
본 포스팅은 《혼자 공부하는 머신러닝+딥러닝》 교재 1~2장을 참고하였습니다.
KNN (K-Nearest Neighbors)
K-최근접 이웃 (K-Nearest Neighbors) 알고리즘은 분류(Classifier)와 회귀(Regression)에 모두 쓰입니다. 처음 접하는 사람들도 이해하기 쉬운 알고리즘이며, 단순한 데이터를 대상으로 분류나 회귀를 할 때 사용합니다.
이 알고리즘은 매우 간단합니다. 어떤 데이터에 대한 답을 구할 때 주위의 다른 데이터를 보고 다수를 차지하는것을 정답으로 사용합니다.
데이터셋 불러오기
케글에서 데이터셋 다운받기
https://www.kaggle.com/datasets/aungpyaeap/fish-market
케글의 Fish market 데이터셋을 사용하겠습니다. 우측 상단의 다운로드 버튼을 눌러 다운받습니다.
Google Colab에 업로드하기
먼저 구글 코랩에 새 페이지를 만듭니다.
좌측에서 폴더 모양의 아이콘을 누르고, 첫번째 세션 저장소에 업로드 버튼을 눌러 Fish.csv 파일을 업로드 해 줍니다.
다음과 같이 파일이 업로드 된 것을 확인할 수 있습니다.
파이썬으로 csv 파일 읽기
Pandas의 read_csv를 활용해 csv 파일을 데이터 프레임으로 불러오겠습니다.
import pandas as pd
row_data = pd.read_csv('Fish.csv')
row_data.head()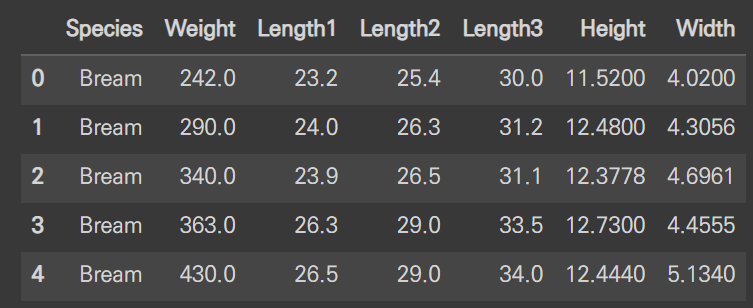
다음과 같이 head() 메서드를 사용하여 데이터를 간략히 확인할 수 있습니다.
필요한 부분만 리스트로 가져오기
도미(Bream)와 잉어(Roach)의 무게, 길이를 가져오겠습니다.
bream_weight = list(row_data.loc[row_data['Species'] == 'Bream']['Weight'])
bream_length = list(row_data.loc[row_data['Species'] == 'Bream']['Length1'])
roach_wight = list(row_data.loc[row_data['Species'] == 'Roach']['Weight'])
roach_length = list(row_data.loc[row_data['Species'] == 'Roach']['Length1'])데이터 프레임의 loc 메서드를 사용하여 특정 Species 의 데이터를 가져온 후, weight, length1 의 데이터를 인덱싱 해주었습니다.
사이킷런을 사용할 예정이기 때문에, 리스트로 변환해 주었습니다.
산점도를 그려 데이터 확인하기
matplotlib 의 scatter 를 이용하여 산점도를 그려보겠습니다.
import matplotlib.pyplot as plt
plt.scatter(bream_length, bream_weight, label='Bream')
plt.scatter(roach_length, roach_weight, label='Roach')
plt.xlabel('length')
plt.ylabel('weigth')
plt.legend()
plt.show()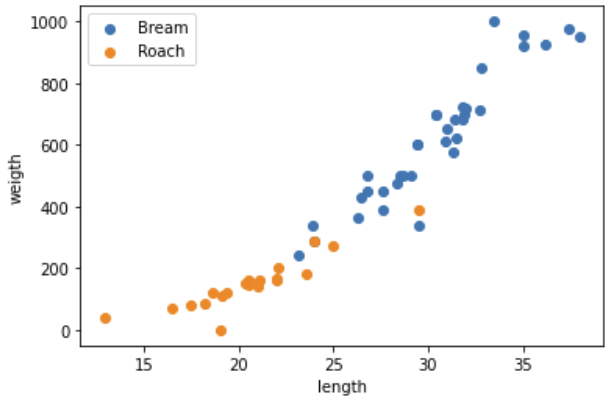
대체로 잉어보다 도미가 길이가 길고, 무거운 것을 확인할 수 있습니다.
데이터 전처리
도미와 잉어 데이터 합치기
도미와 잉어 데이터를 하나의 데이터로 합치겠습니다.
import numpy as np
fish_length = bream_length + roach_length
fish_weight = bream_weight + roach_weight
fish_data = np.column_stack((fish_length, fish_weight))타겟 리스트 생성
도미는 1, 잉어는 0으로 타겟 리스트를 만들겠습니다.
파이썬 리스트를 사용해도 되지만 numpy 의 ones() 메서드와 zeros() 메서드를 사용하여 넘파이 배열을 만든 후, 첫번째 차원을 따라 배열을 연결하는 concatenate() 메서드를 사용하여 합쳐 주겠습니다.
데이터가 클 수록 파이썬 리스트는 비효율적이므로 넘파이 배열을 사용하는것이 좋습니다.
fish_target = np.concatenate((np.ones(len(bream_weight)), np.zeros(len(roach_weight))))사이킷런으로 훈련 세트와 테스트 세트 나누기
훈련 세트와 테스트 세트가 골고루 섞여 있지 않으면 샘플링 편향이 발생할 수 있습니다. 따라서 훈련 세트와 테스트 세트를 섞어주어야 합니다.
train_test_split() 함수는 전달되는 리스트나 배열을 잘 섞은 후, 비율에 맞게 훈련 세트와 테스트 세트를 나누어 줍니다.
strafiy 매개변수에 타겟 데이터를 전달하면 클래스 비율에 맞게 적절히 나누어 줍니다.
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(
fish_data, fish_target, stratify=fish_target
)표준점수(Z-Score)로 데이터 표준화
표준화란 평균이 0이고 분산이 1 인 표준 정규 분포로 변환하는 것입니다.
표준점수 공식은 다음과 같습니다.
평균을 빼고, 표준편차를 나누어 주면 됩니다. numpy 의 mean, std 메서드를 사용하겠습니다.
mean = np.mean(train_input, axis=0)
std = np.std(train_input, axis=0)
train_scaled = (train_input - mean) / std이상치 제거
표준점수의 절대값이 2를 넘기는 경우, 이상치로 분류하겠습니다.
outline = []
for i, sample in enumerate(train_scaled):
for n in sample:
if abs(n) >= 2:
outline.append(i)
break
print(train_scaled[outline])출력값 : [[-2.3026409 -1.45068887]]
이상치가 하나 발견되었습니다.
numpy 의 delete() 메서드를 사용하여 이상치를 제거해 줍시다.
train_input = np.delete(train_input, outline, axis=0)
train_target = np.delete(train_target, outline, axis=0)KNN 알고리즘을 이용하여 데이터 분류하기
알고리즘 훈련하기
sklearn 라이브러리의 KNeighborsClassifier 을 이용하여 KNN 알고리즘을 사용하겠습니다.
fit() 메서드로 알고리즘을 훈련하고, score() 메서드로 모델을 평가해 보겠습니다.
from sklearn.neighbors import KNeighborsClassifier
kn = KNeighborsClassifier()
kn.fit(train_input, train_target)
kn.score(test_input, test_target)출력값이 0.9285714285714286 로 나왔습니다. 92.8% 의 정확도를 보여주고 있습니다.
새로운 데이터의 위치 확인해 보기
길이가 30, 무게가 600인 데이터를 분류해 보겠습니다.
우선 산점도를 그려 새 데이터의 위치를 확인해 보겠습니다.
plt.scatter(bream_length, bream_weight, label='Bream')
plt.scatter(roach_length, roach_weight, label='Roach')
plt.scatter(30, 600, marker='^', color='red', label='New Data')
plt.xlabel('length')
plt.ylabel('weigth')
plt.legend()
plt.show()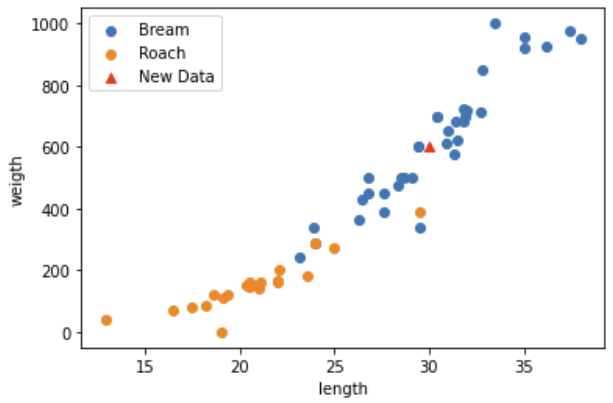
30, 600은 제가 보기엔 도미인 것 같습니다.
KNN으로 새로운 데이터 분류해 보기
predict = kn.predict([[30, 600]])
print(predict)결과값으로 [1] 이 나왔습니다.
아까 도미를 1로 설정하였으니, 모델이 데이터를 잘 분류한 것을 확인할 수 있습니다.
Google Colab 실습 코드
본 포스팅의 모든 코드를 Colab에 올려두었습니다.
https://colab.research.google.com/drive/19aqU70aNwhCezGrMd8v9j_6PokiZNf0I?usp=sharing
