개요
서비스 이용, log, 오류 등 데이터가 통신하는 과정을 모니터링하는 도구와 원리에 대해 이해한다.
Checklist
- ElasticSearch는 어떤 DB인가요?
ElasticSearch
분산형 RESTful 검색/분석 엔진으로, 차세대 데이터 플랫폼이라 불리우는 Elastic stack의 가장 핵심적인 요소이다.
방대한 양의 데이터를 신속하게, NRT(Near Real Time, 거의 실시간)한 속도로 데이터 저장/검색/분석을 할 수 있다.
ELK
Logstash
데이터를 정제하고 전처리하여 ElasticSearch에게 전달한다.
DB, .csv 등의 로그 및 트랜잭션 데이터를 parsing하는 역할을 담당한다.
ElasticSearch
데이터 검색/분석뿐만 아니라 저장소역할까지 담당한다.
Logstash로 부터 받은 데이터를 검색/집계하여 필요 정보를 획득한다.
Kibana
ElasticSearch에 저장된 데이터를 시각화 및 모니터링 한다.
Beats
데이터 수집을 담당한다.
- 기존의 RDB와 어떻게 다르고 어떤 장단점을 가지고 있나요?
ElasticSearch/RDB
ElasticSearch은 사실상 이름만 다르고, 전체적인 원리나 개념은 비슷한 점이 많다.
관계형 DB의 속성들을 ElasticSearch와 연결지으면 아래와 같다.
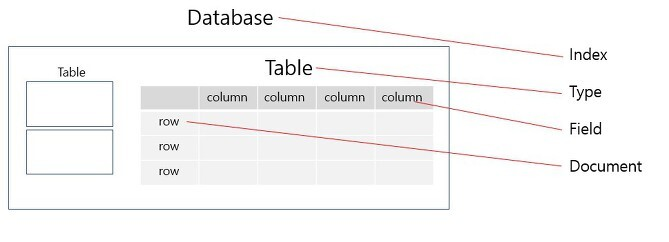
ElasticSearch와 RDB의 다른점
Elastic stack이 차세대 데이터 플랫폼으로 주목받으면서, 이에 대한 활용사례도 많이 늘고 있는 추세이다.
그러나 데이터 저장방식에 차이점이 있어, 아직까지 RDBMS를 완전히 대체하기는 힘들 것으로 보인다.
RDB는 행(속성, Column)을 기반으로 데이터를 저장하는 반면, ElasticSearch는 단어를 기반으로 데이터를 저장한다.
따라서 데이터 자체를(데이터는 우리가 선별하고자 하는 객체가 될 수 있고, 그 객체를 포함하는 전체 속성이 될 수 있다) 다루는데는(수정/삭제) RDB가 유용할 수는 있으나, 검색 측면에서는 객체 확인을 계속 반복하기 때문에 비효율적일 수 있다.
반면 데이터를 단어 기반으로 저장하는 ElasticSearch에서의 검색, 수집 등은 RDB에 비해 훨씬 효율적이고 빠를 수 있다.
해당 단어를 검색한다면 단어가 존재하는 행을 찾는 방식이 ElasticSearch이고, 반대로 행에서 단어를 찾는 방식이라면 RDB이다.
- AWS의 ElasticSearch Service는 어떤 서비스인가요?
라이센스가 바뀐 ElasticSearch의 접근성, 사용자 편의, 관련 서비스 제공을 위해 AWS가 주도하는 OpenSearch 프로젝트의 일환이다.
ElasticSearch는 원래 Apache Lucene 기반의 서비스였으나, 2021년 1월 라이센스를 변경하여 Elastic을 통해 서비스를 제공하게 되었다.
이에 따라 더이상 ElasticSearch는 오픈소스가 아니며, 사용자들은 라이센스 마이그레이션에 따른 대비를 해야했다.
이를 AWS가 주도하여 ElasticSearch를 EC2 및 OpenSearch Service를 통해 ElasticSearch를 사용할 수 있도록 관련 서비스를 제공하고 있다.
다만 EC2를 통해 구현한다면 사용자가 클러스터 및 DB관리 등을 직접 해줘야 하고, OpenSearch Service를 사용하면 완전관리가 가능하다.
- ElasticSearch를 직접 설치하거나 elastic.co에서 직접 제공하는 클라우드 서비스와 비교하여 어떤 장단점이 있을까요?
ElasticSearch를 직접 설치할 경우 관련 인프라나 클러스터 등을 사용자가 직접 제어해야하고, 회사에서 제공하는 서비스를 받을 경우 완전관리 형태로 이용할 수 있다.
- Grafana의 Panel 형식에는 어떤 것이 있을까요? 로그를 보기에 적합한 판넬은 어떤 형태일까요?
Grafana
데이터 시각화를 위한 대시보드를 제공해주는 오픈소스 툴 킷이다.
오픈소스인 만큼 사용자가 만든 대시보드를 import하여 사용할 수 있고, 커스터마이징까지 할 수 있다.
아래 대시보드 화면은 Grafana 실행하였을 때 보여지는 화면이다.
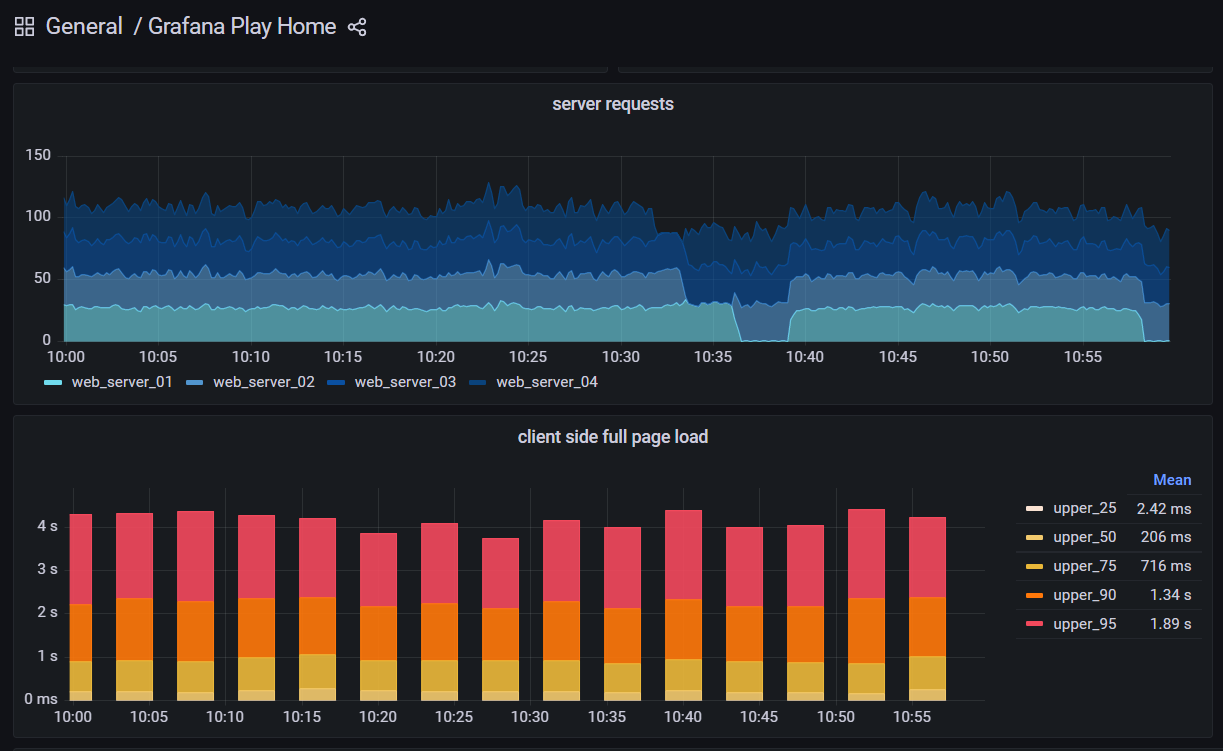
plugin을 통한 내부적으로 확장하여 사용할 수도 있다.
기본적으로 Grafana가 정보를 수집하기 위해서는, 사용자가 해당 DB를 정의하고 연결해주는 작업이 필요하다.
참조개념
데이터베이스의 상태를 변화시키기 위한 작업의 단위, 혹은 그런 작업(요청)을 말한다.
우리가 홈페이지를 방문할 때 무의식적으로 입력하는 url들은 모두 request의 일종이고, 이 request는 하나의 API로 작용하여 DB를 변화시킨다.
따라서 네트워킹 및 통신과정에서 이루어지는 상호작용을 일컫는 의미로 사용이 많이 됨을 유의하도록 한다.
- 역인덱싱(Inverted Indexing)
전통적인 RDBMS가 단어를 찾는 방식

기존 RDBMS는 단어(혹은 데이터)를 찾고 싶을때, 해당 데이터가 있는 모든 행(Column)을 찾는다.
이 "찾는다"는 과정이 단순히 우리가 사전의 단어를 찾는 것처럼 이루어지는 것이 아니라, 모든 행에 대해 반복하는 과정이기 때문에 시간이 많이 걸린다.
즉 기존의 방식은 데이터를 찾기 위해 행을 먼저 찾는다.
RDBMS가 데이터 CRUD에 적합하지만, 검색 및 분석에는 부적합한 이유이다.
역인덱싱

역인덱싱은 RDBMS의 방식과 정 반대로, 우리가 단어(데이터)를 찾을때 추론하는 방식과 유사하게 이루어져있다.
키워드를 통해 찾는 개념이기도 한데, 찾고자하는 단어(데이터)를 통해 document를 검색하는 방식이다.
즉 역인덱싱은 데이터를 찾기 위해 데이터 자체, 혹은 그 키워드를 먼저 탐색하고 그 후에 해당 문서를 찾는다.
정리
0. why
- 기존의 RDBMS와 완전히 다른 개념인 Elastic Seach가 왜 차세대 데이터 플랫폼으로 성장하게 되었는지 생각해본다.
1. what
- Elastic Search는 데이터를 어떻게 저장하고 검색하는지 알아본다.
- 더이상 Elastic Search는 오픈소스가 아니기 때문에, 이를 사용하고 싶다면 어떻게 활용할 수 있을지 고민해본다.
- 역인덱싱 방식에 대해 이해한다.
2. how
- Elastic Search의 데이터 저장 방식인 역인덱싱가 어떠한 원리로 이루어지는지 더 자세히 알아본다.
3. 참조링크
ElasticSearch 개념
https://victorydntmd.tistory.com/308
AWS OpenSearch Service
https://aws.amazon.com/ko/opensearch-service/the-elk-stack/what-is-elasticsearch/
Granfana 공식 홈페이지
https://sgrafana.comsvs
Grafana
https://medium.com/finda-tech/grafana%EB%9E%80-f3c7c1551c38
