1. DB의 실행계획(인덱스)
SQL 실행(Operation) 시 두가지 방법이 있는데,
- 인덱스를 활용하여 조회하는 INDEX
- 인덱스를 활용하지 않고 table을 full scan하는 FULL
이 중 INDEX 방법은, table 일부 레코드에만 액세스를 하여 탐색하는 기법으로 DB성능이 크게 향상할 수 있는 방법이다.
2. 인덱스를 사용한 성능 개선
큰 테이블에서 소량의 데이터를 검색할때 사용할 수 있는 인덱스 기법은, 효율적인 인덱스 정렬 및 인덱스 컬럼 구성하는 것이 필요하다.
이때 효율화라는 것은 두가지 방안으로 구현할 수 있다.
- 인덱스 효율화
선택도는 낮고 카디널리티는 높은 컬럼으로 구성(=이름보다는 주민등록번호, 이름+지역 등의 중복키 등 유일성이 높은 항목을 인덱스로 채택)
- 랜덤 액세스 최소화
인덱스(루트/브랜치/리프)를 거쳐 table 탐색 후 후속처리 작업으로 랜덤액세스를 할 수 있는데, 이 랜덤액세스가 DBMS 성능저하의 주 요인으로 작용할 수 있다.
3. 인덱스 구조 - B* Tree
Balance Tree, 정렬한 인덱스를 별도의 메모리에 저장하는 방식 혹은 구조를 말한다.
인덱스를 사용한다면 데이터를 일부만 읽고 멈출 수 있고, 이때 인덱스는 정렬된 상태로 저장한다.
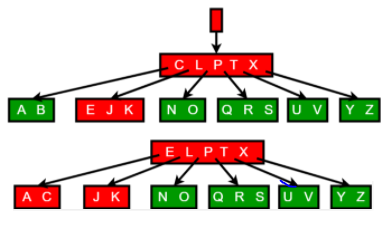
인덱스 정렬 상태 및 Tree(노드) 구조에 따라 루트/브랜치/리프로 구조를 나눌 수 있고, 해당 구조를 탐색하면서 인덱스를 찾는다.
- 각 레코드는 하위 블록에 대한 주소값을 가지고, key값은 하위블록에 저장된 key값의 범위를 나타낸다.
- 각 레코드가 가르키는 주소로 찾아간 블록에는 key값을 가진 첫번째 레코드보다 작거나 같은 값이 저장되어 있다(block이 table 내 data를 저장하는 뭉치로 생각하면 됨).
- 리프블록에 저장된 각 레코드 값은 key 값 순으로 정렬되어 있고, table record를 가르키는 주소값(Row id)를 포함한다.
- 인덱스 key 값이 같으면 row id 순으로 정렬된다.
- 인덱스를 스캔하는 이유는 검색조건을 만족하는 소량의 데이터를 빨리 찾고, 거기서 row id를 얻기 위함이다.
- Row id = data block address(Where is data?) + Row Number
B Tree 구조는 데이터 유지를 위해 자주(DBMS에서 가장 많이) 사용하는 구조이다. 효율적이고 빠른 탐색이 가능하며, 데이터를 정렬(Sort) 상태로 유지한다.
3-1. 인덱스 구조의 장점
인덱스 구조를 사용하면 다음의 3가지 장점을 확인할 수 있다.
- 균일성
어떠한 값에 대해서도 같은 시간에 결과를 얻을 수 있다.
- 이진탐색
정렬을 마친 데이터 구조 탐색에 효과적이고, 정렬이 안된 데이터를 선형탐색할 경우 성능에 불균형이 온다.
- 밸런스
루트로부터 리프까지의 거리가 일정하고, 이는 곧 어떠한 데이터를 탐색하여도 소요시간이 일정하다는 의미이다.
밸런스는 정기적으로 재구성해주는 작업이 필요하다.
4. 인덱스의 장단점
인덱스를 사용한다면 장점과 단점 모두 존재하고, 반드시 full scan보다 빠르다고 확신할 수 없기에 반드시 구성환경을 잘 알아본 후 사용하는 것이 좋다.
4-1. 장점
- 인덱스를 사용하면 일반적으로는 성능을 향상할 수 있고, SQL문을 튜닝(변경)하지 않아도 성능 개선이 가능하다.
- table 데이터에 영향을 주지 않는다(**인덱스와 table은 별도의 객체).
- 비용대비 높은 성능 향상이 가능하며, 조건이 부합한다면 극적인 성능 향상도 가능하다.
- 특정 상황에서는 full scan보다 느릴 수 있으므로, 무조건적인 사용은 금물이다.
4-2. 단점(역효과)
- 갱신오버헤드
인덱스 갱신의 오버헤드로 갱신처리기능이 약화된 상태이다.
테이블 데이터의 갱신 및 제거 시 인덱스 또한 갱신되어야 하며(별도의 객체라도 각자의 주소값을 참조하고 있으므로), 인덱스 갱신 이외의 부차적인 처리가 누적될 경우 처리 시간이 증가한다.
- 의도한 것과 다른 인덱스 사용
DB table에 복수의 인덱스가 생성될 경우, 옵티마이저가 예측을 벗어날 수 있으므로 튜닝이 필요하다.
- 저장소 용량 차지
인덱스 table은 DB와는 별도의 table이며, 이에 따라 백업시간이 늘어나고 저장소 공간 비용 역시 증가한다.
- 느린 성능
인덱스가 비효율적으로 정렬되어 있는 상태에서 대용량 데이터의 인덱스 스캔 시 full scan보다 오히려 성능이 불리할 수 있다.
5. 인덱스 생성 원칙
빠른 데이터 탐색을 위해 인덱스를 생성하는 규칙이 정해져 있다.
- 테이블 크기가 크다면 인덱스는 필요하며, 작으면 오히려 full scan이 좋을 수 있다.
- 기본키는 자동으로 인덱스가 같이 생성된다.
- 선택도가 낮은, 즉 유일성이 높은 컬럼에 인덱스 생성시 높은 수준의 성능향상이 가능하다.
※ Where 절에서 "=" 조건으로 조회되는 컬럼을 생성하거나, 복합인덱스의 경우 "=" 조건이 앞으로 오도록 설정한다.
6. 참고자료
B Tree - https://velog.io/@ryuhyewon/B-tree-Btree, https://m.blog.naver.com/nimdrak/222055921004
카디널리티/선택도 - https://velog.io/@jduck1024/%EC%B9%B4%EB%94%94%EB%84%90%EB%A6%AC%ED%8B%B0-VS-%EC%84%A0%ED%83%9D%EB%8F%84-feat.-NDV-Density
