1. 개요
분산 환경(MSA) 구조에 대해 분석하는 것과 더불어, 이번에는 분산 환경에서 트랜잭션의 일관성을 확보하고, 데이터의 정합성을 확보하기 위한 분산 트랜잭션 구성 방안에 대해 알아보고자 한다.
구현 그 자체보다는, 구현하기 위해 어떠한 점을 고려해야하며, 어떠한 부분을 후순위로 희생해야 할지 등 설계적인 관점에서 분석해보고자 하는 것이다.
일전과 마찬가지로, 설계에는 정답이 없고 상황에 맞게 적절한 best practice를 찾아 일부를 희생하고 일부를 최우선적으로 고려하는 방향으로 이루어져야 한다.
분산 트랜잭션에서는 특히 이러한 최우선적 고려사항, 비동기적 환경에서 데이터 일관성을 보장하는 것을 넘어 데이터 유실 및 Retry 등 Fault에 대한 Resilience(내결함성)도 같이 고려가 필요하기에, 무작정 메시징 큐 / 비동기 구현 그 자체보다는 어떠한 점을 유의해야 하는지 설계적 안목과 유연성을 확보하는 것도 못지않게 중요하다.
이러한 중요성을 바탕으로, 분산 트랜잭션을 구성하기 위한 설계 과정에 대해 분석해보고자 한다.
2. Why SAGA Pattern
일단, SAGA Pattern을 구성하기 전에 역으로 질문을 던져보아야 한다.
왜 SAGA Pattern일까?
기본적으로 트랜잭션 시 DB와 Connection pool을 생성하여 트랜잭션 컨텍스트의 네트워크 통신이 이루어진다.
전통적인 DB는 이러한 트랜잭션이 짧은 시간에 이루어지는 반면, 현대에 들어와서는 그 시간과 양이 훨씬 방대해졌다.
데이터가 많아질수록 그 시간과 일련의 과정이 길어지기에, 현대적인 MSA구조, 나아가 트랜잭션 자체가 복잡하여 유지 시간을 길게 소모해야 하는 상황에서는 기존의 기조가 맞지 않고 이에 따른 성능 문제가 발생하게 되었다.
SAGA Pattern은 Long Lived Transaction에 대한 대비책에서, Eventually Consistency라는 개념에 기반하여 도입된 구성 방안이다.
이후, Monolithic 환경에서 보장해야하는 CAP 요소에 대해, 분산된 환경에서 보장해야 하는 방안, 분리된 트랜잭션을 안정적으로 구성하는데 하나의 표준으로 자리잡기까지 발전하게 되었다.
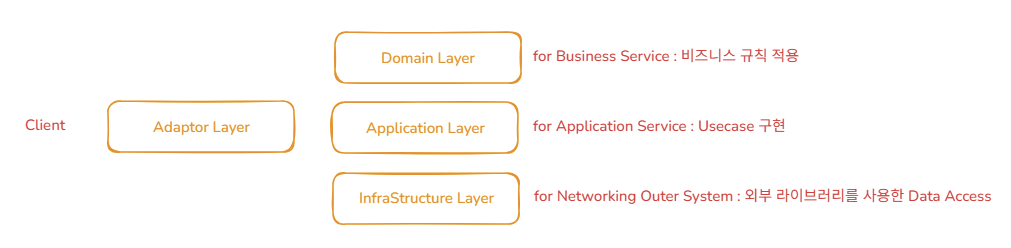
위와 같이 기존 Monolithic 구조에서는 각 layer 기반의 실시간 트랜잭션이 중요하였다면,

분산 환경에서는 각 도메인의 트랜잭션을 분리하고 관리하여, 트랜잭션의 제어 주체는 각 서비스가 분산하여 맡고, 최종적으로 Eventually Consistency하게 트랜잭션 및 데이터 일관성을 확보할 수 있도록 구성하는 것이 목적이다.
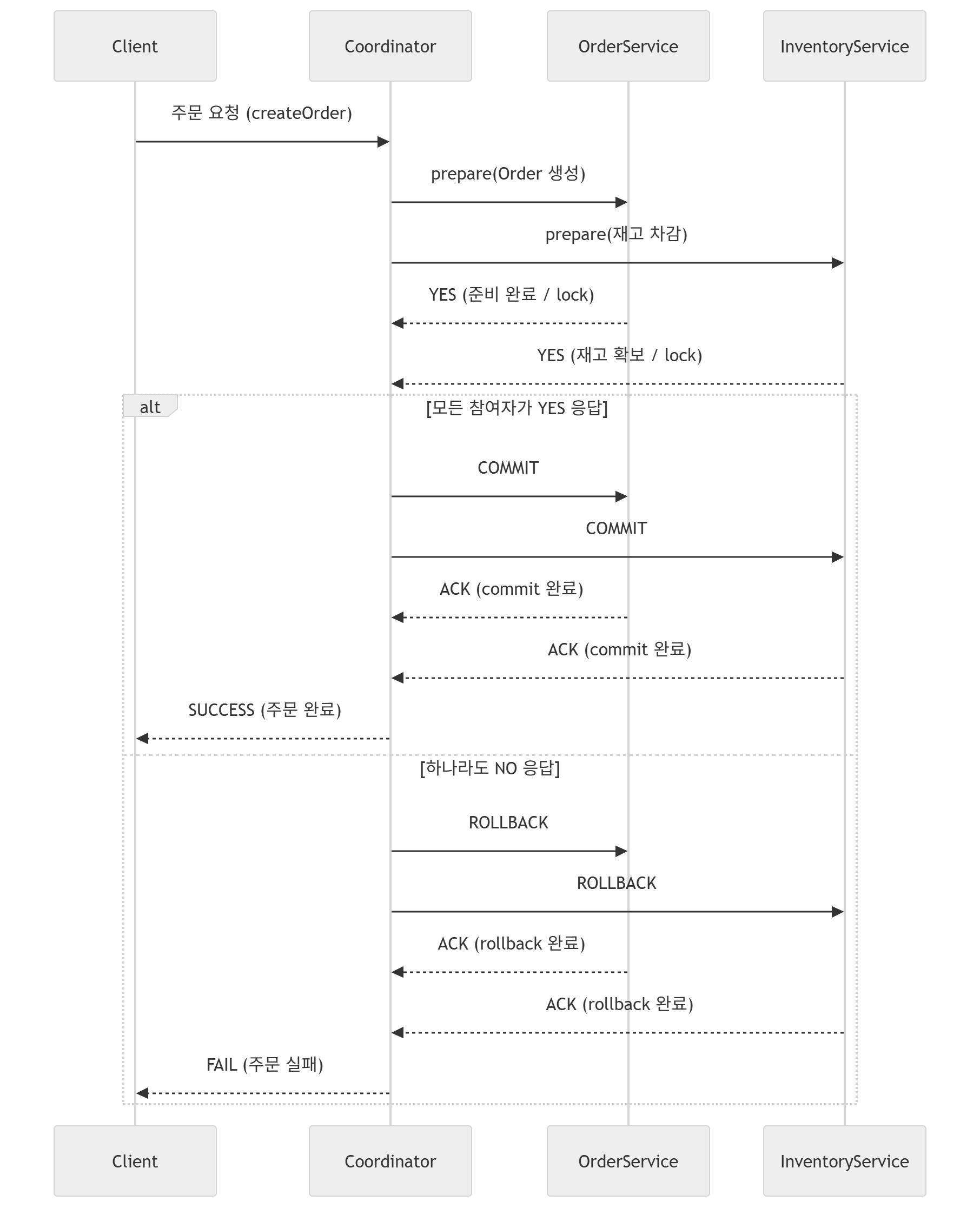
이처럼 전통적인 2PC, Facade 방식은 ACID 보장은 어찌저찌 보장은 할 수 있으나, 이 원자성 하나를 보장하기 위해 성능, 확장성, Locking에 의한 latency 등 너무 많은 요소들을 포기해야만 했다.
기존의 2PC를 MSA에서 적용하여 발생하는 Long Lived Transaction, 성능 저하 문제 등을 보완하고, 동시에 CAP(Consistency, Availability, Partition Tolerance)까지 만족할 수 있는 방안을 정립하기 위해 SAGA Pattern이 자리잡게 된 것이다(도입이 되었다기보다는, SAGA Pattern을 그에 맞게 표준화하고 다듬었다는 표현이 더 정확하다).
3. SAGA Pattern factors
기존 2PC는 데이터베이스가 다수의 데이터베이스 혹은 다수의 스키마에 대한 Aggregation이 가능하였기에 원자성, 일관성을 보장할 수 있는 가장 단순하면서 강력한 트랜잭션의 패턴이었다.
그러나, MSA에서는 원자성을 확보하고자 생기는 확장성, 유연성, 특히 엄청난 성능 저하 문제로 인해 모든 트랜잭션을 하나로 조합하여 묶는 2PC 패턴을 사용하지 않는다. 정확히는, 사용해서는 안된다.
이러한 MSA에서, Long Lived Transaction을 데이터베이스의 기조에 맞게 도입된 SAGA Pattern을 분산환경에서 데이터 일관성을 확보하고자 다듬고, 지금의 표준으로 자리잡게 되었는데, 이를 기반으로 어떠한 점이 중요한지 좀 더 자세하게 살펴보자.
결론적으로 말하면, Eventually Consistency.
즉 일관성은 약화하였지만, 그 일관성을 보장하기 위해 각 도메인에서 진행하는 로컬 트랜잭션에 대해 단계적으로 그 결과를 살펴보고, 실패 시 이미 진행된 트랜잭션에 대해 논리적인 롤백을 진행하는 보상을 해주는 것이다.
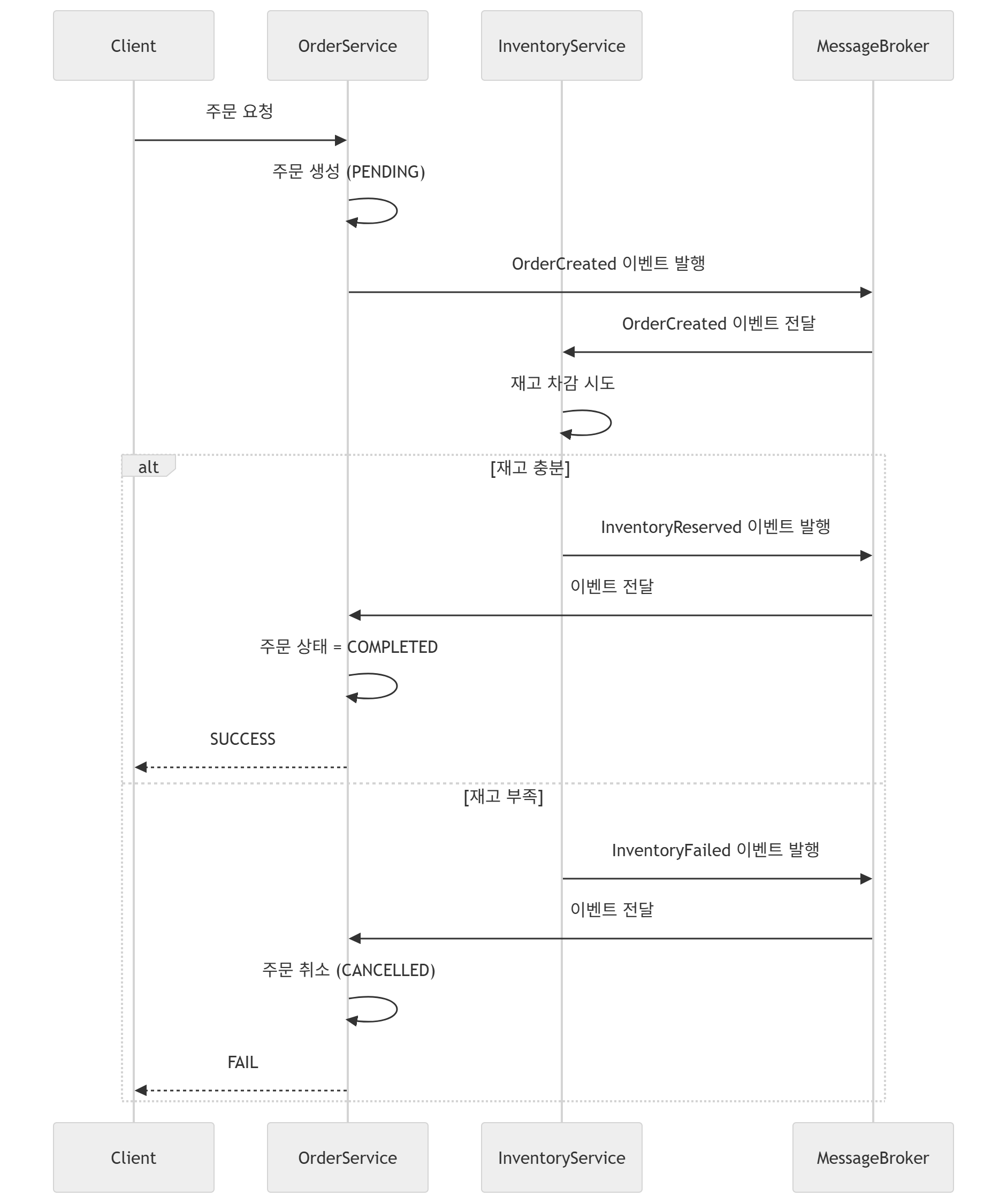
이처럼, 강한 원자성 및 격리성까지는 아니더라도 트랜잭션의 일관성, 데이터의 정합성을 유지하기 위한 이벤트 메시징 기반의 비동기적인 처리 방향을 정립하는 것이 SAGA Pattern의 중요 요소라 볼 수 있겠다.
각 로컬 트랜잭션이 이미 commit한 내역은 물리적으로 이미 반영이 되어있기에, 트랜잭션 처리 실패 시 이를 논리적으로 보완(Logical Rollback)하는 방안에 대해 SAGA Pattern이 제시해주고 있는 것이다.
하지만, SAGA Pattern이 분명 MSA 환경에서 분산 트랜잭션을 구성하기 위한 표준은 될 수 있지만 정답은 될 수 없다.
다시 한번 강조하지만, 설계적인 관점에서 100% 통용되는 설계, best practice란 존재하지 않는다.
SAGA Pattern은 로컬 트랜잭션이 독립적으로 Commit 되는 방향이기에, 각 도메인에서 트랜잭션을 처리하고 제어하는 논리적 일관성 및 확장성, 가용성 측면에서도 서비스 간의 결합도가 최소화된 수준이기에 1순위적으로 고려할 수 있는 패턴이다.
만약 매우 강한 일관성을 유지해야 한다면, SAGA Pattern을 적용하기에는 무리가 있을 것이고 무작정 도메인이 다르다고 하여 SAGA Pattern을 구성하는 것 역시 무리가 있을 것이다.
데이터의 강한 일관성, 트랜잭션의 강한 일관성을 보장해야 한다면 SAGA Pattern은
또한, SAGA 트랜잭션이 다수 발생할 경우, 이에 대한 Dirty Read를 방지하는 방안도 반드시 마련해야한다.
예를 들어, 재고가 1인데 주문요청이 동시에 2번 들어왔다고 가정해보자.
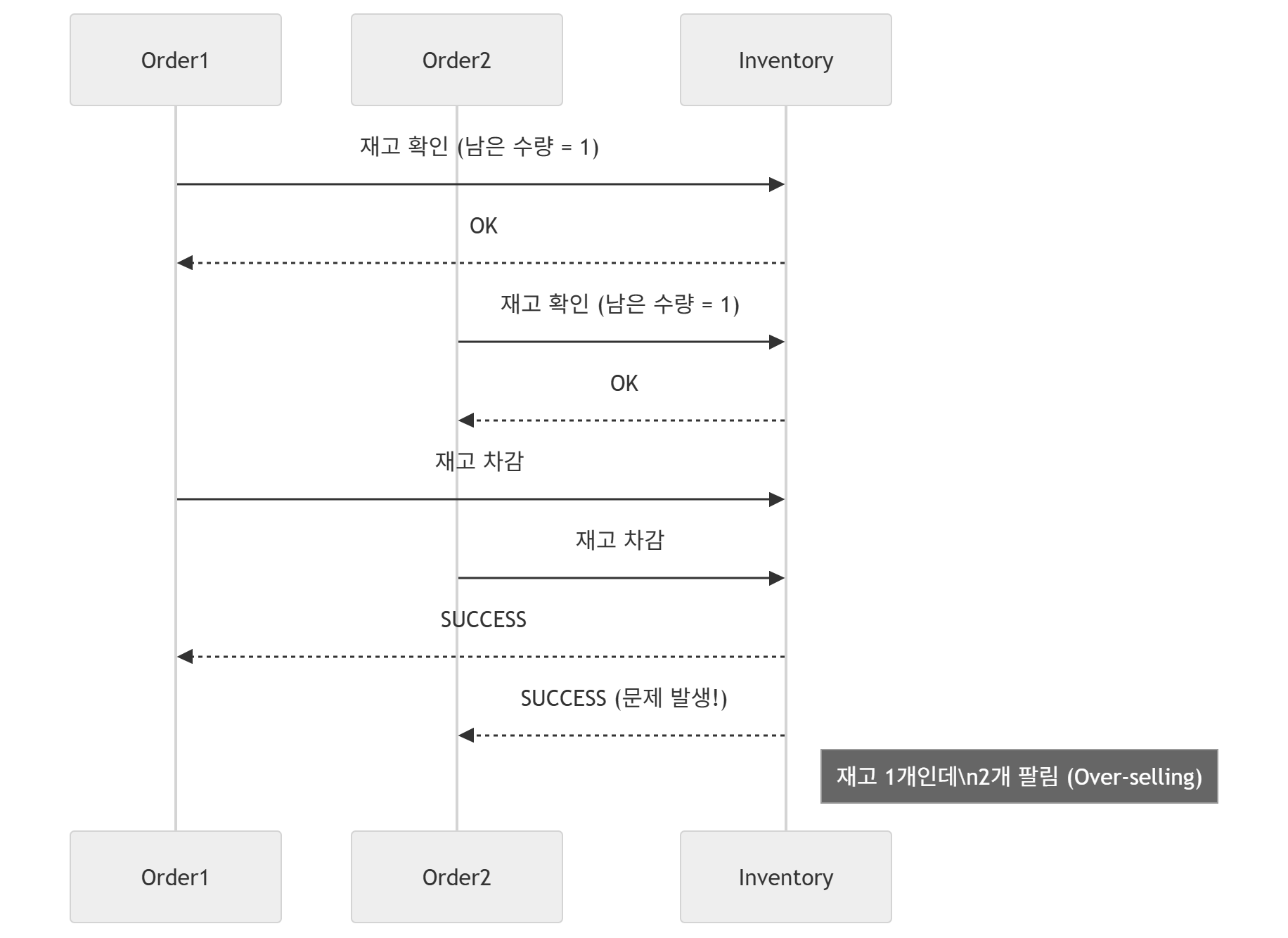
동시에 들어온 요청이 최초 재고 수량을 확인하였을때, 격리성이 보장되지 않은 상황에서 모두 재고 수량이 1인 데이터를 조회하게 된다.
즉, 최초 실행한 SAGA가 재고수량을 반영하기 전에, Commit 이전의 데이터를 다른 SAGA 트랜잭션이 본 상태이기에 Dirty Read의 문제가 발생하고, 데이터 정합성을 보장할 수 없는 상태가 일어나게 되는 것이다.
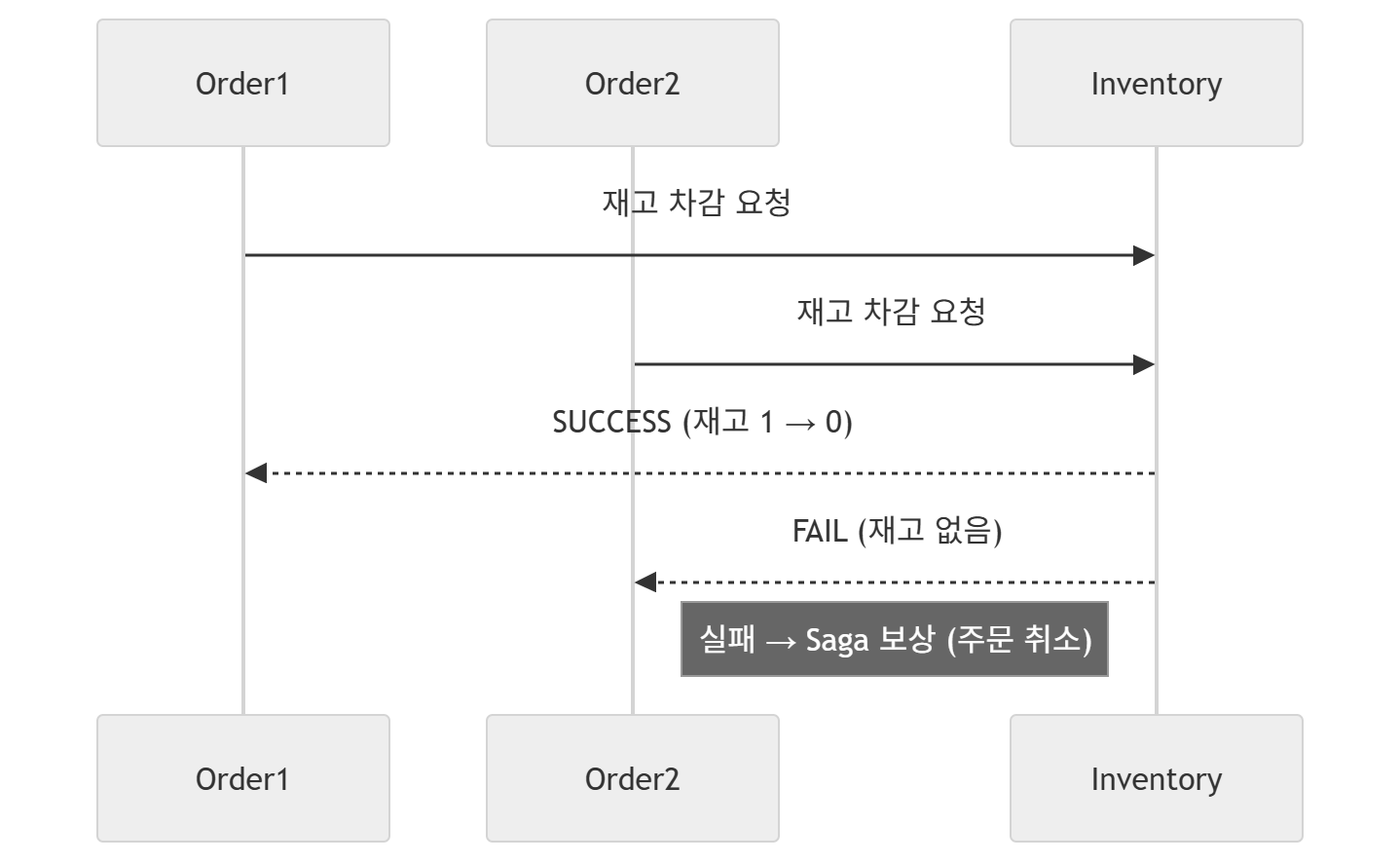
물론 이처럼 보상 트랜잭션을 기반으로 한 재고 내역 복원도 중요하겠지만, 애초에 Dirty Read를 하지 않거나 논리적으로 이러한 처리 진행을 방지하는 방안도 중요하다.
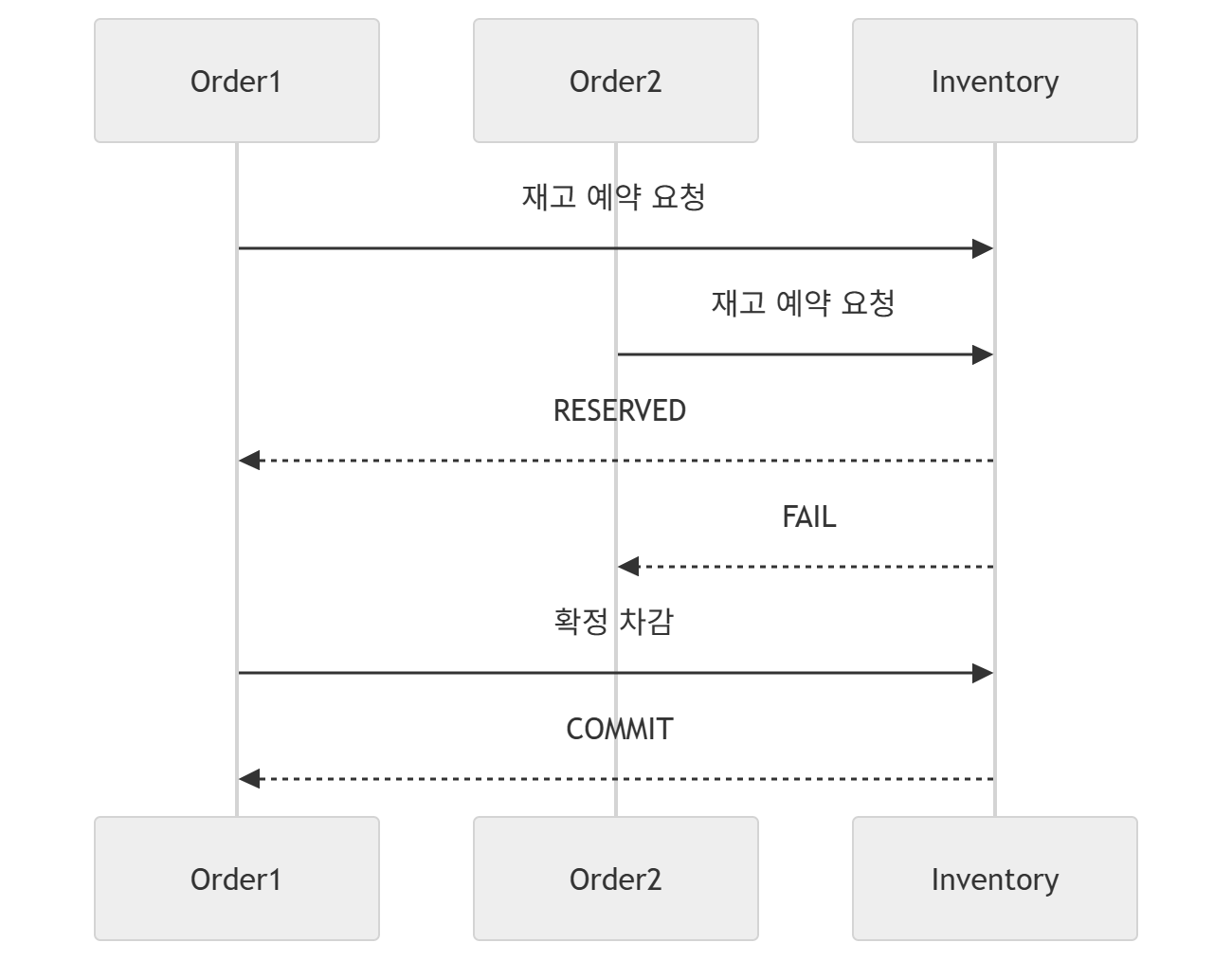
그래서 논리적 락, Reservation 방식으로, 재고의 상태값을 변경하고 그 이후에 재고차감을 발생하거나, 향후 재고차감 트랜잭션에 대해 Reservation하여 이를 기반으로 잔여 재고가 없으면 실패 메시지를 보내는 등의 방안도 존재한다.
(*특히 재고의 상태값 변경의 경우 일단 주문 처리 후 상태값을 Pending으로 처리하여, 모든 서사가 종료되었을때 상태값을 바꾸는 형태로 진행하는 상대적으로 간단한 방식으로 처리할 수도 있겠다)
상황에 따라 적절한 방식으로 분산 트랜잭션을 구성하고, 적절한 필요 요소들을 고려하고 구축하는 것이 필요하겠다.
4. SAGA Pattern의 구체화 - Orchestration / Choreography
그렇다면, 이러한 SAGA Pattern을 구체화하는 방안은 무엇이 있을까?
SAGA Pattern이라는 개념 자체는, 위에서 기술하였듯이 본래 Long Lived 트랜잭션에 적절하게 대응하기 위한 방법이었으나, 분산 환경에서 단순 서비스 결합이 아닌, 긴 트랜잭션의 서사를 구성하는 개념으로 표준화되어 활용하고 있다.
이때, 각각 개별적인 마이크로서비스들이 서로 조화를 이루면서, 이벤트를 주고받고 분산 트랜잭션을 관리하기 위한 형태를, 마치 악기들의 조합으로 음악이 이루어지는 오케스트라, 지휘자, 무용수에 비유하여 구체화하고 있다.
4-1. Choreography
그 중 Choreography는 무용수에 비유하여, 중앙에서 오케스트라를 지휘하는 지휘자없이(Orchestration) 각 서비스들이 개별적인 안무가처럼 서비스 로직을 진행하고, 각 서비스의 조화가 이벤트를 기반으로 이루어져 하나의 시스템, 비즈니스 로직을 구성하는 것에서 비롯되었다.
Choreography의 가장 특징적인 부분은 비즈니스 로직 제어의 주체가 각 로컬 도메인에 있고, 중앙의 지휘자없이 서비스들이 자율적으로 비즈니스 로직을 수행하고 이벤트를 발행하는 형태라는 것이다.
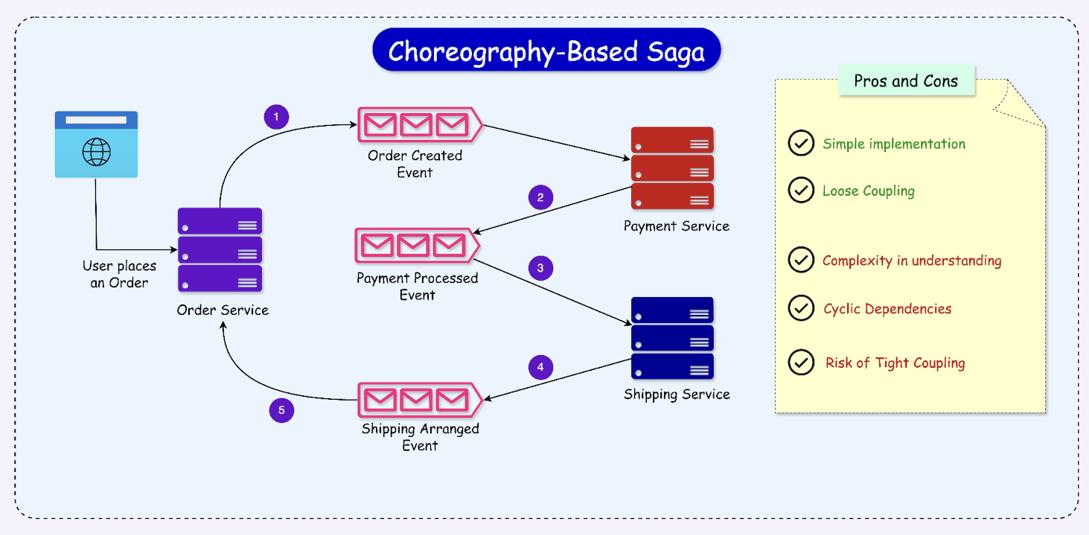
각 로컬 트랜잭션은 물리적으로 레코드를 기록하면서 다음 서사 이벤트를 연결해주고, 응답을 기다리지 않는 비동기 형태로 서사를 구축하기 때문에 데이터의 강한 일관성은 보장할 수 없다.
다만, 강한 원자성을 다소 희생하는대신, 이벤트 기반으로 데이터 일관성을 보장하고 이벤트 전송 및 처리에 실패하였을때를 대비하여 보상 트랜잭션 및 Retry/DLQ/Outbox Pattern 등의 다양한 실패 대응 방안이 나타나게 되었다.
서비스 구축이나 시스템의 동작 원리, 관리가 상당히 복잡하지만, 비즈니스 로직의 제어가 각 도메인에서 이루어지기에 응집도, 확장성, 유연성 측면에서 유리하다(CAP를 이론적으로 적절하게 구축한 형태가 Choreography).
다만, 이벤트가 분산 트랜잭션의 핵심이기에 이에 대한 실패를 대비해야 하고, 일방향 이벤트가 아닌 양방향 이벤트 구성 시 의존성이 순환하는 문제에 빠질 수 있다. 더불어 이벤트의 처리 주체가 도메인이기에 Pub/Sub의 관계를 정확히 인지하고 구축하는 것이 필요하다(특히 이벤트를 다수 발생하는 복잡한 시스템의 경우 더욱 이벤트 처리 과정을 이해하고 모니터링하는데 오래 걸리기에 충분한 검토가 필요하다).
4-2. Orechestration
Choreography의 트랜잭션 제어 주체가 각 도메인, 로컬 트랜잭션이었다면 Orechestration은 제어의 주체가 중앙의 Orechestrator, 지휘자이다.
이벤트 기반으로 각 분산 트랜잭션의 서사를 연결하는 것은 동일하지만, 그 이벤트의 연결이 도메인의 직접적 연결이 아닌, 중앙의 Orechestrator에 집중되어 모든 이벤트 및 트랜잭션 처리를 담당하게 된다.
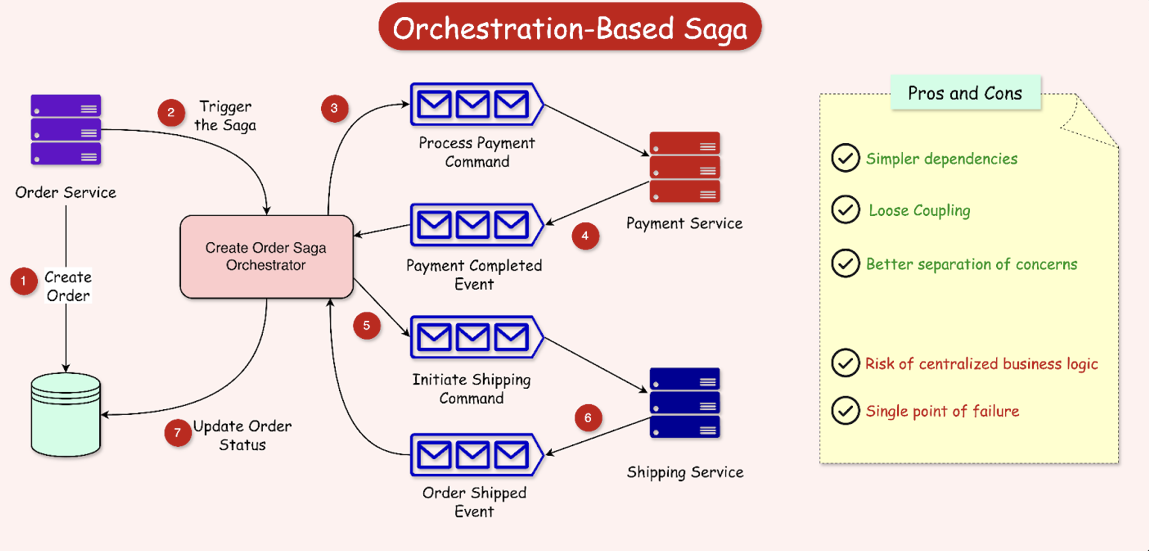
중앙의 Orchestrator가 모든 도메인 서비스에 처리 명령을 전달하는 것이 핵심이다.
따라서, 모든 분산트랜잭션의 흐름이 중앙의 Orchestrator를 거치기때문에 각 도메인의 자율적인 이벤트 기반 처리보다 처리 병목(Latency)현상이 발생할 수 있고, 성능이 Choreography에 비해 떨어질 수 있다.
Client → Orchestrator
↓
Order Service
↓
Orchestrator
↓
Inventory
↓
Orchestrator
↓
Payment구체적으로 위와 같이, 모든 명령의 처리가 각 유관된 서비스간의 상호작용이 아닌 중앙의 Orchestrator에 집중되므로, 시스템 구성이 단순해질 수는 있다. Orchestrator의 명령처리가 시스템의 중심이 되기 때문이다.
다만, 그만큼 Choreography에 비해 서비스 결합도가 매우 높아질 수 밖에 없는 구조이다. 중앙의 Orechestator에 장애가 발생하면 모든 시스템이 영향을 받는 SPOF, 단일 장애점이 발생할 수 있다.
또한, 분산 트랜잭션을 구축할때 고려해야하는 CAP(일관성, 가용성, 서비스간 내결함성)가 Orchestration에서는 Choreography에 비해 그 의미가 많이 옅어질 수 밖에 없는 구조이다.
이러한 부분은 Outbox pattern을 활용한 stateless 방식이나 saga ID를 별도로 발행하여 병렬처리를 하는 등의 보완 설계로 어느 정도 성능 및 일관성을 보장할 수 있으며, 상황에 따라 적절하게 구성하고 보완할 필요가 있겠다.
4-3. 보상 트랜잭션 오류 발생 시 최후의 보루 - Rollback / Transaction Compensation
분산트랜잭션에서 각 도메인 별 로컬 트랜잭션은 물리적으로 commit, 즉 변경사항을 온전히 반영한 이후에 다음 단계로 넘어간다.
즉, 각 도메인 내부에서는 물리적인 Commit이 발생하기에, Monolithic 단일 인스턴스, 단일 데이터베이스 환경에서 두 테이블의 aggregation 및 Rollback이 이루어지는 과정과는 완전히, 본질적으로 다르다.
즉, 전체 서사(SAGA)로 보았을때는 각 도메인에서 발생한 Commit은 이미 발생한 사건이기에 다른 도메인에서 오류가 발생하였을경우, 물리적으로 반영된 데이터를 논리적으로 복구해야 하는 보상 작업이 필요하다.
따라서, 트랜잭션을 처리하기 위한 메시지를 유실한 상태에 대해 대비하는 것도 중요하지만, 이마저 실패하였을경우 보상 트랜잭션을 통해 데이터 일관성을 보장할 수 있는 배수의 진을 구성하는 설계가 반드시 적용되어야 한다.
로컬 트랜잭션의 Rollback
로컬 트랜잭션의 Rollback은 설계적으로 접근하는 것이 아닌, 데이터베이스가 Application의 롤백 요청을 받아 데이터 원복을 진행하는 것을 의미한다.
좀 더 자세하게 살펴보도록 하자.
[Client]
|
v
[Application (Service Layer)]
|
| 1. BEGIN TRANSACTION
|------------------------------> [DB]
| (트랜잭션 시작)
|
| 2. 주문 INSERT
|------------------------------> [DB]
| - undo log 생성
| - redo log buffer 기록
| - 데이터 변경 (버퍼 캐시)
|
| 3. 재고 UPDATE
|------------------------------> [DB]
| - undo log 생성
| - redo log buffer 기록
| - 데이터 변경
|
| 4. (오류 발생 상황)
| ex) 재고 부족 / constraint violation
|
| 5. EXCEPTION 발생
|
| 6. ROLLBACK 요청
|------------------------------> [DB]
|
| [DB 내부]
| - undo log 기반 롤백 수행
| - 변경 내용 원복
|
|<------------------------------|
| rollback 완료 응답
|
[Application]
|
v
[Client]이때 데이터베이스는 Undo Log를 역순으로 적용하여, Step by Step으로 원래의 값으로 데이터를 복구하게 된다.
Undo Log는,
- Update의 경우 기존의 값을 저장하며
Undo Log:
- quantity = 10 (원래 값)- Insert의 경우 Null Record를 저장하여
Undo Log:
- "이 row는 없던 것"기존 값으로 원복하거나, 아예 Record를 DELETE하는 과정으로 일관성을 유지할 수 있도록 조치한다.
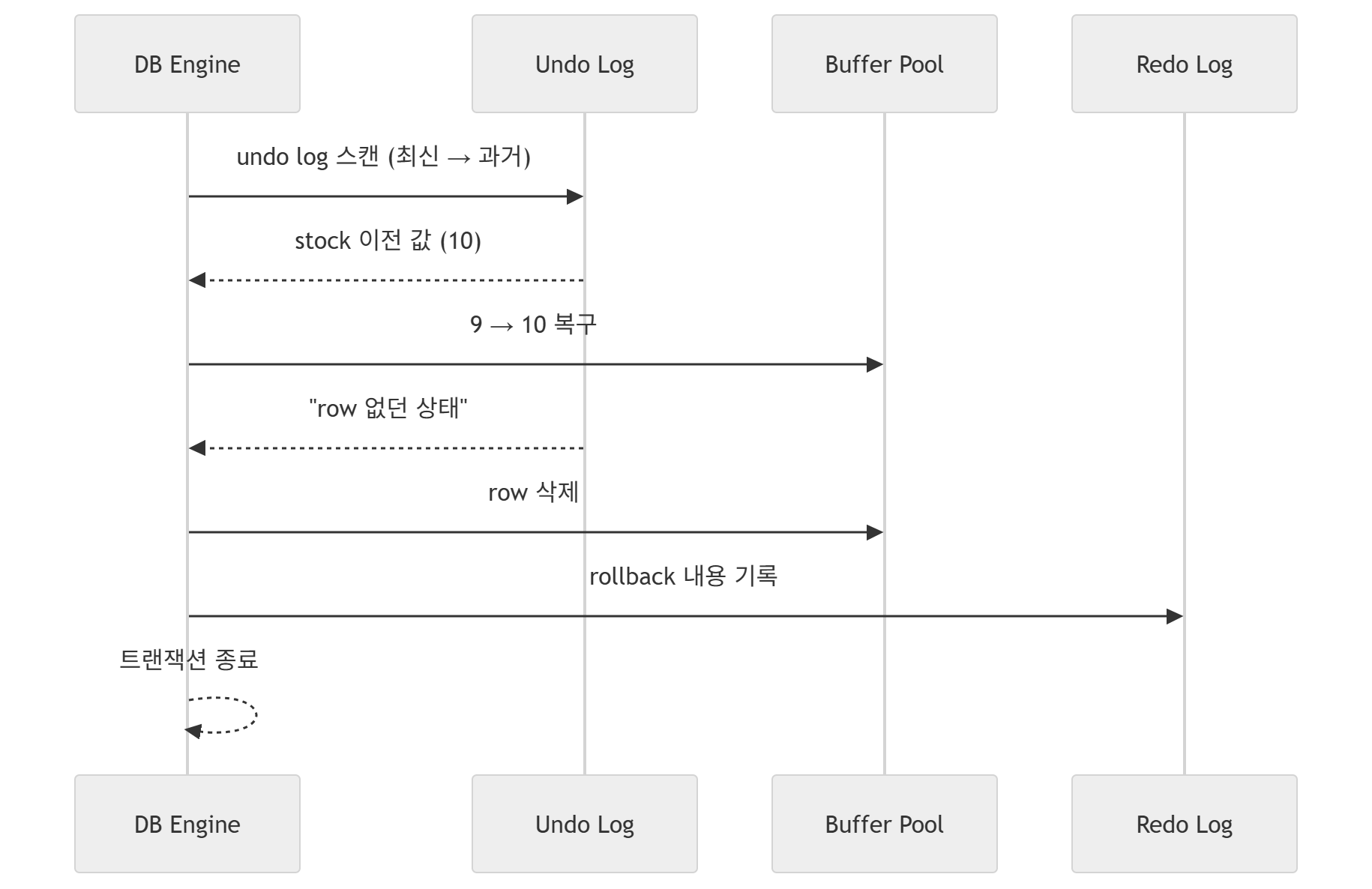
이는 별도의 설계가 아닌, 데이터베이스가 Application의 Rollback 요청을 받아 진행하는 과정으로, 이외의 네트워크가 발생하지 않고 내부적으로 발생한다.
Transaction Compensation
이와 같은 데이터베이스 설계에 따른 물리적 데이터 원복이 아닌, 이미 디스크에 변경사항이 flush되어있는 상태에서 트랜잭션 시작 이전의 값으로 원복을 하기 위해 논리적으로 이전의 상태로 UPDATE를 하는 과정이 바로 보상 트랜잭션, Transaction Compensation이다.
사실 SAGA의 꽃은 보상 트랜잭션이다.
- 멱등성
- 명확한 상태전이
- 진행된 로컬 트랜잭션 서사의 역순으로 진행
- 물리적으로 보상이 가능한 경계 정의(데이터 원복은 가능하지만, 이메일 전송 등의 외부 도메인은 보상이 불가)
이러한 고려사항에 대해 최대한 온전하게, 면밀히 살펴보고 설계 시점부터 심도 있게 적용해주는 것이 필요하다.
참고. Undo Log, Redo Log
그렇다면, Undo Log와 Redo Log는 구체적으로 무엇을 의미할까?
간단하게 기술하면, Undo Log는 과거 상태를 저장하기 위한, 즉 Pre-Do(행위이전)의 상태를 저장하는 내역이며 Redo Log는 미래의 상태를 저장하기 위한, Post-Do(행위이후)의 상태를 저장하는 내역이다.
Undo Log는 오류가 발생할 상태에 대비한 이전 상태 내역에 대한 기록, Redo Log는 행위가 반영된 이후 예상치 못한 오류로 결과가 지워졌을때 이를 복구하기 위한 내역의 의미를 지닌다고 볼 수 있다.
참고로 Undo Log는 이전 데이터, before image를 저장하기 위한 로그로 사실상 단순 로그라기 보다는 Undo Tablespace, 즉 디스크에 저장하는 스냅샷으로 간주하여도 무방하다.
특히, Undo Log의 경우 이전의 상태를 읽을 수 있다는 점에서 다른 트랜잭션이 Dirty Read를 하지 않고 일관된 데이터를 읽을 수 있도록 하는 동시 요청에 대한 Version Control, 즉 MVCC에서도 중요한 요소가 될 수 있겠다.
반면, Redo Log는 변경 내용에 대해 Log 형태로 기록하여, Redo Entry의 형태로 메모리(Buffer)에 저장하며, 최종적으로 Redo Log file의 형태로 디스크에 flush하는 시점을 기준으로 데이터베이스의 Commit이 이루어지는 것이다.
데이터베이스 메모리에 문제가 생겼을때, 위 과정에서 flush된 Redo Log file(디스크 상의)를 참고하여 데이터를 다시 적용할 수 있는 Roll Forward의 핵심 요소라 할 수 있겠다.
이처럼 데이터베이스는 데이터 페이지를 디스크에 쓰기 전에, 반드시 Redo Log file(log내역)을 먼저 디스크에 반영하는 WAL(Write Ahead Logging)을 진행한다.
이 WAL, Redo Log가 디스크에 flush되어 안전하게 디스크에 해당 내용을 Roll forward할 수 있는 시점이 곧 commit의 시점인것이다. 디스크에 데이터 페이지가 Write된 시점이 아니다.
이 과정을 정리하면 아래와 같다.
1. Undo Log 생성 (이전 값 저장)
2. Redo Log Buffer 기록 (변경 내용 기록)
3. Buffer Cache 데이터 변경 (메모리에서 수정)
4. COMMIT 요청
5. Redo Log Buffer → Redo Log File (디스크 flush) ← 여기서 commit 완료
6. (나중에) Buffer Cache → Data File (디스크 반영)다시 한번 강조하지만, Redo Log File이 디스크에 flush되는 시점이 Commit 시점이며, 이는 디스크의 Random Access로 인한 성능 저하를 막기 위한 방책이다.
따라서, Commit 시점에 데이터가 아직 안쓰여질 수 있으나, MVCC에서 중요한 것은 디스크에 쓰여진 데이터가 아닌 Undo Log이기에 데이터가 반영되는 시점은 사실 그렇게 중요하지는 않다.
5. SAGA Pattern 이외의 분산 트랜잭션 구성 방안들 - 보수적 접근 / 일관성 보장 수준 향상
SAGA Pattern을 기반으로 분산 트랜잭션을 구성하는 방법 이외에, 분산 트랜잭션의 서사를 만들어낼 수 있는 다른 일련의 과정들도 존재한다.
기본적으로 SAGA Pattern은 "일단" 로컬 트랜잭션을 진행하고, 오류가 발생하면 그 후에 생각하자는 낙관적인 접근 관점이 심어져 있다.
이러한 최종적 일관성에 기반한 비동기적 트랜잭션 구성이 가지는 약한 일관성, 원자성, 정합성을 보완하고자 도입하는 분산 트랜잭션의
물론 그로 인해 병목현상 발생, 즉 성능을 희생하여 어쩔 수 없는 trade-off가 발생할 수 밖에 없음에 유의한다.
5-1. TCC
SAGA Pattern을 보수적으로 접근한 패턴이다.
Try Confirm Cancel
일상 생활에서 숙소를 예약한다고 가정해보자.
숙소는 기본적으로 "일단 사용"이 불가능하다. 현장에 가서도 반드시 프론트를 통한 예약을 먼저 진행해야 한다.
방을 일단 예약한 이후에, 체크인을 통해 최종 확인이 이루어져야 사용이 가능하며, 취소한다면 방 사용이 불가능하다.
즉, 이처럼 TCC는 예약, 확정, 취소의 과정으로 모든 로컬 트랜잭션의 성공을 보장할 수 있을때만 Confirm 후 Commit하고, 아니면 Cancel하자는 보수적인 접근으로 이루어진 패턴이다.
예를 들어, 주문 후 재고 감소를 SAGA Pattern으로 진행한다고 가정하면
Client
|
v
Order Service
| (주문 생성 - commit)
v
Inventory Service
| (재고 차감 - commit)
v
Payment Service
| (결제 실패)
v
Compensation 시작
|
v
Inventory Service (보상: 재고 복구)
|
v
Order Service (보상: 주문 취소)위와 같이, 메시지 큐 시스템을 도입하여 비동기 기반으로 트랜잭션을 연결할 것이며, 실패 상황에 대응하여 역순으로 트랜잭션을 논리적으로 보상하는 체계를 마련해야 할 것이다(Transaction Compensation).
특히, 낙관적 접근으로 인해 각 트랜잭션이 구조적으로 최종적으로 반영해야할 상태를 읽어버리는 Dirty Read가 발생하며, 이에 따라 데이터 일관성을 보장하는 방법이 복잡하고 번거롭다.
이에 반해, TCC는 매우 강한 데이터 일관성을 보장하기 위해, 모든 로컬 트랜잭션에 대해 일단 Try를 하고 모두 트랜잭션이 성공하였을때 Confirm(=Commit)을 진행하는 과정을 취한다.
즉,
Client
|
v
Order Service (Try: 주문 생성 - 상태=Pending)
|
v
Inventory Service (Try: 재고 예약)
|
v
Payment Service (Try: 결제 승인 시도)
--- 여기까지는 "확정 아님" ---
모두 성공하면 →
|
v
Confirm 단계(=commit)
|
v
Order Confirm (확정)
Inventory Confirm (재고 차감 확정)
Payment Confirm (결제 확정)
|
v
최종 Commit
--- 실패 시 ---
Cancel 단계
|
v
Order Cancel
Inventory Cancel (예약 해제)
Payment Cancel이처럼 낙관적 접근이 아닌, 철저하게 비관적 접근으로, 보수적으로 로컬 트랜잭션을 시도하며 모두 성공응답을 보냈을 경우에만 최종 상태를 성공처리 하는 방식이다.
TCC에서 유의해야 할 점은, 각 로컬 트랜잭션이 부분적으로 Confirm(Commit)하여 Cancel 처리를 하였다 하더라도, 부분적으로 성공한 Confirm 내역은 되돌릴 수 없다는 것이다.
분산 트랜잭션 환경에서 기본적으로 Rollback 개념은 없다고 보면 된다.
Confirm 처리를 하지 못한 로컬 트랜잭션 내역은 별도로 보상을 해주어야 하고, 단지 최종 비즈니스 상태에 대해서만 Cancel 처리를 하는 것임을 유의해야 한다.
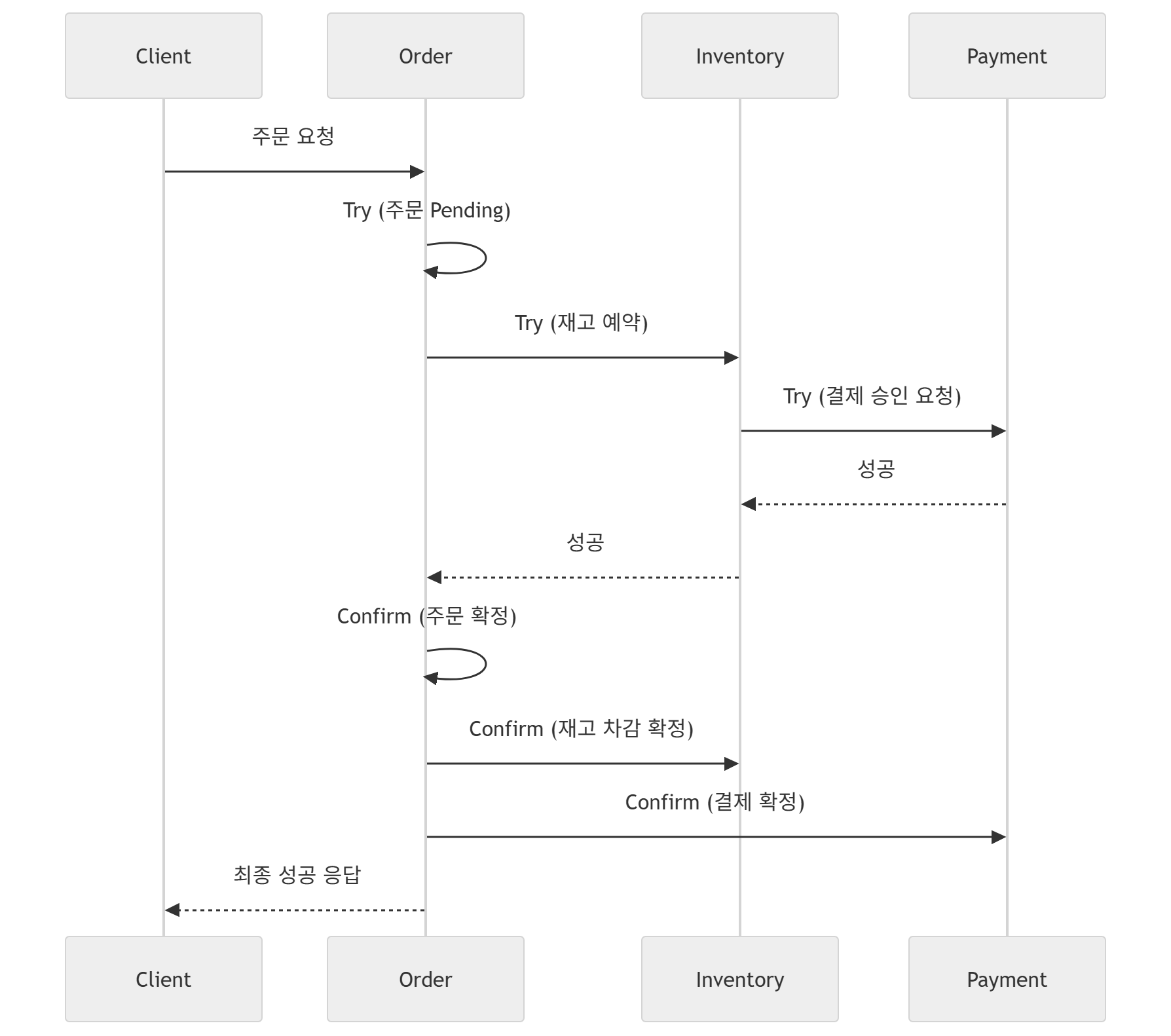
만약 모든 로컬 트랜잭션이 Confirm(=Commit)에 대한 성공 응답을 보낸다면 그때야 비로소 모든 트랜잭션의 성공처리가 되는 것이고, 하나라도 실패하면 Cancel처리한다.
Try 단계에서 Cacel 처리가 났다면 Retry하거나, 사용자 입장에서 재시도 하는 등의 절차가 이루어질 수 있을 것이다.
다시 한번 강조하지만, TCC는 데이터 일관성을 보장할 수 없는 환경에서 그 간극, 실패확률을 줄이는 방법이다.
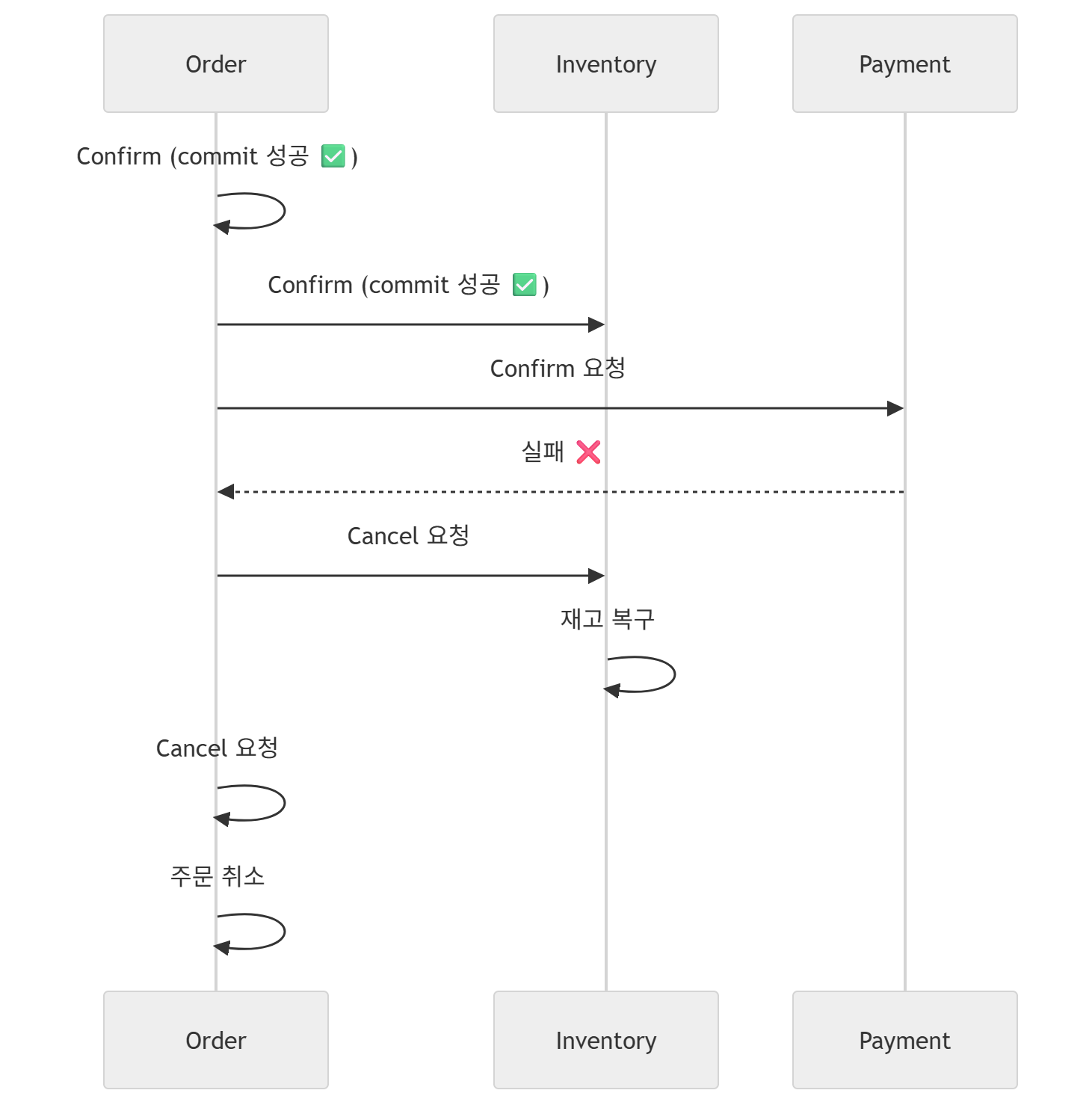
비즈니스 의미적인 Confirm/Cancel처리이며, 부분적인 Commit이 가능한 패턴이기에 반드시 이에 대한 실패 보완책(보상)이 필요하다.
참고로 보통은 Coordinator를 같이 운용하면서 각 로컬 트랜잭션 응답 상태에 따라 진행을 하기에, 이에 따른 병목, 성능 저하가 발생할 수 있다.
5-2. 3PC
TCC가 보수적인 관점에서의 분산 트랜잭션 패턴이라면, 3PC는 데이터 일관성 및 트랜잭션 원자성을 극대화한 패턴으로, 2PC의 동기/블로킹 기반의 트랜잭션 패턴을 차용한 형태이다.
3 Phase Commit
다만, 2PC만큼의 강한 동기화까지는 아니더라도 분산 트랜잭션을 동기화 방식으로 실행함으로써, 데이터 일관성을 최대한 확보하는 관점이 들어간 패턴이다.
이 역시 Coordinator가 활용이 되는데, 중앙의 Coordinator가 각 로컬 도메인에 대해 2PC처럼 트랜잭션 Prepared, Good 요청/응답 상호작용이 일어난 경우에만 모든 분산 트랜잭션에 대해 Commit 요청을 하는 완전한 동기 방식의 트랜잭션이다.
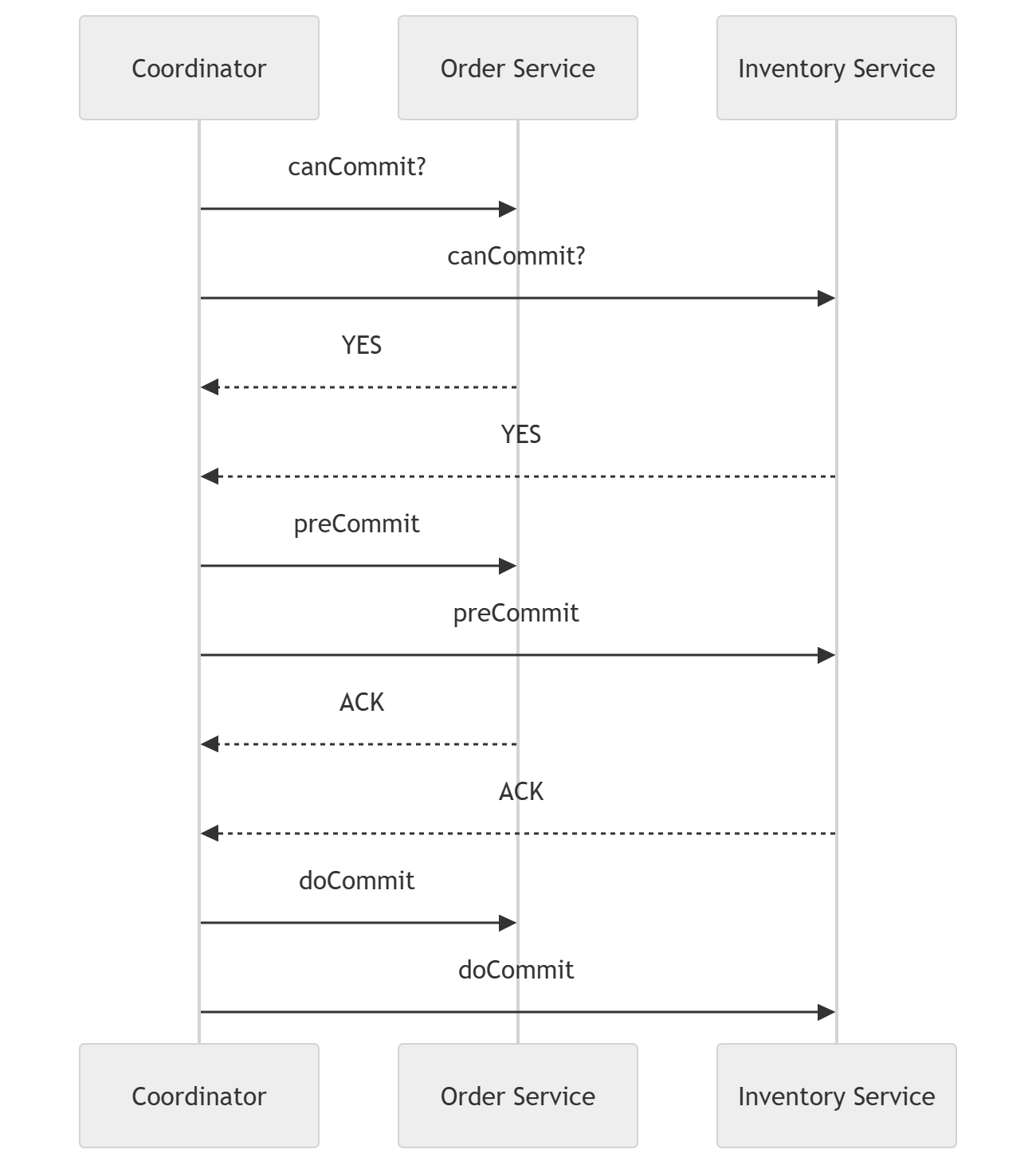
다만, 3PC는 이 중간에 Pre-Commit상태(커밋이 가능하다면, 커밋을 하기 위한 대기 상태에 들어가라)가 추가되어, 2PC에 발생할 수 있는 Participants의 무한 대기 상태를 완화할 수 있는 장치가 존재한다.
즉, 2PC는 Coordinator의 결정이 없으면 각 참가자들은 데이터 상태를 자율적으로 결정할 자격이 없기에 무한 대기에 빠질 수 있다. 그러나 3PC는 이러한 Pre-Commit 상태를 추가하여 미리 Coordinator가 이 데이터의 상태는 Commit을 할 수 있는 상태, Rollback의 가능성이 없는 상태임을 통보하기에 Blocking이지만 그 정도가 다소 완화된 수준으로 트랜잭션이 진행될 수 있는 것이다.
따라서 Participants 입장에서는 PreCommit을 받는 순간, Coordinator의 응답이 일정 시간 이상 없으면 본인이 알아서 Commit을 한다. canCommit 상태에서 응답이 없다면 상황에 따라 무한대기에 빠질 수 있으나, 보통은 rollback을 하기에 사실상 2PC보다 동기화 상태를 완화한 패턴의 형태라 볼 수 있겠다.
이처럼 3PC는 동기화 방식의 분산 트랜잭션을 구성하기 위한 형태이며, 사실 MSA 환경에서 동기식으로 분산 트랜잭션 환경을 구축하는 것은 대규모 트래픽 환경에서 Blocking 상태를 도입하는 것과 다를 바가 없기에 그리 많이 사용하지 않는 패턴이기는 하다.
매우 강한 일관성 보장 환경에 대해서는 TCC를 우선적으로 고려하고, 이것이 힘들때 3PC를 가장 후순위 방책으로 도입하는 것을 방향으로 삼도록 하자.
6. 결론
분산 환경에서 트랜잭션을 구성해야 한다면, 분명 그 표준인 SAGA Pattern을 적용하는 것이 가장 일반적인 방법일 수는 있다.
분산 환경에서 네트워크 I/O를 많이 일으키고, 이에 따른 Thread Blocking 발생 시 성능 저하가 발생하며, 이 성능 저하가 데이터 일관성이라는 기회비용을 넘어선 수준으로 문제를 유발하기 때문이다.
물론, 이러한 비동기 기반으로 동작하는 SAGA Pattern보다, 성능 저하의 위험을 무릅쓰더라도, 아니면 반대로 성능 저하가 발생할 여지가 매우 적은 환경에서 데이터 일관성을 극도로 보장해야 하는 환경이라면 위에서 기술한 TCC, 3PC 패턴이 더 좋은 선택일 수 있겠다.
무조건 일반적인 방법이 정답이 될 수는 없다.
분산 트랜잭션도 하나의 설계이며, 모든 패턴에 대해서는 항상 최우선적 항목과 희생 항목은 존재한다.
trade off를 충분히 고려하고, 시스템에 따라 적절한, 최적화된 선택지를 구성하도록 하자.
다만, SAGA Pattern과 의미적 locking, 상태 기반의 Event Sourcing 기반의 패턴이 데이터 일관성 및 멱등성을 보완하는 형태로 많이 사용되기에, TCC나 2PC/3PC는 그리 우선적으로 고려되어야할 선택지는 아니라는 점을 기억하자.
7. 참고자료
SAGA Pattern(Orchestration/Choreography) - https://blog.bytebytego.com/p/the-saga-pattern
