개요
BackEnd의 기본, GraphQL에 대해 이해한다.
Checklist
- GraphQL API는 무엇인가요? REST의 어떤 단점을 보완해 주나요?
RESTAPI
보통 HTTP REQUEST(GET/POST method)을 지칭하며, 엔드포인트로부터 사용자가 data를 얻기 위해 필요한 API(혹은 요청)을 말한다.
우리(=client)가 request한 요청에 따라 server는 response를 하고, 이에 대한 data 및 template(웹페이지)를 우리에게 response 한다.

REST API는 접속할 url에 대해 특정 방식(GET/POST)으로 요청(Request)하고,
요청에 대한 응답(Response)을 받아 해당 데이터를 얻거나 template을 받는다.
요청 주소가 달라지면 url을 수정하여 재요청해야 하며, 이에 따라 접근해야 하는 endpoint(=요청 주소, url)가 달라지게 된다.
RESTAPI의 문제점
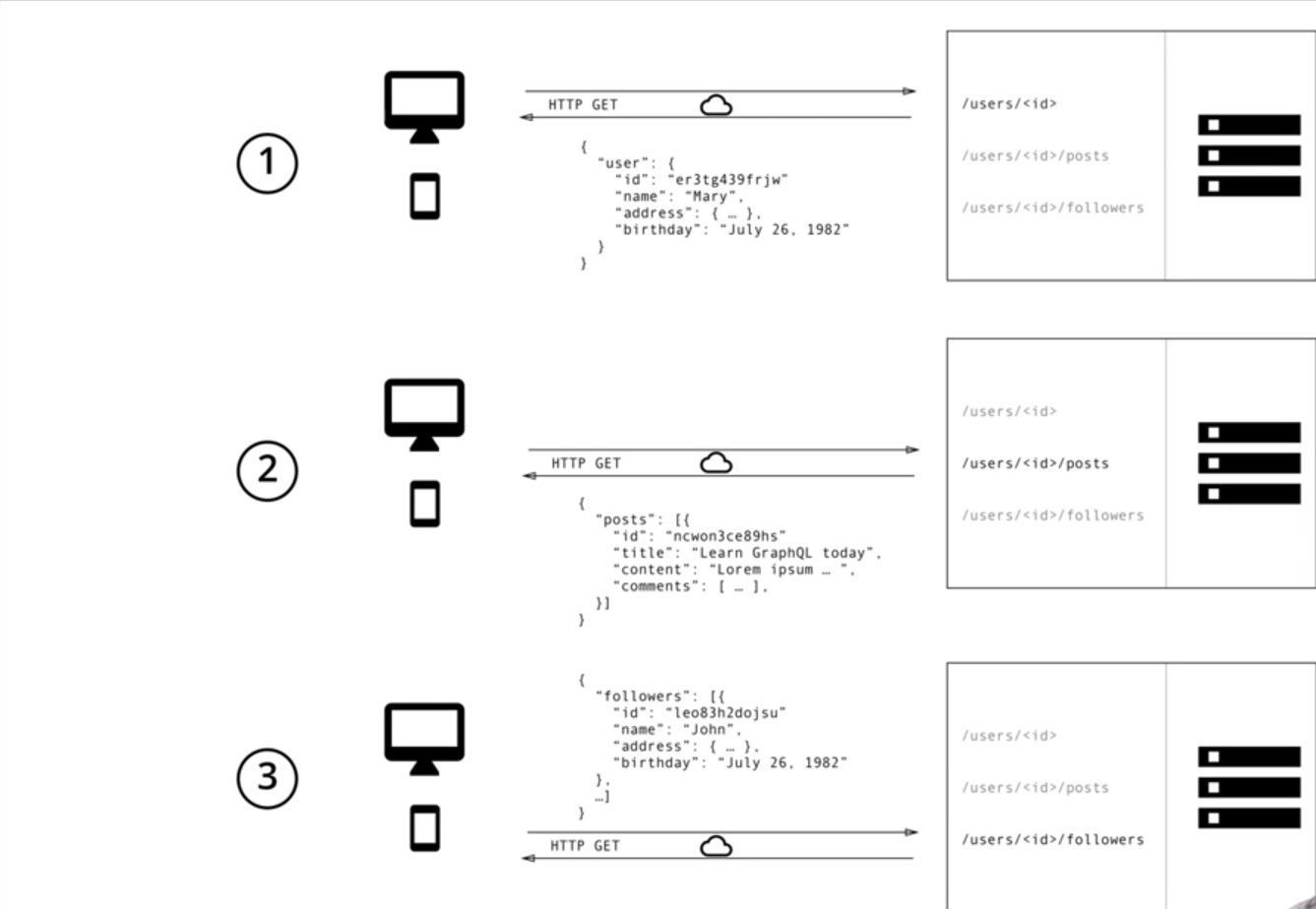
위 그림처럼 최종적으로 특정 user의 follower 정보를 확보해야한다고 생각해보자.
RESTAPI를 이용해 우리가 원하는 follower 정보를 얻기 위해선,
- 먼저 특정 user에 대한 전체 정보가 있는 엔드포인트를 요청한다(RESTAPI ①)
- 이후 user id(key)값을 알아낸다(RESTAPI ①에서 확보)
- 알아낸 id를 통해 다시 user follower 정보가 있는 엔드포인트를 요청한다(RESTAPI ②)
- follower 정보가 있는 엔드포인트에서 follower 정보를 얻는다(RESTAPI ③)
위와 같이 단계적인 엔드포인트 시점을 알아야 하고, 각 엔드포인트로부터 RESTAPI를 호출하여 원하는 정보를 얻어야만 최종적인 follower 정보를 얻을 수가 있다.
overfetching
이때 우리는 follower 정보를 얻기위해 사용자 전체정보와 id 값 등 불필요한 정보까지 모두 확보가 필요하였다.
한 정보를 얻기위해 불필요한 정보까지 얻어야하는 번거로움을 overfetching이라 하고, 이는 RESTAPI의 가장 큰 문제점 중 하나이다.
underfetching
또한 이를 다른 관점으로 볼 수 있다.
follower 정보를 얻기 위해 RESTAPI를 통해 직접적으로 정보를 얻고자 하면 해당 user id를 모른 상태로 정보를 얻게 되거나, 다른 엔드포인트의 follower 정보를 얻을 수 있는 불확실성이 존재한다.
이처럼 RESTAPI를 통해 필요한 정보가 아닌, 다른 정보나 부족한 정보를 얻게 되는 문제를 underfetching이라 하며 이 역시 RESTAPI의 문제점 중 하나이다.
버전관리 및 유지보수의 번거로움
추가적으로, RESTAPI를 사용할 경우 API버전별 관리가 필요하게 된다.
버전별로 API를 관리하게 된다면, 버전에 맞춘 엔드포인트가 별도로 생성되어야 하며 실무적으로 백엔드/프론트엔드간 협의가 반복적으로 이루어져야 하는 번거로움이 생긴다.
이를 통해 RESTAPI를 사용시 data 무결성 및 유지관리에 매우 힘들 수 있음을 알 수 있다.
GraphQL(Graph-data Query Language)
GraphQL은 URL 개념이 존재하지 않는다.
비선형 자료구조인 Graph처럼 data가 무수히 많은 연관관계를 지닌 상태에서,
Query Language를 통해 원하는 data만 선별적으로 확보할 수 있는 체계이다(명령어).
GraphQL은 RESTAPI가 가지는 치명적인 단점인 "여러 개의 엔드포인트"를 "단일 엔드포인트화"하여, 한 번의 엔드포인트 접근으로 원하는 data를 얻을 수 있도록 한다.
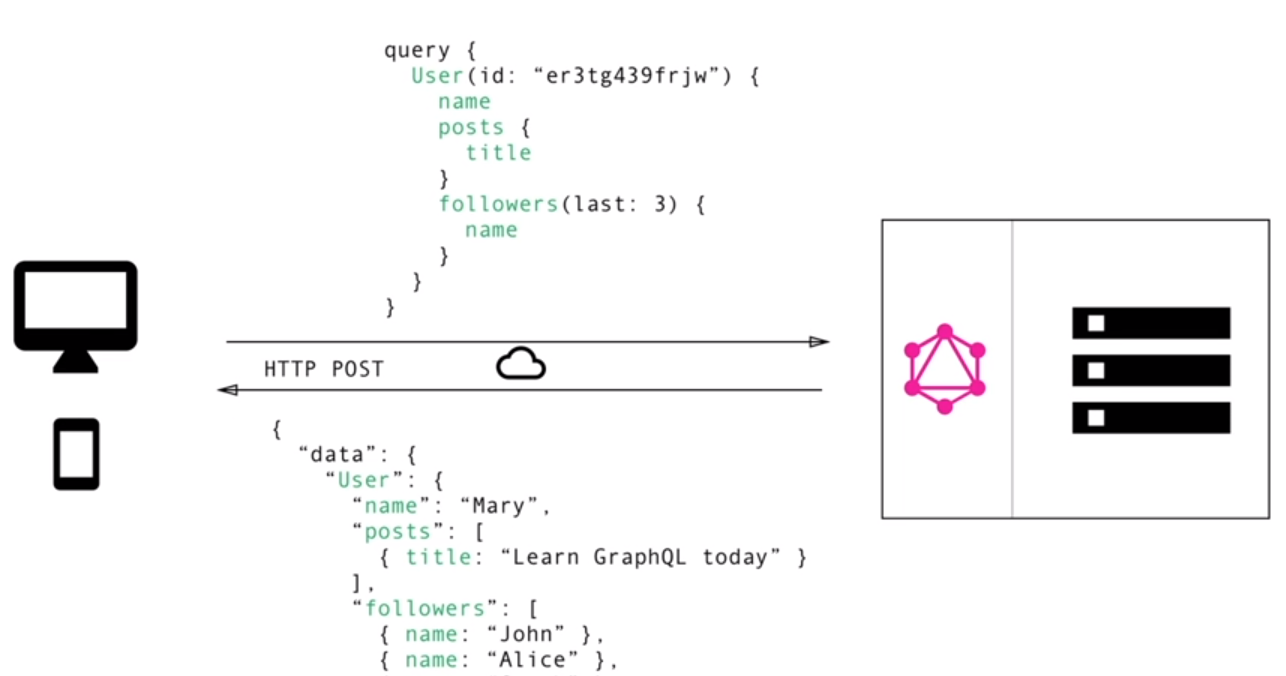
GraphQL은 모든 data가 graph처럼 연결관계를 지닌 것으로 생각한다.
client나 서버관리자는 자신이 원하는 data를 얻기 위해, 여러 엔드포인트를 단계적으로 거치는 것이 아닌 user 정보가 있는 하나의 엔드포인트로만 접근한다.
그 후 Query language를 통해, 모든 데이터가 얽혀있는 저장소에 접근하여 원하는 정보만 선별하여 확보할 수 있다.
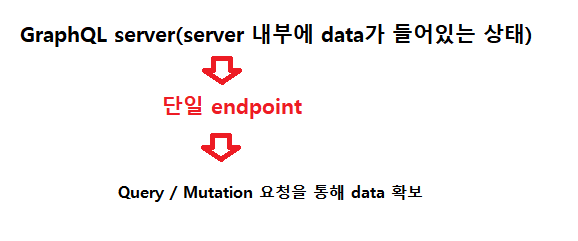
GraphQL은 이처럼 data무결성 및 유지보수가 RESTAPI에 비해 우수하고, server 운영면에서 월등히 간결하고 쉽다.
- GraphQL 스키마는 어떤 역할을 하며 어떤 식으로 정의되나요?
GraphQl에서 Query를 사용하기 위해 미리 "설계도"를 그려놓는다 → type(Schema)
GraphQL에서 schema는 넓게는 데이터모델링을 하는 작업, 좁게는 원하는 데이터를 얻기 위한 Query문을 정의하는 작업으로 이해하면 된다.
이때 데이터 모델링은 GraphQL 상에서 data를 불러오기 위한 type(형태, 속성 등)을 정의하는 것, 이를 위해 데이터베이스에 해당 데이터를 구성해주는 과정을 모두 의미한다.
type Query {
WhatisPersonProperty : [Person]
}
type Person {
name : String!,
favoriteNumber : Int!,
favoriteFood : String!
}GraphQL에서 데이터를 사용하기위해 데이터의 형태, 속성을 정의해주는 코드이다.
schema 작업의 가장 기초가 되는 부분이라 할 수 있다.
- GraphQL 리졸버는 어떤 역할을 하며 어떤 식으로 정의되나요?
GraphQL에서 설계한 Query를 사용하여 data를 얻기위해 실질적으로 사용하는 data 확보도구 → resolver
쉽게 말하면 우리가 작성한 정의문(Query)을 실제로 활용하여 데이터를 얻는 과정을 의미한다.
Schema를 통해 정의했다면, 다음 과정은 resolver를 통해 이를 활용하는 것이다.
const resolvers = {
Query{
WhatisPersonProperty : () => Person
}
}
const Person [
{
name : "LEE Hyo Kyun",
favoriteNumber : 7,
favoriteFood : "rice"
}
] 위에서 정의한 Query를 살펴보면 WhatisPersonProperty라는 요청은 Person이라는 배열을 반환해주는 것을 알 수 있다.
따라서 이러한 구조를 그대로 유지하여, resolvers에 해당 Query문과 반환해주는 배열에 대한 속성을 나타내주었다.
이후 사용자는 WhatisPersonProperty query를 요청하면, resolvers에서 정의한 name/favoriteNumber/favoriteFood를 반환받는다.
- GraphQL 리졸버의 성능 향상을 위한 DataLoader는 무엇이고 어떻게 쓰나요?
N+1문제, 여러 데이터를 얻기 위해 과도하게 query 반복이 이루어지지 않도록 최적화된 데이터 조회/접근을 해주는 기능을 일컫는다.
DataLoader는 크게 두가지 특징을 지니고 있다.
Batch
여러 데이터들을 조회하기 위한 각각의 요청들을 하나로 모은 후, 단일 요청으로 보내고 해당 결과값들을 확보한다.
Cache
요청항목 중 기존에 요청과 중복되는 것이 있다면, 이를 Caching하여(미리 기억에 저장하고 있다가, 중복 요청이 생기면 특정) 접근한다.

이와 같이 Database에서 DataLoader가 요청을 한 곳으로 모으고, 이 요청을 fetch(전달)하는 과정으로 접근이 이루어진다.
- 클라이언트 상에서 GraphQL 요청을 보내려면 어떻게 해야 할까요?
기본적으로 GraphQL에서 정의한 query문, 이를 통해 데이터를 확보하는 작업은 모두 백엔드(server)에서 정적으로 이루어진다.
하지만 필요에 따라 동적으로 변수를 추가하거나 확보하는 작업이 필요하다면, client 측에서도 요청을 보내고 변수를 얻을 수 있다.
client를 통해 요청을 전달하는 과정을 대략적으로 기술하면 아래와 같다.
→ resolvers에 client를 통한 요청값을 담을 변수를 지정하고, 해당 변수가 client로 부터 요청받은 값임을 나타낸다(@client).
→ 이를 위해 type(Query)에도 해당 변수를 추가해준다.
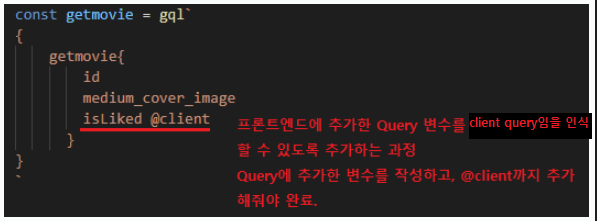
→ client에서 동적으로 변화하는 데이터를 활용한다.

- Apollo 프레임워크(서버/클라이언트)의 장점은 무엇일까요?
백엔드 관점에서 살펴보면 이해가 쉬워진다.
→ GraphQL server은 단일 endopint(=server)를 통해 data를 저장해 둔 곳이다.
→ 우리는 이러한 data에 접근하고 확보하기 위해, 접근방식인 Query를 정의하고 설정해준다.
→ 기본적으로 해당 data를 접근하기위해 GraphQL server에 직접 접속한다.
→ axios fetch 등을 통해 기본적으로 POST Request를 진행해주어야 한다.

Apollo를 통해 접근하게 되면 직접 server에 접속하지 않고도
GraphQL server 내부에 저장되어있는 data에 접근하고 이를 확보할 수 있게 된다.

즉 ApolloClient가 접근을 하게 되는 방식이고, 사용자가 설정해 주었던 GraphQL 요청방식을 그대로 활용하여 data 확보가 가능하다.
쉽게 말하면 GrpahQL의 장점인 단일 endpoint를 그대로 활용하면서
→ GraphQL server에 직접 접속하지 않고도, visualstudio와 같은 환경에서 ApolloClient를 통해 server에 접근할 수 있다.
→ 사용자가 정의한 Query도 그대로 활용하면서 data를 확보할 수 있다.
GraphQL과 함께 사용할 수 있는 호환성이 매우 높고, 이를 통해 효율적으로 data를 확보할 수 있다는 점이 Apllo를 활용하는 이유이다.
- Apollo Client를 쓰지 않고 Vanilla JavaScript로 GraphQL 요청을 보내려면 어떻게 해야 할까요?
fetch, axios과 같은 데이터 전달 module 및 REST API(GET/POST method) 등 data를 확보할 수 있는 별도의 모듈을 사용해야 한다.
변수가 담겨진 querystring 및 req.body와 같은 요소를 활용할 수 있다.
- GraphQL 기반의 API를 만들 때 에러처리와 HTTP 상태코드 등은 어떻게 하는게 좋을까요?
→ server 접속 및 모든 요청처리 성공(※ status code - 200)
→ GraphQL server / apollo server initialization 실패처리
→ REST API 실패처리
→ resolver가 정의되어있지 않는 변수/객체를 반환하는 오류
참고개념
- 데이터베이스 이론에서의 Schema
데이터베이스 이론에서 Schema는 여러 데이터가 저장되어 있는 공간을 말한다.
이론적으로는 여러 Schema가 모였을때 하나의 데이터베이스를 이루는 것으로 보지만, 실무적으로는 Schema와 데이터베이스를 거의 동일하게 취급하고 있다.
쉽게 말하면 책꽂이(인스턴스)에 책(데이터베이스)이 있고, 이 책(데이터베이스)에 여러 페이지(Schema)와 내용들(table)로 구성되어 있는 것이다.
- n+1 문제
type Query {
WhatisPersonProperty : [Person]
}
type Person {
name : String!,
favoriteNumber : Int!,
favoriteFood : String!
}위 코드에서 정의한 query문을 살펴보도록 한다.
사용자가 WhatisPersonProperty query를 요청한다면, 해당 query 요청 1개와 내부적으로 3개의 속성을 가져오기 위해 3개의 query를 수행해야 한다.
즉 n개의 속성을 확보하기위하여 외부적으로 n+1번의 query가 수행되는 번거로움을 n+1 문제라 한다.
정리
0. why
- 백엔드개발자라면 GraphQL, Apollo 등 endpoint 처리에 대한 개념을 왜 알고있어야 하는지 고민해본다.
- REST API를 통한 요청보다 GraphQL이 왜 각광받고 있는지 알아본다.
1. what
- GraphQL이 무엇이고, 어떠한 원리로 작동하는지 이해한다.
- 데이터를 확보하기위한 Schema, resolver 작업에 대해 이해한다.
2. how
- GraphQL을 통한 데이터 확보, 활용을 실무에 어떻게 적용할 수 있을지 고민해본다.
- GraphQL을 실무에 적용한다면, 어떠한 방식으로 DB-DATA 확보 logic 설계를 진행할 수 있을지 생각해 본다.
3. 참조링크
GraphQL N+1문제 / DataLoader
https://chanyeong.com/blog/post/53
GraphQL 공식문서
https://graphql.org/
Apollo 공식문서
https://www.apollographql.com/
Web DEV Curriculum - QUEST13
https://github.com/leejiwoo2021/WebDevCurriculum/tree/master/Quest13
