회기 성능 평가
Sklearn.metrics는 손실, 점수, 회기 성능 평가 함수 등 다양한 함수를 가지고 있다. 예를 들면, mean_squared_error, explacined_evariance_score, r2_score 같은 것이 존재하고 있다.
1. Explained Variance Score
- Explained variance score는 설명 분산 점수라고도 부른다. 이는 기존 SSR에서 Mean Error를 빼는 것으로 모델에서 나오는 오차가 0을 기준으로 왔다갔다 한다면 R2와 비슷할 것이다.
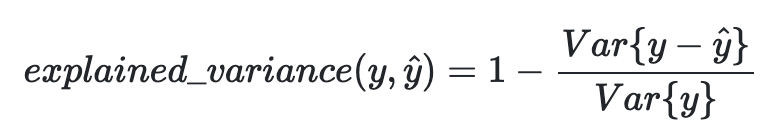
- 식을 보면 알 수 있듯이 우리가 예측한 yhat을 기존 y값에서 빼고 나서 분산 처리를 하는 것을 알 수 있다.
- 가장 좋은 최적의 값은 1.0이고 더 낮은 값일수록 더 나빠진다.
기존 함수
from sklearn.metrics import explained_variance_score
y_true = [3, -0.5, 2, 7]
y_pred = [2.5, 0.0, 2, 8]
explained_variance_score(y_true, y_pred)다른 예시
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.utils import shuffle
data = pd.read_csv("https://raw.githubusercontent.com/amankharwal/Website-data/master/student-mat.csv")
data = data[["G1", "G2", "G3", "studytime", "failures", "absences"]]
predict = "G3"
x = np.array(data.drop([predict], 1))
y = np.array(data[predict])
from sklearn.model_selection import train_test_split
xtrain, xtest, ytrain, ytest = train_test_split(x, y, test_size=0.2)
linear_regression = LinearRegression()
linear_regression.fit(xtrain, ytrain)
predictions = linear_regression.predict(xtest)
from sklearn.model_selection import cross_val_score
print(cross_val_score(linear_regression, x, y, cv=10, scoring="explained_variance").mean())
vie- 설명된 분산은 회기 모델에서 예측의 분산 비율을 측정하는데 사용된다.
2. Max Error
- Max Error은 잔차의 최댓값으로 가장 최악의 오류가 발생하는 경우를 잡아 나타내준다.
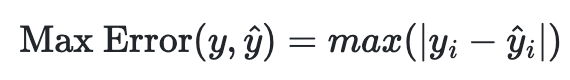
- 위 식에서도 볼 수 있듯이 최대 오류의 값을 출력해준다.
기본 함수
from sklearn.metrics import max_error
y_true = [3, 2, 7, 1]
y_pred = [9, 2, 7, 1]
max_error(y_true, y_pred)
출력
63. Mean Absolute Error(MAE)
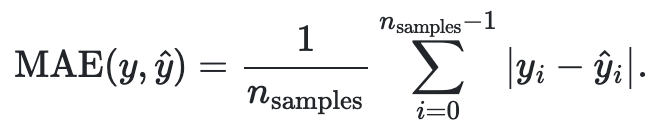
- 이 지표는 오류의 평균값을 나타낸 것이다.
기본 함수
from sklearn.metrics import mean_absolute_error
y_true = [3, -0.5, 2, 7]
y_pred = [2.5, 0.0, 2, 8]
mean_absolute_error(y_true, y_pred)Numpy로 구현하기
import numpy as np
def mae(y_true, y_pred):
return np.mean(abs(y_true - y_pred), axis=0)4. Mean Squared Error(MSE)
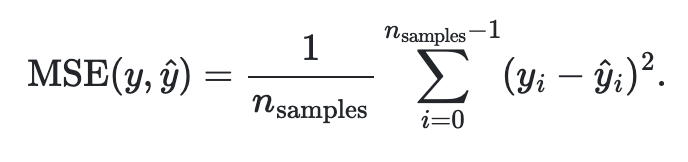
- MAE는 절댓값을 사용한 반면에 MSE는 오류의 제곱으로 양수를 만들고 성능을 평가한다.
기본 함수
from sklearn.metrics import mean_squared_error
y_true = [3, -0.5, 2, 7]
y_pred = [2.5, 0.0, 2, 8]
mean_squared_error(y_true, y_pred)Numpy로 구현하기
import numpy as np
def mse(y_true, y_pred):
return np.square(np.subtract(y_true, y_pred)).mean()5. Root Mean Squared Error(RMSE)
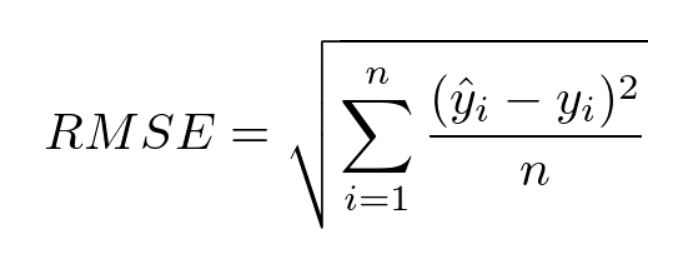
- 평균 제곱근 오차라고 불리며 기존 MSE의 Root를 씌운 평가지표이다.
MSE 활용
from sklearn.metrics import mean_squared_error
mean_squared_error(y_actual, y_predicted, squared=False)Numpy로 구현하기
import numpy as np
def rmse(y_true, y_pred):
return np.sqrt(((y_true - y_pred) ** 2).mean())6. Root Mean Squared Logarithmic Error(MSLE)
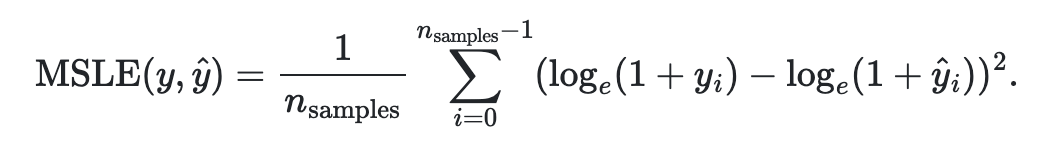
- 기존 RMSE에 로그를 씌워 계산한 성능 지표이다.
기존 함수
from sklearn.metrics import mean_squared_log_error
y_true = [3, 5, 2.5, 7]
y_pred = [2.5, 5, 4, 8]
mean_squared_log_error(y_true, y_pred)Numpy로 구현하기
def rmsle(y_true, y_pred):
sum = 0.0
for x in range(len(y_pred)):
if y_pred[x] < 0 or y_true[x] < 0:
continue
p = np.log(y_pred[x] + 1)
r = np.log(y_true[x] + 1)
sum = sum + (p-r)**2
return (sum/len(y_pred))**0.57. R2 Score
- R-Squared에 기반을 두어 선형 회귀 모델에 대한 적합도 측정값을 추리는 것이다.
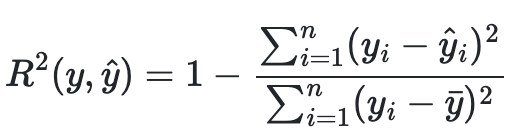
- 기존 식을 살펴보게 되면 전체 오차 제곱의 합이 있고 ybar는 전체 y값의 합을 y의 개수로 나눈 평균 값으로 전체를 제곱한 제곱 오차항이 존재하고 있다.
- 0과 1 사이에서 1에 가까울 수록 선형회귀 모델이 데이터에 대하여 높은 연관성을 가지고 있다고 해석할 수 있다.
기존 함수
from sklearn.metrics import r2_score
y_true = [3, -0.5, 2, 7]
y_pred = [2.5, 0.0, 2, 8]
r2_score(y_true, y_pred)Numpy로 단순하게 구현하기
def r2_score(x_values, y_values):
correlation_matrix = np.corrcoef(x_values, y_values)
correlation_xy = correlation_matrix[0, 1]
return correlation_xy**2다항 함수일 경우 Numpy로 구현하기
import numpy as np
# 다항함수를 사용하는 경우
def poly(x, y, degree):
results = {}
coeffs = np.polyfit(x, y, degree)
# 다항 함수 계수
results['polynomial'] = coeffs.tolist()
# r-squared
p = np.poly1d(coeffs)
yhat = p(x)
ybar = np.sum(y)/len(y)
ssreg = np.sum((yhat-ybar)**2)
sstot = np.numpy.sum((y-ybar)**2)
results['determination'] = ssreg / sstot
return resultsScipy를 활용하는 경우
slope, intercept, r_value, p_value, std_err = scipy.stats.linregress(x, y)최종적으로 정리를 하다보니 앞서 작성한 분류 모델 평가와 회귀모델 평가 지표를 더 자세히 알 수 있었던 것 같다.

https://medium.com/@jinsung1048 미디엄으로 이전하였습니다.