1. 개요
3년 동안의 여러 실무 상황, 요구사항에 맞춘 개발을 하면서 느낀 점 중 하나는 설계의 중요성이다.
사실 지금까지의 개발을 진행하면서 아쉬웠던 점은 Application 설계(흔히 말하는 시스템 구축), Database 설계를 동일선상에 두면서 생각을 하였다는 것이다.
그것도 Application 설계, 즉 비즈니스 로직을 처리한 후에 Database를 어떻게 구축하고 이에 따른 데이터를 어떠한 방향으로 모델링할 것인지..당시 상황과 협의 과정에서는 최선의 방향일 수 있지만, 지금 생각해보면 아쉬운 순간으로 복기가 되고 있다.
특히 Application 설계 후 Database 설계 및 데이터 모델링이 이루어지는 것은 상황에 따라 선택이 가능하지만, database 설계 후 데이터 모델링이 이루어지는 것은 모순이다.
이러한 오해와, 나의 기준에서 부족하다고 생각하는 DB, Data modeling에 대한 부분을 바로잡고 보완하기 위해 데이터 모델링에 대한 실무중심적이고 합리적인 이해를 진행해보고자 하며, 이에 대해 이해한 내용을 기록해보고자 한다.
데이터 모델링에 대한 기록 내용은 기술적, 결과론적 내용보다는 그것이 "왜" 필요한지 고민하는 "과정적" 내용에 중점을 둘 것이다.
이러한 깊은 이해를 바탕으로, 단순 이론 학습에 그치지 않고, 실무적으로 어떻게 응용하고 적용할 수 있을지 다방면으로 생각해보면서 즉시 적용이 가능하도록 하기 위한 배경, 기본기를 튼튼히 다져보고자 한다.
2. Join
데이터 모델링에 대해 본질적으로 이해하기 위해서는 먼저 Join이라는 개념을 시작으로, 데이터 분리 - 데이터 Merge에 대해 단계적으로 살펴보는 것이 좋겠다.
일단, join이 왜 필요한가에 대해 의문을 가져본 적이 있는가?
이 의문은 결국 "왜 굳이 데이터를 나누는가? 나누지 않고 한번에 조회하면 되지 않나?에 대한 생각에서 출발한다.
2-1. 데이터 모델링
요구사항에 맞는 데이터의 "표현"은 데이터 모델링의 근간이다.
좀 더 풀어서 기술하면, 데이터모델링이란
- 어떤 데이터가 필요한가
- 그러한 데이터를 어떻게 표현해야 하는가
- 이 표현한 데이터를 통해 필요 요구사항을 누락없이 나타낼 수 있는가
이에 대한 답변이며, 이 기본적인 맥락에서 데이터 연결(정규화) 및 설계가 이루어진다. 즉 말 그대로 "모델링", 즉 설계의 일환이며 비즈니스 로직에서의 "연산"/"처리"와 구분해야 하는, 그 연산보다도 선행되어야 하는 과정이다.
2-2. 정규화의 필요성
예를 들어, 김철수와 이영희가 각각 2개의 주문을 하였다고 하자.
주문 테이블에 이 주문내역을 아래와 같이 "표현"하도록 모델링하였다고 하자.
- order id : 1 / order name : 김철수 / order email : kim@mail / product name : 키보드
- order id : 2 / order name : 김철수 / order email : kim@mail / product name : 청소기
- order id : 3 / order name : 이영희 / order email : kim@mail / product name : 두부
- order id : 4 / order name : 이영희 / order email : kim@mail / product name : 마우스
물론 이 상황에서는 데이터를 굳이 나누지 않고, 하나의 저장소에 모든 데이터를 우겨넣었기때문에 join이 필요없고, 굳이 다른 테이블도 만들지 않아도 된다는 생각이 들 수 있다.
하지만 이 join을 제외한 나머지 관점에서 큰 문제가 생겨버린다.
Data Redundancy : 데이터 중복
하나의 테이블에 김철수 이름, 김철수 이메일이 중복이 된다. 만약 김철수가 100개의 상품을 주문했다면? 100개의 김철수와 그의 이메일 데이터가 계속 쌓일 것이다.
하나의 데이터 저장소에 100개, 200개의 데이터가 중복으로 쌓이면 그것은 데이터 중복이고, 저장공간의 낭비이다.
갱신 이상(Update Anomaly)
이 상태에서 김철수가 이메일을 바꾼다고 한다면, 김철수가 주문한 주문개수만큼 쌓인 데이터에 대해 일일이 수정 작업을 진행해야 한다. 수정을 하다가 하나라도 누락이 된다면, 데이터의 일관성이 그대로 깨져버린다.
삽입 이상(Insert Anomaly)
만약 새로운 상품인 옥수수를 주문한다고 하자. 이 새로운 상품을 이 테이블에 "등록"하기 위해서는 반드시 주문이 선행되어야 하는 구조로 모델링이 이루어진 상황이기에, 새로운 상품 등록 자체가 불가능한 상황이다.
우리가 주문할때 등록된 상품을 대상으로 주문을 진행해야 하는데, 상품이 등록되지 않은 모순적인 상황이 발생한 것이다.
삭제 이상(Deletion Anomaly)
만약 김철수라는 회원이 탈퇴했다고 하자. 이 회원이 주문한 100개의 상품이 있다면, 100개의 상품에 대해 일일이 회원의 탈퇴 여부를 기록하거나 별도의 표시를 남겨두어야 하겠다.
반대로, 주문 내역 하나를 만들었던 "홍길동"이라는 사람이 해당 주문을 삭제하였다면, 홍길동이라는 사람 정보 자체가 아예 없어질 수도 있다.
이러한 이유로 데이터 분리, 정규화는 반드시 필요하다.
2-3. 사람이 이해할 수 있는 의미있는 데이터를 추출하기 위한 과정 - JOIN
데이터 분리가 이루어졌다면, 사용자 중심의 의미있는 데이터를 표현하기 위해 데이터 통합, merger 작업이 필요하다.
마치 컴파일러를 통해 .java 파일을 컴퓨터가 이해할 수 있는 바이너리 코드로 변환하는 과정과 맥락이 동일하다.
이러한 통합과정을 가능하게 해주는 연결고리의 역할이 바로 JOIN이며, 이를 위한 연결관계를 구성하기 위해 FK(다른 테이블에서의 PK를 보통 활용)를 사용하는 것이다.
이 과정을 통해, 데이터 분리 즉 정규화가 필요한 이유, 더불어 데이터 모델링이 왜 필요한지 자연스럽게 이해할 수 있다.
그리고 이러한 이해를 바탕으로 DB table, 연결관계, 모델링 등 데이터를 다루기 위한 관점과 고민의 방향성을 탄탄하게 다질 수 있다.
단순히 join이 왜 필요한가?에 대한 기술적 이해가 아닌, 이것이 왜 고민의 시작점인지, 이로 인해 어떤 기술에 대한 방향이 잡히고 근간이 이루어지는지 살펴볼 수 있었다.
3. index
데이터를 표현하는 방법 중, 그 데이터를 조회하는 속도를 빠르게 하기 위한 성능개선사항을 고려하기위해 Index를 생각해볼 수 있다.
사실 index 자체가 데이터 모델링과는 연관성이 적을 수 있겠으나, 넓은 의미에서 데이터를 표현하는 방법으로 간주할 수 있고 무엇보다 Database 개념에서 빼놓을 수 없는 핵심 개념이기에 다시 짚고 넘어가는 의미에서 기록해보고자 한다.
결론부터 살펴보자.
인덱스가 없는 테이블에서는 옵티마이저 측에서 아무런 힌트없이 모든 데이터를 일일이 탐색하고 찾는 FULL TABLE SCAN이 발생한다.
DB사양(CPU/디스크 I/O)에 따라 다르지만 보통 1000만건 기준 수초 ~ 1분이상 소요되며, 2~3초 이상만 넘어가도 사용자 입장에서는 긴 로딩시간으로 인한 서비스 이탈이 발생하기에 성능적으로 개선점을 반드시 확보해야 한다. 참고로 위에서 기술한 "수초"도, 기업용 서버 환경인 SSD 디스크 기반의 한 row 당 1KB 데이터 기준이며, 실무에서는 표현하는 데이터가 많아 1KB 그 이상이 될 수 있기에, 더 소요 될 수 있다.
이때 사용하는 것이 인덱스인데, 인덱스가 왜 조회속도를 빠르게 해줄 수 있는 것일까?
인덱스와 대응하는 개념인 사전에서, 원하는 데이터를 찾는 속도를 빠르게 할 수 있는 근간은 "데이터가 정렬되어있는 기준을 알고, 이를 색인(특정 데이터의 형태 및 해당 데이터의 원본 위치)으로 원본 데이터의 포인터를 직접적으로 알려주기 때문"이다.
- 사전에서는,
"가, 1페이지" , "나, 105페이지" 등과 같이 데이터를 찾아가는 힌트, 이정표를 사용자에게 알려주었다면,
- 인덱스에서는,
달라지는 것은 없다. 동일한 원리로 특정 컬럼의 값과 해당 값이 원본 테이블의 어디에 위치하는 지에 대한 포인터(주소값, PK값 등)를 가진다.
인덱스 자체가 DB는 아니지만, 데이터와 그 위치를 저장해주는 자료구조의 일종이다.
4가지 인덱스 사용 방법 : 2
SQLP Guide : 13
인덱스에 대해 알아보자 : 27
삼성 갤럭시 워치 : 5이와 같이, "정렬되어있는 데이터"를 기반으로 그 데이터가 어디에 위치하는지 알려주는 것이 바로 인덱스의 역할이자 본질적인 개념이다.
데이터 옵티마이저 입장에서는 이와 같은 기준으로 정렬되어있는 데이터를 탐색할때, 마치 사전 색인을 참조하듯이 원하는 데이터의 위치를 인덱스를 통해 얻고 빠르게 도달할 수 있기에 FULL TABLE SCAN에 비해 압도적인 조회성능을 확보할 수 있다.
SELECT * FROM ITEMS
WHERE ITEM_NAME LIKE '%SQLP%'이처럼 테이블의 데이터를 검색할때 그 검색 "기준"이, 인덱스의 "정렬 기준"과 동일하다면 당연히 그 정렬된 데이터를 탐색하기 위한 힌트, 위치를 얻기위해 옵티마이저는 인덱스를 참고할 것이며, 자연스럽게 조회 성능이 개선될 수 밖에 없을 것이다.
3-1. "보편적인" 인덱스 구조 - 이진탐색트리
인덱스가 pk를 기반으로 원본 데이터를 보관하는 클러스터 인덱스, 원본 데이터의 pk(포인터)를 보관하는 보조 인덱스로 구성되어있는 것은 잘 알고 있을텐데, 유의해야 할 점은 결코 모든 DB에 전역적으로 물리적인 인덱스 구조 및 구현, 작동방식이 통용되는 것은 아니라는 점이다.
즉, 클러스터 및 비클러스터(보조) 인덱스라는 구조 자체가 인덱스에 통용되는 구조는 맞지만 세부적인 구조나 동작방식에 있어서 DB별로 약간의 차이가 존재한다.
이에 대한 내용은 별도 벨로그 글로 남기도록 하고, 중요한 것은 이러한 인덱스의 "본론"은 DB 전역적으로 통용이 된다는 점이다.
그 시작점은 트리 자료구조이다.
10
5 18
2 7 16 21이처럼, 상위 계층에 있는 노드를 기준으로 왼쪽에 작은 값, 오른쪽에 큰 값을 저장하는 자료구조를 이진탐색트리라 한다.
이진탐색트리의 알고리즘을 기억하는가?
while(currentTree != null){ //getData -> NPE
parentTree = currentTree;
if(currentTree.getData() > data){
currentTree = currentTree.getLeftSubTree();
}else if(currentTree.getData() < data){
currentTree = currentTree.getRightSubTree();
}else if(currentTree.getData() == data){
System.out.println("이진트리의 데이터 삽입은 중복을 허용하지 않습니다.");
return;
}
}이진탐색트리의 중요 관점은 데이터를 입력하는과 동시에 정렬을 진행하여 보관한다는 점이다.
만약 위 데이터 중 9를 찾아간다면?
최초 10에서, 7는 10보다 작으므로 왼쪽 노드로 탐색을 이어가고, 그 이후에 5보다 크므로 오른쪽 노드로 탐색을 이어간다.
각 노드와의 대소비교만으로 탐색 범위의 절반을 줄일 수 있고, 이에 따라 일일이 선형적으로 데이터를 비교하는 것과 대비하여 엄청난 조회 성능을 기대할 수 있게 된다.
이것이 가능한 이유는 데이터가 이미 정렬되어있고, 그 정렬된 기준을 조건으로 데이터를 추출하고자 하기 때문이다.
참고로, 이러한 이진탐색(BinarySearch)을 통해 O(N)의 시간복잡도를 O(logN)으로 획기적으로 줄일 수 있다
3-2. 밸런스트리(Balanced Tree)
하지만 이진탐색트리 구조를 활용한다고 하여, 무조건적으로 O(logN)의 시간복잡도를 가질 수 있는 것은 아니다.
UnBalanced Tree,
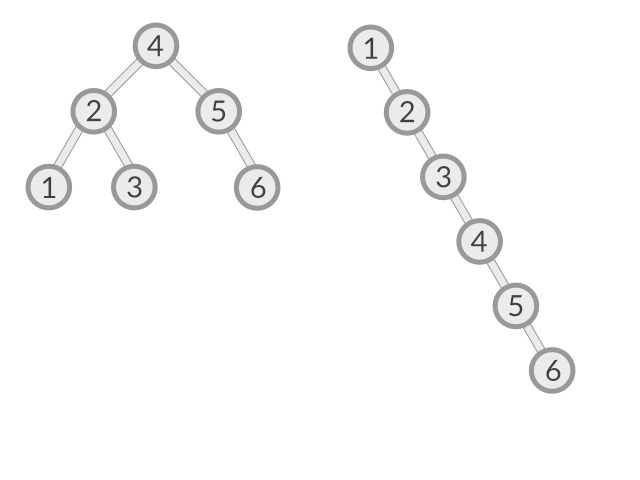
위와 같이 이진탐색트리의 정의에 따라 데이터를 곧이 곧대로 넣는다면, 노드가 한쪽 방향으로 치우쳐져 실제 데이터 탐색 시 선형적으로 데이터를 탐색하게 된다. 이 경우 이진탐색의 의미가 없어지기에 이에 대한 밸런스 작업, 균형작업을 동적으로 진행하는 자료구조가 바로 밸런스 트리이다.
밸런스 트리의 대표적인 예시로 AVL, 레드-블랙 트리가 있으며, 데이터 정렬 시 최초 삽입한 데이터를 루트노드로 간주하여, 동적인 정렬 및 밸런싱이 이루어진다.
이진탐색트리는 검색성능을 O(logN)로 개선할 수 있지만, 데이터 삽입 시 위와 같은 균형이 발생하지 않는다면 O(N)의 성능을 보일 수 있다. 여기서 나아가, 기존 단일 노드 별로 단일 데이터를 보관하는 구조적 한계를 B-/B+트리를 통해 여러개의 자식노드를 가질 수 있도록 구조적 개선도 이루어졌다.
현대적인 DB들은 B-/B+트리를 인덱스의 보편적인 형태로 활용하며, 한 노드에 들어있는 데이터를 단일 관계가 아닌, 여러 자식 노드를 통해 저장할 수 있는 다수의 구조로 개선하여 데이터를 탐색하기 위해 디스크를 들락날락하는 I/O비용을 줄일 수 있었다.
즉 관계형 데이터베이스의 이진탐색트리는 항상 균형잡힌 상태를 유지하고 있고 자식 노드를 다수 위치시켜, 데이터를 탐색하기 위한 디스크 I/O를 확실하게 줄이고 이에 따른 조회 성능을 개선할 수 있었다.
이러한 밸런싱 트리를 기반으로, 정렬된 상태의 데이터와 PK(클러스터 인덱스)를 저장하여 테이블의 원본데이터를 찾기 위한 색인으로 활용할 수 있기에, 대용량 데이터 내 찾고자 하는 항목을 효율적으로, 빠르게 찾을 수 있게 되었다.
3-3. 유일성의 척도(카디널리티)
인덱스를 생성하기 위한 여러 기준이 있을텐데, 보통 중복도가 낮고(유일성의 정도가 높고) 이에 따른 정렬기준을 많이 사용하는 항목을 중점적으로 활용할 것으로 생각할 수 있다.

인덱스 자체적으로 이러한 "인덱스로 활용하기 위한 기준"에 대한 중요도를 잘 알고 있기에, 위 그림처럼 데이터 중복에 대한 척도를 나타내기 위해 카디널리티값을 별도로 추출하여 나타내기도 한다.
카디널리티는 해당 데이터의 유일성을 나타내기 위한 척도로, 카디널리티가 높다면 유일성의 척도가 높아 데이터가 중복이 되지 않는다.
데이터 색인을 나타낼때 가장 기본적인 전제조건은 해당 데이터의 중복 정도가 낮느냐일 것이다. 데이터가 기본적으로 중복정도가 낮아야 데이터 별로 유일한 색인, 참조가 가능해지고 치우친(unbalanced) 정렬이 일어나지 않을 것이라는 어느 정도의 "보장"을 할 수 있기 때문이다.
3-4. 옵티마이저의 실행 계획
데이터 모델링에 인덱스를 활용하기 위해서는 해당 인덱스를 옵티마이저가 적절하게, 올바른 방향으로 사용하고 있는지 옵티마이저의 실행 계획을 먼저 살펴볼 필요가 있다.

위와 같이 실행할 쿼리에 대해 EXPLAIN을 질의하면, 데이터베이스에서 옵티마이저가 해당 쿼리를 실행할 계획에 대해 응답을 한다.

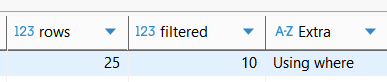
이 구성사항에 대해 찬찬히 살펴보면,
- type - 옵티마이저가 테이블의 데이터에 어떠한 전략으로 접근하는지를 나타낸다. ALL은 모든 테이블 데이터를 스캔하는 full table scan, 만약 인덱스를 사용한다면 Covering, secondary 등의 인덱스를 사용할 것이다.
- key - 쿼리를 실행할때 사용한 인덱스(key name)을 보여준다.
- ref(range) - 인덱스를 사용한 조건으로, 동등조건/범위조건/ORDERB BY를 통한 정렬조건 등 여러 방안이 존재한다.
- rows : 쿼리를 실행하기 위해 원본 데이터를 몇개 탐색할 것인지에 대한 개수이며, 위의 경우 25개의 전체 데이터 모두 탐색하는 full-table-scan이 발생한다.
- filtered : 기본적인 데이터 탐색 후(rows) where 조건 등으로 추가적인 필터링을 통해 몇개의 데이터를 선별할 것인지에 대한 비율로, %단위로 봐야한다.
- extra : rows를 추출한 후에 추가 선별을 위해 필터링 작업을 수행한 전략을 기재하며, 위의 경우 모든 데이터를 탐색한 후 추가적인 필터링 작업을 거치는 경우로 판단할 수 있다.
위와 같이 옵티마이저의 실행계획을 통해 인덱스를 적절하게 활용하였는지, 인덱스를 적절하게 구성하였는지 파악하고 이해할 수 있어야 한다.
3-5. 인덱스 사용 시점
옵티마이저가 인덱스를 사용하는 "시점"은 주로 정렬된 데이터와 찾고자 하는 데이터의 기준이 동일한 경우로, 그 경우는 동등조건(=), 범위조건(<,>), order by 정렬 조건 등 크게 3가지 상황에 대해 적용해볼 수 있다.
- 동등조건 : ref type
먼저, 동등조건의 경우 말 그대로 동등조건(=, join)일때 인덱스를 사용했다는 의미이다.
예를 들어,
SELECT *
FROM TABLE
WHERE COLUMN_NAME = '?';라는 쿼리를 동작하였을때, 위 WHERE 절에서의 동등조건에 대한 정렬 데이터를 인덱스를 통해 먼저 순회하여 찾는다.

이 경우, type이 ALL이 아닌 인덱스를 참조한 "ref"가 되고, 그때 사용한 index의 key name을 옵티마이저의 실행계획에 나타내게 된다(참고로 possible keys에서 사용가능한 인덱스 목록을 나타내며, 이 중 하나의 인덱스를 활용한다).
인덱스를 사용한다면 모든 데이터를 훑는게 아닌, 미리 데이터를 찾은 후에 진행이 되므로 rows가 찾는 데이터 그 자체로 나타나거나 이분탐색하여 범위를 많이 좁힌 데이터의 개수가 나타난다.
위의 경우 이미 부합하는 데이터 그 자체를 1개 찾았기때문에, Extra를 통해 추가적인 필터링없이 곧바로 원하는 데이터를 반환하여 Extra는 공란으로 나타나고, filtered 비율 역시 그대로 추출하여 100%의 효율을 보인다.
- 범위조건 : range type
말 그대로 WHERE 절에서의 범위조건에 대한 정렬 데이터를 인덱스를 통해 찾는다는 의미이다.
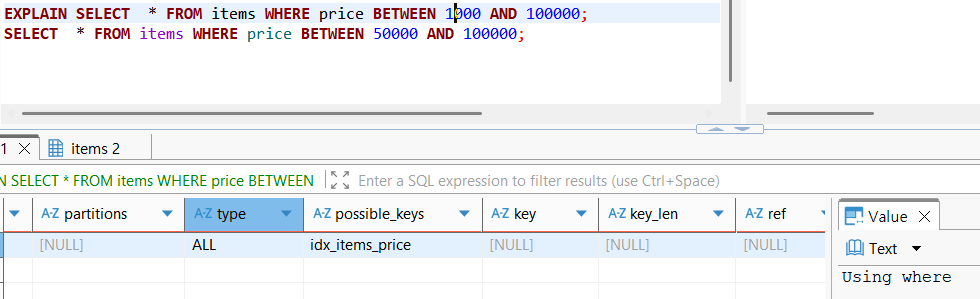
EXPLAIN SELECT *
FROM TABLE
WHERE COLUMN_NAME BETWEEN 50000 AND 100000;위와 같이 범위조건에 해당하는 쿼리를 동작하였을때, 이에 해당하는 정렬 데이터가 인덱스에 존재하지 않는다면 full table scan을 피할 수 없다.
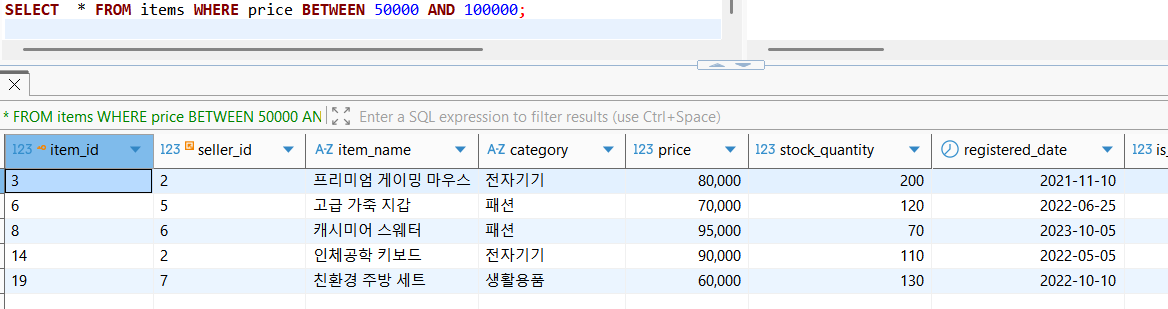
이처럼 실제 결과가, 예상한대로 full table scan을 진행한 후 원본 데이터에서 찾은 순서(PK)대로 데이터를 조회해온것을 확인할 수 있다.
이때 직관적으로 "정렬된 데이터를 인덱스에서 찾아야하므로", 자연스럽게 인덱스에 COLUMN_NAME의 데이터가 숫자 순으로 정렬이 되어야겠구나 라는 생각이 들게 된다(범위의 데이터를 찾기 위해 해당 데이터가 숫자순으로 정렬이 되어있어야 하겠다).
인덱스를 아래와 같이 만들었다면,
price : 5000, item_id(PK) : 16
price : 15000, item_id(PK) : 5
price : 20000, item_id(PK) : 21이런식으로 위 데이터의 경우, price에 해당하는 데이터가 문자(알파벳) 순이 아닌 숫자의 크기 순서대로(오름차순) 정렬이 되어있는 인덱스가 생성될 것이다.
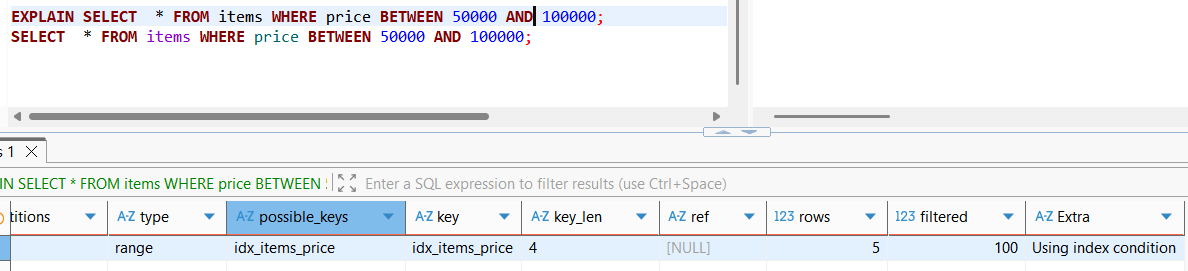
실제로 옵티마이저의 실행계획을 살펴본다면, 범위조건(BETWEEN)에 대해 인덱스를 사용하여 type이 range로 기재되어있음을 확인할 수 있고, key name에 해당 사용 인덱스명이 명시되어있는 것 역시 확인 가능하다.
다만, 범위 조건의 경우 인덱스에서 정렬된 데이터를 먼저 찾은 후에, 필터링이 어느 정도 필요할 것이다. 위의 경우 필요한 데이터 5개를 바로 찾고 필터링 비율이 100%이며, Extra 필터링 내역에 index condition을 사용하여 원하는 데이터를 바로 추출하였으나 복잡한 쿼리라면 추가적인 필터링이 필요할 수 있을 것이다.
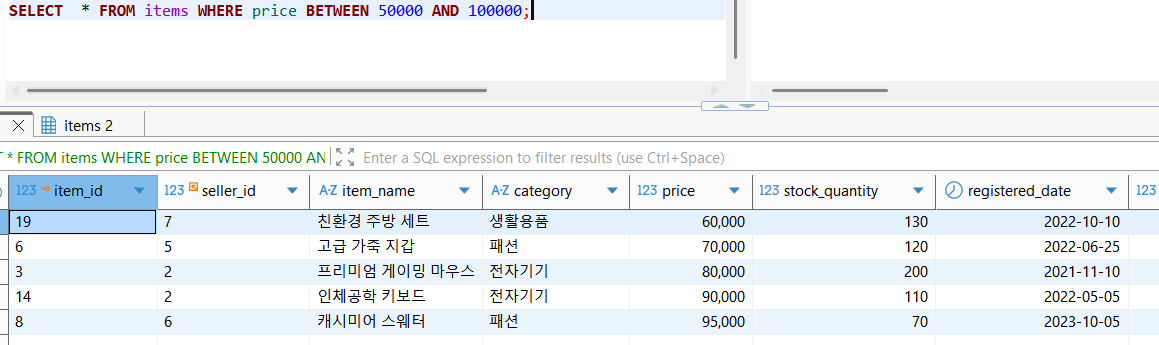
더 눈여겨 볼 부분은 쿼리의 결과이다. 보다시피, 위에서 full table scan으로 찾은 pk 순서대로 데이터를 추출한 것과 달리 인덱스에서 찾은 정렬 결과 그대로(price 오름차순) 데이터를 추출해온 것을 확인할 수 있다(구체적으로는 인덱스에 해당하는 정렬데이터를 순서대로 찾고, 그 순서 그대로 원본데이터를 추출해왔다).
- LIKE 범위조건 : range type
EXPLAIN SELECT *
FROM TABLE
WHERE COLUMN_NAME LIKE '?%'LIKE절에서 index를 사용할 수도 있는데, 위와 같이 와일드카드를 문자 뒤에 기재하였을 경우 인덱스 활용이 가능해진다.
'%문자열%', '%문자열' 등 와일드카드 양 옆 혹은 앞쪽에 위치한 경우는 인덱스 활용이 불가능한 점에 유의하자.
참고로, 중간에 원하는 문자열이 있어서 이러한 특정 문자열에 대한 데이터를 검색하고자 한다면 전문검색(full-text-search)라는 별도의 기능을 사용하거나, 이를 위한 트라이(Trie) 알고리즘을 사용하는 등의 전략을 고민해야 한다.
- 정렬에 사용하는 인덱스 : range type
조회 쿼리에서 ORDER BY라는 정렬 작업을 사용한다면 내부적으로 추가 정렬작업인 file sort 작업을 진행하게 된다.
이 정렬 작업은, 조건에 맞는 데이터를 모두 추출해온 후 메모리 혹은 디스크에 저장하여 해당 결과를 바탕으로 추가적인 정렬을 수행하는 번거롭고 무거운 작업이다.
order by 정렬 시 핵심 포인트는 인덱스에 정렬되어있는 상태가 where 조건에 사용하는 정렬대상 및 order by 조건에 사용하는 정렬조건이 동일하게 구성되어, file sort를 사용하지않고 인덱스만으로 원하는 데이터를 바로 추출해오는 경우이다.
바로 이러한 이상적인 상황을 구성하는 것이 order by의 최적화라 할 수 있겠다.
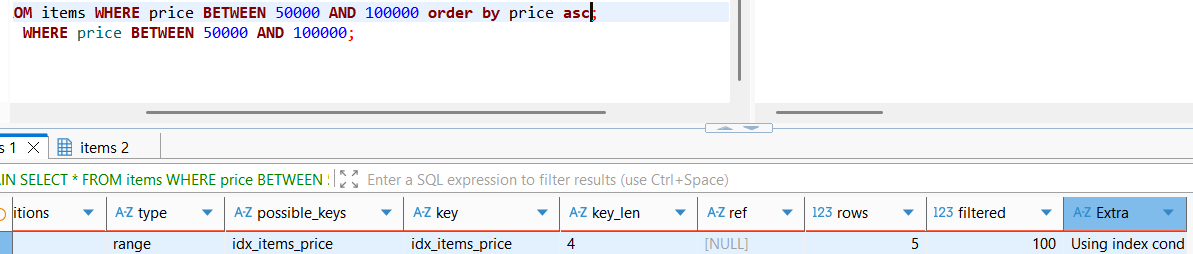
즉 위 range type처럼, 인덱스에 정렬되어있는 데이터가 찾고자 하는 데이터 및 정렬조건 모두 부합하는 경우를 최대한 맞춰주는, 쉽게 말하면 order by라는 작업이 필요하여도 filesort를 진행하지 않고 인덱스를 통한 즉시 데이터 추출이 가능한 설계와 분석이 반드시 필요하다.
참고로 인덱스를 활용한 데이터 항목 및 정렬 조건이 부합한다면, 옵티마이저의 인덱스 활용은 정방향과 역방향 모두 가리지 않고 사용 가능하다.
즉, order by asc 이든 desc이든 상관하지 않고 bacward index scan이 가능하기에, 여전히 filesort를 진행하지 않은 효율적인 인덱스 스캔이 가능해진다.
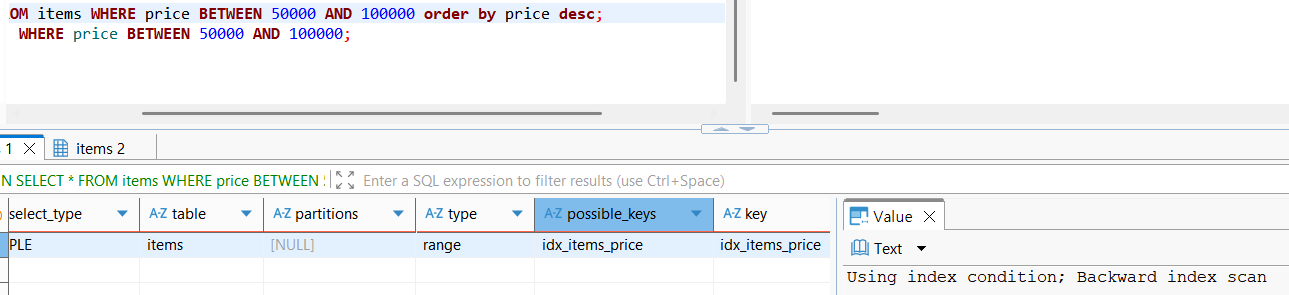
이처럼 범위조건에 해당하는 인덱스를 활용하였을때, 정렬조건이 역방향이더라도 Backward index scan을 통해 양방향 스캔이 가능하여 데이터 조회의 성능효율을 유지할 수 있다.
참고로, 정방향 스캔의 경우 메모리에 미리 올려두는 미리읽기(Prefetching)가 가능하며 역방향 스캔의 경우 미리읽기를 진행할 수 없기 때문에 이로 인한 성능차이가 발생할 수 있으나, 이 차이는 매우 매미하기에 무시할 수 있는 정도이다.
order by를 인덱스를 활용하지 못하고 filesort까지 활용하게 하는 구조적, 설계적 개선이 훨씬 더 중요하고 시급한 문제임을 유의하자.
MySQL 8.0부터는 역방향 스캔을 아예 내림차순 인덱스(Descending Index)로 제공한다. 단일 컬럼에 대한 조건에서는 성능 차이가 미비할 수 있지만, 다수의 컬럼에 대한 조건에서 범위 조건이 정방향, 역방향 혼합되어있다면 이러한 내림차순 인덱스는 빛을 발휘할 수 있다.
이 개념이 나아가, 복합 인덱스(다중 컬럼에 대한 정렬 데이터를 저장하는)까지 이어지므로 이 필요성에 대한 흐름을 자연스럽게 유지하고 기억하는 것이 필요하겠다.
만약 이러한 인덱스 탐색들의 비용 자체가 full table scan보다 클 경우, 즉 데이터 규모가 그리 크지 않을 경우 full table scan을 옵티마이저 측에서 사용할 수 있다. 만약 굳이 인덱스 사용을 강제하고 싶다면 force index하여 인덱스를 의무적으로 활용할 수 있도록 조치할 수 있지만, 굳이 권장하지는 않는다.
4. 옵티마이저
데이터 모델링에서 인덱스와 함께 빼놓을 수 없는 개념이 바로 옵티마이저, 특히 옵티마이저의 실행 계획이다.
위 내용만 보면, 이미 정렬된 데이터를 그대로 사용하기에 WHERE 조건에 해당하는 데이터 (정렬) 대상 및 정렬 조건에 부합하는 내용이 인덱스에 존재한다면 무조건적인 성능 향상이 일어날 것으로 기대할 수 있는데, 옵티마이저는 생각보다 똑똑한 놈이다.
옵티마이저는 인덱스가 존재한다고 하여 무조건 인덱스 스캔을 선택하는 것이 아니라, 쿼리를 실행하기 전에 스캔 방법을 먼저 탐색하여, 인덱스를 사용하는 것이 full table scan에 비해 더 비효율적이라 판단하면 인덱스 스캔이 아닌 풀 테이블 스캔을 선택한다.
만약 인덱스의 정렬된 데이터를 통해 범위 자체를 줄일 수 있더라도, 이를 통해 추출해야하는 데이터가 원본 테이블에 흩어져 I/O비용이 더 크다고 판단하면 원본 테이블을 바로 읽는 풀테이블 스캔을 진행하게 된다.
말 그대로, 테이블을 일단 읽어버리는 것이 인덱스 스캔을 통한 번거로운 추출 작업에 비해 데이터 조회의 성능에 더 유리하다고 판단한 것이다.
4-1. 손익분기점
위의 분기, 즉 옵티마이저가 인덱스 스캔을 선택할 것인지 혹은 풀 테이블 스캔을 선택할 것인지 판단하는 기준을 손익분기점이라 지칭한다.
즉, 인덱스를 통한 스캔 비용이 풀 테이블 스캔 비용보다 오히려 더 높아져 비효율적인 상황을 의미한다.
이 경우를 간단하게 표현하면,
인덱스를 탐색하고, 인덱스에서 찾은 주소로 원본 테이블에 랜덤으로 접근하는 비용이 풀 테이블 스캔을 통해 순차적으로 접근하는 비용보다 클 경우
보통 이러한 상황은 데이터양이 전체 원본 테이블의 20~25% 이상을 조회해야 한다면, 인덱스를 통한 랜덤한 접근보다 차라리 원본 테이블의 순차적 접근을 통해 데이터를 추출하는 경우에 발생한다.
물리적인 동작으로 살펴보면 꽤나 납득이 갈 수 있다.

관계형 데이터베이스가 데이터를 저장하는 공간은 기본적으로 HDD, SSD와 같은 디스크 공간이다.
- 풀 테이블 스캔을 통한 순차(Sequential) I/O가 발생한다면
최초 데이터 위치를 찾아낸 이후, 데이터가 연속되어 있는 상태를 그대로 추출하면 되기에 디스크를 순차적으로 조금씩 움직여 I/O비용이 꽤나 감소할 수 있고, 그만큼 작업이 빨라지고 효율적일 수 있다.
SSD의 경우, 컨트롤러 측에서 최초 데이터를 기준으로 100~200개를 그대로 가져오면 된다는 큰 명령 하나만 내릴 수 있기에 이 역시 처리효율이 높다.
- 인덱스 스캔을 통한 랜덤 I/O가 발생한다면
반면 인덱스 스캔을 통해 Random I/O가 발생할 경우, 디스크를 왔다갔다하면서 원본 데이터를 추출해오므로 I/O비용이 그만큼 추가, 느려질 수 밖에 없다.
SSD 역시 5페이지 > 2페이지 > 15페이지 > 9페이지 등..큰 명령어 1개가 아닌 작은 명령어를 수없이 쪼개어 번거로운 실행을 진행해야하기에, 이 경우 순차 스캔보다 더 비효율적인 상황으로 귀결될 수 밖에 없다.
따라서 이러한 손익분기점 상황에서, 특히 찾아야할 데이터양이 25%를 상회할 경우 옵티마이저는 차라리 인덱스 스캔보다 풀 테이블 스캔이 더 낫다고 판단하여 풀 테이블 스캔을 선택하게 된다.
예를 들어, 위와 같이 range type의 인덱스 스캔을 선택하였더라도 같은 쿼리에서 데이터 개수를 더 많이 추출하도록 조정할 경우,
type ALL(풀테이블 스캔), 및 Using Where로 필터링하는 순차적 I/O를 옵티마이저에서 선택하였음을 확인할 수 있다.
물론, 데이터 자체가 매우 적다면 이 역시 인덱스 스캔보다 풀 테이블 스캔을 사용하여 데이터를 조회해올 것이다. 그렇기에 소량의 테스트 데이터의 상황에서 인덱스 성능을 확인하고자 할 경우, 인덱스 사용을 강제해야 할 수 있다.
아니면, 테스트 데이터를 실무 데이터 수준까지는 아니더라도 충분하게 많이 생성(100만개 정도만 되어도 테스트 가능)하여 인덱스 성능을 확인할 수 있고, 그러한 테스트 전략과 방향으로 고민하는 것이 중요하겠다.
4-2. Covering Index
이처럼 인덱스는 무조건적으로 조회 성능을 향상할 수 있는 만능적인 장치가 절대 아니다.
이 인덱스 대신 풀 테이블 스캔을 유발하는 손익분기점의 "트리거"는 원본테이블로 접근하는 Random I/O이다. 데이터의 절대적인 양을 고려사항에서 배제하고, 인덱스 스캔 후 디스크 접근 비용 및 번거로움을 유발하는 Random I/O로 인해 인덱스 스캔 대신 풀 테이블 스캔을 선택하게 된다는 것이다.
따라서, 인덱스만으로도 원하는 데이터를 모두 추출할 수 있는 "수용력"이 높은 데이터 및 구조를 구축해야 하는데, 이처럼 원본 테이블 접근 필요없이, 인덱스만을 읽어서 데이터 조회를 추출할 수 있는 경우를 Covering Index라 한다.
보통 SELECT, WHERE, ORDER BY, GROUP BY 등에 사용되는 모든 컬럼이 인덱스에 포함된 데이터라면 Covering Index의 조건으로 생각해볼 수 있겠다.
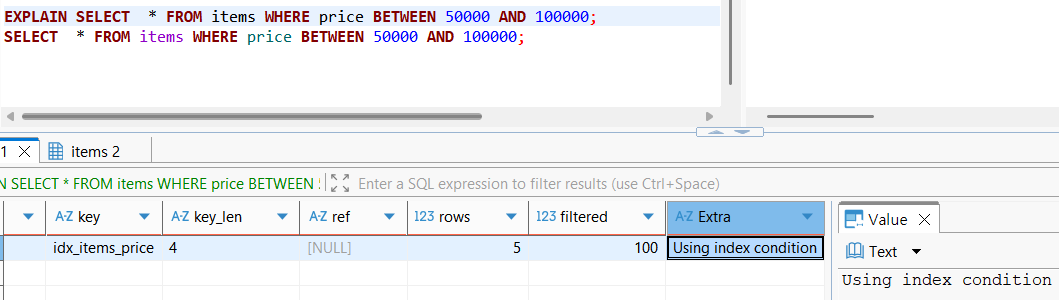
EXPLAIN SELECT item_id, price, item_name FROM items WHERE price BETWEEN 50000 AND 100000;예를 들어, 위와 같이 일전에 인덱스(price 가격에 대한)를 생성한 상태에서 조회 대상을 추가하였다고(price / item_id / item_name) 가정해보자.
이 상태에서는 range scan(인덱스 스캔)을 사용하지만,
Extra에 별도의 추가 처리작업이 발생하여, Using Index Condition, 즉 Random I/O가 발생하였음을 유추할 수 있다.
참고로 item_id의 경우 PK이기에 인덱스에서 조회할 수 있다. 여기서 문제가 된 데이터는 바로 "item name"이다.
여기서 인덱스에 저장되어있는 item_id, price에 대해서만 조회 대상으로 설정한다면?
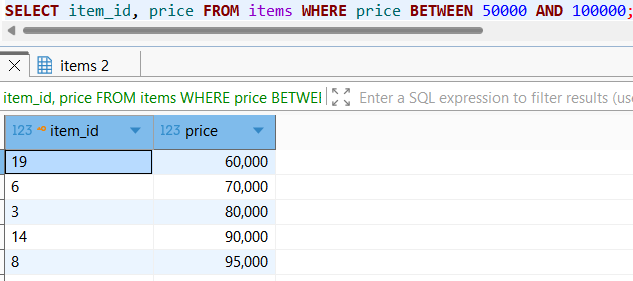
위와 같이 풀 테이블 스캔이 아닌 인덱스 스캔을 통한 데이터 (item_id순이 아닌 price 정렬 순) 추출이 발생하였음을 확인할 수 있으며,
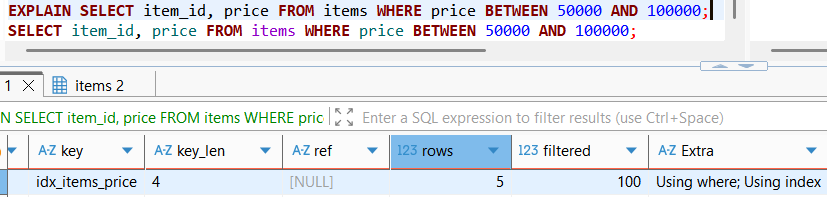
실제 옵티마이저의 실행 계획을 살펴보면, price에 대한 인덱스를 활용하고 인덱스에서 찾은 데이터에 대해 필터링한 Using Where/Using Index 전략을 사용하였음을 명확히 확인할 수 있다.
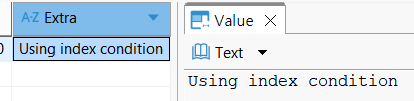
Using Index가 중요하다.
옵티마이저의 실행 계획에 Using Index가 기재되어있다면, Index만을 활용하여 데이터를 찾았다는 의미로 Covering Index의 증거이다.
이때 사용한 Using Where은 원본 데이터를 찾기위해 테이블에 들어가 random I/O를 한 것이 아니라, 인덱스에서 찾은 데이터를 Using Where을 통해 필터링이 이루어졌다는 것을 의미한다.
결론적으로는 이 쿼리는 Covering Index를 통해 테이블 접근을 피하고, 인덱스만을 활용한 데이터 조회가 이루어진 효율적인 쿼리임을 확인할 수 있다.
하지만 무작정 Covering Index를 사용해서는 곤란하고, 이후에 기술할 복합 인덱스를 사용하기 위해서는 인덱스를 저장하는 공간, 쓰기 작업에 대한 성능 trade-off까지 모두 고려해야 한다.
물론 Random I/O를 제거하고 인덱스만 사용함으로써 조회성능을 개선할 수는 있겠지만, 인덱스라는 원본 데이터 별개의 저장 공간이 필요하고, 원본 테이블의 INSERT/UPDATE/DELETE 등의 작업으로 인해 부수적으로 수반하는 인덱스 쓰기 작업까지 이루어지기에 작업 부하가 그만큼 커지게 된다.
따라서, 읽기 작업과 쓰기 작업 중간에서 저울질을 하여, Index를 어디까지 구성하는 것이 좋을까에 대한 고려를 하는 것이 필요하다.
보통은 쓰기 작업에 비해 조회가 빈번하게 발생하는 테이블에 대해 사용해야 하며, 보통 Covering Index는 성능 문제가 특징적으로 발생하는 특정 쿼리에 대해 적용하는 최후의 수단으로 사용하는 경우가 많다.
또한, 위의 경우처럼 인덱스에 저장하는 쿼리가 그리 많지 않을 경우, Covering Index를 적극 사용해보도록 한다. 조회해야하는 경우가 많다면, 모든 컬럼을 조회해야 한다면 Covering Index는 전략적으로 좋지 못한 선택일 수 있다.
4-3. 복합 인덱스
이제 조회대상을 추가해보자.
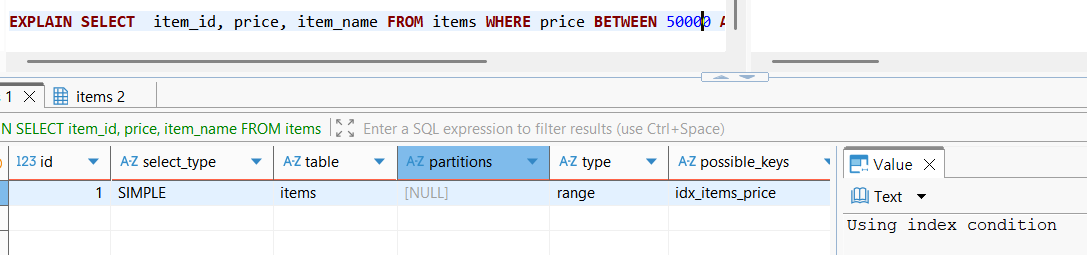
EXPLAIN SELECT item_id, price, item_name FROM items WHERE price BETWEEN 50000 AND 100000;1차적으로, 조회 대상을 추가하였으니 price 이외 item_name까지 포함하는, 다중 컬럼에 대한 복합 인덱스를 생성해보면 어떨까하는 생각이 들게된다.
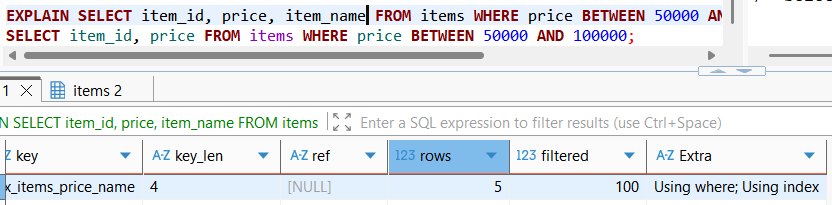
실제로 index를 price, item_name에 대해 생성하고 위 쿼리에 대한 옵티마이저 실행계획을 들여다보면 Using Index, 즉 커버링 인덱스로 동작하고 있음을 확인할 수 있다.
이는 인덱스에서 필요 데이터를 저장하고 있기에, 즉,
price : 5000, item_name : "1"
price : 10000, item_name : "2"이런 식으로 인덱스만으로 필요 데이터를 모두 추출이 가능하기에 커버링 인덱스를 최종적으로 실행계획으로 선택한 것이다.
이처럼 단일 컬럼이 아닌, 다중 컬럼을 대상으로 운용하는 인덱스를 복합 인덱스 혹은 다중 컬럼 인덱스라 한다.
복합 인덱스에서 중요한 것은 컬럼의 구성 순서이다.
위 인덱스에서 저장되어있는 데이터처럼, 복합 인덱스를 구성하면 저장한 컬럼의 순서대로 순차 정렬하여 데이터를 저장해둔다.
즉,
create index idx_items_price_name on items(price, item_name);위와 같이 인덱스를 생성하였다면, price 순 정렬 후, price가 동일할때 item_name 순으로 2차적인 정렬이 이루어진다는 것이다.
데이터 종류를 바꿔보자.
'전자기기' : '5000'
'전자기기' : '6000'
'헬스용품' : '1000'
'헬스용품' : '110000'이런식으로 데이터를 찾고자 한다면, 인덱스는 가격 순서가 아닌 item_type으로 먼저 정렬되어 있어야 한다. 즉, type > price 순의 정렬이 이루어져야 의미있는 데이터를 확보할 수 있을 것이다.
따라서, WHERE 조건에서 사용하는 A,B,C 컬럼이 있다면 인덱스 역시 그 조건 순서 그대로 구성되어 있어야 빛을 발휘할 수 있다.
이러한 규칙을 인덱스 왼쪽 접두어 규칙, Index-Left-Prefix_rule이라 한다.
위에서 기술한 모든 인덱스에 대한 내용을 기억하면서, 유의하면서 실무에 활용하도록 하자.
- 기본적으로 WHERE 조건(PK), JOIN 조건(외래키)에 사용하거나, 정렬에 많이 사용하는 대상을 인덱스에 넣어라.
- 동등조건(유일성이 높거나 특정할 수 있는 항목)을 앞으로, 범위 조건은 뒤로 하며, 이는 인덱스 뿐만 아니라 쿼리에서도 적용하여 서로의 규칙을 일치하여 사용하도록 하자.
- filesort를 피하기 위해 order by 조건과 일치하도록 인덱스 정렬에 적용하라.
- 복합인덱스가 필요하다면 조건에 필요한 컬럼 순서대로 구성하라.
어딜가나 trade-off는 무조건 존재한다.
인덱스는 만능이 아니다. 읽기 중심의 MIS 등에서 별도 테이블을 구성하여 사용한다면 적극적으로 인덱스 활용을 검토할 수 있겠으나, 실시간으로 데이터를 기록하는 로깅이나 거래/체결 테이블에는 인덱스로 인한 공간(보통 원본의 10% 차지) 및 쓰기 작업으로 인한 부하 증가로 인해 인덱스 생성을 제고하거나 충분한 고려를 통한 도입이 필요할 것이다.
이외에도, 복합인덱스를 힘들게 구성하였지만, 조건에서 사용하는 대상 및 정렬조건과 일치하지 않을 경우, 추출 데이터의 개수가 25%를 하회하더라도 옵티마이저 측은 full table scan을 선택할 수도 있으므로, 인덱스에 대한 정확한 이해를 기반으로 사용하자.
참고. Using Index Condition의 이면
아래의 쿼리를 실행한다고 하자.
EXPLAIN SELECT * FROM items WHERE category >= '패션' AND price = 20000;언뜻 보면 위에서 생성한 category, price 복합인덱스를 잘 활용하였나..하고 넘길 수 있으나 filtered에 주목해보자.
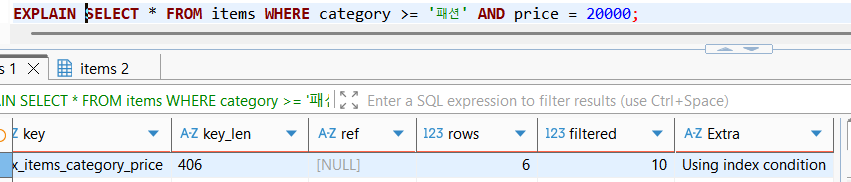
filtered가 10%밖에 안된다.
이 말은 Index를 활용하긴 하였지만, 실제 인덱스에서 추출한 데이터에서 추가적으로 원하는 데이터를 추출하기 위한 탐색 동작을 진행하였다는 의미로 볼 수 있다.
가령 위의 추출 조건이라면,
인덱스에 저장되어있는 "패션" 이상의 데이터들 중 동등조건인 가격 20000원 항목을 찾기 위해 하나하나 검사하고 필터링 하는 작업을 수반하게 된다.
즉, 원하는 데이터의 동등 조건이 가격이지만, 복합 인덱스에서는 1차적인 구성이 category로 되어있고 2차적 정렬 대상이 가격으로 되어있기에, 복합 인덱스에서 데이터를 찾고는 있지만 제대로 활용하지 못하고 이로 인해 10%의 필터링 결과만 얻게 되는 불합리한 결과를 확인할 수 있다.
따라서, 쿼리에서 사용하는 동등조건이 먼저, 그 다음에 범위 조건으로 구성이 되고 인덱스도 이러한 전제를 만족해야 인덱스의 제대로된 활용이 가능해진다.
또한 범위조건 대신 IN조건을 활용하여 쿼리를 구성할 수도 있다.
위의 where 조건에서 사용한 범위 조건 대신,
SELECT * FROM ~~~~ IN ('패션', '헬스뷰티') ~~~와 같이 IN을 사용하였다고 해보자.
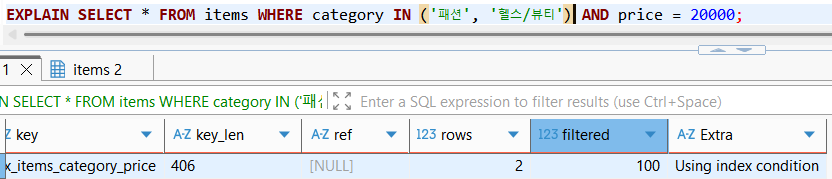
이 경우 위와같이 filterd 10%라는 수치가 아닌, 동등 조건으로 만족하는 category 탐색, 그 이후 해당 데이터의 가격 동등 조건 탐색으로 마치 동등조건을 2번 사용한 효과가 발생하여, 인덱스를 제대로 활용하였기에 원하는 데이터 2개를 명확하게 찾고 추출하였음을 확인할 수 있다(범위 조건에 필터링되는 요소가 소수라면, 범위조건 대신 IN 조건을 고려해보도록 하자).
이처럼 사소한 조건, 사소한 순서 하나하나를 튜닝해가면서 큰 효과와 효율을 얻을 수 있음을 반드시 기억하자.
참고. 복합인덱스를 활용한 성능개선 확인
기존 category, price를 조회하였을때 price에 대한 인덱스만으로는 random I/O를 피할 수 없고, Covering Index를 통한 극적인 성능 개선을 필요로 하기에 복합 인덱스를 사용하고자 한다.

위와 같이 category, price 순으로 idx_items_category_price라는 복합인덱스가 생성되었음을 확인하였다(=Seq_in_index).
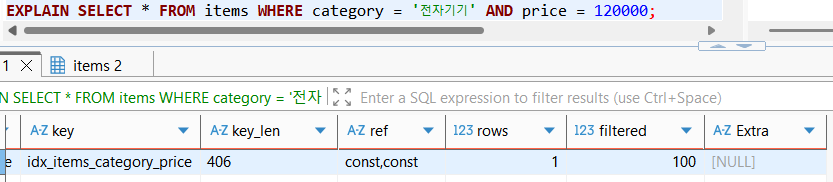
인덱스의 정렬 순서와 WHERE의 탐색대상 및 정렬순서가 정확히 일치하기 때문에, 인덱스 스캔(Type REF)을 사용하였으나 조회 대상의 컬럼이 인덱스에 모두 있지는 않으므로 Covering Index를 사용하지는 않았다(Random I/O 발생).
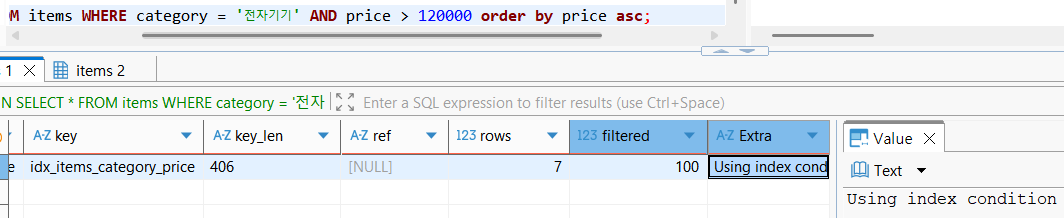
인덱스 내에서 정렬 조건과 order by의 정렬대상 및 그 조건이 일치한다면, filesort를 진행하지 않고 데이터 그대로 추출해올 수 있다.
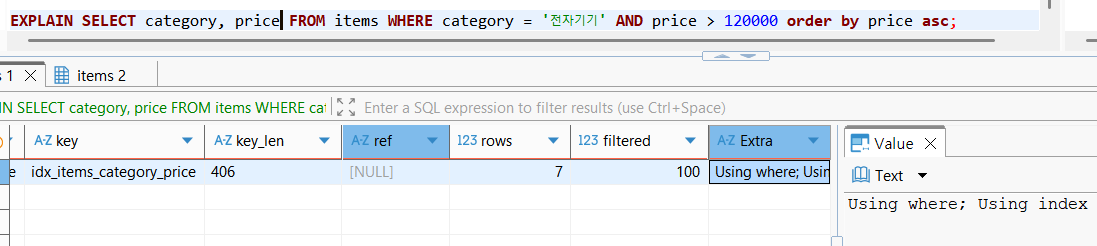
추출하는 데이터가 인덱스에 존재하고, where 및 order by 조건에서 사용하는 정렬대상 및 정렬조건이 인덱스에 완벽하게 존재할때 비로소 Covering Index 및 filesort 없는 인덱스의 온전한 활용이 가능해진다.
5. 데이터 무결성의 중요성
데이터 모델링의 또 하나 중요한 점은 저장하는 데이터의 무결성, 즉 결함이 없는 상태를 보장해야 한다는 것이다.
예를 들어 계약을 체결했음에도 체결한 사람의 내역이 존재하지 않거나, 체결한 거래액이 음수이거나, 주문수량이 음수이거나 혹은 0이거나 등..데이터베이스에 예상치 못한 잘못된 데이터를 저장한다면 이로 인해 발생하는 side-effect는 걷잡을 수 없이 커진다.
단순 유지보수, 운영 측면의 문제가 아닌 향후 개발 시 해당 오류 혹은 문제점이 다른 도메인에 전염될 수도 있고, 여러가지로 시스템의 논리적 다운을 유발할 수 있는 중요한 지점 중 하나이다.
Data Integrity, 데이터 무결성은 이처럼 시스템 전반에 향한 문제로 번질 수 있기에, 초입부터 그 성질과 규칙을 정확하게 정의하고 운용하는 것이 중요하다. 특히 애플리케이션의 1차적인 필터링을 맹신하지 않고, 기본적인 데이터 무결함을 지키기 위한 본질적인 접근이 필요하다.
단순 "제약조건"의 개념이 아닌, 운용과 전략의 개념으로 데이터의 정확성, 일관성을 지킬 수 있으며 시스템의 유지보수에 불필요한 비용을 제거할 수 있는 무결성 향상 항목에 대해 충분히 살펴보고 실무에 적용하는 것이 중요하겠다.
5-1. 데이터 유효성 관점에서의 제약조건
데이터를 수정, 삭제, 삽입할때 지켜야하는 규칙이자 조건이다.
NOT NULL을 통해 NULL값을 방지할 수도 있고, Unique를 통해 해당 데이터의 유일성을 보장할 수도 있다.
데이터의 중복성을 방지하고, 도메인의 특성을 지닌다면 NOT NULL과 Unique 특성을 모두 지니는 PRIMARY KEY로 구성할 수도 있겠다.
만약, 기본적인 데이터(상태값 등)를 지정하고 싶다면 DEFAULT를 사용하여 데이터 누락 방지 및 기본값을 명시적으로 지정해줄 수 있다.
이러한 제약조건은 유효한 데이터만을 넣기 위한, 데이터 유효성 관점에서의 제약 조건이다.
5-2. 테이블 무결성 관점에서의 제약 조건
그 범위와 규모를 넓혀, 단순 데이터가 아닌 테이블과 테이블 사이에서의 관계, 이에 대한 무결성을 보장해주는 제약조건이 있을 수있다.
예를 들어, 계약 체결을 할때 유령회원이 아닌 반드시 이미 존재하는 회원에 의해 계약체결이 진행되어야 한다.
이처럼 테이블과 테이블 사이의 관계에 대해 참조 무결성, Referential Integrity는 테이블의 관계와 내부 데이터까지의 유효성 및 일관성을 모두 보장하고 확보하기 위한 중요한 수단이다.
외래키(FK)의 경우, 보통 다른 테이블의 PK를 사용하기에 유령 회원의 계약 체결 혹은, 반대로 회원 정보가 삭제되었더라도 주문내역을 삭제하여 유령 주문 기록으로 남기는 결함적인 상황을 방지할 수 있다.
참조대상인 부모테이블(PK)과 이를 참조하는 자식테이블(FK)의 관계를 ON DELETE/ON UPDATE 처리 시 같이 삭제 혹은 수정할 것인가(CASCADE), 부모 테이블의 데이터를 먼저 삭제하는 것을 강제하거나(RESTRICT), 이를 참조하는 자식테이블의 데이터를 NULL로 설정(SET NULL)할 수 있다.
이러한 처리조건의 경우, 편리하지만 데이터 규모가 커질 경우 관리가 번거로워질 수 있으며(DB의 동작에 대한 상세 이해가 필요) 의도치 않은 비즈니스 동작이 이루어질 수 있다.
따라서, cascade 같은 옵션을 사용하기 보다는 이러한 부분들은 비즈니스 로직에게 그 책임을 위임하고 데이터 유효성에 대한 처리 및 관계 무결성 정도만 고려하여 구성하는 것을 권장한다.
5-3. 데이터 유효성 및 세부적인 특징에 대한 제약조건
체결수량 및 체결액이 음수가 될 수 없고, 확률을 저장한다면 0에서 1 사이의 값으로 저장하고자 한다.
이 경우, 데이터 유효성과 함께 그 세부적인 특징에 대한 규칙을 적용하기 위해 CHECK 제약조건을 고려해볼 수 있다.
이러한 제약조건 및 데이터 유효성 검증 등을 적극 활용하여, 무결하고 튼튼한 데이터와 나아가 테이블까지, 이를 보장하고 신뢰성을 향상할 수 있는 기본적인 수단이 될 수 있다.
사실 실무에서는 애플리케이션 로직(백엔드)으로 반영하는 것이 더 일반적이고, 개발자 입장에서는 이해하기 쉽고 편리할 수 있겠지만 project init 시점에서 장기적인 운용 관점에서본다면 기본적인 제약 조건들은 같이 명시해두는 것이 좋을 것이다. 나쁠 건 없다.
어찌되었든, 실무 상황 및 인프라를 잘 살펴보고 적절한 전략을 세우고 적용해보는 것이 중요할 것이다.
6. 결론
사실 이러한 인덱스는 InnoDB 엔진에서 적용할 수 있는 다소 제한적인 개념이다.
DB 전역적으로 B-, B+ Tree와 같은 데이터 저장 자료구조는 공통적인 요소이지만, 내부적으로 클러스터링 인덱스 자체 구조를 테이블 구조로 활용하는 MySQL과 더불어 인덱스를 단순 포인터 개념으로 사용하고 실제 테이블 데이터는 Heap 자료구조로 디스크에 보관한다.
하지만 MySQL의 인덱스 개념은, MySQL 자체가 널리 사용되는 DBMS이기도 하고 MySQL에서 사용하는 인덱스 개념을 이해하면 보통 다른 DB의 자료구조를 이해하는데 상당히 많은 도움이 될 수 있기에 기본기를 튼튼하게 잡아놓는 것이 좋을 것이다.
이러한 내용에 대해서는 따로 벨로그 글을 통해 후술하도록 하고, 위 내용을 통해 분석한 인덱스 생성 전략이나 접근 방향을 적극적으로 활용하여 조회 성능을 향상할 수 있도록 준비하도록 하자.
JOIN, 계산과 같은 쿼리적 혹은 공간적 제약 요소는 성능에 미치는 영향이 그리 크지 않다. MySQL의 경우 인덱스 전략으로 충분히 보완 가능하다는 것을 인지하고, 인덱스 전략을 생성하고 관리하는데 집중하도록 하자.
7. 참고자료
밸런스트리 - https://stackoverflow.com/questions/59206128/balanced-vs-unbalanced-binary-tree-clarification-needed
HDD/SSD 구조 - https://www.donemax.com/ssd-solutions/about-ssd.html?srsltid=AfmBOooaV05aKlffsMzsMQo6k-LUMoKUExmFkXdXiMaHH1v3Et4cxoJs
