
우테캠 팀 프로젝트였던 쇼핑몰 애플리케이션을 리팩토링 해보기로 했다.
가장 먼저 개선할 부분은 시간이 오래 걸리는 조회 쿼리를 캐싱하는 부분이다.
문제 파악
@Query(value = "select p.* from order_items oi "
+ "inner join products p on oi.product_id = p.id "
+ "where oi.order_id in ("
+ "select inner_o.id "
+ "from order_items inner_oi "
+ "inner join orders inner_o on inner_oi.order_id = inner_o.id "
+ "where inner_oi.product_id = :productId and inner_o.status = 'COMPLETED'"
+ ") and p.id != :productId "
+ "group by p.id "
+ "order by count(oi.id) desc, p.id desc", nativeQuery = true)
Slice<Product> findRecommendedProducts(@Param("productId") final Long productId, final Pageable pageable);애플리케이션에는 상품 조회 시 같이 구매된 횟수 순으로 최대 30개의 상품을 추천해주는 기능이 있었다. 위와 같은 쿼리로 상품 리스트를 받아 왔는데, 주문이 300만 개, 주문 상품이 750만 개인 상황에서 위와 같은 쿼리는 성능이 좋지 않았다.
(프로젝트 개발 시에는 원래 주문 500만 개, 주문 상품 1250만 개였는데, 노트북 사양이 좋지 않아서 리팩토링할 때 데이터 크기를 40% 줄였다.)
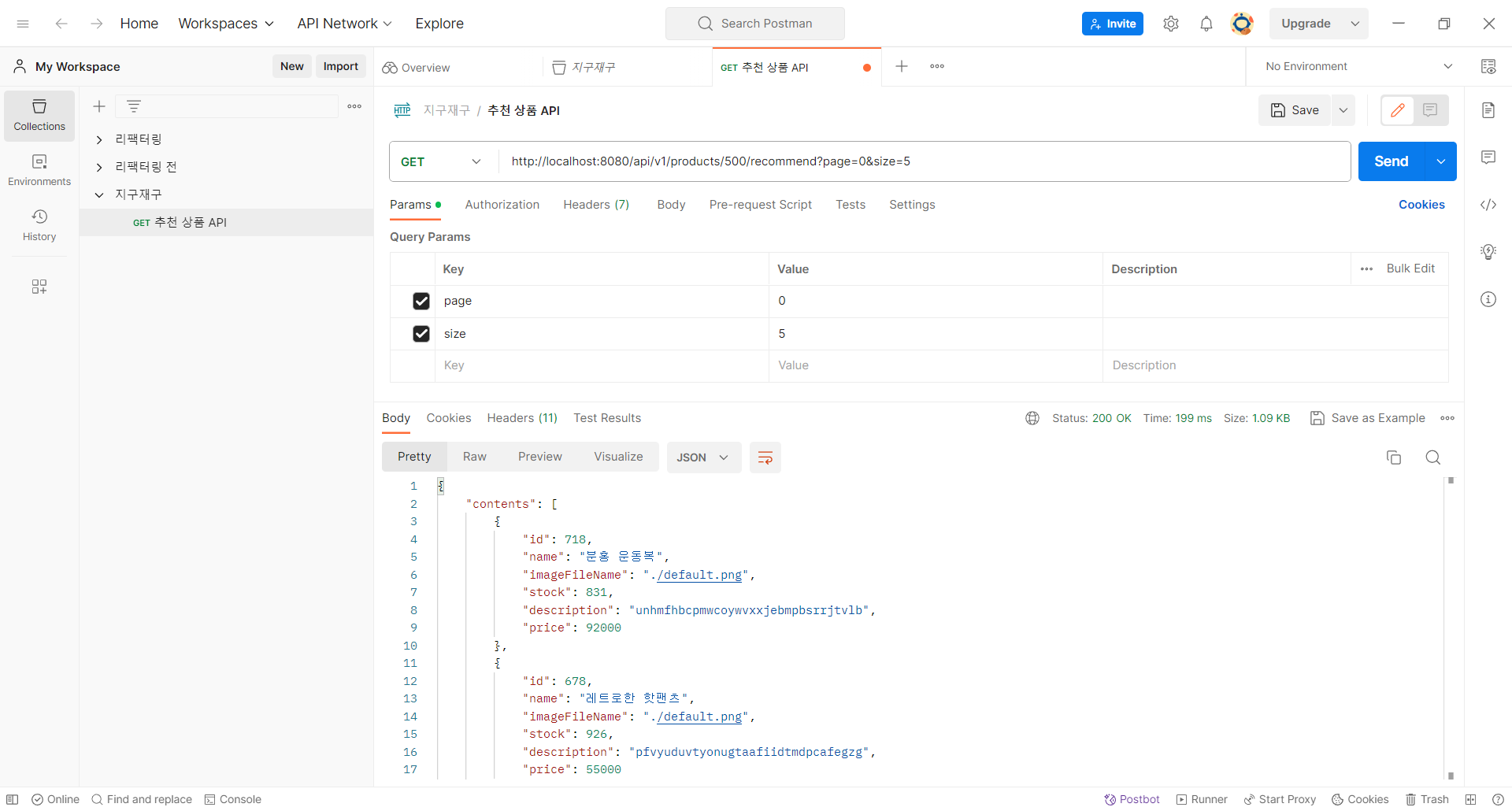
추천 상품 첫 5개를 가져오는 데 200ms 정도가 걸리는 것을 확인할 수 있다. 다음 5개를 가져올 때에도 똑같은 쿼리를 날리기 때문에 추천 상품 30개를 모두 확인하려면 1.2초(200ms * 6) 정도가 걸릴 것이다.
해결 방안 찾기
해당 쿼리를 최적화하는 방법은 아무리 생각해 봐도 떠오르지 않아서 캐싱을 사용하기로 했다. 확장성을 고려해서 리모트 캐시인 레디스(Redis)를 택했다.
다음으로 정할 것은 데이터를 저장 형식, 그리고 캐싱 데이터를 적재하는 방식이었다.
데이터 저장 형식
응답으로 나갈 추천 상품 정보를 모두 캐시에 저장하는 방법과 추천 상품 ID만 저장하는 방법 중에 고민이 많았다.
전자는 DB 조회가 필요 없다는 장점을, 저장해야 하는 데이터 용량이 많아지고 저장 데이터가 뷰(응답 형식)에 의존한다는 단점을 가진다. 반대로 후자는 저장 데이터가 간결하고 뷰에 의존하지 않는다는 장점을, ID로 다시 상품 조회를 진행해야 한다는 단점을 가진다.
나는 후자를 택했는데, 추천 상품 ID로 DB를 조회하는 부분을 JPA의 findAllById를 사용해서 쿼리 한방으로 해결했더니 성능 차이가 거의 없었기 때문이다. 상품 1000개에 추천 상품 30개씩 저장했을 때 전체 저장 용량도 1MB 정도로 매우 작았다.
- 231009 추가
추천 상품 ID만 저장하는 경우, 데이터 동기화 문제도 발생하지 않는다. 요구사항이 변경되어 상품 이미지나 가격이 수정 가능한 경우를 생각해 보자. 상품 정보를 모두 캐싱한다면 수정한 정보가 제때 반영되지 않을 것이다. ID의 경우 (인공키를 사용한다면) 변경의 여지가 없다.
데이터 적재 방식
요청이 왔을 때 캐시에 데이터가 없으면 조회 쿼리를 수행해서 캐시에 적재하고 응답하는 방식(하루에 한 번 정해진 시간에 캐시 전체 삭제)과 애플리케이션이 올라갈 때 모든 상품에 대해 캐시 데이터를 생성해놓는 방식(하루에 한 번 정해진 시간에 캐시 갱신) 중에 고민했다.
전자는 처음 조회되는 경우 응답 시간이 그대로라는 단점이, 후자는 애플리케이션 시작 시 캐시 데이터를 생성하는 시간이 필요하다는 단점이 있었는데, 전자를 택하기로 했다.

처음 조회 시에만 약간의 지연이 발생하는 건 감당 가능하다고 생각했고, 무엇보다 캐시 데이터 생성에 위와 같이 약 20초가 걸렸기 때문이다. 1000건에 대해 20초라면, 상품이 많아질수록 데이터 생성 시간이 더 길어질 것이다.
@Component
@RequiredArgsConstructor
@Slf4j
public class ProductCacheWarmer {
private final ProductRepository productRepository;
private final ProductCache productCache;
public void warmRecommendationCache() {
log.info("recommendation cache warmer method invoked");
final long start = System.currentTimeMillis();
final List<Long> productIds = productRepository.findAllId();
final List<ProductIdOrderIdPairDto> productIdOrderIdPairs = productRepository.findAllIdWithOrderId();
final Map<Long, List<Long>> orderIdToProductIds = productIdOrderIdPairs.stream()
.collect(Collectors.groupingBy(ProductIdOrderIdPairDto::getOrderId,
Collectors.mapping(ProductIdOrderIdPairDto::getProductId,
Collectors.toList())));
final Map<Long, List<Long>> idToOrderedWithIds = new HashMap<>();
for (Long productId : productIds) {
idToOrderedWithIds.put(productId, new ArrayList<>());
}
for (List<Long> productIdsInOneOrder : orderIdToProductIds.values()) {
final int size = productIdsInOneOrder.size();
for (int i = 0; i < size; i++) {
final Long pId1 = productIdsInOneOrder.get(i);
for (int j = i + 1; j < size; j++) {
final Long pId2 = productIdsInOneOrder.get(j);
idToOrderedWithIds.get(pId1).add(pId2);
idToOrderedWithIds.get(pId2).add(pId1);
}
}
}
productIds.stream()
.parallel()
.forEach(productId -> singleWork(productId, idToOrderedWithIds));
log.info("recommendation cache warmed, total elapsed time : {} ms", System.currentTimeMillis() - start);
}
private void singleWork(final Long productId, final Map<Long, List<Long>> idToOrderedWith) {
final List<Long> recommendationIds = idToOrderedWith.get(productId)
.stream()
.collect(Collectors.groupingBy(Function.identity(), Collectors.counting()))
.entrySet()
.stream()
.sorted(Comparator.comparingLong(Map.Entry<Long, Long>::getValue).reversed())
.map(Map.Entry::getKey)
.limit(ProductCache.RECOMMENDATION_SIZE)
.toList();
productCache.setRecommendationIds(productId, recommendationIds);
}
}백준을 푸는 것 같은 가독성이 없는 코드도 이 선택에 한몫했다.
그 외에 고려했던 점
"{\"@class\":\"com.gugucon.shopping.item.dto.response.ProductIds\",\"contents\":[\"java.util.ArrayList\",[718,678,181,751,725,992,947,940,821,815,794,303,230,176,39,998,784,610,556,492,399,344,959,953,889,652,589,570,555,442]]}"캐시에 저장되는 데이터 형식은 위와 같은데, 클래스 메타데이터가 같이 저장되는 게 마음에 안 들어서 ObjectMapper를 사용해서 문자열 변환 후 저장할까도 생각했다. 그런데 이렇게 하면 문자열 데이터를 캐시로부터 전달 받아서 한 번 더 객체로 변환하는 작업을 해야 했고, 서비스 로직은 이미 충분히 복잡했기 때문에 스프링에서 제공해주는 기능 그대로 사용하기로 했다.
또 위에서 ID 리스트를 래핑(wrapping)하는 ProductIds 클래스가 존재함을 알 수 있는데, 래핑을 하지 않으면 캐시된 데이터의 역직렬화가 실패한다. 아마 런타임에 제네릭 타입 정보가 사라지기 때문에 리스트를 그대로 넘기면 리스트 내부 타입 정보가 없어서 역직렬화가 안 되는 것 같다.
캐싱 결과
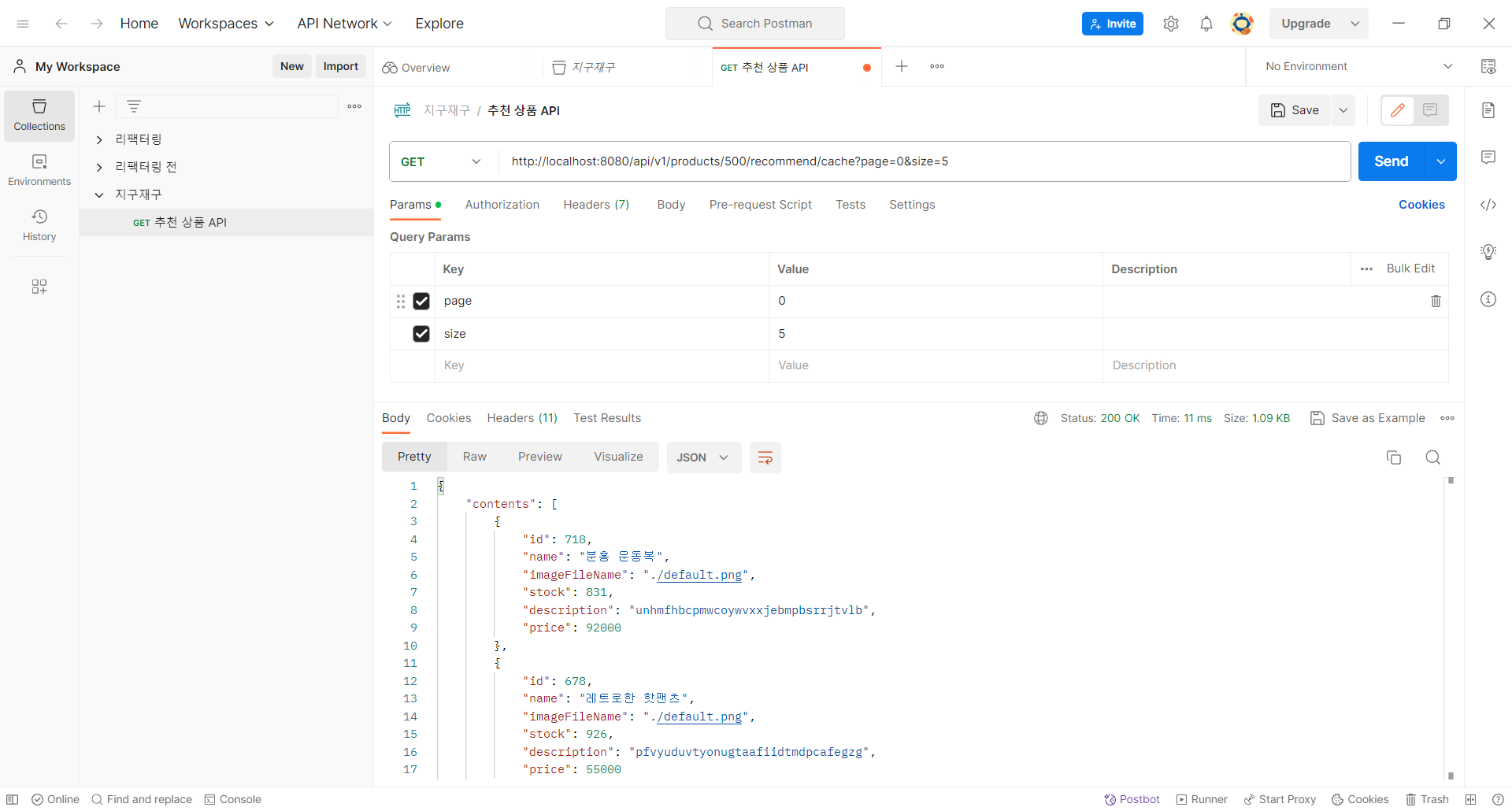
결과는 아주 좋았다. 응답 시간이 10ms 정도로 줄었다.
상품 페이지 첫 조회 시에도 추천 상품 처음 5건 조회 시에는 응답 시간이 약간 길지만, 그 다음 5건부터는 캐싱의 이점을 누릴 수 있다.
테스트는 어떻게 하나
테스트는 레디스 없이도 작동해야 하기 때문에 테스트 전용으로 ConcurrentMapCacheManager를 빈 등록하려고 했다.
@SpringBootTest(classes = {ProductCache.class})
@EnableCaching
@AutoConfigureCache(cacheProvider = CacheType.SIMPLE)
class ProductCacheTest { ... }그런데 위와 같이 @AutoConfigureCache(cacheProvider = CacheType.SIMPLE)를 사용하니까 따로 빈 등록 없이 인메모리 캐시를 사용할 수 있었다.
빈 목록을 살펴보니 simpleCacheConfiguration이라는 빈이 있었는데, 아래와 같이 ConcurrentMapCacheManager를 빈으로 등록해주고 있었다.
@Configuration(proxyBeanMethods = false)
@ConditionalOnMissingBean(CacheManager.class)
@Conditional(CacheCondition.class)
class SimpleCacheConfiguration {
@Bean
ConcurrentMapCacheManager cacheManager(CacheProperties cacheProperties,
CacheManagerCustomizers cacheManagerCustomizers) {
ConcurrentMapCacheManager cacheManager = new ConcurrentMapCacheManager();
List<String> cacheNames = cacheProperties.getCacheNames();
if (!cacheNames.isEmpty()) {
cacheManager.setCacheNames(cacheNames);
}
return cacheManagerCustomizers.customize(cacheManager);
}
}마무리
캐싱은 제대로 적용해본 적이 없어서 Config 클래스 작성부터 해맸던 것 같다. 그래도 이것저것 고민할 거리가 많아서 좋았고, 테스트까지 성공적으로 작성할 수 있어서 뿌듯했다.
다음으로는 데이터베이스 레플리케이션에 도전해봐야겠다.
