1. 개요
DB index는 말 그대로 DB에서 사용하는 index로, DB내 다양한 table, 그 table 내에서 찾고자하는 특정 COLUMN을 쉽고 빠르게 찾을 수 있도록 설정하는 색인(목차)와 같은 개념이다.
우리가 사전에서 단어를 찾을 때 혹은 책에서 특정 주제의 내용을 찾을때, 공통적으로 해당 내용에 대한 힌트가 있고 앞부분에 목차가 있기 때문에 이를 참조하여 빠르게 내용을 찾을 수 있는 것이다.
DB index도 이와 유사한 개념으로, 조회쿼리에서 사용하는 COLUMN을 광범위한 DB와 table에서 찾을때 인덱스가 있다면, optimizer는 이를 기반으로 table을 빠르게 찾을 수 있을 것이다. 없다면 full scan하고 그만큼 조회시간이 오래 걸릴 것이다.
2. 개념
SELECT COLUMN
FROM TABLESELECT COLUMN FROM TABLE
WHERE COLUMN_CONDITION = 'A'위 두 SQL문에서 opimizer는 [COLUMN]이라는 column을 찾기 위해, index라는 힌트가 없다면 full scan할 것이다.
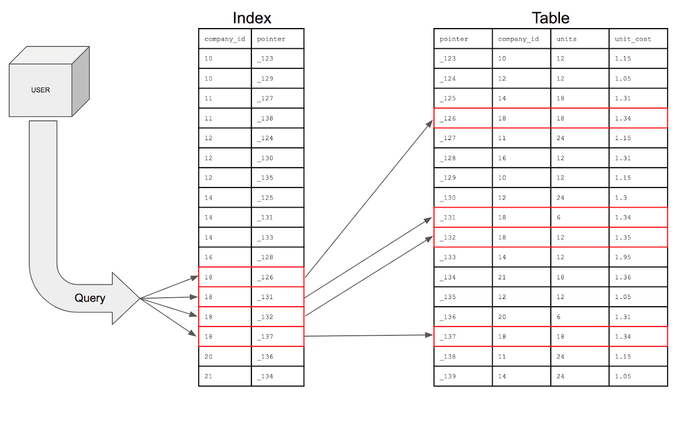
이처럼 index는 조건절에 사용하는 COLUMN, 특히 특정 COLUMN을 업무적으로 자주 활용할 경우 해당 COLUMN에 빠르게 도달할 수 있도록 그 위치를 저장하는 목차, 색인이다.
DB의 도메인이 크다면 그만큼 COLUMN을 찾는데 많은 시간이 걸리므로, 이에 대한 성능을 개선하기 위해 해당 COLUMN에 대한 index를 DB에 저장한다.
2. index 저장 과정
일단 index는 DB에 따로 공간을 내어(10%) 해당 COLUMN에 대해 key-value 형식으로 저장한다.
- index 저장
CREATE INDEX COLUMN_INDEX ON TABLE(COLUMN);이후 DB의 여유 공간에 key-value 형식으로 index를 저장할 수 있다.
3. 유의사항
기본적으로 index는 저장시 DB의 별도 공간을 사용한다.
조회시 성능적으로 이점을 가져다줄 수 있지만, 엄연히 별도의 공간을 사용하여 저장하므로 무분별한 index 저장은 과부하가 올 수 있다.
무엇보다도 가장 유의해야할 부분은 해당 COLUMN이 변경이 자주 일어날 경우이다.
index는 DELETE, UPDATE시 기존의 index를 사용하지않음으로 처리하고, 새로운 인덱스를 추가적으로 생성하여 관리한다.
따라서 변경이 자주 일어날 경우, 새로운 index를 계속 생성하므로 오히려 data보다 index가 많아진다면 시스템 성능이 더 나빠지는 모순을 겪을 수 있다.
4. 관계차수(Cardinality)와의 관계
관계차수가 높으면 높을수록, 그만큼 특정 속성 및 인스턴스가 다양한 관계를 맺고 있고 식별자의 특성을 지녀 중복도가 낮다고 볼 수 있다.
중복도가 낮은 속성을 index로 활용한다면, 그만큼 많은 데이터를 필터링 할 수 있고 식별자 특성상 각 COLUMN에 대한 강력한 힌트로 볼 수 있으므로 시스템 성능이 그만큼 높아질 수 있을 것이다.
5. 참고자료
DB index 개요 - https://tecoble.techcourse.co.kr/post/2021-09-18-db-index/
DB index의 관리/유의점 - https://mangkyu.tistory.com/96
DB index의 종류 - https://webisfree.com/2016-07-08/[sql]-%EC%9D%B8%EB%8D%B1%EC%8A%A4(indexes)-%ED%85%8C%EC%9D%B4%EB%B8%94%EC%9D%B4%EB%9E%80-%EA%B0%84%EB%8B%A8%ED%95%98%EA%B2%8C-%EC%84%A4%EC%A0%95%ED%95%98%EB%8A%94-%EB%B0%A9%EB%B2%95
