합 계측/수집 프레임워크이자 도구이다.
SDK(Software Development Kit)은 다양한 언어로 제공되어, 각 언어에서 사용할 수 있는 계측 API를 또한 제공한다.
OTel은 말 그대로 Open의 성격을 지니기때문에 특정 벤더나 기술에 종속적이지 않고, OTel 명세에 따르지 않는 데이터도 수집/계측할 수 있는 어댑터와 같은 역할을 한다.
좀 더 쉽게 말하자면, OTel 이전에는
앱 → Prometheus exporter → Prometheus
앱 → Fluent Bit → Elasticsearch
앱 → Jaeger agent → Jaeger backend각 계측 정보를 수집하기 위해, 목적에 맞게 혹은 형태에 맞게 각기 다른 벤더사, 도구를 사용하고 이에 대한 SDK나 Receiver, Exporter 등을 모두 따로 붙여야 하였다(쉽게 말하면 의존성을 각기 다르게 추가해주어야 했다).
Prometheus → metrics 수집
Fluent Bit → logs 수집
Jaeger → tracing 수집프로메테우스의 메트릭 수집, Fluent Bit의 logs 수집, Jaeger의 tracing 수집 등 이 collector들은 데이터 수집과 계측의 목적이 모두 달랐기 때문에 각 구현체를 따로 사용해야 했다.
그러면서 수집 데이터의 정량적, 정성적 규모가 커졌을때 그만큼 수집 SDK를 따로 붙여야 하고 플러그인도 추가해주어야 했기에 관리가 복잡하고, 시스템도 그만큼 무거워졌다.
하지만 이러한 Collector들을 통합하여, Otel을 붙여주기만 하면 SDK/벤더 종속되어있던 기존 계측 데이터들을 통합적으로 수집하고 관리할 수 있게 되었고, 하나의 파이프라인으로 손쉽게 활용 가능하게 된 것이다.
Prometheus ┐
Jaeger ├→ OTel Collector → 원하는 backend
Logs ┘기존의 계측 Collector들은 OTel과 연동되어, 어댑터(Receiver/Exporter)를 제공하게 된 것이다.
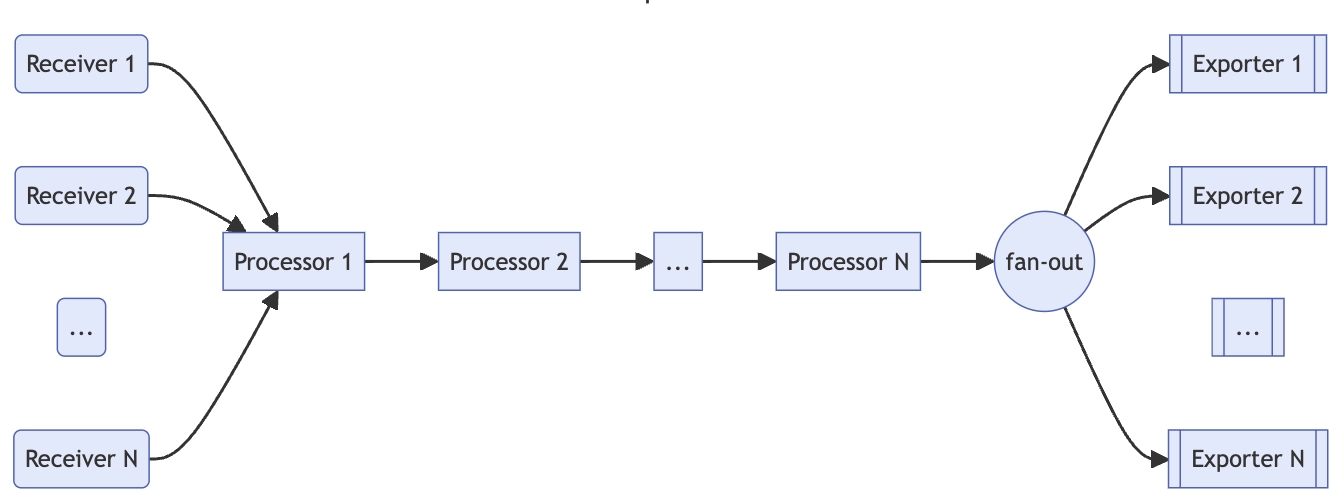
게다가,
OpenTelemetry는 내부적으로,
- Metrics
- Logs
- Traces
의 기존 Collector들이 제공한 계측 포맷을 수집할 수 있을 뿐만 아니라,
Otel 포맷에서 제공하는 데이터 뿐만 아니라, 다른 로그 데이터까지 같이 수집하여 전달할 수도 있다.
- Prometheus → Prometheus 포맷
- nginx 로그 → 텍스트 로그
- AWS → 자체 포맷
- Kafka → 이벤트 메시지
유의하도록 하자. OpenTelemetry은 통합된 수집, 계측의 과정을 제공하는 프레임워크이자 파이프라인이며, Prometheus는 그 표준에 연관되어, 통합된 파이프라인으로 제공하는 backend(구현체) 중 하나일 뿐이다.
3. log에 대한 고찰
표지에 "시스템과 가장 쉽고 강력하게 상호작용 할 수 있는 방법"을 logging이라 하였다.
시스템이 내뱉는 출력 결과가 아닌, 시스템에 문제가 생겼을때 어떤 문제가 어디서, 왜 발생하였는지 대화할 수 있는 창구로써 logging을 바로보고 이해해보도록 하자.
다만 모든 로직에 대해 로그를 남길 필요는 없다.
문제가 생겼을때 추적이 가능한 선에서 적절하게 남길 수 있는 방안이 필요하고, 그 목적과 형태에 맞게 활용할 수 있는 것이 필요하다.
로그의 형태란, 중요도 및 로그를 통해 추적, 파악하고자 하는 데이터 내역의 상세도에 따라 계층적으로 분류된다.
TRACE
가장 상세한 정보를 남기며, 로직이 한줄 한줄 실행해가는 과정을 일일이 남기는 정도의 수준으로 메시지를 제공한다.
로그 출력도 엄연한 I/O 비용이 소모되는 작업이기에, 무분별한 로그는 시스템 성능에 중대한 영향을 끼칠 수 있으므로 TRACE 로그는 개발 단계에서만 사용하고, 운영 단계에서는 사용하지 않는 것을 권장하고 있다.
DEBUG
디버그는 시스템의 예상치 못한 동작, 특히 오류가 발생하였을때 시스템의 작동 상태를 상세하게 파악하기 위한 목적으로 기록하는 로그이다.
개발환경에서 테스트를 위해 작동시키기 위한 부가적인 도구로, 기본적으로 시스템은 log레벨을 info를 기본으로 해두기에 debug로 레벨을 낮추고 작동상태를 파악해야 한다.
INFO
시스템의 정상 작동 상태에서 특징적인 부분, 백엔드 로직에서 받아오는 파라미터 등을 표기하기 위해 사용하는 로그 레벨이다.
문제가 발생하였을때, 시스템이 아닌 사용자의 잘못된 사용으로 인해 발생하는 오류에 대해서도 INFO를 통해, 사용자의 잘못된 사용 원인을 고지하는 방법으로 사용할 수 있다.
오픈소스, 운용환경에서도 유의미한 부분에 info 로직을 사용하여 해당 로직을 보았을때 흐름을 잘 파악할 수 있도록 도움을 주는 장치가 필요하다.
WARN
현재보다는, 이후의 트래픽이 늘어나거나 확장이 필요한 상황에서 문제의 소지가 있을 경우, 지금의 임시적인 대책이 향후 문제점으로 작용할 수 있는 경우에 이를 표시하기 위한 용도로 사용하는 로그이다.
말 그대로 경고의 의미로, 가령 지금은 latency가 정상적이지만 대규모 트래픽 상황에서 latency가 수 초 이상, 사용자가 체감할 수 있을 정도로 잠재적인 문제점이 될 경우, 혹은 불필요한 설정이 중복되거나 deprecated된 내용을 사용할 경우 log.warn을 사용할 수 있다.
2026-04-10T17:13:24.478+09:00 WARN 23976 --- [spring-boot-monitoring] [ main] org.hibernate.orm.deprecation : HHH90000025: MySQLDialect does not need to be specified explicitly using 'hibernate.dialect' (remove the property setting and it will be selected by default)보통 보완사항에 대해 알림을 주기 위한 용도로 사용한다.
ERROR/FATAL
시스템 중단이 발생할 정도로 치명적인 에러, 오류가 발생하였을때 사용하는 로그로, 장애 발생지점을 추적하고 언제, 어떤 이유로 발생하였는지 보여주기 위한 매우 중요한 단서이다.
더불어, 사용자의 잘못보다는 시스템의 구성, 서버 내부의 동작이 잘못되어 발생할 경우 사용하는 형태이다.
보통 Exception 분기에서 해당 오류에 대한 내용을 보여주기 위한 log.error 등으로 활용한다.
이러한 로그를 어떠한 방안, 어떠한 목적으로 사용할 수 있을지, 좀 더 구체적인 상황에 기반하여 살펴보도록 하자.
3-1. Debugging / Exception / Error
가장 많이 사용하는 방안은 역시 장애 발생 시 문제 대응을 위한 목적으로 활용하는 방식일 것이다.
Debugging 시, 문제 추적을 위한 정보 추출 및 시스템의 작동 현황 파악, 나아가 시스템에서 어떠한 예외나 Error를 발생하였는지, 상세한 정보를 추출하기 위해 로그를 사용할 수 있다.
3-2. Request/Response(EventPayload)
Kafka/RabbitMQ를 비롯한 외부 API 등을 사용할때 필수적으로 사용해야 하는 정보로, 사용자가 어떤 요청을 보냈고 어떠한 응답을 받았는지 외부 체계와의 송수신 기록을 남기는 방안이다.
이 방안에서 가장 중요한 목적은 요청/응답이 외부 체계 간 잘 동작하였는지, 특히 메시지 유실이 되어 일관성을 해치지는 않았는지 파악하는 것이다.
요청을 보냈는데, 오픈 API를 제공하는 외부 체계 측에 문의를 할 것인가?
불필요하고 번거로운 데이터 수집 비용, 커뮤니케이션 비용을 제거할 수 있는 필수적인 방안이다.
3-3. 감사/대규모 트래픽 모니터링
사용자의 행동 양상을 살펴보고, 그 트래픽 규모가 많아졌을때 모니터링할 수 있도록 tracing 경로의 관점에서 로깅을 진행할 수 있겠다.
이 시점에서는 Grafana, Prometheus 등 단순 문제 수집을 위한 제한적인 범위에서의 수집이 아닌, 전 사용자의 행동 양상을 분석하기 위해 모니터링 체계로 범위를 넓히는 단계로 볼 수 있겠다.
참고. log 내용 구성
hibernate ORM이 실행하면서 DB메타정보를 출력하는데, 여기서 출력하는 로그 메시지를 통해 log 내용이 어떻게 구성되어있는지 확인해보고자 한다.
2026-04-10T17:13:24.494+09:00 INFO 23976 --- [spring-boot-monitoring] [ main] org.hibernate.orm.connections.pooling : HHH10001005: Database info:
Database JDBC URL [undefined/unknown]
Database driver: undefined/unknown
Database dialect: MySQLDialect
Database version: 8.0
Default catalog/schema: unknown/unknown
Autocommit mode: undefined/unknown
Isolation level: NONE [default NONE]
JDBC fetch size: undefined/unknown
Pool: DataSourceConnectionProvider
Minimum pool size: undefined/unknown
Maximum pool size: undefined/unknown로그는 7가지의 정보로 이루어진다.
발생시간 : 2026-04-10T17:13:24.494+09:00
로그를 발생한, 로그를 생성한 시간이다. 시스템 동작이 언제 이루어졌는지 그 시점을 파악할 수 있는 중요한 단서이다.
로그레벨 : INFO
현재의 로그가 어떠한 형태인지, 어떠한 목적으로 보여주는 것인지 그 레벨을 보여준다.
보통의 프레임워크, 오픈소스에서 시스템 동작 상황이나 흐름, 현황을 보여주기 위해 많이 사용하는 형태이다.
PID : 23976
OS에서 해당 application을 실행하기 위해 할당한 프로세스의 ID를 나타낸다.
애플리케이션(project name) : [spring-boot-monitoring]
해당 애플리케이션의 이름을 나타내며, 기본적인 해당 로그를 실행한 프로젝트, 도메인 이름을 추출하여 이를 파악할 수 있다.
스레드명 : [ main]
해당 요청을 처리하기 위한 스레드명을 나타낸다. 보통 Main Application을 실행할때의 main thread, main thread 실행 후 이후 client 요청을 처리하기 위한 background thread가 존재한다.
[ 하나의 프로세스 (PID 23976) ]
|
├── main 스레드 (앱 시작)
├── GC 스레드
├── HTTP 요청 처리 스레드들
│ ├── http-nio-8080-exec-1
│ ├── http-nio-8080-exec-2
│ └── ...
└── 기타 백그라운드 스레드참고로, application 실행을 위한 main 스레드 외 GC, HTTP 요청 스레드 등 다양한 목적으로 실행하는 스레드들이 존재한다.
더불어, 기본적으로 Client가 다르다면 다른 스레드가 생성되어 그 요청을 처리할 것이기에, 다른 경로로 살펴보아야 할 것이다.
로그 발생 위치 : org.hibernate.orm.connections.pooling
로그를 발생한 구체적인 패키지 경로 및 클래스 명을 표기한다.
단순히 로그를 발생한 위치가 아니라, 에러를 발생한 위치를 특정할 수 있는 매우 중요한 단서이다.
로그 메시지 : HHH10001005: Database info:
이후 로그 메시지를 통해 어떠한 오류가 발생하였는지 그 내역에 대해 파악할 수 있다.
4. Slf4j
Slf4j는 Simple Logging Facade For Java의 축약어로, Java에서 사용할 수 있는 가장 간단하면서 편리한 로그 인터페이스이다.
이 인터페이스를 사용하여, System.out.println 등 단순히 메시지 출력을 사용하는 방법이 아니라 형태에 맞게 INFO, ERROR 등의 로그를 Application level에서 확인할 수 있다.
시스템 레벨에서의 로그는 장애가 발생한 지점을 추적하는 용도로 사용해볼 수 있을 것이다.

더불어, ResponseEntity 등을 활용하여 엔드 포인트 레벨에서 시스템과 상호작용하고, 시스템의 장애 발생 여부에 대해 파악할 수 있는 중요한 단서로 작용할 수 있을 것이다.
@GetMapping("/users/{userId}")
public ResponseEntity<UserResponse> readUser(@PathVariable("userId") Long userId){
log.info("[INFO] CHECKING REQUEST PARAM : {}", userId);
UserResponse userResponse = userService.readUser(userId);
return ResponseEntity.status(HttpStatus.OK).body(userResponse);
}이제, 로그를 바라보는 관점이 달라졌기 때문에, 시스템 레벨에서의 상호작용과 엔드포인트 레벨에서 보는 상호작용 모두 구분하면서,
장애가 발생한 지점, 장애를 유발한 원인, 장애가 왜 발생하였는지 파악할 수 있도록 적절하게 로그 체계, 요청 및 응답체계를 구성하도록 하자.
5. MdcLoggingFilter
로그를 수집하는데 있어 중요한 개념 중 하나가 traceId, spanId에 대한 개념이다.
분산 추적에 사용되는 개념이지만, 로그를 사용하면서 전체 시스템 흐름 및 내부적으로 호출되는 여러 서비스 및 데이터베이스 I/O 등을 구분하기 위해 충분히 활용할 수 있는 개념이기 때문이다.
TraceId는 하나의 요청을 처리하기 위해, 해당 처리를 완료할때까지 전체 워크플로우를 구분하는 Id값이다.
spanID는 전체 요청 중 내부적인 layer, 서비스 호출 및 DB I/O 등을 구분하고 식별하기 위한 Id 값이다.
이 중, Monolithic 구조에서는 EDA라는 특수한 상황이외에는 서비스들이 하나의 프로젝트에서 진행되기에, TraceId를 통해 이벤트를 추적 관리하는 전략을 취할 수 있겠다.
그 중 하나가 MdcLoggingFilter 전략인데, Spring Context에 진입하기 전에, Servlet Context의 filter에, 이 중 MDC에 traceId를 넣고, 이 식별Id를 기반으로 일관된 추적 흐름을 살펴볼 수 있는 것이다.
MdcLoggingFilter에 대한 자세한 구현 방안은 생략한다.
다만 중요한 것은 Filter의 실행 흐름 및 적용 시점인데,
Filter (MDC 넣음)
→ Controller 진입
→ Service 호출
→ @Transactional AOP 시작
→ DB 연결 시도 → 실패 mdc를 넣는 시점은 Servlet Context 측에서 filter를 실행하는 시점이며, 그 이후에 spring application이 아닌 다른, Hibernate나 JDBCDriver 등 MDC 컨텍스트를 사용하지 않는다면 mdc traceId를 공란으로 처리해버릴 수도 있다(적용하지 못했을 경우).
이 경우,

위와 같이 mdc 컨텍스트를 사용한 application 측의 info log는 trace id를 잘 출력하였으나, 에러를 발생시킨 hibernate 측의 error log는 trace id를 출력하지 못하였음을 확인할 수 있다.
따라서, 전체 프로세스를 application 내부적으로 동작하는 과정에서 살펴볼 경우 traceId는 매우 효과적인 방안이 될 수 있을 것이다. 그러나, RabbitMQ, Database, Kafka 등 외부 체계 및 별도 클래스/구현체를 사용하는 경우 traceId는 큰 효과를 기대하지 못할 수 있다.
다만, 이 경우 별도 모니터링 체계를 사용하여 보완할 수 있고, 동기기반의 Monolithic 체계에서는 동일한 스레드 ID만으로 충분히 추적, 메트릭 수집을 통한 모니터링이 충분할 수 있기에 적극적으로 활용해볼만한 전략임을 기억하자.
6. log의 영속화, 파일로 관리
로그는 실시간으로 동작 상태, 장애 상황을 파악할 수 있는 요소이지만, 동시에 결제내역/주문내역 등 상태를 저장하고 이를 복구하기 위한 중요한 자료로 활용될 수 있다.
따라서, 로그를 디스크에 저장하여 영속화하여, 로그 파일을 별도로 저장하는 관리 방식도 고려해볼 필요가 있겠다.
이를 위해 batch, 별도의 filter를 통해 파일로 저장하는 방법이 있을 수 있겠지만 이 중에서도 가장 간단한 방법으로 logback을 활용한 영속화가 있을 수 있겠다.
기존 logback을 활용한 traceId의 경우, appender의 목적지를 console로 지정하여 로그 메시지를 출력하는 것으로 끝냈지만, File로 지정하여 로그를 텍스트 파일로 특정 경로에 저장하는 방식을 사용할 수 있다.
참고로 실무에서는 RollingFileAppender를 활용하여, 특정 시간이 지남에 따라 다른 파일로 저장하는 방식으로 파일을 새롭게 생성해줄 수 있기도 한다.
자세한 구현 방안은 생략하도록 하며,
로그를 만들면서 해당 내용을 파일로 저장하고, 이후 문제가 발생하였을때 해당 내용을 추적하거나 당시 상황을 확인할 수 있는 중요한 전략으로 활용할 수 있을 것이다.
7. ELK
Monolithic, 분산 환경에서는 로그를 별도의 파일로 저장하여 관리하는데, TPS가 하루에 수천~수만개 정도로 운용되는 소규모의 환경이더라도 엄청난 양의 로그가 쌓이므로 단순 별도의 하드디스크보다는 서버에 저장하여, 집중적으로 운용하는 방안을 채택한다.
이 경우, 단순히 로그 파일을 샅샅이 탐색하고 파헤치면서 오류를 대응하는 방식에는 한계가 있기 때문에, 각 엔드포인트 호출 내역을 저장하는 로그를 단순 System print나 로그 파일을 통해 관리하는 것이 아닌, 별도의 서버에서 응집하여 관리한다.
이러한 로그 관리에 집중하는 특별한 관리 방식이자 체계를 ELK라고 한다.
로그를 관리하고 운용하는 서버에서 특징적으로 사용하는 기술 스택인 Elastic Search, LogStash, Kibana를 지칭하는 개념이며 각 목적과 역할에 맞게 모니터링 도구를 적절하게 사용하는 것이 중요하겠다.
이에 대해 자세하게 살펴보도록 하자.
7-1. ElasticSearch
ElasticSearch는 이러한 ELK(ElasticSearch, LogStash, Kibana)를 이루는 기술 중 하나로, 로그 데이터의 저장 및 검색에 활용하는 도구이다.
쉽게 말해, 방대한 로그 데이터를 저장하여 쉽게 검색할 수 있도록 해주는 데이터베이스 그 자체이다.
로그 파일은 하루에 엄청난 양으로 쌓이기에 관리가 상당히 어렵고 복잡한데, Elastic Search는 그 자체로 데이터베이스, 이러한 로그 데이터를 문서 및 Inverted Index 기반으로 엄청난 속도로 로그 데이터를 탐색하고 찾아낼 수 있는 기능을 지닌 데이터베이스(1억건을 0.1초에 찾는 수준)이다.
참고로 ElasticSearch는 로그 및 이벤트를 JSON 및 document 형식으로 저장하는 데이터베이스이며, Prometheus와 같이 데이터를 수집하고 내부적으로 붙여진 TSDB(시계열데이터베이스)에 저장하는 방식과는 동작 방식이 조금은 다르다. 특히 시간이나 숫자 관련한 데이터를 중심으로 저장하는데 최적화된(append only 방식) 저장 방식과 이를 promQL로 조회하는 Prometheus와는 달리, ElasticSearch는 이벤트/텍스트 기반의 로그 데이터를 탐색하는데 더 유리하다.
최근에는 Elastic Search도 시계열 데이터베이스를 지원하고 있기도 하기에, 데이터 형태 및 목적에 따라 명확하게 쓰임새를 구분하고 활용하는 전략이 필요하겠다.
7-2. LogStash
LogStash는 각 서버에서 로그데이터를 수집 및 정제하여, ElasticSearch에 전달해주는 도구이다.
참고로, Stash는 데이터를 잠시 저장해두는 과정을 의미하는 용어인데, logStash는 말 그대로 로그를 영속화된 저장소로 보내기전에 수집하고 정제하는 목적으로 잠시 저장해두는 임시 거처로 보면 되겠다.
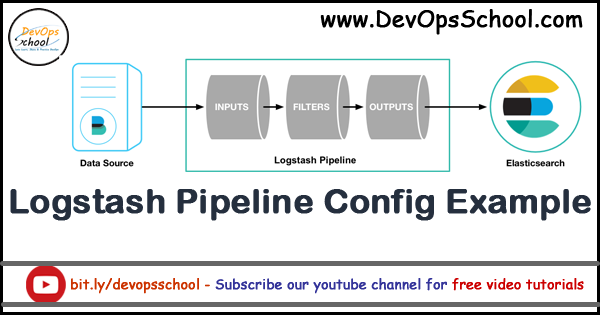
위와 같이, logStash는 정말 단순하게 말하면 내부적으로 log파일(datasource)의 입력(INPUT), 가공(FILTER), 전송(OUTPUT)으로 이루어진 전통적인 데이터 가공 및 정제 도구이다.
Jenkins처럼 파이프라인을 구성하여, 로그 수집을 자동화할 수 있기도 하다.
최근 들어서는 DataDog과 같이 SaaS 제품으로 출시되어, 서버 측에서 파이프라인을 구성하는 번거로운 과정을 진행하지 않아도 되고, OTEL을 지원하는 도구들을 활용하는 방식으로 실무에서 많이 활용하고 있긴 하다.
사실 ELK는 무겁고, 메모리를 많이 요하는 프로그램이며, 가격이 비싸기에 ELK를 통합적으로 사용한다기 보다는, Log Stash나 Elastich Search 등 필요한 부분만 부분적으로 활용하는 개념으로 접근 방법을 유연하게 택하고 있다(OTEL의 계측/수집/전달의 구현체를 부분적으로, 적절하게 사용하는 방식).
참고로 OTel은 Telemetry 데이터를 표현하고 전달하는 표준으로, ELK는 이를 통해 데이터를 저장하고 검색, 시각화하는 제품의 일종이다.
[ Application ]
↓
(계측)
→ Micrometer / OTEL SDK
↓
(수집/전달)
→ OpenTelemetry Collector
↓
(저장/분석)
→ ELK / Datadog / Prometheus / Grafana이 단계 중에 LogStash는 데이터를 수집하고 ElasticSearch에 보낸다는 점에서 OTEL의 Collector 성격을 지니고 있다고 말할 수 있다.
| Logstash | OTEL Collector |
|---|---|
| input | receiver |
| filter | processor |
| output | exporter |
다만, ELK는 하나의 통합된 기술 스택으로 총칭하는 것이 대부분이기에 로그 데이터를 저장하고 보여준다는 점에서 OTEL의 마지막 단계에 위치시키기도 한다.
7-3. Kibana
Kibana는 ElasticSearch에 저장된 데이터를 시각화해주는 모니터링 장치이다.
현재는 로그 데이터의 단순 시각화를 넘어, Elastic Stack 내의 데이터 탐색, 관리, 대시보드 기능을 제공하는 ELK 기술의 인터페이스로 자리잡게 되었다.
[ Application ]
↓
(OTEL SDK / Agent)
↓
(Collector 계층)
→ OTEL Collector
→ Logstash (대체 가능)
↓
(저장/분석)
→ Elasticsearch
↓
(시각화)
→ Kibana위와 같은 OTEL 과정에 대입해보면, application에서 보내는 로그 데이터를 최종적으로 저장, 분석한 이후 시각화, 관리, 탐색 등 다양한 대시보드의 기능을 제공해주는 도구이며, 일전에 Prometheus의 데이터를 시각화해주었던 Grafane와 같은 장치라 보면 되겠다.
7-4. ElasticSearch + LogStash
기본적으로 계측 데이터를 수집하고 확인하는 것부터 시작하고, 그 이후에 시각화 도구를 도입하는 것이 좋다.
계측의 기본은 적절한 SDK를 활용하여 데이터를 수집하는 것이고, 시각화에 매몰되어 데이터 계측의 기본을 잊어서는 안되겠다.
일단 LogStash를 통해 데이터를 계측하여, 계측한 데이터를 그대로 Elastic Search에 전송하는 파이프라인을 구축하고 이를 Elastic Search 서버에서 확인해보자.
이를 위해, logstash.conf에서 구성한 파이프라인을 기반으로 INPUT/OUTPUT 파이프라인을 생성한다.
# INPUT
input {
file {
path => "/usr/share/logstash/spring-boot-monitoring-log.log"
start_position => "begining"
stat_interval => 1
}
}
# FILTER
filter {
}
# OUTPUT
output {
elasticsearch {
hosts => ["http://elasticsearch:9200"]
index => "spring-boot-monitoring-logs-%{+YYYY.MM.dd}"
}
stdout { codec => rubydebug }
}위와 같이 구성한 파이프라인을 기반으로, 계측 데이터를 하드디스크에 볼륨 마운트해야 한다.
volumes:
- ./logs:/usr/share/logstash/logs
- ./logs/logstash/logstash.conf:/usr/share/logstash/pipeline/logstash.conf볼륨 마운트하는 구성은 위와 같이 로그 파일과, 파이프라인 환경에 대한 conf 파일 두가지이다.
이 사항을 확인한 후, docker compose 및 볼륨 마운트의 경로 동기화에 유의하면서 실행한다면,
docker compose -f docker-compose-elasticsearch-logstash.yml -pdocker-compose-elasticsearch-logstash-infra up -dElasticSearch의 서버에서 로그가 전달되었는지, 인덱스 생성 여부를 통해 확인할 수 있다.
인덱스를 생성하였는지 여부를 알기 위해
http://localhost:9200/_cat/indices?v의 api를 통해 확인하면 되고,
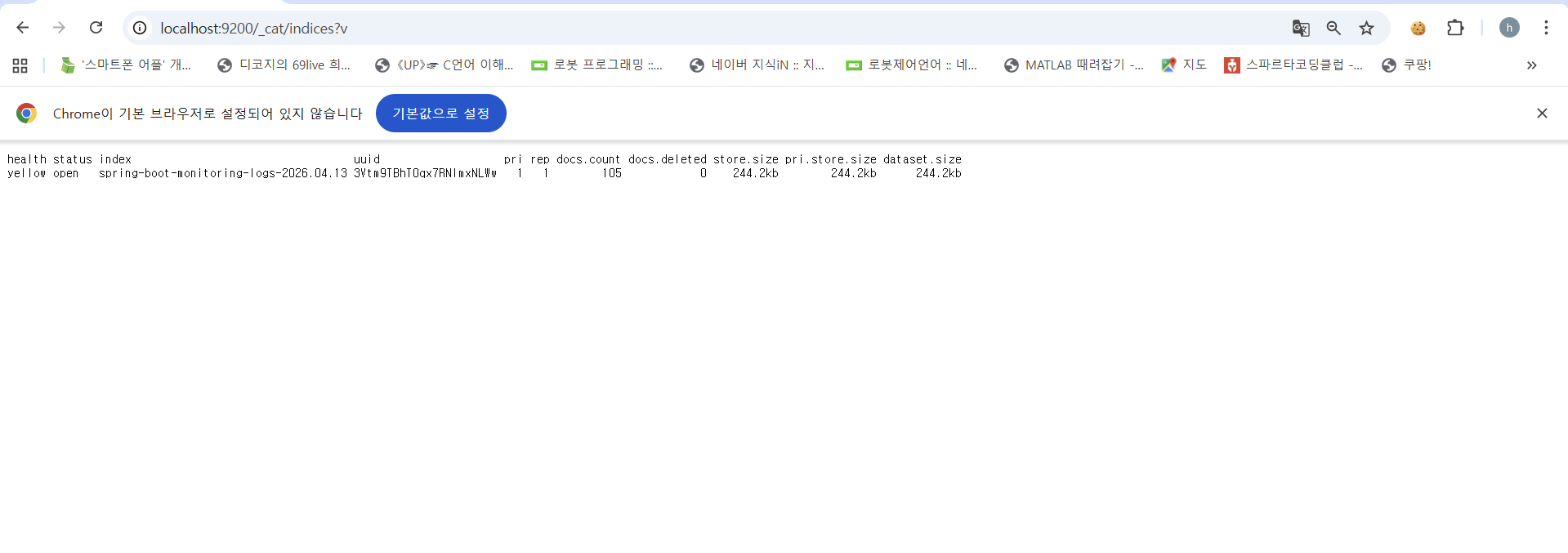
만약 정상적인 파이프라인이 구성되었다면, 위와 같이 logstash에서 구성한 인덱스가 정상적으로 생성되었음을 확인할 수 있겠다.
이 상태에서, 내부 로그 내용 중에 특정 메시지를 빠르게 검색하는 작업을 할 수 있게 된다.
http://localhost:9200/spring-boot-monitoring-logs-2026.04.13/_search?q=message:ERROR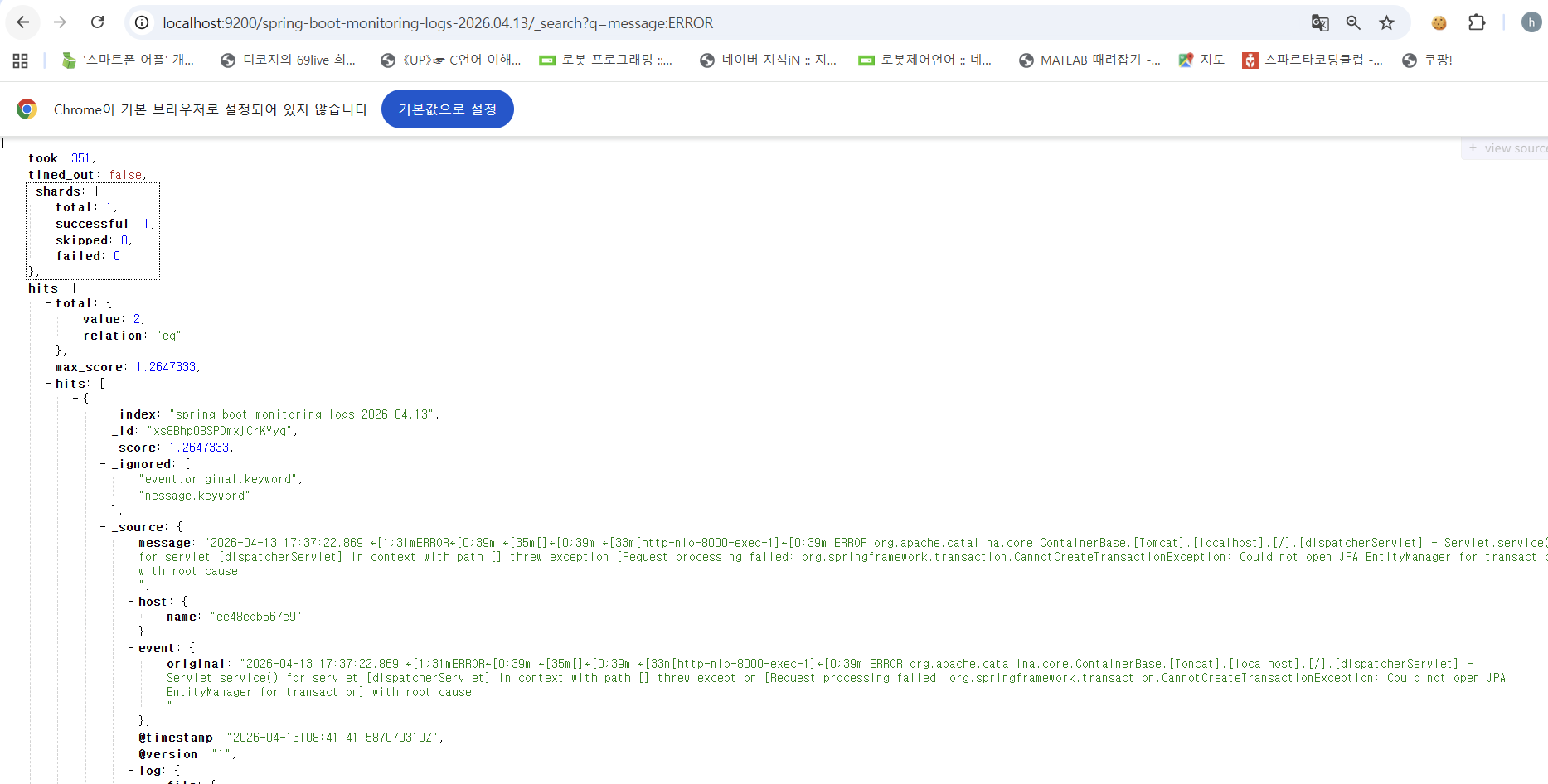
위 내역을 살펴보면 알 수 있듯이, 저장되는 로그는 JSON(Document) 형태로 저장이 된다(JSON 형태로 가공하는 것도 log stash 내부적으로 Filtering하는 과정에 포함).
이를 인덱스로 묶고, 내부적으로 로그 메시지(Event Original)를 자체적으로 가공하여 message text로 저장한다. 위에서 기술하였듯이, ElasticSearch는 자체적으로 DB는 아니고, DB가 붙어있는 형태이기에 해당 데이터를 조회해오는 방식으로 빠른 탐색이 가능한 것이다.
7-5. Kibana
사실 이를 통한 계측 및 수집은 가능한데, 이러면 Actuator와 다를 바가 없다. 정확히는, Actuator의 확장판이라고 해도 무방할 정도이다.
ELK의 꽃은 Kibana까지 이어지는 시각화, 대시보드를 통한 간편한 데이터 확인이라 할 수 있는데, api를 통해 쿼리를 보내고 실행하는 과정을 Kibana를 통해 간편화, 편의화할 수 있는 것이다.
자세한 도커 컴포즈 과정은 생략하며, ElasticSearch, logStash, Kibana의 파이프라인 및 버전 동기화에 유의하면서 환경을 구성하도록 한다.
이후,

Discovery를 통해 filtered 된 message를 확인하거나,
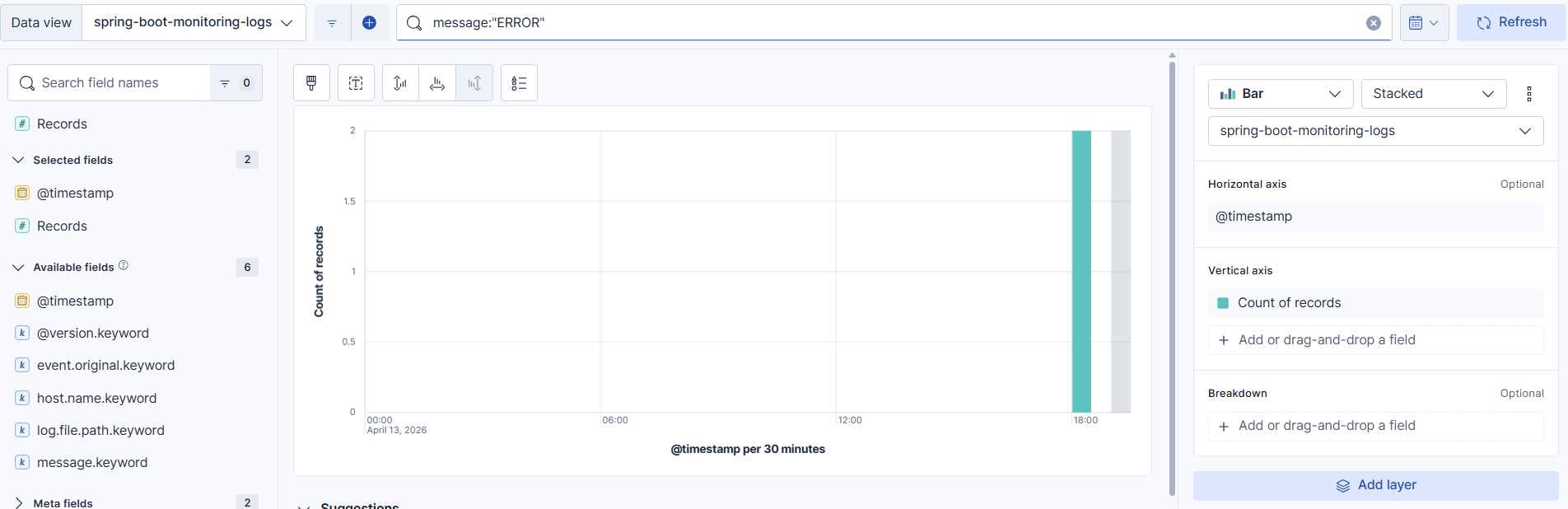
DashBoard를 통해 이러한 데이터의 양상을 어느 시점에 생성이 되었고, 얼마나 생성이 되었는지 시각화된 포맷을 통해 매우 간편하게 확인할 수있다.
전체적인 설정은 grafana와 비슷하다. kibana의 data view를 설정해주는 것에서 시작하며, 위와 같이 Dashboard를 통해 어떠한 형태로 확인할 것인지 설정해주는 작업으로 구성된다.
중요한 것은 기술의 사용이 아닌, 기술의 목적과 파이프라인 등 활용 방법 등에 대한 깊이 있는 분석과 파악이다.
확실히 시계열 데이터 기반의 이벤트 로그보다는, text 기반의 데이터 검색에 유용하며, grafana 만큼은 아니더라도 timestamp를 통해 숫자 기반의 시계열 데이터 또한 계측 및 관리에도 꽤 유용하게 적용할 수 있음을 확인할 수 있다.
다만, 숫자 기반의 메트릭만 저장하는 Prometheus와 달리, 고성능을 위해 Lucene 기반의 역색인 인덱싱, 데이터를 메모리에 캐싱하며, 검색 성능을 위해 JVM Heap을 사용하는 등 인덱싱을 위한 디스크 segment 작업과 JVM Heap(최소 512MB)에 소모하는 비용이 prometheus에 비해 무겁고, 과할 경우 시스템 성능에도 영향을 많이 미치게 된다.
따라서, 로그 데이터 수집을 위한 ELK 구성은 별도의 서버를 구성하여 진행하는 것이 바람직하며, 로그 기반의 구체적인 데이터를 모니터링 하여 특히 CPU와 같은 리소스 성능에 기반한 병목지점의 예상보다는 명확한 문제 지점을 탐색하고 원인을 분석하기 위한 도구로 많이 사용한다.
이러한 명확한 목적, 시스템 성능(서버 구축 관점에서)에 맞는 모니터링 도구를 사용하도록 하자.
8. 결론
위와 같이 Spring Boot 환경을 기반으로, Logging에 대한 분석, 특히 ELK 및 Prometheus / Grafana 환경을 바탕으로 각각 어떠한 데이터를, 어떠한 환경에서 어떠한 목적으로 모니터링하는 것이 적합한지 구체적으로 분석해보았다.
설계와 마찬가지로, 결국 어떠한 목적으로 모니터링 환경을 구성하는 것이 좋을지 파악하고 적절하게 구성하는 것이 중요하다.
다만, 모니터링 환경에서는 trade off보다는 "적절한 목적, 형태, 환경"을 구성하는 것을 우선순위로 적절한 데이터, 적절한 파이프라인을 구축하여 데이터를 계측하고 수집, 시각화하는 전략을 취해보도록 하자.
참고로, ELK와 Prometheus의 목적은 꽤나 분명하고 명확하기에, 시스템 성능이나 설계 방법에 맞게 적절한 모니터링 시스템을 구축하여 사용하도록 하자.
| 항목 | ELK | Prometheus + Grafana |
|---|---|---|
| 목적 | 로그 분석 | 시스템 모니터링 |
| 데이터 형태 | 로그 (텍스트) | 메트릭 (숫자 시계열) |
| 수집 방식 | push (Logstash 등) | pull (scrape) |
| 저장소 | Elasticsearch | Prometheus |
| 시각화 | Kibana | Grafana |
| 쿼리 방식 | DSL (검색 기반) | PromQL (시계열 쿼리) |
| 실시간성 | 준실시간 | 거의 실시간 |
| 리소스 사용 | 매우 큼 | 상대적으로 가벼움 |
| 저장 구조 | 역색인 (Lucene) | 시계열 DB |
| 사용 사례 | 로그 추적, 에러 분석 | CPU, 메모리, 트래픽 모니터링 |
| 장애 분석 | 상세 원인 분석 강함 | 징후 탐지 강함 |
9. 참고자료
OpenTelemetry 파이프라인 시스템 체계 - https://www.anyflow.net/sw-engineer/opentelemetry-overview
Kibana 공식문서 - https://www.elastic.co/kr/kibana/features
Log Stash 파이프라인 - https://www.devopsschool.com/blog/logstash-pipeline-config-example/
ELK는 전통적인 느낌이 강함, 현대 벤더들은 OTel이 우선순위 - https://www.reddit.com/r/devops/comments/1pu28v7/is_elk_stack_still_relevant/?tl=ko
