
✅SQL 중심적인 개발의 문제점
대부분 객체지향 언어와 함께 관계형 DB를 사용하여 어플리케이션을 개발한다
이 말은 즉, 객체를 관계형 DB에 저장하여 관리해야 한다는 의미이다.
📌하지만 SQL 중심적 개발로 되는 문제점이 발생한다.
- 무한 반복, 지루한 코드
📌객체지향 과 관계형 DB의 패러다임 불일치 문제가 존재한다.
- 관계형 DB는 데이터를 저장하여 보관하는게 목표이고
- 객체지향은
추상화, 캡슐화, 정보은닉,상속, 다형성등 시스템의 복잡성을 제어하는게 목표이다 - 패러다임이 맞지 않은 두 개념 (
객체를관계형 DB에 저장하여 관리해야 하기 때문에 문제가 발생한다. )

객체를 SQL로 매핑하는 작업은 개발자의 몫이다.
👏객체와 관계형 DB의 차이
- 상속
👉 객체에는 상속관계가 있다.
관계형 DB에는 상속관계가 없다고 보면 된다.- 연관관계
👉 객체는 참조를 통해 (getXX() 메소드) 연관관계를 맺는다.
관계형 DB는 join연산을 통해 연관관계 맺기를 흉내낼 수 있다.- 데이터 타입
- 데이터 식별 방법
🥦1. 상속
📢관계형 DB에서 객체의 상속관계와 그나마 유사한 것이 Table 슈퍼타입, 서브타입 관계이다.

Album 을 저장할 때,
- 객체 입장에서 Album 은 Item의 속성을 상속받은 상태이다. 👉 객체 분해
- 관계형 DB입장에서 다른 INSERT Query를 두번 작성해야한다. 👉
insert into ITEM,insert into ALBUM
Album 을 조회할 때,
- 관계형 DB에서
ITEM,ALBUM테이블을 JOIN하고 - JOIN결과 테이블을 가지고
Item,Album객체의 속성에 맞게 데이터를 넣어줘야한다.
👉 문제점은
Movie,Book조회시 매번ITEM테이블과 각각 JOIN해야하고, 그 결과를 객체에 집어넣는 과정을 반복해야한다.
👉 이러한 문제 때문에관계형 DB에 저장할객체에는상속관계를 쓰지 않는다.
📢객체를 관계형 DB가 아니라 Java Collection에 저장, 조회한다고 가정해보자.
add 메소드로 객체 저장
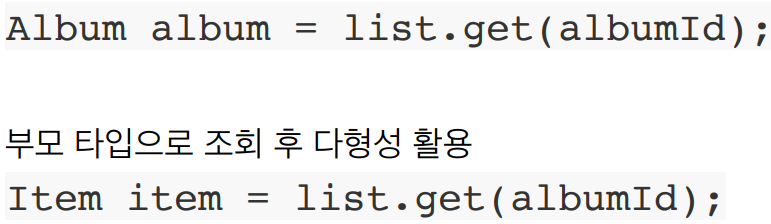
get 메소드로 객체 조회
👉객체를
Java Collection에 넣고 뺄 경우 문제가 단순해지지만,
관계형 DB에 넣고 빼는 과정은 굉장히 복잡해진다 (중간의 SQL mapping작업을 개발자가 다 해줘야 한다)
🥦1. 연관관계
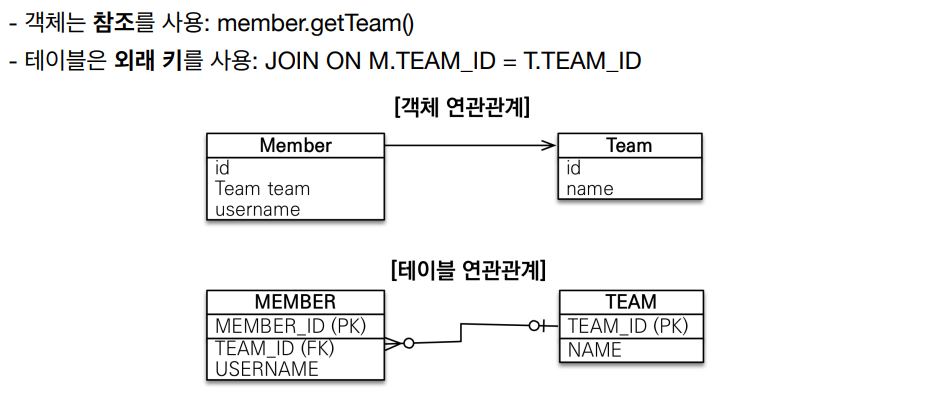
객체의 연관관계에서
Member객체로 Team객체를 참조할 수 있지만, Team객체는 Member객체를 참조할 수 없다 (단방향)
테이블의 연관관계에서
객체의 연관관계와 다르게, TEAM테이블에서 MEMBER테이블을TEAM_ID속성을 통해 역참조할 수 있다. (양방향)
📢객체를 모델링해보자


테이블에 맞추어 모델링하면 객체지향스럽지 못하다

Long teamId가 아니고Team team이라는 참조값을 가져야 객체지향적 모델링이다.
- 관계형 DB에서
외래키는 객체지향에서참조와 비슷하다
이 상태에서 Member 테이블에 Insert해보자
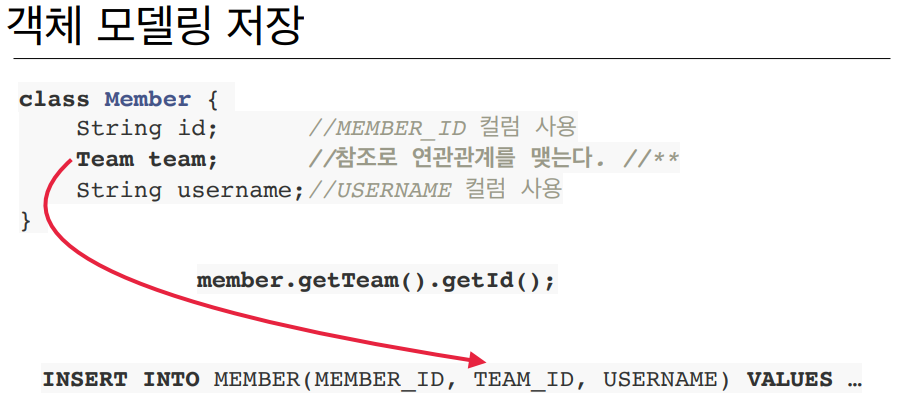
class Member에는
TEAM_ID라는 외래키값은 없고Team team이라는 참조값만 있다.
👉member.getTeam().getId()으로 외래키TEAM_ID를 얻을 수 있다.
📢객체지향적 모델링의 문제는 조회할 때 발생한다.
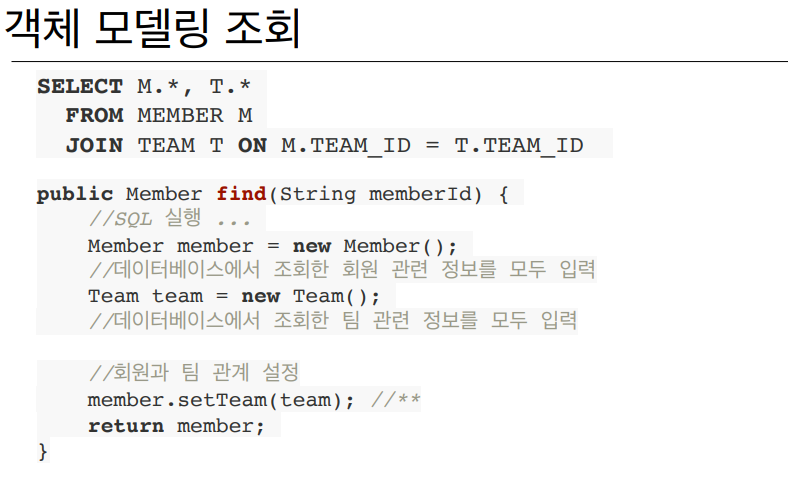
MEMBER,TEAM테이블을 Join한 데이터를 얻는다.
섞여있는 데이터에 member, team 부분을 분리하여 값을 객체에 넣는다.
그 다음, 개발자가 직접member.setTeam(team);으로 연관관계를 세팅한다.
👉 번거로운 과정이다.
📢하지만 Java Collection으로 관리하면 참 괜찮은 방법이다.

Collection에 member객체를 add할 때, member와 연관된 team 참조값이 함께 들어간다.
team객체는member.getTeam()으로 member객체와 함께 딸려온다.
👏객체 그래프 탐색
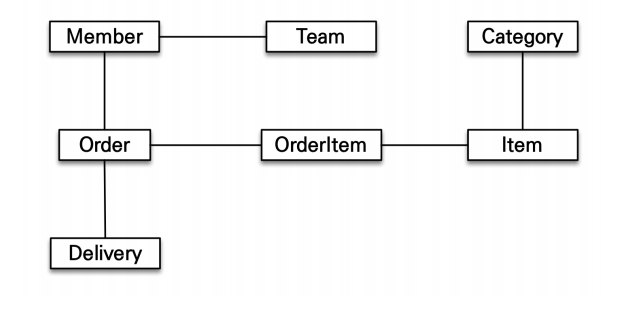
객체는 자유롭게 객체 그래프를 탐색할 수 있어야 한다.
📢하지만… 생각대로 탐색할 수 없다

Memebr와 Team 정보를 가져오는 SQL을 날린 경우, Member와 Team에 대한 값만 채워진다.
👉member.getTeam();할 경우 값이 반환되지만,member.getOrder();의 경우는 null값이 반환된다. (애초에 member와 team에 대해서만 값이 채워진 상태이기 때문)
👉 처음 실행한 SQL에 따라 탐색 범위가 결정되기 때문에 객체 그래프 탐색의 성질을 완벽히 활용할 수 없다.
📢 위와 같은 상황으로 엔티티에 대한 신뢰 문제가 발생한다.

과연
member.getTeam();,member.getOrder().getDelivery();값이 null이 아니라는 보장이 있을까 ❓
NO
👉memberDAO.find(memberId);메소드가 실행될 때, 어떤 query가 날라가서 어떻게 데이터를 조립했는지 눈으로 직접 확인해야 알 수 있다.
그렇다고 해서 모든 객체를 미리 로딩해 둘 수 없다.

동일한 회원에 대한 정보를 조회하는 경우, 모든 경우의 수를 따져가면서 여러 개의 조회 메소드를 만들어야 한다.
✍ 계층형 아키텍처의 진정한 계층 분할이 어려워진다. (물리적으로는 분리되지만 논리적으로 긴밀하게 밀접해있다)
👏비교하기

memberId가 100인 객체 member1, member2는 다른 객체이다.
👉 식별자 memberId가 동일해도getMember()메소드에서return new Member(..);으로 member1, member2 객체를 생성하기 때문에member1 ≠ member2이다

하지만 Java Collection에서 조회하는 경우 member1, member2 객체의 참조값이 같으므로
member1==member2이다
👏결론
✍ 객체답게 모델링을 하면 할수록 mapping 작업만 늘어난다.
객체를 Java Collection에 저장 하듯이 관계형 DB에 저장할 수 없을까 ❓
YES 👉 JPA (Java Persistence API)
