
브라우저에 URL을 입력했을 때 - 1. 브라우저가 화면을 그리기 위해 파일을 가져오는 단계
를 이어서 배워 보려 한다.
참고로 본 게시물은 Chrome broswer architecture에 대해 초점을 맞춰서 알아 볼 것이다!
Chrome broswer는 어떤 processes로 구성이 되어 있을까?
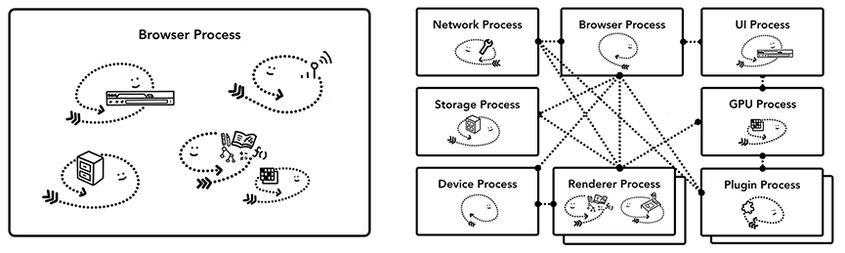 위의 이미지는 일반적인 broswer architecture이다.
위의 이미지는 일반적인 broswer architecture이다.
(broswer architecture는 표준이 없다는 특징이 있어서 각 broswer마다 architecture가 조금씩 다름)
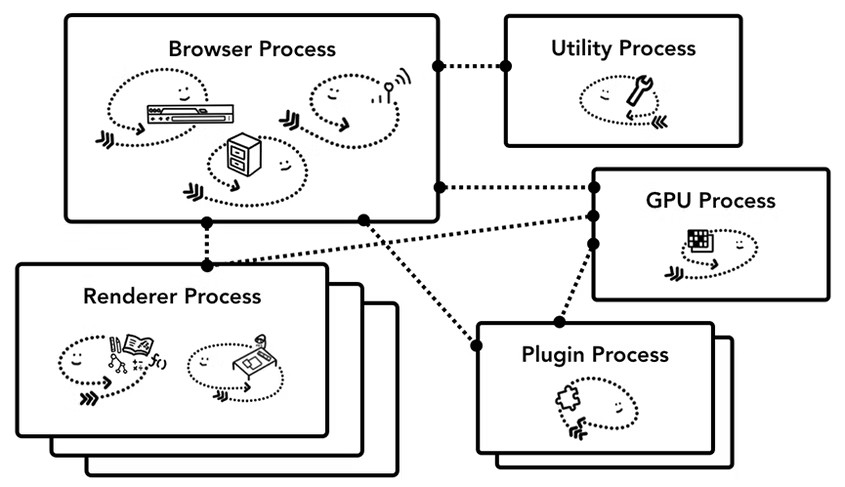 이미지로 chrome broswer architecture가 어떤 process들로 어떻게 구성되어 있는지 있는지 간단히 알아볼 수 있는데,
이미지로 chrome broswer architecture가 어떤 process들로 어떻게 구성되어 있는지 있는지 간단히 알아볼 수 있는데,
Browser Process는 Utility process, GPU process, Plugin process, Renderer process와 연결이 되어 있음을 확인할 수 있다.
또한, renderer process와 plugin process가 여러개 있다는 특징도 알 수 있다.
그렇다면 각 process들은 어떤 역할을 담당하고 있을까?
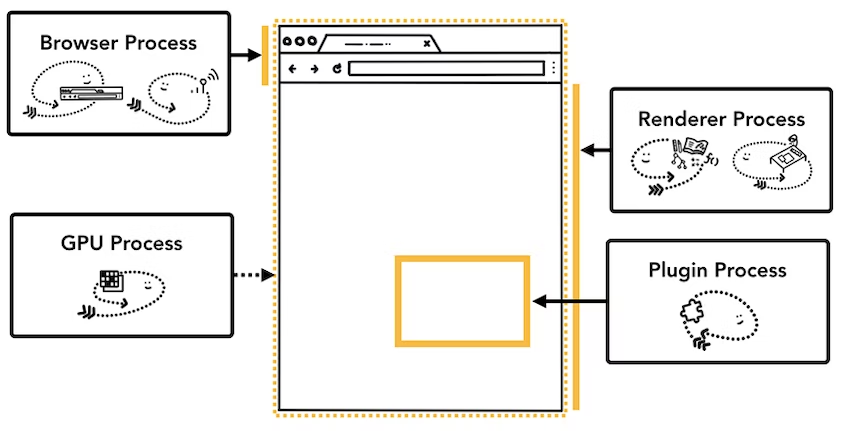
-
Browser Process
: 항상 사용해서 익숙한 위의 브라우저 창 이미지를 보면,
x버튼으로 나갈 수 있고, tab이 있으며,
그 아래 앞/뒤로가기 버튼, 새로고침 버튼, URL 입력창 등이 있다.
이런 것들을 담당 하는 것이 브라우저 프로세스이다.
Browser Process 중에서는 UI Thread가 있고, Network Thread가 있다.
사용자의 입력이 일어나면 그 입력은 UI Thread가 처리하게 된다.
그리고 URL창에 특정 주소를 입력하면 그 주소를 토대로 Network Thread가 새로운 요청을 보내기도 한다.
이런 Thread들은 모두 Browser Process안에 있다. -
Renderer Process
: 위의 이미지에 노란 실선이 길게 표시되어 있다.
즉, tab 하나가 그리고 있는 browser안의 화면을 담당한다.
그래서 tab 하나당 Renderer Process가 하나가 생성된다. (chrome browser architecture의 특징임)
tab안에서 표현되는 모든 화면들은 Renderer Process가 담당한다고 이해하기!
tab을 여러개 띄울 수 있고, tab마다 Renderer Process가 생성되니까 tab이 여러개라면 당연히 Renderer Process도 여러 개가 된다. -
Plugin Process
: Plugin은 한 화면에 여러개 있을 수 있다.
그래서 Plugin Process 또한 각 Plugin당 하나 씩 생성되므로 여러 개가 동시에 있을 수 있다. -
GPU Process
: Browser Process와 Renderer Process가 담당하는 모든 전체 화면을 그리는 역할을 담당하고 있다.
Chrome broswer의 processes 구성이 가지는 장점은 무엇일까?
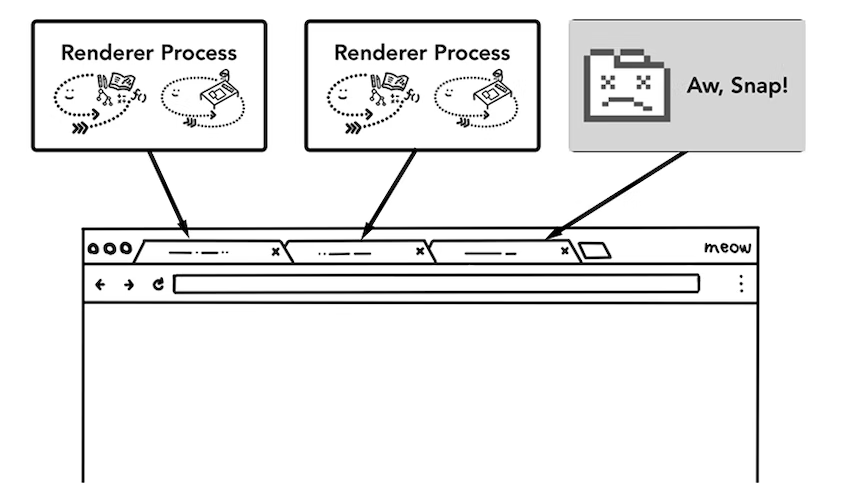
-
Renderer Process가 각 tab마다 생성되어 각각 담당한다는 점
위에서 설명한 것 처럼 chrome broswer는 tab마다 Renderer Process가 생성된다.
예시로 하나의 tab을 담당하고 있는 Renderer Process에서 어떠한 error가 발생해서 응답없음 상태가 되었다고 가정해보자.
이럴 때 해당 process를 강제 종료 시킨다고 하더라도 다른 tab은 종료되지 않을 수 있는 것이다.
다른 tab들은 다른 Renderer Process들이 각각 담당하고 있기 때문!
그런데 만약! Renderer Process가 여러 개가 아니라 하나만 있다면? 하나의 Renderer Process가 여러개의 tab을 다 담당하게 될 것이고, 특정 tab에 응답 없음 error가 발생하면 다른 tab들도 모두 종료가 된다.
하나의 tab에서 응답 없음이 발생하면 그 tab을 담당하고 있는 Renderer Process를 강제 종료 시켜야 하는데, 이 Renderer Process는 다름 tab들도 담당하고 있으므로 해당 Renderer Process가 종료되면 다른 tab들도 모두 종료가 되어야 한다.
이와 같은 비효율적인 상황을 Renderer Process가 각 tab마다 생성되어 각각 담당을 하므로써 막고 있다. -
보안과 샌드박싱
앞 게시물에서 process별로 각자가 OS에 의해 고유한 메모리 영역을 할당받는다고 했었다.
이와 같은 이유로 다른 Renderer Process가 해당 Renderer Process에 접근할 수가 없다.
즉 data에 접근할 수 없다. (접근하려면 권한을 부여 받아야 함)
그래서 보안적인 측면에서 더 유리한 점이 있는 것이다.
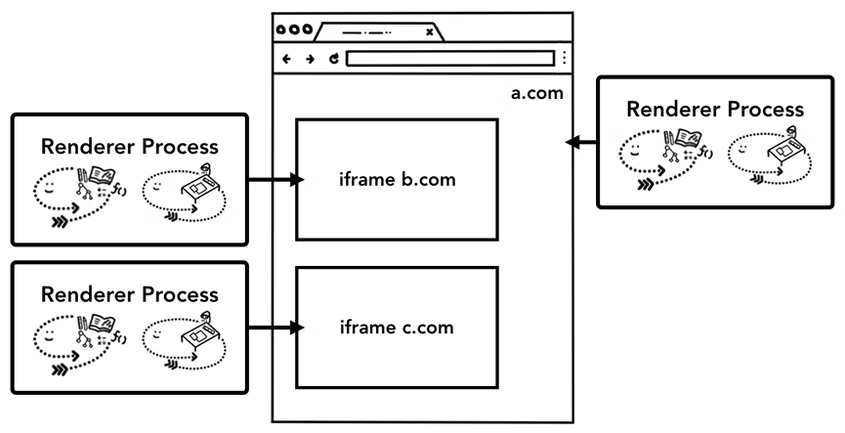 그리고 위의 이미지에서 설명하고 있는 것 처럼 현재 chrome browser architecture는 tab 하나당 Renderer Process가 있는 것을 넘어서 하나의 iframe당 Renderer Process가 생성되는 것 까지 진화한 것을 볼 수 있다.
그리고 위의 이미지에서 설명하고 있는 것 처럼 현재 chrome browser architecture는 tab 하나당 Renderer Process가 있는 것을 넘어서 하나의 iframe당 Renderer Process가 생성되는 것 까지 진화한 것을 볼 수 있다.
이런 점을 보면 chrome browser architecture는 보안을 최대한 생각하고 있다는 것을 알 수 있다.
동일 출처 정책을 지켜 각 사이트 별로 각자의 데이터를 고유의 Process가 할당 받을 메모리 안에 저장하고 관리하므로써 다른 사이트가 접근할 수 없도록(권한 없이는 접근할 수 없도록) 하고 있다.
이렇게 분리된 multi process architecture 를 가지고 있어서 chrome browser의 architecture는 보안을 강화할 수 있게 된다.
Chrome broswer architecture가 가지는 한계점🤔
장점이기도 했던 tab하나당 Renderer Process가 생성되는 상황이 늘어서 계속계속 증가하는 상황이 온다면? 고유한 메모리 영역도 Renderer Process의 수만큼 점점 늘어날 것이다. 그렇게 되면 메모리의 한계점이 있을 것이다.
그래서 Chrome broswer architecture가 가지는 한계점을 극복한 방법이 있다!
chrome broswer는 Renderer Process수 의 limit을 가지고 있다.
만약, chrome broswer가 실행되고 있는 환경의 CPU와 메모리가 충분하지 않은 상황이 오면, 메모리를 절약하기 위해 process들을 통합하는 작업을 하게 된다.
2. 웹 사이트가 렌더링하기 바로 직전까지의 과정
Renderer Process에게 데이터를 전달하는 바로 직전 까지의 과정을 5단계로 알아보자.
1) Handling Input
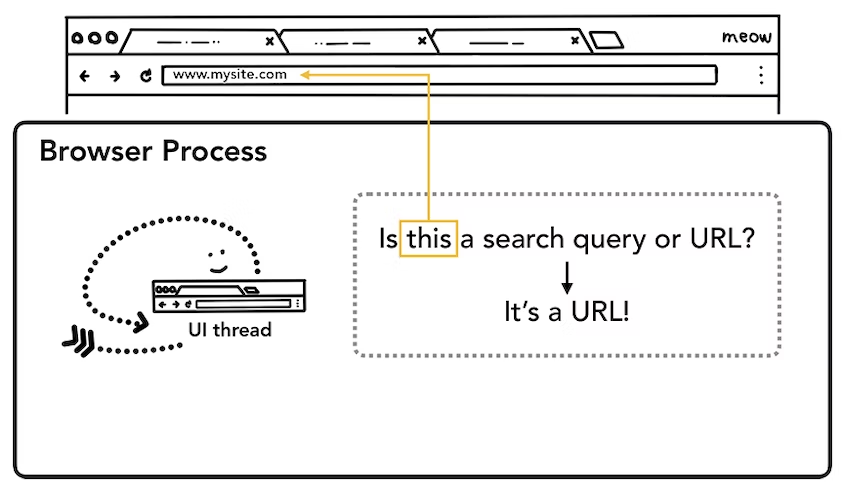 유저가 URL창에 글자를 입력한다고 생각해보자.
유저가 URL창에 글자를 입력한다고 생각해보자.
browser Process안에 있는 UI Thread가 유저가 입력한 text값을 통해 해당 text가 진짜 URL값인지, 아니면 search query인지를 판단하게 된다.
-
search query일 경우
: chrome browser의 경우에는 해당 search query를 바로 google search engine에게 넘겨주어서 바로 검색이 된다. -
URL일 경우
: URL값을 Network Thread에게 전달할 준비를 한다.
여기 까지의 과정을 handling input이라고 한다. 이렇게 준비가 되고 나면 start navigation과정이 시작된다.
2) Start Navigation
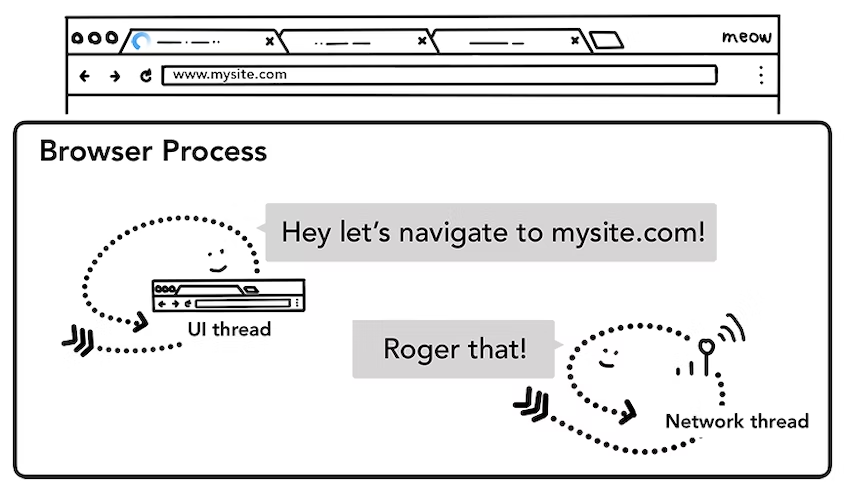 네비게이션이 시작되는 과정으로, 이때는 유저가 URL창에 input값을 다 입력한 다음 enter를 치며 시작되는 과정이다.
네비게이션이 시작되는 과정으로, 이때는 유저가 URL창에 input값을 다 입력한 다음 enter를 치며 시작되는 과정이다.
1단계에서 Network Thread에게 전달할 URL값을 전달하기 직전에 UI Thread가 network call initiates를 하게된다.
=> network call인데 왜 이것을 Network Thread가 initiates안하고 UI Thread가 하는가?
: 위의 이미지에서 tab에 로딩 스피너가 있는 것을 볼 수 있는데, 이 로딩 스피너를 그리는 것을 매니징하는 것이 UI Thread이다. UI Thread가 이 로딩 스피너를 그리려면 network call이 시작됐다는 것을 UI Thread가 알고 있어야 할 것이다. 그래서 UI Thread가 network call을 initiates하게 되고, 그 다음 바로 로딩 스피너를 tab왼쪽에 그리게 된다.
그리고 나서 network call initiates하는 동시에 Network Thread에게 URL값을 전달했기에 Network Thread는 그 URL값을 활용해서 DNS에도 연결을 하게 되고, 또한 TLS(ransport Layer Security) connection을 생성하게 된다. (이때 TLS는 보안 관련 레이어라고만 일단은 알아두자!)
만약, Network Thread로 해당 요청에 대해 http status code가 301(=redirect response)가 오게 되면 redirect를 해야 한다고 UI Thread에게 다시 전달하게 된다.
이때 UI Thread는 다른 Network call을 initiates하게 된다.
근데 301 code가 아니라고 한다면?? 다음 과정인 Read Response으로 넘어간다.
3) Read Response
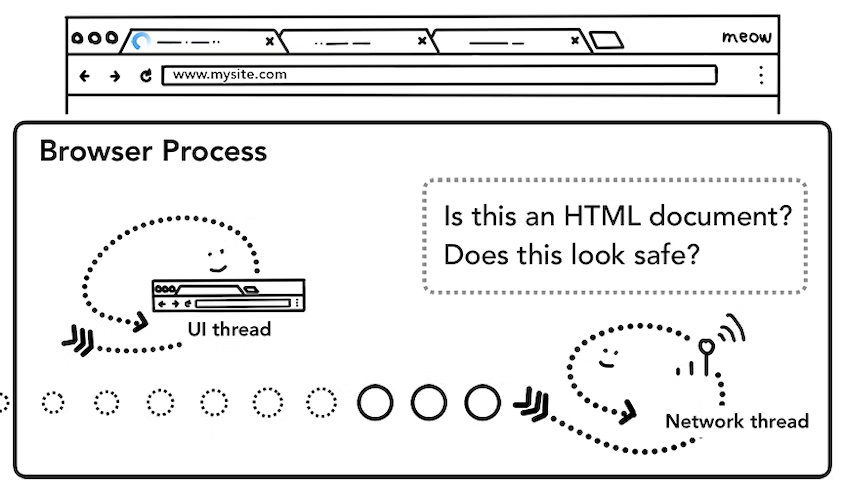 response body가 Network Thread로 들어올 때 Network Thread가 들어오는 응답 (response body data의 type)을 확인해야 한다.
response body가 Network Thread로 들어올 때 Network Thread가 들어오는 응답 (response body data의 type)을 확인해야 한다.
data의 type을 확인해야 하는 이유는?
-
HTML형식이 아닐 경우(Zip파일 등..)
: response body에 담겨져 온 data를 download manager에게 전달해야 한다.
왜냐하면 이것이 웹사이트를 렌더링 하는 과정이 아닌, 다운로드 과정이 진행되어야 하기 때문이다. -
HTML 형식일 경우
: response body에 담겨져 있는 data를 Renderer Process에게 전달할 준비를 해야한다.
위와 같이 type에 따라 경우가 나눠지기 때문에 파일의 type을 확인해야 한다.
그렇다면 어떻게 확인해야 할까?
가장 먼저는 response header의 content-type으로 type을 확인한다. 그것이
MIME(Multi-purpose Internet Mail extensions)라는 type을 표시하는 stream인데, 이것만으로는 오류(오타)로 인해 제대로 확인이 안될 수 있다. 그래서 한번 더 체킹하기 위해 MIME type sniffing이라는 것을 한다.
(type sniffing는 data stream의 몇몇 byte 조금을 먼저 읽는 것이다. 그로 HTML형식 이구나 아니구나를 한번 더 확인함)
이렇게 확인한 다음, data type이 HTML이라면
이제 Renderer Process에게 해당 data를 전달할 준비를 마치게 된다.
이때 Renderer Process에게 HTML파일을 전달하기 전에 두가지 과정이 더 필요하다.
-
1번째는 SafeBrowsing
: domain이나 data가 malicious 체크(악의가 있어서 나쁘게 만들려고 하는 사이트인지를 SafeBrowsing를 통해 체크)
만약, 알려져있는 악의를 가진 사이트라고 판단되면 warning page를 보여준다. -
2번째는 CORB(Cross Origin Read Blocking)
: 민감한 cross-site data,
(이 부분을 알려면 Same Origin Policy에 대해서 알아야 하는데, 간단히만 짚고 가자면, origin이 완전히 동일한 site의 data만 신뢰할 수 있다고 판단하는 정책이다. 즉, Same Origin의 data는 안전하고 신뢰할만 하다고 말해주는 정책인데, 이것을 반하는 data가 cross-site data이다.)
cross origin을 가진 site에서 data를 받아오면 그 data는 신뢰할 수 없어서 그것을 읽는 것은 Blocking해야 한다고 판단한다.
그래서 해당 data는 Renderer Process에게 전달하지 않게 된다.
이렇게 Read Response과정에서 요청을 통해 받아온 data의 type이 HTML인지 체크하고, SafeBrowsing과 CORB과정을 통해 안정성까지 검증했다고 하자. 그다음은??
4) Find Renderer Process
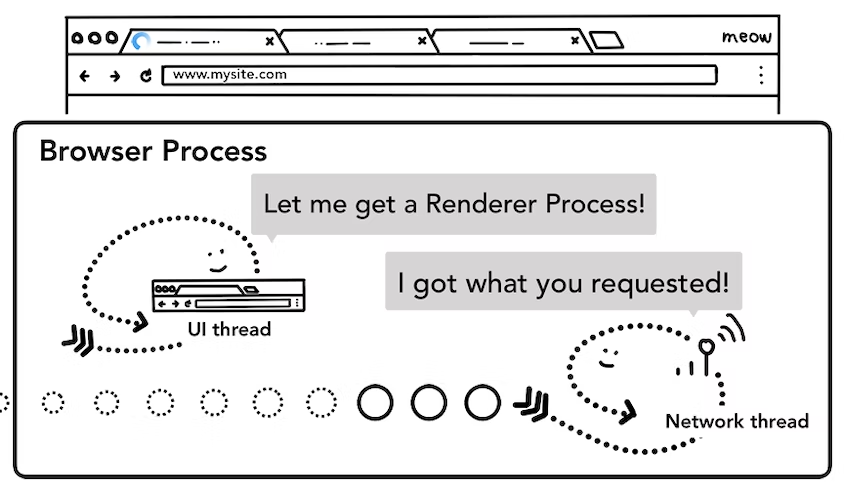 해당 스테이지는 Network Thread가 type과 여러 안정성에 대한 확인이 끝난 후 브라우저가 해당 사이트로 이동을 해야 한다는 판단이 섰을 대때 진행되는 과정이다.
해당 스테이지는 Network Thread가 type과 여러 안정성에 대한 확인이 끝난 후 브라우저가 해당 사이트로 이동을 해야 한다는 판단이 섰을 대때 진행되는 과정이다.
여기서 주의해야 할게 있다.
해당 Find Renderer Process과정은 Network Thread가 data가 다 준비되었고 UI Thread에게 전달해서 UI Thread가 다시 Renderer Process에게 준비된 data를 전달할 차례인데, 이 4단계에서 Renderer Process를 찾는 것이 아니라 미리 찾아 놓는다.
=> 2단계인 start navigation에서 미리 찾아 놓음. 어떻게 그럴 수 있냐면 UI Thread가 Network call을 initiates를 하면서 이 Network call은 server와 통신이라 수백ms가 텀이 발생한다.
그래서 이 텀 동안에 UI Thread가 미리 Renderer Process를 찾아놓고 준비를 시켜놓는다. 병렬적으로 처리를 할 수 있고, 이렇게 했을 때 시간을 아껴줄 수 있다. 만약 이것을 동기적으로 Network call이 끝난 다음부터 Renderer Process를 찾기 시작한다면 시간이 더 많이 들 것이다. 이런 시간을 아끼기 위해 UI Thread는 Renderer Process를 미리 찾아 놓는다.
이렇게 미리 찾아 놓은 Renderer Process에게 아까 응답으로 전달받은 data, 즉 HTML을 전달한다. 그리고 나면 이 Renderer Process는 이제 렌더링할 준비를 시작하게 된다.
이때 렌더링 직전에 발생하는 것이 commit navigation 과정이다.
5) Commit Navigation
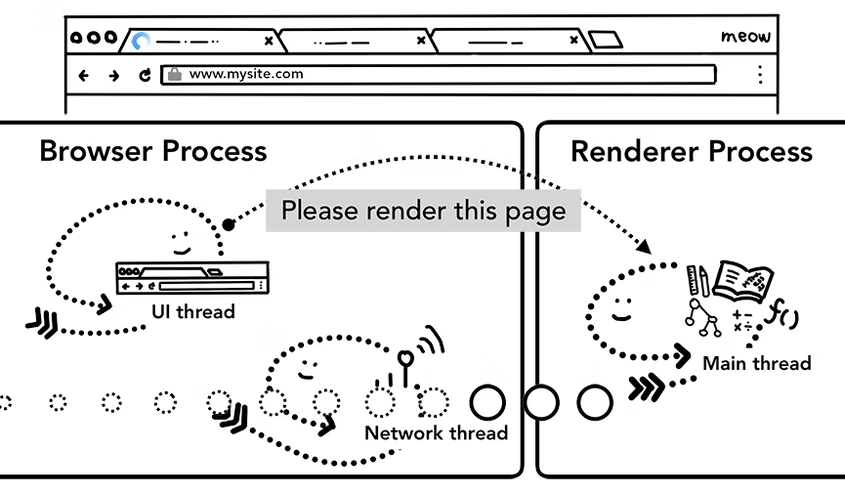 해당 과정을 통해 navigation이 commit이 된다. 이 과정까지 끝나고 나면 브라우저가 이제 Renderer Process를 실행하고 있기 때문에 Renderer Process안에서 렌더링하는 과정이 진행이 된다. 그리고 그 직전까지의 단계가 바로 Commit Navigation!
해당 과정을 통해 navigation이 commit이 된다. 이 과정까지 끝나고 나면 브라우저가 이제 Renderer Process를 실행하고 있기 때문에 Renderer Process안에서 렌더링하는 과정이 진행이 된다. 그리고 그 직전까지의 단계가 바로 Commit Navigation!
해당 과정에서는 어떤 것이 필요할까?
위에서 Browser process안에 UI Thread가 HTML파일 data를 가지고 있다고 했었다.
이 HTML파일 data를 이제 Renderer Process에게 전달한다. 이때는 process와 process간의 data이동이라서 inter-Process communication(IPC)을 활용하게 된다.
이때 navigation이 commit되기까지 계속 전달을 해주는 것이다. 그러면 HTML파일들을 받아서 Renderer Process는 렌더링을 시작한다.
Commit Navigation이 되었다는 확인을 들으면 그때 네비게이션이 끝나게 되는데, 그렇게 되면 document loading phase가 시작된다.
(document loading phase = Renderer Process가 시작하는 렌더링 과정)
document loading phase가 시작되기 전에 주소창이 업데이트가 되어야 하고(유저가 입력했던 그 주소창으로 업데이트),
그 다음 security indicator(주소창 부분 좌물쇠 모양 => 신뢰할만한 security가 검증된 사이트라는 것을 표시해주는 것)또한 업데이트가 되어야 한다.
그리고 site setting UI들이 새로운 페이지에 대한 정보로 반영이 되어 업데이트가 되야 한다.
현재 사이트가 아닌, 이동할 사이트의 정보로 확인이 되어서 그 사이트의 security를 표시하는 것으로 업데이트 되어야 한다.
마지막으로, 가장 중요한 것이 commit navigation의 마지막에 추가가 되어진다.
=> navigation이 commit되었다는 사실은 session history가 새롭게 추가되었다는 사실이다.
session history가 추가되면 뒤로가기를 눌렀을 때 유저가 방문했던 사이트로 돌아갈 수 있게되는 것이다.
만약, session history가 추가되지 않으면 기록이 없기 때문에 뒤로가기 기능을 사용할 수 없다.
마찬가지로, tab 혹은 창을 껐다가 다시 복구를 할 수 있으려면 해당 사이트에 대한 정보가 저장이 되어 있어야 한다.
(저장이 되어 있어야 한다는 것 = session history에 추가가 되는 것)
이렇게 commit navigation과정이 끝나면 아직 브라우저는 화면을 그리지 않았어도 직전까지(commit navigation까지 진행) 뒤로가기 버튼을 누르면 머물렀던 사이트로 이동할 수 있게 된다.
이렇게 된 후 최종적으로 Renderer Process가 HTML파일을 쭉 받으면서 여러가지 과정을 거친 후
모든 렌더링 과정이 끝나고 나면?
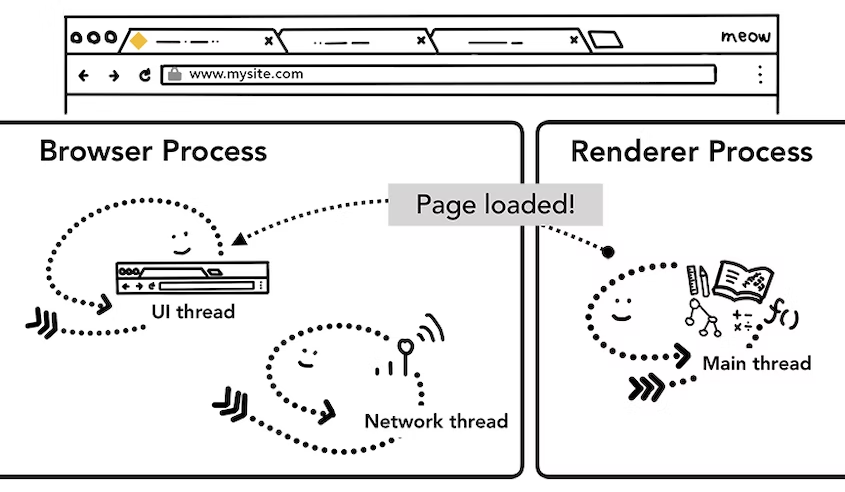 Renderer Process가 끝나기 전까지 계속 resorce를 loading 해온다.
Renderer Process가 끝나기 전까지 계속 resorce를 loading 해온다.
어떻게 그럴 수 있을까?
HTML tag중에서 image, script, style과 같은 tag들이 있다. 이렇게 외부 자원(CSS,Javascript,image..)을 계속 load할 수 있다.
이렇게 load를 하다가 모든 iframe에서 load가 다 끝나고 나면 Renderer Process는 렌더링이 끝난다고 가정하고, 렌더링이 끝나고 나면 Browser Process에게 IPC로 다시 돌려준다.
렌더링 끝났어~ 페이지 load 다 됐어~라고 알려주면 그때 Browser Process의 UI Thread가 완전히 로딩이 끝났으므로 로딩 스피너를 없앤다.
그런데, 이렇게 끝나더라도 HTML파일이 진행되는 과정에서 script tag를 가져올 수가 있다.
그래서 새롭게 resource를 load하거나, 새로운 view를 렌더링할 수 가 있다.
정리해보자면,
commit navigation을 하기 위해 handling input 부터 쭉 진행해온 것이다!!
브라우저가 어떻게 렌더링 되는지 문서와 좋은 영상 덕분에 이해가 잘 되었다😙
글로도 열심히 정리했으니 방치하지 말고 계속 읽자!!
참고 자료
