1. 개요
대용량 트래픽 제어에 대해 학습하면서 자연스럽게 Kafka를 적용해볼 수 있는 좋은 기회가 생기게 되었다.
kafka가 가지고 있는 독특한 특징들과 각 요소들이 어떠한 원리로 작동하는지 기초 개념부터 차근차근 알아본 내용을 기록한다.
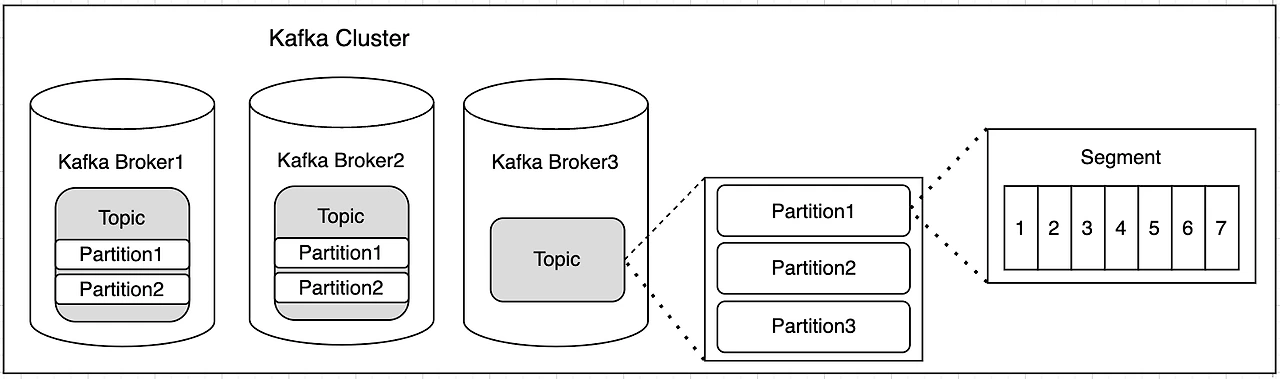
2. kafka 구성요소
kafka를 이해하기 위해 반드시 알아야 하는 4가지 대표적인 개념들을 먼저 알아보자.
기본적으로 kafka는 애플리케이션에서 메인 로직을 진행한 후에, 후행으로 진행하는 서비스가 대용량으로 요청이 들어와 동시성 제어와 순차 처리가 필요하다고 판단될 경우 사용한다.
이때 메인 로직과 부가 로직은 "로직을 처리하는 도메인" 관점에서 서로 연결이 되어있다고 볼 수 있겠다.
이 흐름을 세부적으로 살펴보면 다음과 같다.
1) 메인 로직의 서비스 종료 후 이벤트 발행한다.
2) 발행한 이벤트를 메시지로 보내어 kafka cluster에서 broker 내 지정 topic에 저장한다.
3) 이때 topic을 기준으로 메시지를 broker에 저장하되, 같은 topic에 저장된 다른 key값들의 메시지들은 다른 partition에 저장된다.
4) 같은 topic 다른 key값으로 저장된 메시지들은 병렬처리하고, 다른 topic에 저장된 메시지들은 완전히 다른 도메인 영역(서로 관심이 없는)이라 할 수 있겠다.
4) 관심사 topic을 구독하고 있는 consumer가 메시지 발행을 감지하여 해당 메시지를 전달받아 후행 동작을 한다.
5) 동일한 topic에 동일한 key값으로 저장된 메시지들은 순차적으로 consumer에게 전달되어 순차처리 및 원자성을 모두 보장해주는 처리를 기대할 수 있다(여기서 동시성 제어 발생).
이제 이 흐름에서 사용하는 개념들과 구성요소를 세부적으로 살펴보겠다
- producer
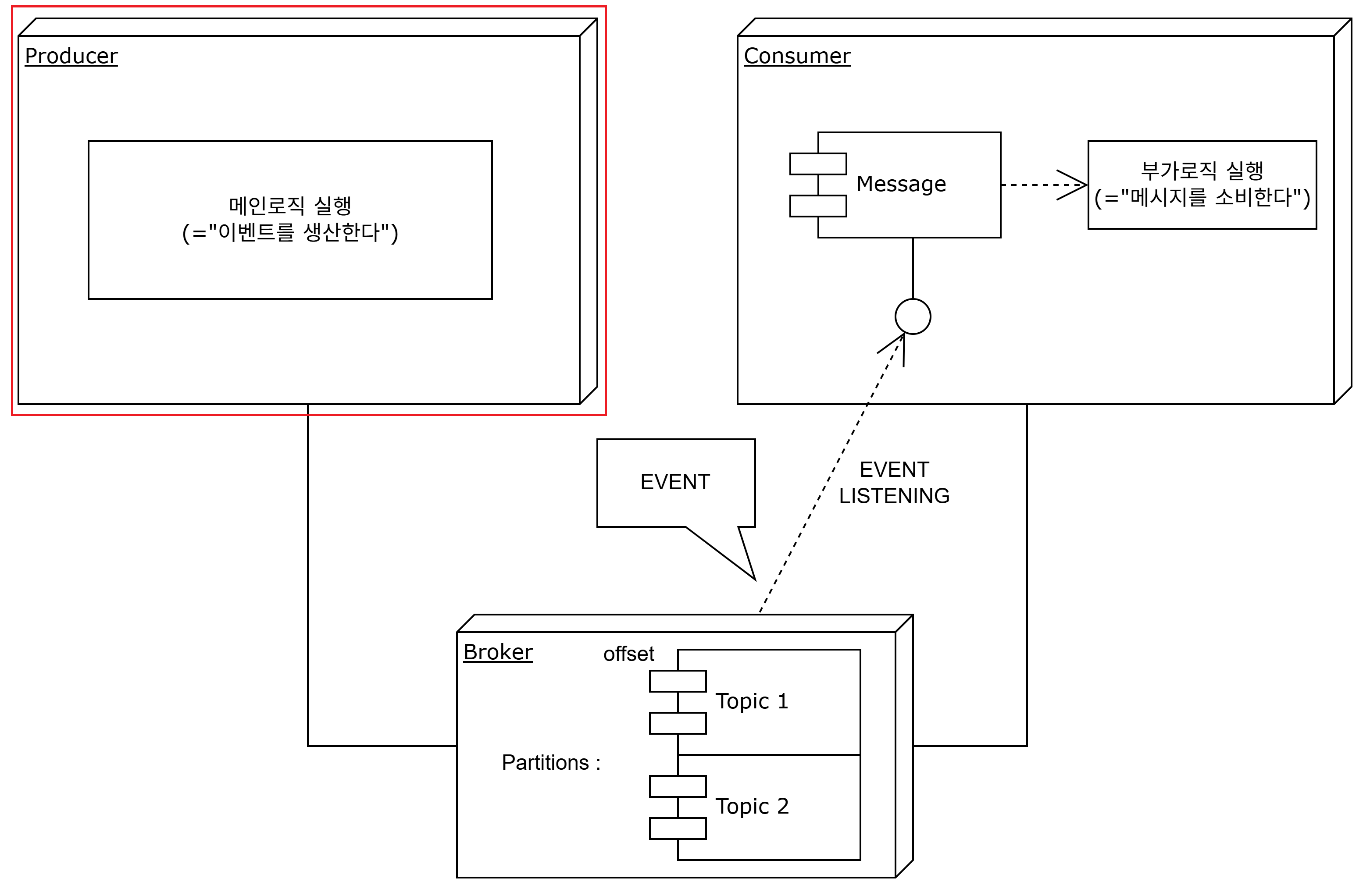
쉽게 말하면 카프카를 통해 이벤트를 발행하는 메인로직을 수행하는 서비스라 할 수 있겠다.
동일 관심사에 대해 특정 기준(key)으로 동시성 제어를 필요로하는 메시지를 카프카로 발행하며, 메시지를 "생산"하니까 producer라 생각하면 이해가 편하다.
- consumer
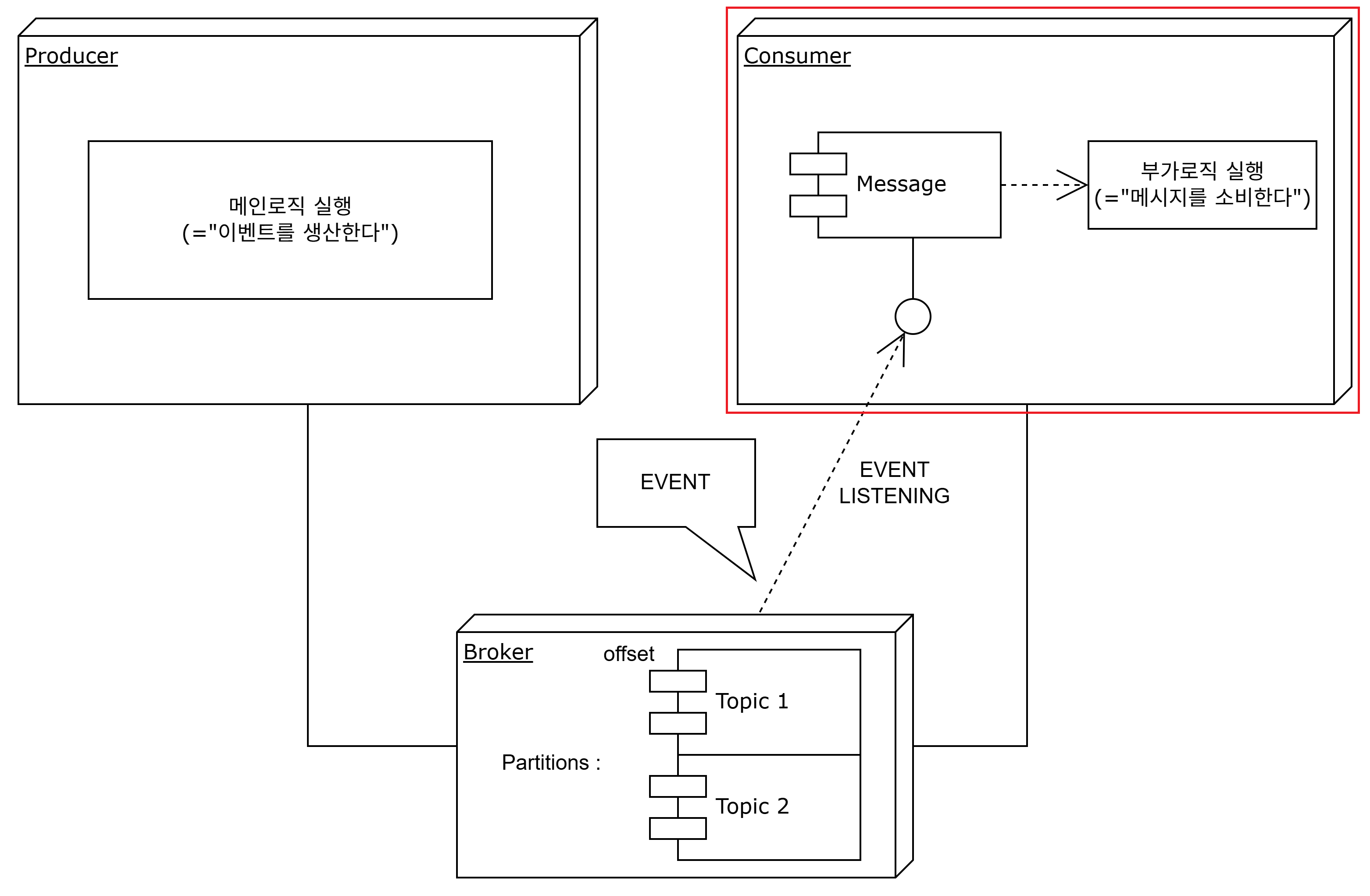
producer가 발행한 메시지가 관심사(동일 topic)일때 이를 감지하고, 메시지를 전달받아 후행 동작을 처리하는 서비스이다.
쉽게 말하면 부가로직을 수행하는 서비스라 할 수 있겠다.
- message
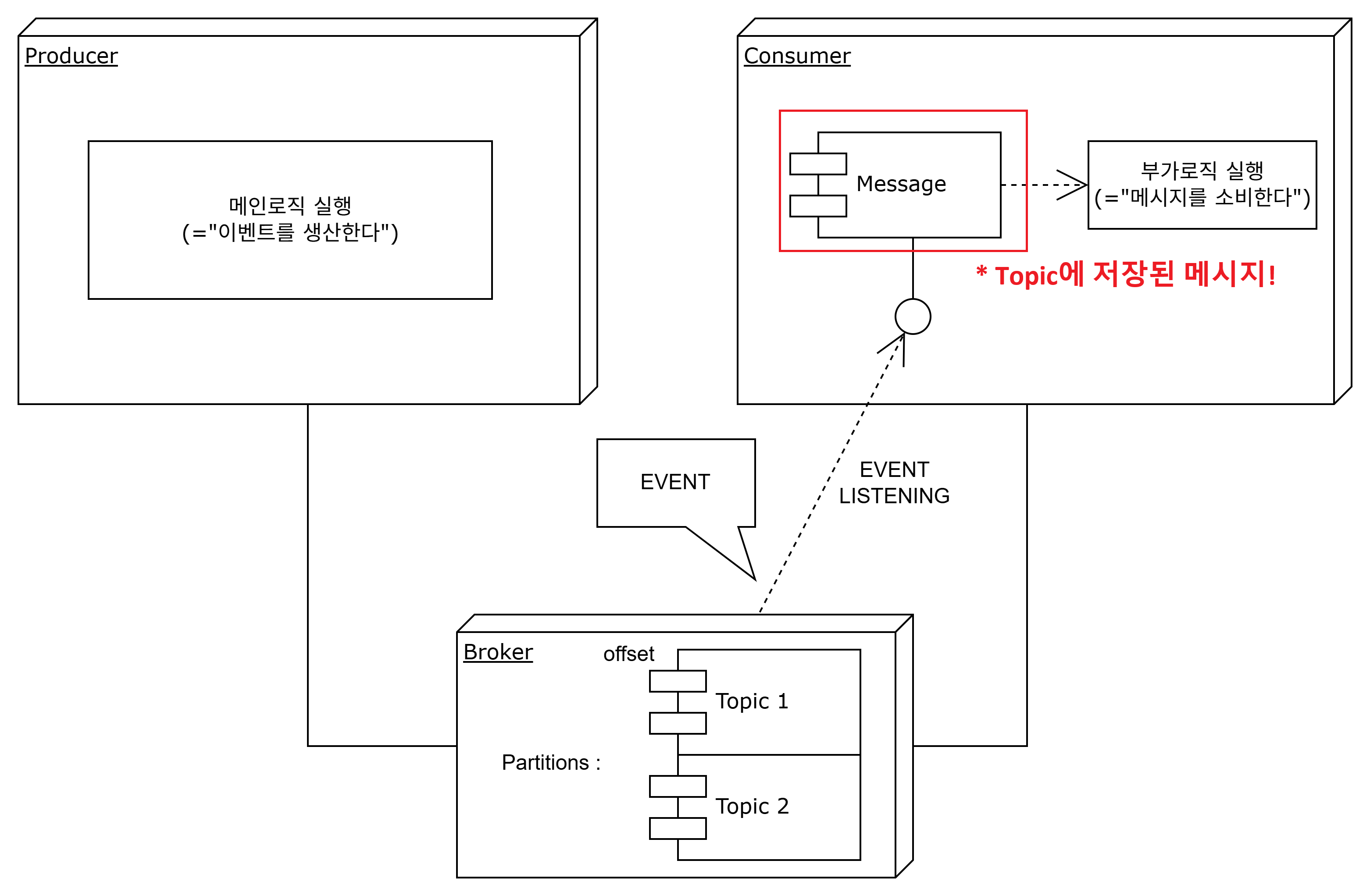
producer가 발행하는 하나의 이벤트이자 consumer에게 전달하는 상태정보로, producer와 consumer가 서로 통신하는 매개체이다.
consumer는 producer가 발행한 이벤트를 전달받아, 후행 동작을 처리한다.
- topic
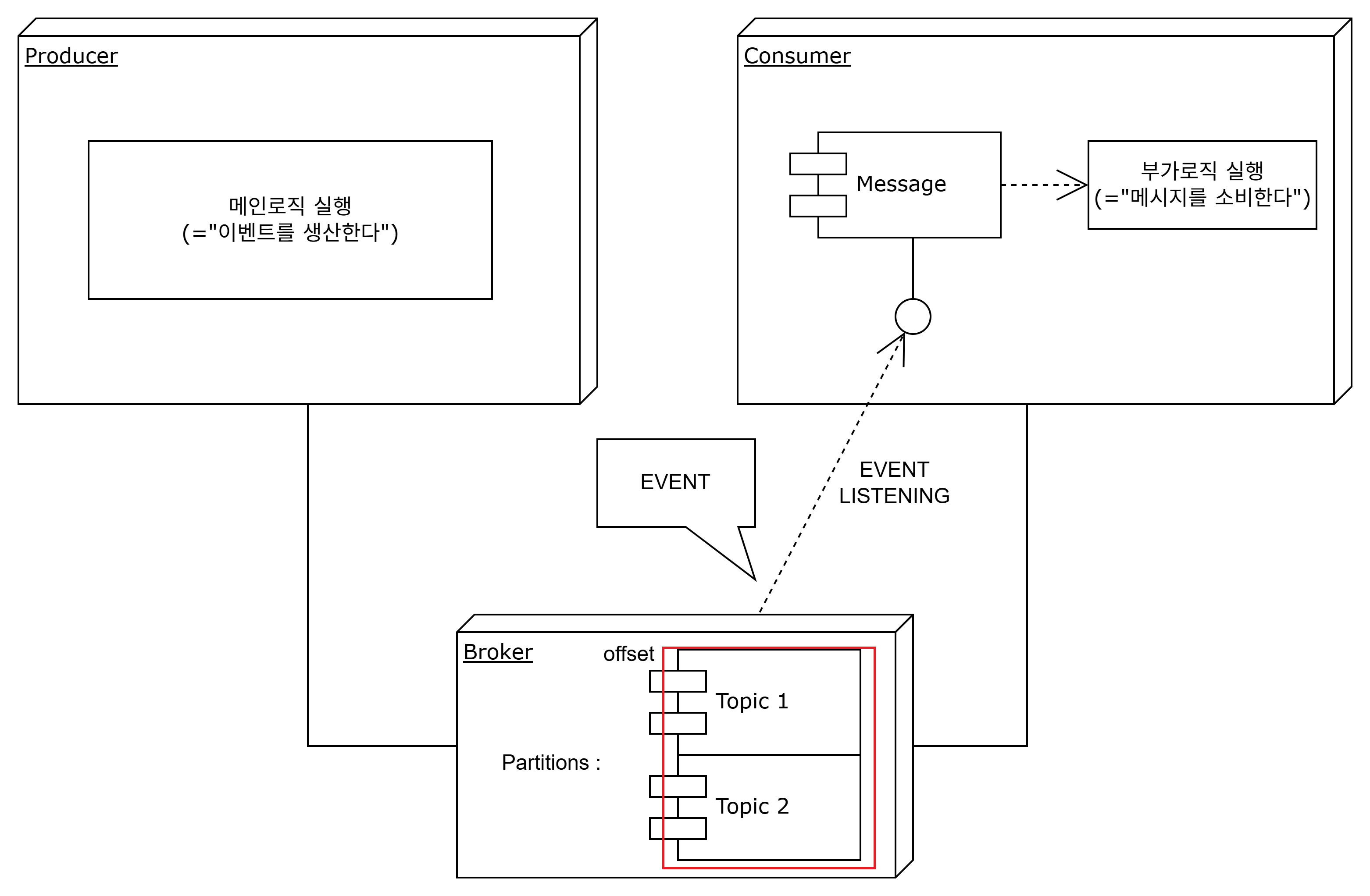
메인 로직을 진행하는 서비스(producer)가 메시지를 전달할때, broker에 같은 관심사 메시지를 저장하기 위한 구분인자(도메인)이다.
같은 관심사(topic) 내 메시지를 구독하고 있는 consumer가 메시지 발행을 감지하여 후행동작을 진행한다.
- partition
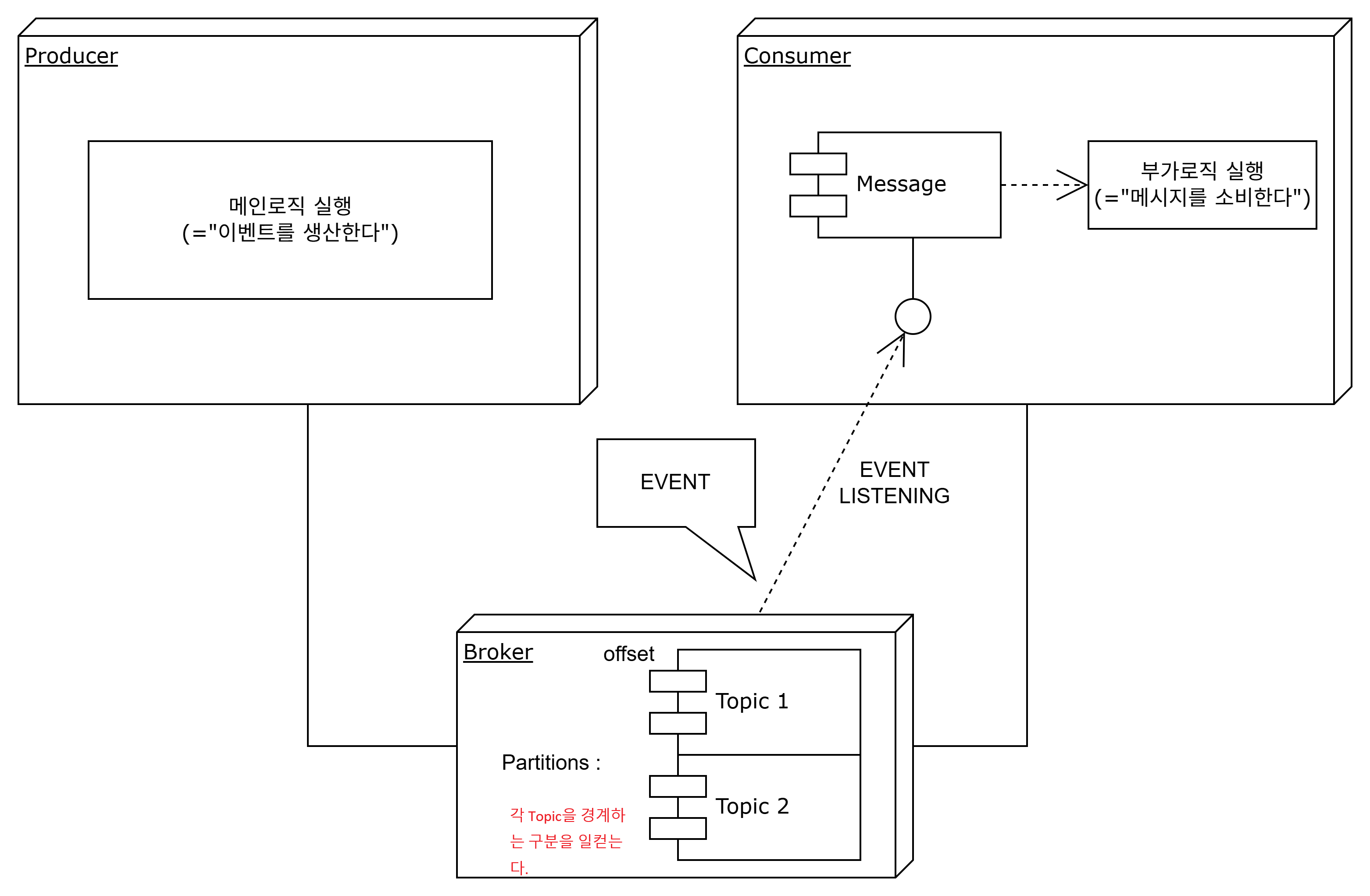
메시지가 서로 다른 도메인, 즉 다른 topic일때 구분하여 저장하기 위한 경계이다.
즉, topic이 다르다면 다른 partition에 메시지를 저장한다.
- broker
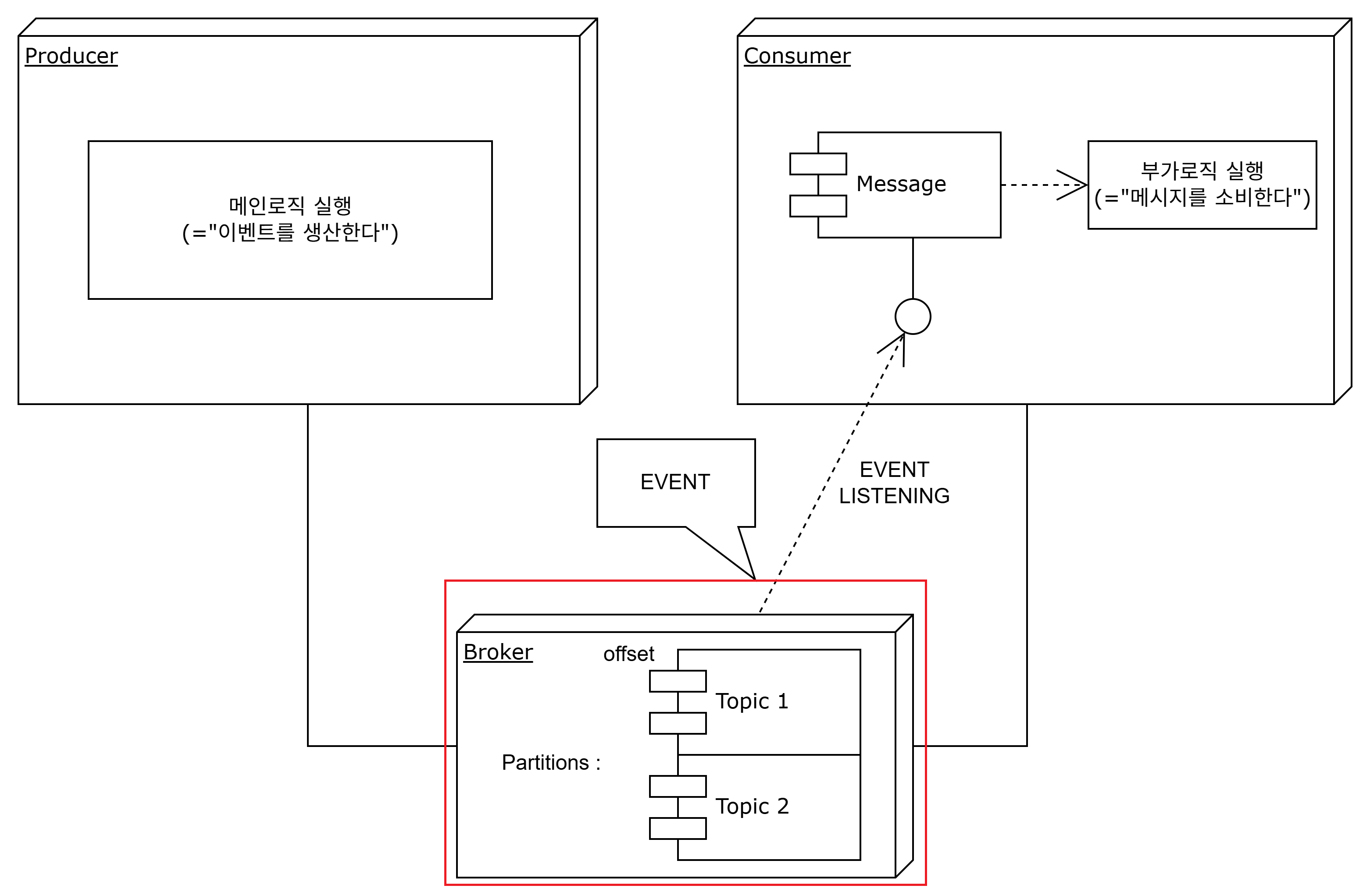
kafka cluster 내에서 메시지를 저장하고 관리해주는 체계이다.
partition, consumer group 등을 관리하는 환경적인 개념이라 볼 수 있겠다.
- Segment(Offset)
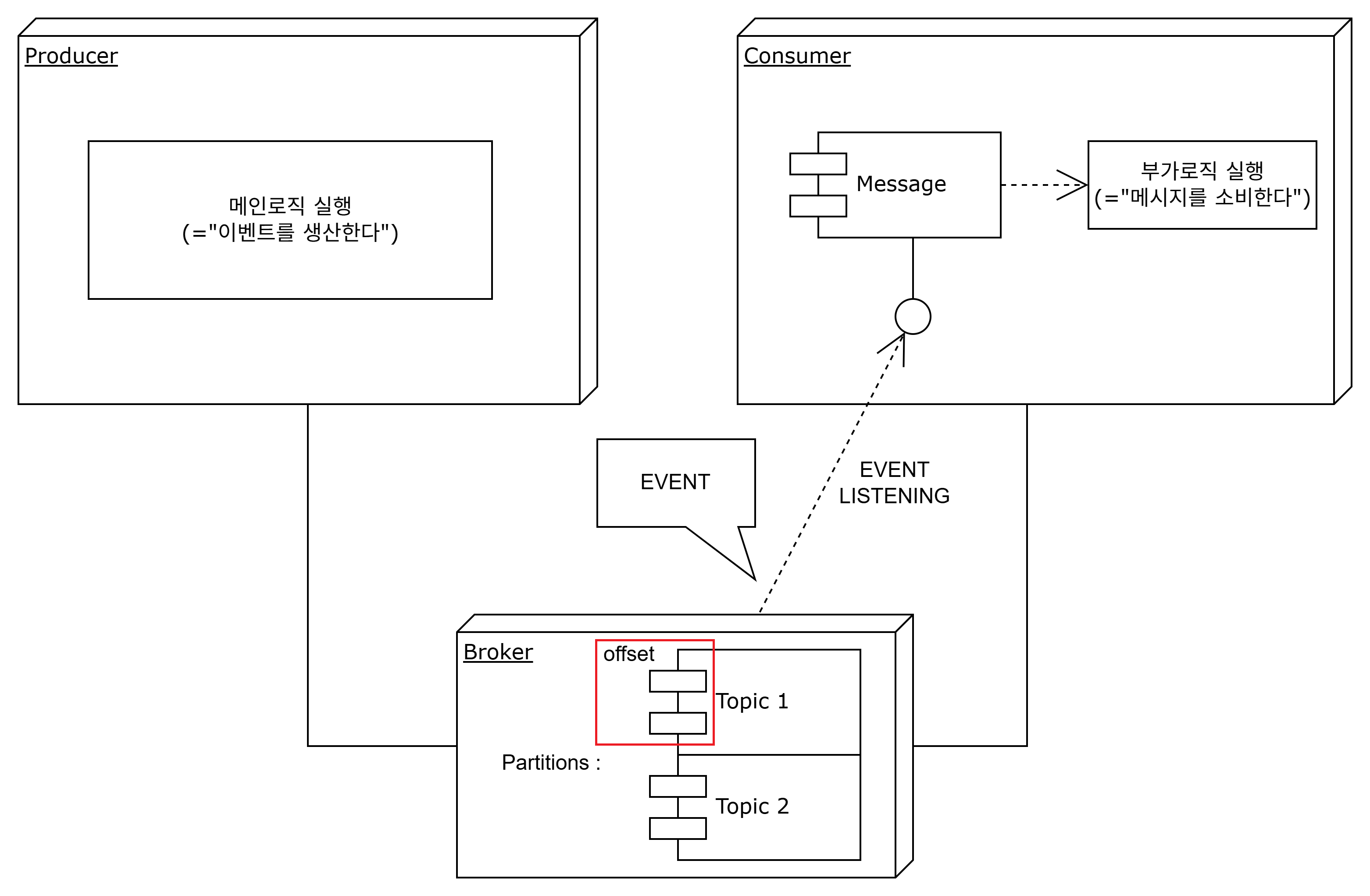
같은 topic에서 동일한 key값을 가지는 메시지들이 저장되는 곳이며, 이를 구분하여 메시지들을 저장하여 순차처리 및 동시성 처리를 보장해주는 세부적인 구분인자이다.
offset에 같은 topic 메시지들이 쌓이고 이를 기반으로 consumer가 처리하기 때문에, 순차처리 및 원자성을 보장해준다.
3. kafka를 사용하는 목적
위에서 설명을 거의 다 하였지만, 정리하는 차원에서 복습해보자.
kafka의 정체성은 기본적으로 "대용량 트래픽 제어"에 있다고 볼 수 있겠다.
-
동시성 제어 및 원자성
이 서비스들을 특정 기준(key)에 따라 동일 topic안에서 Queue처럼 대기시키므로, 동시에 요청이 들어온 서비스들의 동시성 제어와 각 처리에 대한 원자성 보장을 해준다. -
순차처리 보장
서비스들이 topic안에서 들어온 순서대로(earlist) 처리를 보장하여, 순차처리를 보장해준다.
4. kafka 적용해보기
4-1. kafka 설치
Kafka 설치는 이곳에서 할 수 있다.
또한 반드시 Zookeeper까지 설치해야 Kafka를 실행할 수 있다.
4-2. kafka 환경설정
Spring framework (gradle)에서 kafka를 활용하기 위한 기본적인 환경설정을 해준다.
- gradle 의존성 추가
//kafka
implementation("org.springframework.kafka:spring-kafka")- application.yml에서 producer와 consumer에 대한 기본적인 환경설정
offset 유실방지 및 Error Handling을 위해 enable-auto-commit을 false로 설정하였고, 자세한 설명은 후술한다.
spring:
kafka:
consumer:
bootstrap-servers: localhost:9092 # Kafka 클러스터(브로커)의 주소
group-id: platform # consumer group을 관리하기 위한 식별자
auto-offset-reset: earliest
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer # Kafka 메시지 key 역직렬화(*1단계 - 단순 문자열)
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer # Kafka 메시지의 value를 역직렬화(*1단계 - 단순 문자열)
enable-auto-commit: false #offset 유실을 방지하기 위해 수동커밋으로 변경
max-poll-interval-ms: 60000 # 1분안에 후행 서비스 처리를 못하면 실패로 판단하고 메시지를 재전송함
producer:
bootstrap-servers: localhost:9092 # Kafka 클러스터(브로커)의 주소
key-serializer: org.apache.kafka.common.serialization.StringSerializer # Kafka 메시지 key 역직렬화(*1단계 - 단순 문자열)
value-serializer: org.apache.kafka.common.serialization.StringSerializer # Kafka 메시지의 value를 역직렬화(*1단계 - 단순 문자열)4-3. kafka 본격활용 - kafka로 이벤트 전달하기(단순 문자열을 통한 통신)
Kafka를 통해 이벤트를 구독하는 consumer(platformService)가 단순 문자열 기반 통신을 하도록 설정할 수 있다.
/*
* 카프카 프로듀서
* 메시지를 발행하기 위해 전역적인 infra로 구성하여 활용합니다.
* */
@Component
@RequiredArgsConstructor
public class KafkaProducer {
/*
* producer 서비스가 메시지를 발행할때 사용하는 메소드를 정의합니다.
* 전역적으로 활용할 수 있기에 config 도메인에서 구성해주는게 좋습니다.
* */
private final KafkaTemplate<String, String> kafkaTemplate;
/*
* 외부 데이터 플랫폼에 전송하기 위한 컨슈머와
* 이를 위해 설정한 토픽을 기반으로
* 메시지 발행합니다.
* */
public void publish(String message) {
kafkaTemplate.send(PlatformEnum.PLATFORM.topic(), message);
}
}먼저 이벤트를 발행할 KafkaProducer를 구성해준다. KafkaProducer는 별도의 kafka 도메인에서 생성하여, 전역적으로 각 도메인에서 이벤트 발행시 활용할 수 있도록 하였다.
kafkaProducer.publish(String.valueOf(orderDTO.getOrderId()));이처럼 메인로직에서 kafkaProducer의 이벤트 발행을 해주도록 구현하면 된다.
/*
* platform topic으로 발행되어
* platform consumer group에 메시지를 발행한 프로듀서에 반응하는 리스너입니다.
*
* */
@KafkaListener(topics="platform", groupId="platform")
public void sendData(String orderId) {
log.info("*********************");
log.info("데이터 외부 전송 mock API");
log.info("주문 정보를 전송합니다 : {}", orderId);
log.info("주문 세부 정보를 전송합니다 : {}", orderReaderRepository.findById(Long.valueOf(orderId)));
log.info("*********************");
}이때 발행하는 메시지를 단순 문자열로 구성해주었기에, consumer 측에서도 동일하게 단순 문자열로 메시지를 전달받을 수 있도록 해주면 된다(아래 부가로직이 후행 실행되어 로그로 출력되는 모습).

이처럼 단순 문자열 기반의 메시지 전달을 기본으로 kafka 활용을 학습할 수 있겠다.
4-4. kafka 본격활용 - kafka로 이벤트 전달하기(Record를 통한 통신)
Kafka를 통해 이벤트를 구독하는 consumer(platformService)가 단순 문자열로는 통신이 힘들 경우, 역직렬화된 문자열(길이가 긴 문자열)을 받을 수 있도록 설정할 수도 있다.
kafkaTemplate.send(PlatformEnum.PLATFROM.topic(), String.valueOf(order.getId()), payload);기본적으로 producer에서 발행해주는 메시지의 형태가 곧 consumer가 받는 메시지의 형태이므로, producer에서 consumerRecord 타입으로 메시지를 발행하도록 해준다.
@Component
@AllArgsConstructor
public class PlatformEventConsumer {
@Autowired
private PlatformSenderService platformSenderService;
/*
* platform 도메인에서 Event Consumer 컴포넌트를 별도 생성하여
* Kafka로부터 메시지를 Record 형태로 받아 consuming 하는 로직을 별도 생성합니다.
* 의존받는 서비스만 주입하여 consume - 후행로직처리를 별도의 과정으로 실행할 수 있도록 합니다.
* */
@KafkaListener(topics = "platform", groupId = "platform")
public void platformConsume(ConsumerRecord<String, String> record, Acknowledgment jointProcess) {
/*
* platformService를 DI받습니다.
* */
platformSenderService.sendData(record.value());
/*
* 수동으로 확실히 커밋하도록 하여 offset 유실 및 누락을 방지합니다.
* acknowledge 하는 과정 자체가 "정상적으로 메시지를 처리하고 offset를 확실히 처리했다는 것"을 의미합니다.
* */
jointProcess.acknowledge();
/*
* acknowledge 커밋하기전에 오류가 발생한다면
* try-catch로 예외발생문을 처리하지 않아도 카프카는 자체적으로 해당 컨슈머에게 메시지를 재발행합니다.
*
* max-poll-interval-ms: 60000의 환경설정을 해주었으므로
* 서비스 처리를 1분이상 지체할 경우 자동으로 메시지를 재전송합니다.
* */
}
}그 후 consumer가 Record 형태로 메시지를 전달받아 후행 동작을 처리하도록 구성하고, Consumer는 도메인 하위에 별도 Kafka Consumer 클래스로 구성하였다.
이때 Record로 메시지를 받는 전달부와 실제 동작을 처리하는 동작(서비스)부를 나누어 구현하고, 특히 동작 처리는 서비스만 주입받아 사용하도록 구성하여 적절한 도메인 분리와 API 구성을 굳이 변경하지 않도록 하였다.
5. 유의사항 - offset 유실을 방지하기 위한 방안
consumer가 메시지를 처리하지 못하거나, 처리하면서 오류가 발생하였을 경우에 대한 대비책도 고려해야 한다.
kafka 측에서는 auto commit을 false로 설정해주었을때 수동커밋 이전에 오류발생 시 다시 해당 consumer에게 메시지를 다시 보내주는 정도만 해준다.
하지만 계속 메시지를 재전송할 수도 없고, 재시도처리를 하기 위해 consumer가 계속 대기할 수도 없기에 사용자가 직접 정책을 만들어주는 것이 필요하다. 또한 offset(message) 자체가 유실되었을때 이를 따로 보관하여 이후에 처리한다던지 하는 방법도 있겠다.
current offset 은 유실 될 가능성을 염두에 두고 적절한 환경설정 및 에러 핸들링을 구성해보자.
5-1. application.yml 설정
기본적으로 offset 유실을 방지하기 위해 메시지를 수동으로 커밋하는 방식으로 변경하고, 이외 메시지 처리 실패를 판단하기 위한 인터벌을 얼마나 둘 것인가를 설정해주는 것이 좋겠다.
enable-auto-commit: false #offset 유실을 방지하기 위해 수동커밋으로 변경
max-poll-interval-ms: 60000 # 1분안에 후행 서비스 처리를 못하면 실패로 판단하고 메시지를 재전송함위의 경우 60초(1분)으로 설정하여, 1분안에 서비스를 처리하지 못할 경우 예외상황이라 판단, 메시지를 다시 재발행할 수 있도록 하였다.
5-2. ConcurrentKafkaListenerContainerFactory
Kafka Consumer 측에서 예외 상황을 어떻게 처리할것인지 정책정보를 적용하고, DLQ(유실메시지 보관) 등의 정보를 저장하기 위한 RuleDefiner를 설정해주었다.
RuleDefiner를 컴포넌트로 등록하였고, Consumer 측에서 KafkaListening 할때 ConcurrentKafkaListenerContainerFactory에 담겨진 정보를 참고하게 된다.
참고로 Spring 2.5버전 이전에는 setRetryTemplate을 사용하였으나 현재는 decprecated되었고, setHandlerError를 활용하여 Consumer 정책을 정의할 수 있다.
/*
* offset 유실방지 대책 : 재시도 횟수 제한 및 실패 메시지의 DLQ 처리
* ErrorHadnler와 DLQ 등
* 메시지 발행 실패 후 재시도 및 메시지 발행 재시도 최대 횟수 제한 등
* Consumer의 정책을
* Spring 2.5버전 이전에는 setRetryTemplate을 사용하였으나 현재는 decprecated.
* setHandlerError를 활용하여 Consumer 정책을 정의하도록 구성합니다.
* */
@Component
@AllArgsConstructor
public class KafkaConsumerRuleDefiner {
/*
* reference for : Listenr Container
* 즉 Kafka 리스너는 Rule Definer를 참조하게 되는 형태
* Listner Container에 정책정보와 에러 핸들링 정보가 모두 들어있습니다.
* */
/*
* Spring은 애플리케이션 컨텍스트를 초기화할 때: 모든 @Bean, @Component, @Service, @Configuration 등을 스캔
* 필요한 순서로 의존성 주입 (Dependency Injection) 수행
* 정의된 순서와 무관하게 Spring이 필요한 순서로 자동 주입을 해주기에, 빈 순서 상관없이 필요 빈을 등록하기만 하면 됩니다.
* consumerFactory의 정보는 아래에서 등록한 consumerFactory 빈의 정보로 메서드 이름의 빈을 그대로 활용하면 됩니다.
* */
/*
* factory 1 : kafka listener가 내부적으로 사용하는 Container Listener 정보가 담겨져 있는 정보
* */
@Bean
public ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory(
DefaultKafkaConsumerFactory<String, String> consumerFactory,
KafkaTemplate<String, String> kafkaTemplate
) {
ConcurrentKafkaListenerContainerFactory<String, String> factory =
new ConcurrentKafkaListenerContainerFactory<>();
//kafka consumer 정보가 담겨져있는 정보
factory.setConsumerFactory(consumerFactory);
// 메시지 발행이 실패했을 경우에 대한 정책 정보 반영
factory.setCommonErrorHandler(this.commonErrorHandler(kafkaTemplate));
return factory;
}
/*
* factory 2 : kafka consumer의 기본정보가 담겨져있는 정보
* reference for : application.yml
* */
@Bean
public DefaultKafkaConsumerFactory<String, String> consumerFactory(KafkaProperties kafkaProperties) {
return new DefaultKafkaConsumerFactory<>(kafkaProperties.buildConsumerProperties());
}
}ConcurrentKafkaListenerContainerFactory는 consumer factory가 담겨진 consumerFactory 정보와 에러 핸들링(재시도 최대 횟수 및 DLQ 등) 정보가 담겨진 commonErrorHandler 정보를 bean으로 부터 받아와 최종 적용한다.
5-3. DLQ/Error Handling 정책
위에서 ConcurrentKafkaListenerContainerFactory에 저장할 DLQ/Error Handling 정책 정보를 추가 구성해주도록 한다.
DLQ(Dead Letter Queue)는 유실된 메시지, 즉 처리하지 못한 메시지를 별도 topic을 두어 저장하여 후처리하는 과정이고 Error Handling은 메시지 처리를 실패하였을때 어떤 간격으로 최대 몇회까지 메시지 발행을 재시도할 것인지에 대한 과정이다.
/*
* factory 3 : Error Handling(*메시지 커밋 실패시에 대한 정책 정보)
* */
@Bean
public CommonErrorHandler commonErrorHandler(KafkaTemplate<String, String> kafkaTemplate) {
/*
* 3회 재시도 후 DLQ topic으로 전송하여 커밋하지 않은 메시지들을 쌓아놓고 이후에 처리하도록 설정합니다.
*/
var recoverer = new DeadLetterPublishingRecoverer(kafkaTemplate,
(record, ex) -> new TopicPartition(PlatformEnum.DLQ.topic(), record.partition()));
var backOff = new FixedBackOff(60000L, 3L); // 1분 간격, 재시도 최대 횟수 3회로 제한
return new DefaultErrorHandler(recoverer, backOff);
}DLQ의 경우 enum을 따로 구성하여 DLQ topic으로 유실된 메시지를 보내도록 하였고, 메시지 처리 실패 상황이 발생한다면 1분 간격으로 최대 3번까지 재시도하도록 하였다.
6. 참고자료
kafka 설치 및 띄우기 - https://velog.io/@so-eun/Kafka-%EC%9C%88%EB%8F%84%EC%9A%B0-%EB%A1%9C%EC%BB%AC-%EC%97%90%EC%84%9C-%EC%B9%B4%ED%94%84%EC%B9%B4-%EC%8B%A4%ED%96%89%ED%95%B4%EB%B3%B4%EA%B8%B0
Kafka 구성요소 - https://curiousjinan.tistory.com/entry/understanding-kafka-all-structure
Kafka 기초 - https://soonmin.tistory.com/m/22
Kafka consumer/producer 구성방안과 역직렬화를 별도 클래스로 구현할 경우 - https://velog.io/@cobin_dev/Kafka로-Java-객체-전송하기
심화(Kafka Consumer가 많아질때 고려해야할 점들) - https://velog.io/@sunwupark/Kafka-Kafka-Consumer-Thread
