select -> 데이터를 조회하거나 산술,함수등 실행
select 1+1;
#계산식도 사용가능distinct -> 중복값 제거 후 출력
select distinct a,b from table_name;as -> 별칭 지정
select (aaa,bbb) as ccc from table_name;
#as를 쓰지않고 한칸 띄우기로도 지정가능as를 이용한 column끼리의 연산도 가능하다
select 제품이름, 가격, 가격*0.2 as 할인율, 가격*0.8 as 최종가격 from table_name;별칭지정된 할인율과 최종가격이 가상테이블로(?) 추가되어 출력된다
논리곱, 논리합
select 1 and 0;
#논리곱 -> 0출력
select 1 or 1;
#논리합 -> 1출력between -> 사이값 찾기
select a from table_name where a between 30 and 50;
#column a의 30~50까지의 값 출력 (30과 50을 포함한다!!)in -> 조건과 일치하는 여러값 찾기
select * from table_name where a in (10,20,30);
#column a 에서 10,20,30과 일치하는 값을 찾아서 출력문자열 like
ex) 데이터 이름이 paullab, paultest, paulcodes1 3개가 있다고 가정
select * from table_name where a like 'paul%';
#paul로 '시작'하는 데이터 전부출력 -> paullab, paultest, paulcodes1
#보통 %paul%이렇게 앞뒤로 많이 쓴다고한다
select * from table_name where a like 'paul___';
#언더바 하나당 문자 하나!
#언더바가 3개이므로 paullab출력
#%,_ 둘다 대소문자 관계없이 출력IS NULL, IS NOT NULL
select a from table_name where IS NULL
# a column에서 null인값을 출력
select a from table_name where IS NOT NULL
# a column에서 null이 아닌 값을 출력
IF ISNULL(a, '') = '';
#COALESCE -> TITLE에서 NULL을 0으로
SELECT * , COALESCE(TITLE, '0') AS TNULL FROM [dbo].[TB_JHH_SAMPLE];
--NULL은 0을 반환, NULL아 아닌 값은 TITLE을 반환
@MAXID INT = (SELECT COALESCE(MAX(ID), 0) + 1 FROM TB_JHH_SAMPLE)
--(NULL은 0을 반환 하고 +1, NULL아 아니면 ID중 제일 큰 값을 반환하고 +1)의 값을 @MAXID에 저장ISNULL과의 차이 -> COALESCE는 NULL값을 여러개 매개변수로 받을수있지만
ISNULL은 1개만 체크
ISNULL - SSMS / COALESCE - ANSI 표준
CREATE시 DEFAULT지정
CREATE TABLE [dbo].[TB_JHH_SAMPLE2]
(
ID INT PRIMARY KEY
, DOCNO NVARCHAR(30)
, TITLE NVARCHAR(30)
, CDATE DATETIME DEFAULT GETDATE()
);
--USE_YN CHAR(2) DEFAULT 'Y'INSERT할때
INSERT INTO
[dbo].[TB_JHH_SAMPLE2] (ID, DOCNO, TITLE (DEFAULT 생략))
SELECT * FROM
[dbo].[TB_JHH_SAMPLE];
--SELECT INSERT문 -> TB_JHH_SAMPLE의 데이터를 TB_JHH_SAMPLE2에 INSERTDEFAULT는 빼고 작성
@, DECLARE -> 변수
--선언,정의
DECLARE @MAXID INT;
DECLARE @EID INT = NULL;
DECLARE @SID INT = 1;
DECLARE @GET_CNT INT = (SELECT COUNT(ID) AS CNT FROM [dbo].[TB_JHH_SAMPLE2]);
--사용
SELECT *, @GET_CNT AS CNT FROM [dbo].[TB_JHH_SAMPLE];LEN, CONCAT, SUBSTRING, UPPER, PARSE, REPLACE 내장함수
SELECT
LEN(COALESCE(TITLE, '')) AS LENG
, CONCAT(DOCNO, ' / '+TITLE) AS CON
, SUBSTRING(COALESCE(TITLE, '-'), 2, 5) AS SUBS
, UPPER(COALESCE(TITLE, '-')) AS UP
, PARSE('2017/01/30' AS date) AS ANNVS
, (SELECT CONVERT(VARCHAR(7), 777+'777')) AS CONV
, CONVERT(VARCHAR(3), [dbo].[TB_JHH_SAMPLE].ID, 0)+1 AS CONVID2
, REPLACE(TITLE, 'a', 123) AS REPL
FROM
[dbo].[TB_JHH_SAMPLE];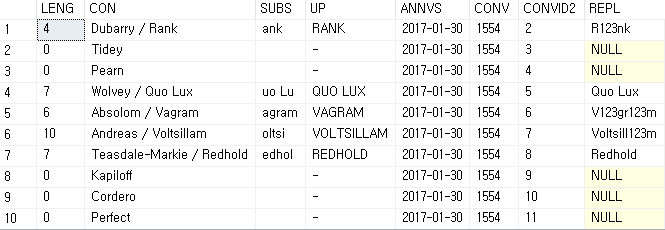
CONCAT - 문자열 + NULL도 합쳐준다(A + NULL = A), 중간에 ' / '+ 를 넣어서 문자열사이 구분도 가능
SUBSTRING - 내생각엔 문자와 문자사이 이동이 1회로 치는거 같다(공백도 하나로 취급)
PARSE - 문자열을 DATE타입으로 변경
CONVERT - 아직도 잘모르겠다 VARCHAR로 타입변경을 했는데 숫자계산이 되서 출력...
REPLACE - 일치하는 문자를 해당하는 문자나 숫자로 치환 공백제거는 밑에서 설명
COUNT조건문
SELECT
COUNT(CASE WHEN ID%2=0 THEN 1 END) AS even
FROM
[dbo].[TB_JHH_SAMPLE];
--ID COLUMN을 2로 나눳을때 나머지가 0인 것만 COUNTREVERSE, TRIM/RTRIM/REPLACE
SELECT REVERSE('SSMS SQL SERVER') AS REV;
--문자열을 그냥 뒤집어서 출력(공백도 유지)
SELECT
TRIM(' a aas ddw s dw fe qweq s eef ') AS T
, RTRIM(' a aas ddw s dw fe qweq s eef ') AS RT
, REPLACE(' a aas ddw s dw fe qweq s eef ', ' ', '') AS REP
;

TRIM - 문자열 양끝의 공백 제거
RTRIM - 문자열 오른쪽 끝의 공백제거 <==> LTRIM
REPLACE 문자열, ' ', '' - 공백(' ')을 찾아서 ''으로 치환 (공백 전체 제거)
VARCHAR_FORMAT
SELECT VARCHAR_FORMAT(CURRENT_TIMESTAMP, 'YYYY-MM-DD HH24:MI:SS') AS FormattedDateTime;
VARCHAR_FORMAT(TO_DATE(B.USEDT, 'YYYYMMDD'), 'YYYY-MM-DD') AS USEDTANSI SQL 표준 함수
숫자, 날짜, 시간 및 다른 데이터 유형을 문자열로 변환하는 데 사용
VARGRAPHIC -> IBM Db2
P_TITLE VARGRAPHIC(100) CCSID 1200
--100문자열(최대 200바이트)길이의 VARGRAPHIC 데이터타입의
--CCSID(Coded Character Set Identifier)의 1200은 UTF-16 인코딩, 유니코드 문자열을 저장문자열의 길이가 고정되어 있지 않은 가변 길이를 지원, 문자열의 실제 길이에 따라 저장 공간을 동적으로 조절 -> 저장 공간을 효율적으로 사용
영어, 한국어, 중국어, 아랍어 등 다양한 언어의 텍스트를 하나의 필드에 저장 -> 유니코드 문자열을 저장하는 데 사용
다른 RDBMS의 NVARCHAR와 유사함
